【NLP自然语言处理】深入解析Encoder与Decoder模块:结构、作用与深度学习应用

目录
? Encoder模块
1.1 Encoder模块的结构和作用
1.2 关于Encoder Block
1.3 多头自注意力层(self-attention)
? Decoder模块及Add & Norm模块
3.1 Decoder模块介绍
3.2 Add & Norm模块
3.3 位置编码器Positional Encoding
3.4 Decoder端的输入解析
3.4.1 Decoder端的架构
3.4.2 Decoder在训练阶段的输入解析
3.4.3 Decoder在预测阶段的输入解析
? 小结

学习目标
? 掌握Encoder模块的结构和作用
? 掌握Decoder模块的结构和作用
? Encoder模块
1.1 Encoder模块的结构和作用
经典的Transformer结构中的Encoder模块包含6个Encoder Block.每个Encoder Block包含一个多头自注意力层, 和一个前馈全连接层.1.2 关于Encoder Block
在Transformer架构中, 6个一模一样的Encoder Block层层堆叠在一起, 共同组成完整的Encoder, 因此剖析一个Block就可以对整个Encoder的内部结构有清晰的认识.1.3 多头自注意力层(self-attention)
首先来看self-attention的计算规则图:
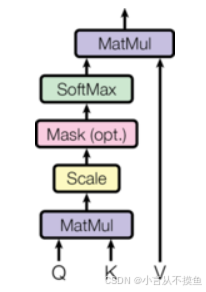
上述attention可以被描述为将query和key-value键值对的一组集合映射到输出, 输出被计算为values的加权和, 其中分配给每个value的权重由query与对应key的相似性函数计算得来. 这种attention的形式被称为Scaled Dot-Product Attention, 对应的数学公式形式如下:
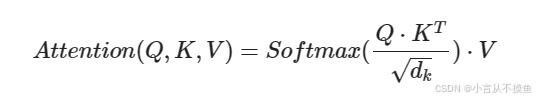
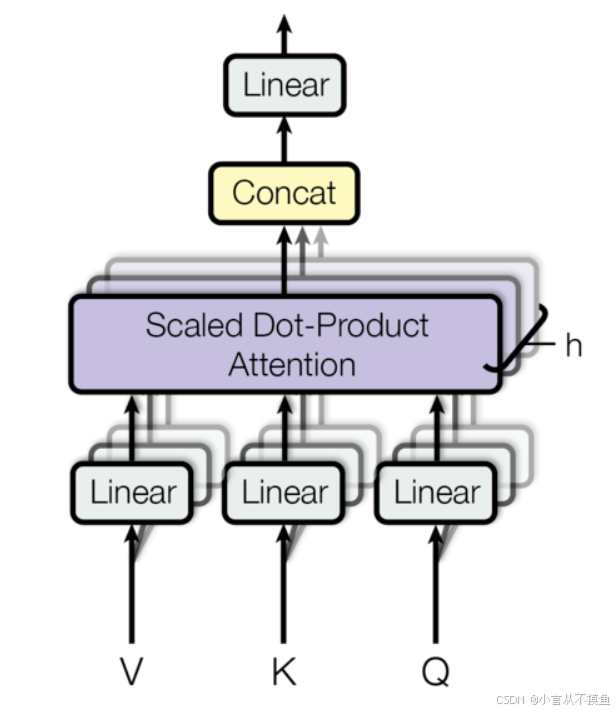
上述的多头self-attention, 对应的数学公式形式如下: $$ MultiHead(Q,K,V)=Concat(head_1,\cdots , head_h)W^O\\ where \; head_i= Attention(QW_{i}{Q},KW_{i}{K},VW_{i}^{V})\\ 其中\; W_{i}^Q \in \Bbb{R}^{d_{model}\times d_k} ,W_{i}^K \in \Bbb{R}^{d_{model}\times d_k} , W_{i}^V \in \Bbb{R}^{d_{model}\times d_v} ,W_{i}^O \in \Bbb{R}^{hd_v\times d_{model}} $$ 多头self-attention层的作用: 实验结果表明, Multi-head可以在更细致的层面上提取不同head的特征, 总体计算量和单一head相同的情况下, 提取特征的效果更佳.
