文章目录
工具和环境准备安装必要的库 编写爬虫脚本第一步:构造请求第二步:保存文件第三步:批量下载pdf第四步:处理分页+最终代码 结语
最近有很多朋友,甚至还有不少陌生人都花钱找我要上市公司的年报数据。为了节省大家的时间和金钱,我决定写一篇教程,教你们如何用Python轻松爬取巨潮资讯上的上市公司年报。即使你是编程新手也能快速上手,赶紧学起来吧!
工具和环境准备
在开始之前,我们需要准备一些工具和环境:
Python 3.x安装requests和panda库 安装必要的库
首先,打开命令行,运行以下命令安装所需库:
pip install requests beautifulsoup4编写爬虫脚本
第一步:构造请求
打开巨浪资讯搜索 分类年报
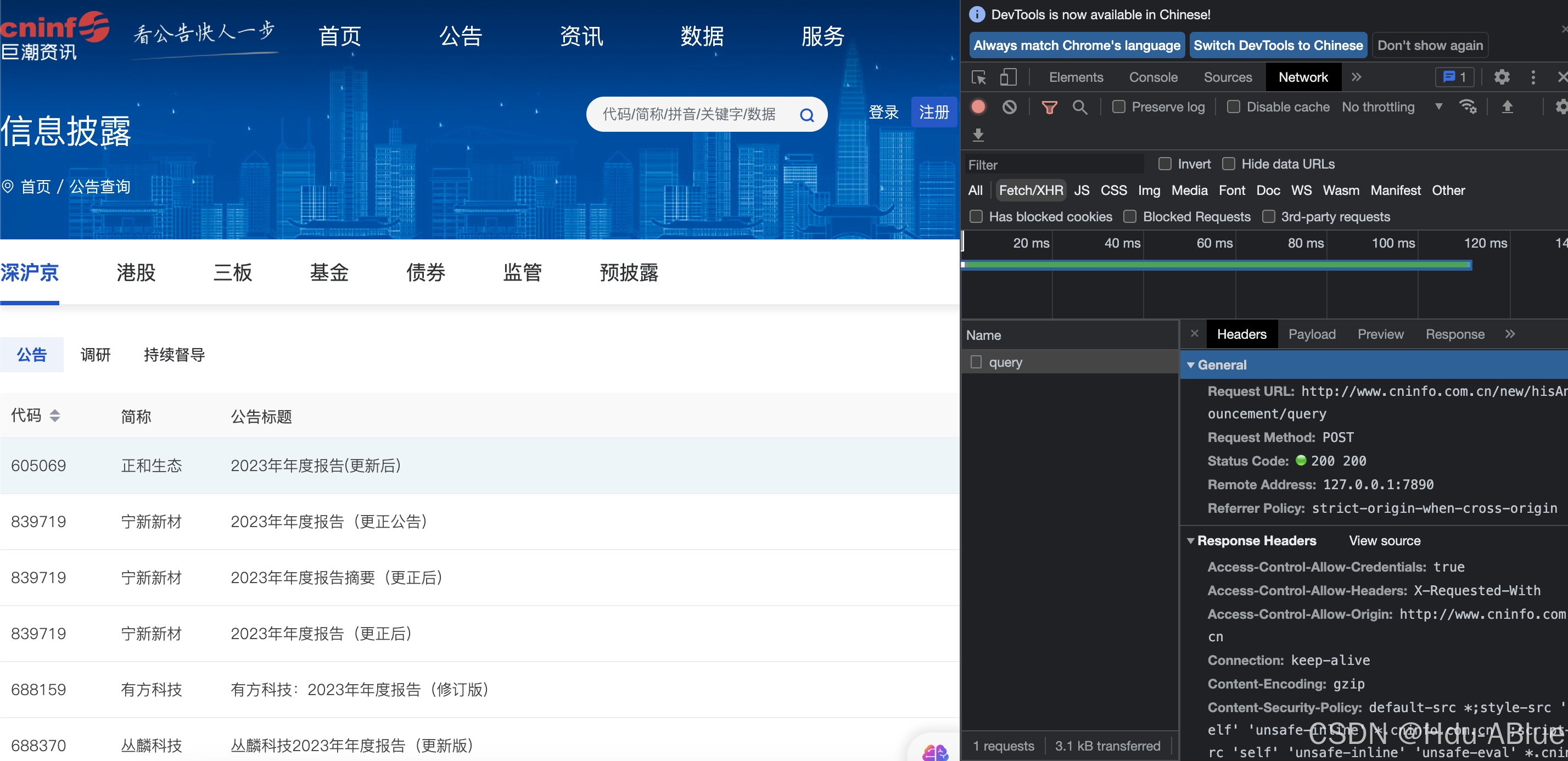
这个接口访问可以查看所有年报,开始python模拟请求
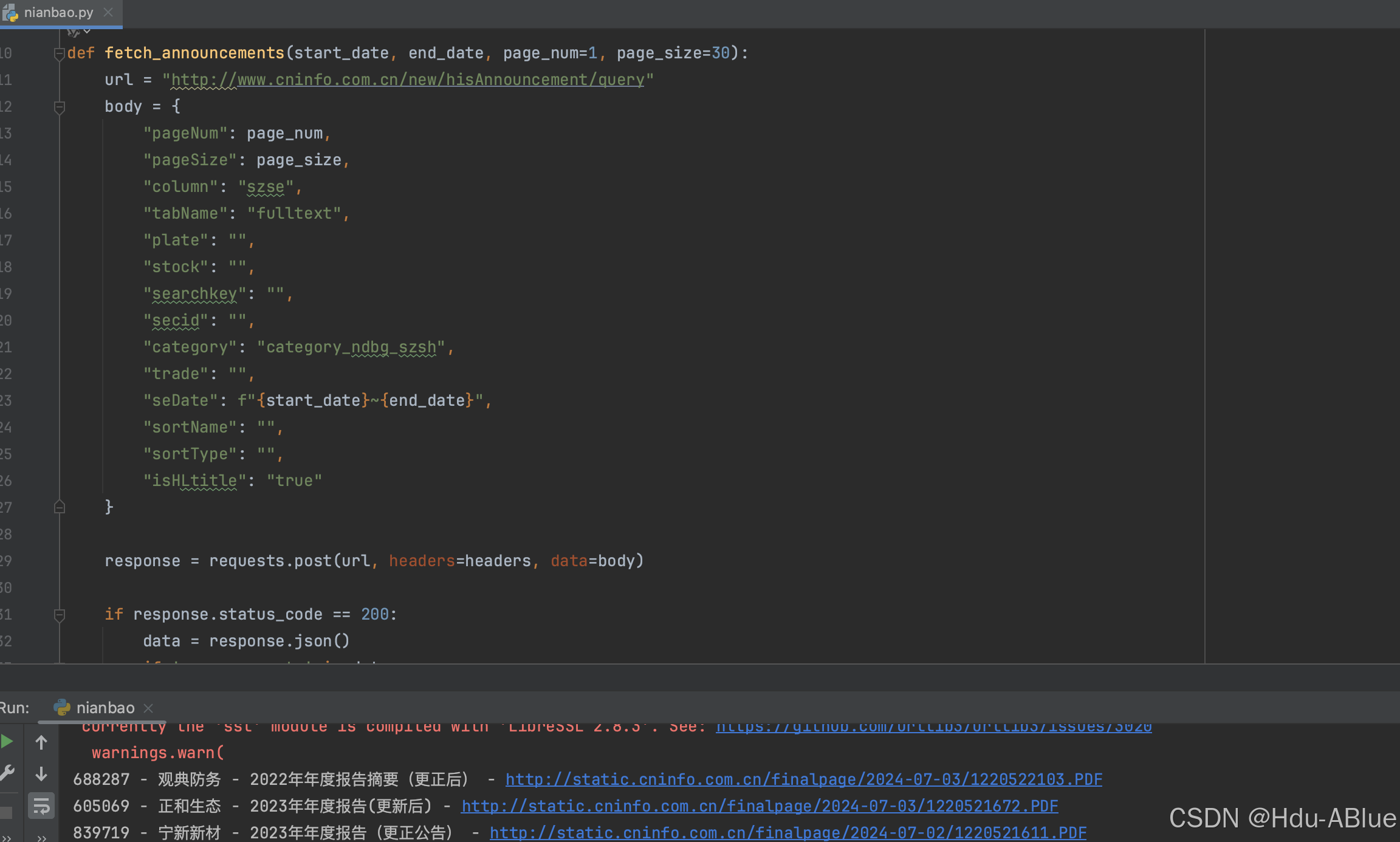
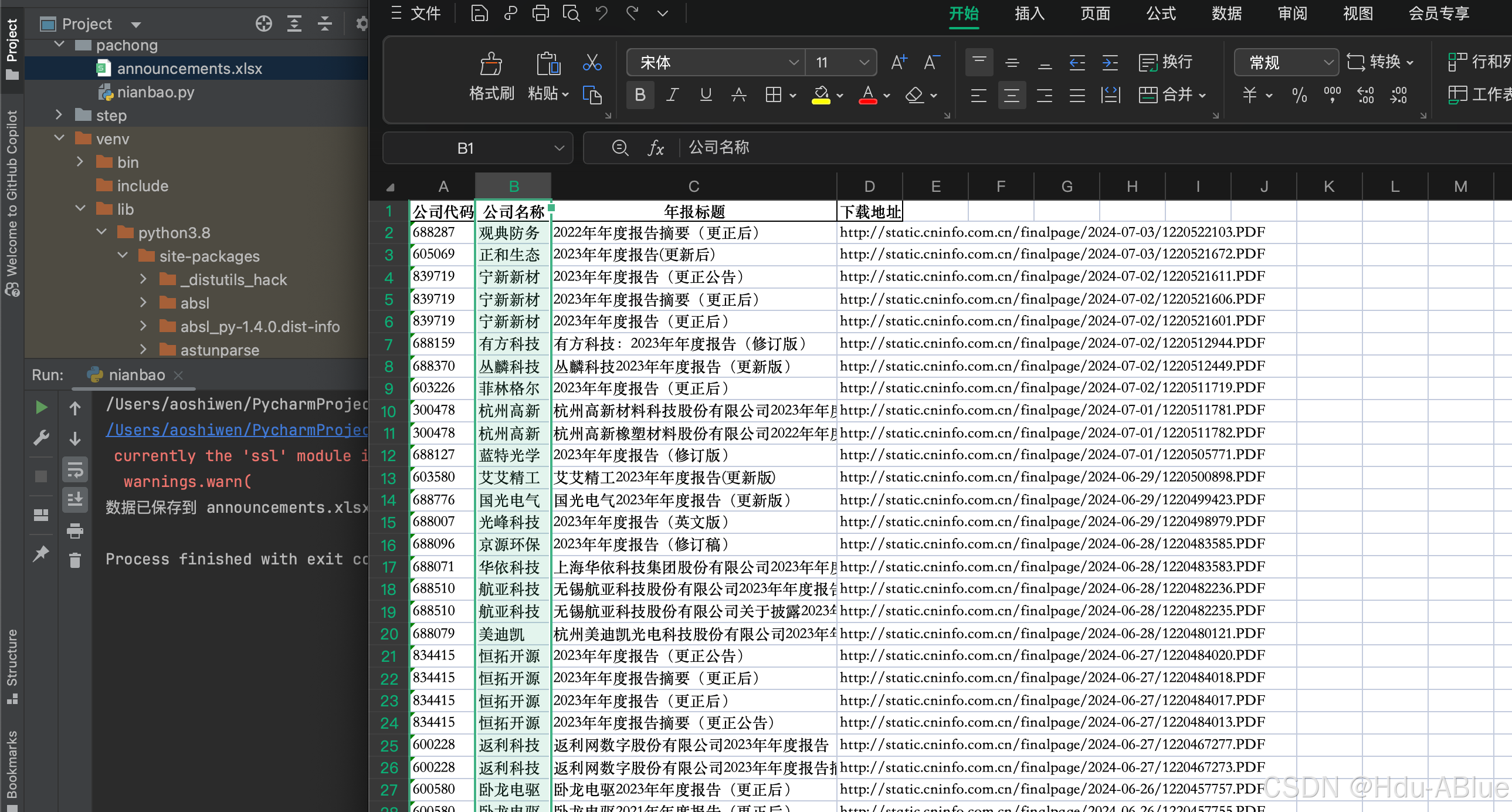
第二步:保存文件
调整代码 使用 panda保存数据可以看到处理后的数据已经保存在excel中
第三步:批量下载pdf
直接上代码
# 下载PDF文件的函数def download_pdf(url, filename): response = requests.get(url) if response.status_code == 200: with open(filename, 'wb') as f: f.write(response.content) print(f"Downloaded: {filename}") else: print(f"Failed to download: {filename}, Status code: {response.status_code}")第四步:处理分页+最终代码
使用请求接口返回的hasMore字段判断是否需要继续加页码,终极版本代码
