完整解决方案(一键复制)代码替换housing = fetch_california_housing()
翻了几条解决方案要么不全,要么收费,烦死个人下面给出完整解决方案!!!
1、下载数据集
原始数据集: cal_housing.tgz
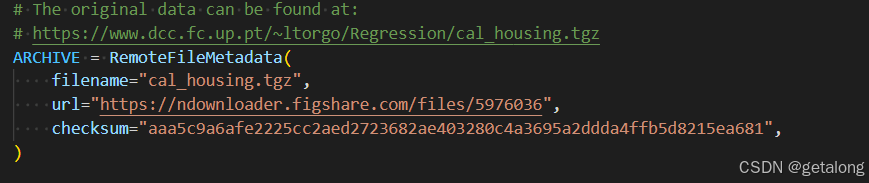
2、放置数据集
查找 本地位置,执行代码后进入目标文件夹。
from sklearn import datasetsdata_home = datasets.get_data_home()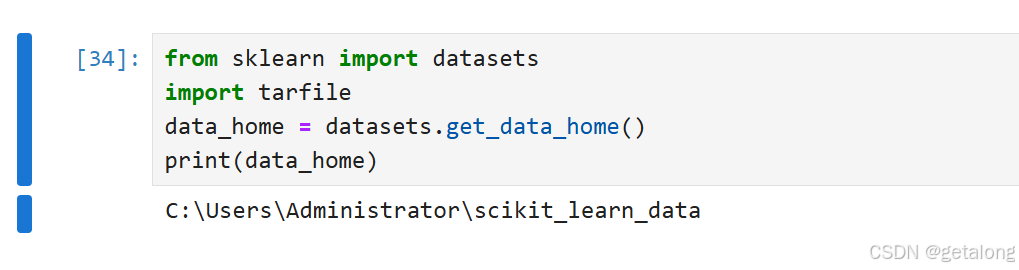
放入下载好的数据压缩包,注意不需要解压缩!!

3、替换代码片段
将
calhous = fetch_california_housing()data = calhous.datatarget = calhous.target替换为
from sklearn import datasetsimport tarfiledata_home = datasets.get_data_home()archive_path = os.path.join(data_home, 'cal_housing.tgz')with tarfile.open(mode="r:gz", name=archive_path) as f: cal_housing = np.loadtxt( f.extractfile("CaliforniaHousing/cal_housing.data"), delimiter="," ) # Columns are not in the same order compared to the previous # URL resource on lib.stat.cmu.edu columns_index = [8, 7, 2, 3, 4, 5, 6, 1, 0] cal_housing = cal_housing[:, columns_index] feature_names = [ "MedInc", "HouseAge", "AveRooms", "AveBedrms", "Population", "AveOccup", "Latitude", "Longitude",]target, data = cal_housing[:, 0], cal_housing[:, 1:]# avg rooms = total rooms / householdsdata[:, 2] /= data[:, 5]# avg bed rooms = total bed rooms / householdsdata[:, 3] /= data[:, 5]# avg occupancy = population / householdsdata[:, 5] = data[:, 4] / data[:, 5]# target in units of 100,000target = target / 100000.0解决!!!
因为粘贴代码时有缩进,手动删除时可能出现缩进不正确的问题,自行加减空格就行了。