前馈全连接层模块
前馈全连接层模块, 由两个线性变换组成, 中间有一个Relu激活函数, 对应的数学公式形式如下: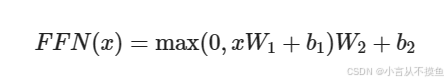
注意: 原版论文中的前馈全连接层, 输入和输出的维度均为d_model = 512, 层内的连接维度d_ff = 2048, 均采用4倍的大小关系.
前馈全连接层的作用: 单纯的多头注意力机制并不足以提取到理想的特征, 因此增加全连接层来提升网络的能力.
? Decoder模块及Add & Norm模块
3.1 Decoder模块介绍
Decoder模块的结构和作用:
经典的Transformer结构中的Decoder模块包含6个Decoder Block.每个Decoder Block包含三个子层. 一个多头self-attention层一个Encoder-Decoder attention层一个前馈全连接层Decoder Block中的多头self-attention层
Decoder中的多头self-attention层与Encoder模块一致, 但需要注意的是Decoder模块的多头self-attention需要做look-ahead-mask, 因为在预测的时候"不能看见未来的信息", 所以要将当前的token和之后的token全部mask.Decoder Block中的Encoder-Decoder attention层
这一层区别于自注意力机制的Q = K = V, 此处矩阵Q来源于Decoder端经过上一个Decoder Block的输出, 而矩阵K, V则来源于Encoder端的输出, 造成了Q != K = V的情况.这样设计是为了让Decoder端的token能够给予Encoder端对应的token更多的关注.Decoder Block中的前馈全连接层
此处的前馈全连接层和Encoder模块中的完全一样.Decoder Block中有2个注意力层的作用: 多头self-attention层是为了拟合Decoder端自身的信息, 而Encoder-Decoder attention层是为了整合Encoder和Decoder的信息.
3.2 Add & Norm模块
Add & Norm模块接在每一个Encoder Block和Decoder Block中的每一个子层的后面. 具体来说Add表示残差连接, Norm表示LayerNorm.
对于每一个Encoder Block, 里面的两个子层后面都有Add & Norm.对于每一个Decoder Block, 里面的三个子层后面都有Add & Norm.具体的数学表达形式为: LayerNorm(x + Sublayer(x)), 其中Sublayer(x)为子层的输出.Add残差连接的作用: 和其他神经网络模型中的残差连接作用一致, 都是为了将信息传递的更深, 增强模型的拟合能力. 试验表明残差连接的确增强了模型的表现.
Norm的作用: 随着网络层数的额增加, 通过多层的计算后参数可能会出现过大, 过小, 方差变大等现象, 这会导致学习过程出现异常, 模型的收敛非常慢. 因此对每一层计算后的数值进行规范化可以提升模型的表现.
3.3 位置编码器Positional Encoding
Transformer中直接采用正弦函数和余弦函数来编码位置信息, 如下图所示:
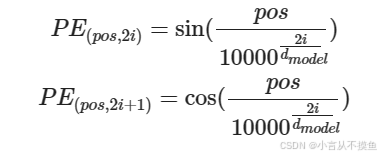
需要注意: 三角函数应用在此处的一个重要的优点, 因为对于任意的PE(pos+k), 都可以表示为PE(pos)的线性函数, 大大方便计算. 而且周期性函数不受序列长度的限制, 也可以增强模型的泛化能力.
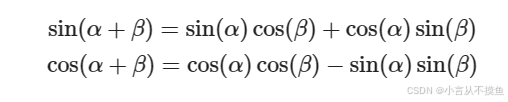
3.4 Decoder端的输入解析
3.4.1 Decoder端的架构
Transformer原始论文中的Decoder模块是由N=6个相同的Decoder Block堆叠而成, 其中每一个Block是由3个子模块构成, 分别是多头self-attention模块, Encoder-Decoder attention模块, 前馈全连接层模块.