import requestsimport pandas as pdimport os# 请求头headers = { "accept": "*/*", "accept-language": "zh-CN,zh;q=0.9,en;q=0.8", "content-type": "application/x-www-form-urlencoded; charset=UTF-8", "proxy-connection": "keep-alive", "x-requested-with": "XMLHttpRequest"}# 创建存储PDF文件的文件夹os.makedirs('announcements', exist_ok=True)# 获取公告数据的函数def fetch_announcements(start_date, end_date, page_num=1, page_size=30): url = "http://www.cninfo.com.cn/new/hisAnnouncement/query" body = { "pageNum": page_num, "pageSize": page_size, "column": "szse", "tabName": "fulltext", "plate": "", "stock": "", "searchkey": "", "secid": "", "category": "category_ndbg_szsh", "trade": "", "seDate": f"{start_date}~{end_date}", "sortName": "", "sortType": "", "isHLtitle": "true" } # 发送 POST 请求 response = requests.post(url, headers=headers, data=body) if response.status_code == 200: data = response.json() if 'announcements' in data: announcements_list = [] for announcement in data['announcements']: sec_code = announcement.get("secCode", "") sec_name = announcement.get("secName", "") title = announcement.get("announcementTitle", "") download_url = f"http://static.cninfo.com.cn/{announcement.get('adjunctUrl', '')}" announcements_list.append([sec_code, sec_name, title, download_url]) print(f"Fetched {len(announcements_list)} announcements. hasMore is {data['hasMore']}") return announcements_list, data['hasMore'] else: print("No announcements found.") return [], False else: print(f"Request failed with status code: {response.status_code}") return [], False# 下载PDF文件的函数def download_pdf(url, filename): response = requests.get(url) if response.status_code == 200: with open(filename, 'wb') as f: f.write(response.content) print(f"Downloaded: {filename}") else: print(f"Failed to download: {filename}, Status code: {response.status_code}")# 主函数def main(): start_date = "2024-02-13" end_date = "2024-03-01" page_size = 30 page_num = 1 all_announcements = [] while True: announcements, has_more = fetch_announcements(start_date, end_date, page_num=page_num, page_size=page_size) if announcements: all_announcements.extend(announcements) if not has_more: break page_num += 1 else: break if all_announcements: # 使用 pandas 创建 DataFrame df = pd.DataFrame(all_announcements, columns=["公司代码", "公司名称", "年报标题", "下载地址"]) # 将 DataFrame 保存到 Excel 文件中 df.to_excel("announcements.xlsx", index=False) print("数据已保存到 announcements.xlsx 文件中") # 下载 PDF 文件 for announcement in all_announcements: sec_code, sec_name, title, download_url = announcement title = title.replace("/", "_") filename = f"announcements/{sec_code}_{sec_name}_{title}.pdf" download_pdf(download_url, filename)# 执行主函数if __name__ == "__main__": main()结语
感谢大家阅读这篇关于如何利用 Python 爬取巨潮资讯网上市公司年报数据的教程。通过这篇文章,相信大家已经掌握了基本的爬取流程以及如何处理分页数据和下载 PDF 文件的方法。希望这篇教程能够帮助大家更好地获取所需的数据。
在实际应用中,大家可以根据自己的需求修改代码中的参数,例如调整爬取的时间范围、分页大小等。也可以对代码进行扩展,增加更多的功能,比如数据分析和可视化等。
如果你觉得这篇文章对你有帮助,请不要忘记点赞、收藏和关注。我会不定期分享更多有趣且实用的技术文章。你们的支持是我持续创作的动力!
最后,再次感谢大家的阅读和支持。如果在操作过程中有任何问题,欢迎在评论区留言,我会尽快回复大家。
祝大家在数据爬取和分析的道路上不断进步!
特别提示:请确保在使用爬虫技术时遵守相关法律法规和网站的使用协议,合理合法地进行数据获取。
感谢大家的支持!?