pyltp是哈尔滨工业大学社会计算与信息检索研究中心推出的一款基于Python封装的自然语言处理工具,它提供了哈工大LTP(Language Technology Platform)工具包的接口。LTP工具包以其强大的中文分词、词性标注、命名实体识别、依存句法分析等功能,成为了中文NLP领域的佼佼者。pyltp通过Python接口,可以方便地集成到各种NLP应用中,满足各种复杂的NLP需求。
文章目录
一、安装1. 安装pyltp库2. 下载并解压LTP模型 二、常见操作案例1. 分词2. 词性标注3. 命名实体识别
一、安装
pyltp的安装过程可能略显复杂,但通过详细的步骤指导,用户可以轻松地在Windows环境下完成安装。以下是在Windows 10,Python 3.6环境下的安装步骤:
1. 安装pyltp库
pip install pyltp2. 下载并解压LTP模型
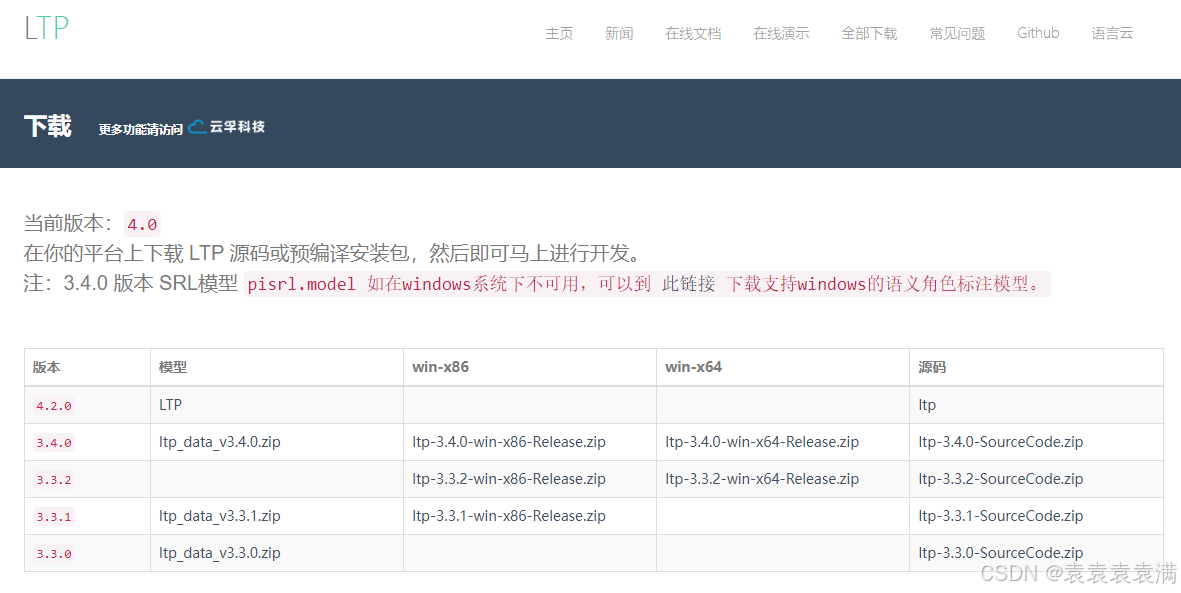
pyltp要实现分词、词性标注、命名实体识别等功能,还需要下载并解压LTP模型。确保下载的模型版本与当前版本的pyltp对应,否则会导致程序无法正确加载模型。例如,pyltp版本0.2.0-0.2.1对应LTP模型版本3.4.0。下载模型后,解压到任意位置,但模型的路径最好不要有中文,否则可能会导致模型加载失败。
模型官网:http://ltp.ai/download.html.
二、常见操作案例
以下是一些使用pyltp进行常见NLP任务的代码案例和输出结果:
1. 分词
import osfrom pyltp import SegmentorLTP_DATA_DIR = r'E:\path\to\ltp_data_v3.4.0' # LTP模型目录路径cws_model_path = os.path.join(LTP_DATA_DIR, 'cws.model') # 分词模型路径segmentor = Segmentor() # 初始化实例segmentor.load(cws_model_path) # 加载模型words = segmentor.segment('元芳你怎么看') # 分词print('|'.join(words)) # 输出分词结果segmentor.release() # 释放模型输出结果:
元芳|你|怎么|看2. 词性标注
import osfrom pyltp import PostaggerLTP_DATA_DIR = r'E:\path\to\ltp_data_v3.4.0' # LTP模型目录路径pos_model_path = os.path.join(LTP_DATA_DIR, 'pos.model') # 词性标注模型路径postagger = Postagger() # 初始化实例postagger.load(pos_model_path) # 加载模型words = ['元芳', '你', '怎么', '看'] # 分词结果postags = postagger.postag(words) # 词性标注print('|'.join(postags)) # 输出词性标注结果postagger.release() # 释放模型输出结果(LTP使用863词性标注集,具体标注含义可参考LTP文档):
nh|r|r|v3. 命名实体识别
import osfrom pyltp import NamedEntityRecognizerLTP_DATA_DIR = r'E:\path\to\ltp_data_v3.4.0' # LTP模型目录路径ner_model_path = os.path.join(LTP_DATA_DIR, 'ner.model') # 命名实体识别模型路径recognizer = NamedEntityRecognizer() # 初始化实例recognizer.load(ner_model_path) # 加载模型words = ['元芳', '你', '怎么', '看'] # 分词结果postags = ['nh', 'r', 'r', 'v'] # 词性标注结果netags = recognizer.recognize(words, postags) # 命名实体识别print(list(netags)) # 输出命名实体识别结果recognizer.release() # 释放模型输出结果(每个元素是一个三元组,表示实体类型、起始位置和结束位置):
[('O', 0, 1), ('O', 1, 2), ('O', 2, 3), ('O', 3, 4)]注意:以上输出结果是基于示例文本“元芳你怎么看”的,实际输出可能会根据文本内容和模型版本有所不同。