
? 个人主页:谁在夜里看海.
? 个人专栏:《C++系列》《Linux系列》
⛰️ 天高地阔,欲往观之。

目录
前言:对引用的底层理解
一、左值与右值
提问:左值在左,右值在右?
二、左值引用与右值引用
1.提问:右值引用为左值?
2.不能取地址≠没有地址
3.左右值引用的绑定
4.左右值引用的比较
三、右值引用的意义
1.左值引用的使用场景
作为函数参数
作为函数返回值
2.左值引用的局限
3.右值引用和移动语义
前言:对引用的底层理解
在区分左右值引用之前,我先补充一下对引用的理解。
相较于C语言,C++引入了一种语法:引用,我们需要了解的是,为什么C语言没有引用,而C++有呢?
在C语言中,设计者希望语言保持简单并且支持直接操作内存,因此选择使用指针完成数据的传递,通过指针,C语言可以实现对变量的直接访问和修改;
在C++中,引入了更高级抽象机制,引用作为一种高级抽象比指针更安全、易用,并且在实现参数传递和返回值时不需要&、*操作符,更符合直观语义,便于面向对象编程。
引用被看作一种别名,在上层,是变量的别名,但在底层,其实是地址的别名,为什么这么说呢:
在语言层面,int num = 10;表示创建一个int类型的变量num,并初始化为10:
但是跳出高级语言层面,我们来看底层:num并不是什么变量名称,num对应了一个地址,是一个位于进程地址空间栈区的地址;int也不是什么类型,它表示从该地址往后的4字节的空间被进程使用了,要以4字节为一个整体,修改该地址上的内容;而字面常量10呢,用二进制表示00001010,根据辅助对象的不同进行提升或截断,10要赋值给int对象,先被提升成32bit即4字节,存储时将这些字面值从正文代码区拷贝到num对应的栈区地址上。
所以,引用实际上是地址的别名,是与地址建立的一种映射关系,我们可以通过不同的别名访问同一块地址空间,由于引用并不直接接触地址,这使得程序出错的可能性减少,安全性也提高了。
说完了引用,我们来说一下左值右值:
一、左值与右值
左值与右值统称为值类别,它们都是表示数据的表达式,而左右的区分决定了表达式的使用方式,为什么这么说呢?下面来左值右值的特点就知道了:
左值:可以获取地址,并且可以对其赋值。如变量名、数组指针等
int a = 10; // a 是左值,&a 有效a = 15; // 可以对左值进行赋值int arr[5] = {1, 2, 3, 4, 5};arr[2] = 10; // arr[2] 是左值,可以被赋值class MyClass {public: int value;};MyClass obj;obj.value = 5; // obj.value 是左值右值:不可以取地址,也不能对其赋值。如:字面常量、表达式返回值、函数返回值
int x = 5; // 5 是右值,不能取地址std::string("temporary"); // 这是一个右值,不能取地址int y = x + 10; // x + 10 是右值,不能取地址提问:左值在左,右值在右?
左值只能出现在 = 左边,右值只能出现在 = 右边吗?
虽然这种说法很符合左右值取名的定义,但是这种说法是不准确的:
int a = 10;int b = a; // a是左值,但是在=右边// 10 = a; // 报错,左边必须为左值
赋值符号 = 左边必须是左值(右值不行),并且是可修改的左值(const修饰的左值不行)
二、左值引用与右值引用
传统的C++语法中就有引用的语法,而C++11中新增了右值的引用语法特征,下面这些都是左值引用的情况:
int main() { // 以下的p、b、c、*p都是左值int* p = new int(0); int b = 1; const int c = 2; // 以下几个是对上面左值的左值引用int*& rp = p; int& rb = b; const int& rc = c; int& pvalue = *p; return 0; }那右值引用该怎么用呢,我们怎么对字面常量 10 进行引用呢?左值引用是在类型后面加&,右值引用就是在类型后面加&&:
int main(){ double x = 1.1, y = 2.2; // 以下几个都是常见的右值 10; x + y; fmin(x, y); // 以下几个都是对右值的右值引用 int&& rr1 = 10; double&& rr2 = x + y; double&& rr3 = fmin(x, y); // 这里编译会报错:error C2106: “=”: 左操作数必须为左值 10 = 1; x + y = 1; fmin(x, y) = 1; return 0;}1.提问:右值引用为左值?
左值引用是左值吗,右值引用是右值吗?
引用作为表达式的别名,它本身也是一个表达式,所以也有左右值之分,要进行区分,我们对它进行取地址,看看可不可行:
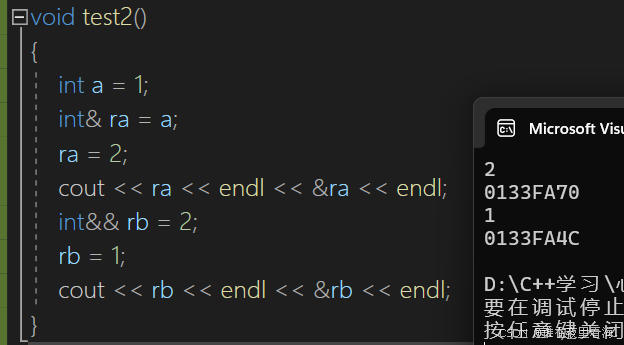
我们发现,ra作为左值引用,rb作为右值引用,它们都可以被取地址并且赋值,说明它们都是左值,这就很奇妙了,左值引用为左值并不奇怪,但是右值引用也是左值,这是为什么呢?
要了解原因,我们就得从左值右值的底层入手:
2.不能取地址≠没有地址
我们知道,字面常量(如 2)作为右值是不能取地址的,也就是&10这种做法是被禁止的,但是右值不能被取地址,就代表它没有地址吗?显然不是:
我们上面提到过,int num = 2; 这段代码被编译后会放到进程空间的正文代码区,那么系统怎么知道你要用2去初始化num呢,因为正文代码区存储了10的二进制序列以及它要放入的地址信息以及把10放入该地址的指令。
回头看这个规则:右值不能被取地址,2有地址吗?当然右,如果没有地址,系统怎么知道初始化的值是2。所以不能取地址不是因为没有地址,而是因为这个地址指向只读数据区,该地址上的数据只有在程序运行后才会被系统读取,由于数据不能被修改,所以编译器禁止取地址操作(取到地址就可以凭借地址对数据进行篡改),于是编译失败。
2的地址是禁止访问的,但是rb作为2的右值引用,却可以进行地址访问,这不应该啊,唯一合理解释就是,右值的引用与右值并不共用一块地址。
3.左右值引用的绑定
左值引用(例如int &ref = a;)确实直接绑定到左值的地址,即原始对象的内存位置。这意味着左值引用和原始对象共享同一个地址:

但是右值引用本身并不是直接对右值地址的引用,而是编译器会分配一个新的存储地址,将右值的值拷贝到该位置。
因此可以作如下区分:
1️⃣左值引用绑定左值的 值+地址
2️⃣右值引用只绑定右值的 值,不绑定地址,额外分配一块地址
4.左右值引用的比较
左值引用:
1.左值引用只能引用左值,不能引用右值。
2.但是const左值既可以引用左值,也可以引用右值
int main(){ // 左值引用只能引用左值,不能引用右值。 int a = 10; int& ra1 = a; // ra为a的别名 //int& ra2 = 10; // 编译失败,因为10是右值 // const左值引用既可引用左值,也可引用右值。 const int& ra3 = 10; const int& ra4 = a; return 0;}右值引用:
1.右值引用只能引用右值,不能引用左值
2.但是右值引用可以引用move以后的左值(move将左值转化成右值)
int main(){ // 右值引用只能右值,不能引用左值。 int&& r1 = 10; // error C2440: “初始化”: 无法从“int”转换为“int &&” // message : 无法将左值绑定到右值引用 int a = 10; int&& r2 = a; // 右值引用可以引用move以后的左值 int&& r3 = std::move(a); return 0;}三、右值引用的意义
右值引用到底有什么意义呢,C++11为什么要推出右值引用这个概念呢?
在右值引用出现之前,只存在左值引用,那么就说明,左值引用存在短板,需要右值引用来补齐。
1.左值引用的使用场景
作为函数参数
我们用对象作为参数传递的时候,使用左值引用可以避免对象的拷贝,在传递较大对象或包含复杂数据结构的对象时,可以显著提高效率,下面用一个自定义string类来演示,出现拷贝构造时会打印信息:
// 拷贝构造string(const string& s):_str(nullptr){cout << "string(const string& s) -- 深拷贝" << endl;string tmp(s._str);swap(tmp);}// 赋值重载string& operator=(const string& s){cout << "string& operator=(string s) -- 深拷贝" << endl;string tmp(s);swap(tmp);return *this;}
可以看到,使用左值引用避免了一次拷贝构造(深拷贝)
作为函数返回值
左值引用也可以作为函数的返回值,从而可以通过函数调用直接操作该变量,比如访问数组元素、链表节点这戏:
#include <iostream>int& getElement(int arr[], int index) { return arr[index]; // 返回数组元素的引用}int main() { int arr[5] = {1, 2, 3, 4, 5}; getElement(arr, 2) = 10; // 修改返回的元素 std::cout << arr[2] << std::endl; // 输出:10 return 0;}但是左值引用作为函数返回值的情况,有一个局限,那就是当函数返回对象是一个局部变量(出了函数作用域就不存在了),就不能使用左值引用返回,只能传值返回。这会有什么影响呢?
2.左值引用的局限
当我们用传值返回的方式返回一个局部对象,例如下面这个函数(将整形转成字符串)
my::string to_string(int value){bool flag = true;if (value < 0){flag = false;value = 0 - value;}my::string str; // 局部变量while (value > 0){int x = value % 10;value /= 10;str += ('0' + x);}if (flag == false){str += '-';}std::reverse(str.begin(), str.end());return str;}int main(){my::string str = to_string(123);}上面这种情况会进行几次拷贝构造?编译器说是一次,但其实是两次,这里是编译器进行优化了:

由于对象作为局部变量在函数结束时就会销毁,所以要想保留对象的内容,就需要一个临时对象来接收(即返回对象ret),此时就会调用一次拷贝构造,将局部变量的内容拷贝到返回对象中,返回对象也只是临时的,它的作用就是在外部需要接收时,再将内容拷贝构造给新的对象,所以总共是发生了两次拷贝构造:

不过现在的编译器会优化成一次拷贝构造,将局部对象直接作为函数临时对象拷贝给接收对象:

无论如何,至少都要进行一次深拷贝,面对较大对象时,会很大程度上影响性能,那么可不可以不多这一次拷贝构造呢,就是将局部对象的内容直接传给外部接收对象,左值引用不能做到的事情,右值引用可以做到。
3.右值引用和移动语义
上述拷贝构造函数的参数都是左值引用,所以我们需要重新定义拷贝构造函数,其参数列表为右值引用。

在左值引用传参的拷贝构造函数中,由于左值引用传递的对象仍然在其他地方使用,所以我们需要定义一个临时对象tmp,开辟一块新的空间,将传入参数的数据安全地拷贝到tmp中,然后通过swap将tmp的内容与this对象进行交换,这种拷贝称为深拷贝。
而在右值引用传参的拷贝构造函数中,由于右值引用传递的对象(例如临时变量)即将销毁,我们可以直接“窃取”其资源,就不用深拷贝了,所以它叫做移动拷贝,将别人的资源转移到自己身上。
// 移动构造string(string&& s):_str(nullptr), _size(0), _capacity(0){cout << "string(string&& s) -- 移动语义" << endl;swap(s);}// 移动赋值string& operator=(string&& s){cout << "string& operator=(string&& s) -- 移动语义" << endl;swap(s);return *this;}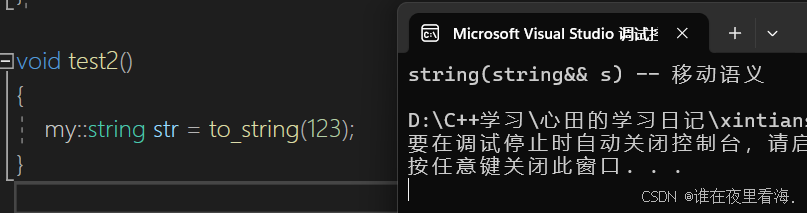
如此一来,大大提升了效率。
以上就是对左值引用与右值引用的介绍与个人理解,欢迎指正~
码文不易,还请多多关注支持,这是我持续创作的最大动力!