6个Block的输入不完全相同: 最下面的一层Block接收的输入是经历了MASK之后的Decoder端的输入 + Encoder端的输出.其他5层Block接收的输入模式一致, 都是前一层Block的输出 + Encoder端的输出.3.4.2 Decoder在训练阶段的输入解析
从第二层Block到第六层Block的输入模式一致, 无需特殊处理, 都是固定操作的循环处理.聚焦在第一层的Block上: 训练阶段每一个time step的输入是上一个time step的输入加上真实标签序列向后移一位. 具体来说, 假设现在的真实标签序列等于"How are you?", 当time step=1时, 输入张量为一个特殊的token, 比如"SOS"; 当time step=2时, 输入张量为"SOS How"; 当time step=3时, 输入张量为"SOS How are", 以此类推...注意: 在真实的代码实现中, 训练阶段不会这样动态输入, 而是一次性的把目标序列全部输入给第一层的Block, 然后通过多头self-attention中的MASK机制对序列进行同样的遮掩即可.3.4.3 Decoder在预测阶段的输入解析
同理于训练阶段, 预测时从第二层Block到第六层Block的输入模式一致, 无需特殊处理, 都是固定操作的循环处理.聚焦在第一层的Block上: 因为每一步的输入都会有Encoder的输出张量, 因此这里不做特殊讨论, 只专注于纯粹从Decoder端接收的输入. 预测阶段每一个time step的输入是从time step=0, input_tensor="SOS"开始, 一直到上一个time step的预测输出的累计拼接张量. 具体来说: 当time step=1时, 输入的input_tensor="SOS", 预测出来的输出值是output_tensor="What";当time step=2时, 输入的input_tensor="SOS What", 预测出来的输出值是output_tensor="is";当time step=3时, 输入的input_tensor="SOS What is", 预测出来的输出值是output_tensor="the";当time step=4时, 输入的input_tensor="SOS What is the", 预测出来的输出值是output_tensor="matter";当time step=5时, 输入的input_tensor="SOS What is the matter", 预测出来的输出值是output_tensor="?";当time step=6时, 输入的input_tensor="SOS What is the matter ?", 预测出来的输出值是output_tensor="EOS", 代表句子的结束符, 说明解码结束, 预测结束.? 小结
Encoder模块
经典的Transformer架构中的Encoder模块包含6个Encoder Block.每个Encoder Block包含两个子模块, 分别是多头自注意力层, 和前馈全连接层. 多头自注意力层采用的是一种Scaled Dot-Product Attention的计算方式, 实验结果表明, Mul ti-head可以在更细致的层面上提取不同head的特征, 比单一head提取特征的效果更佳.前馈全连接层是由两个全连接层组成, 线性变换中间增添一个Relu激活函数, 具体的维度采用4倍关系, 即多头自注意力的d_model=512, 则层内的变换维度d_ff=2048.Decoder模块
经典的Transformer架构中的Decoder模块包含6个Decoder Block.每个Decoder Block包含3个子模块, 分别是多头自注意力层, Encoder-Decoder Attention层, 和前馈全连接层. 多头自注意力层采用和Encoder模块一样的Scaled Dot-Product Attention的计算方式, 最大的 区别在于需要添加look-ahead-mask, 即遮掩"未来的信息".Encoder-Decoder Attention层和上一层多头自注意力层最主要的区别在于Q != K = V, 矩阵Q来源于上一层Decoder Block的输出, 同时K, V来源于Encoder端的输出.前馈全连接层和Encoder中完全一样.Add & Norm模块
Add & Norm模块接在每一个Encoder Block和Decoder Block中的每一个子层的后面.对于每一个Encoder Block, 里面的两个子层后面都有Add & Norm.对于每一个Decoder Block, 里面的三个子层后面都有Add & Norm.Add表示残差连接, 作用是为了将信息无损耗的传递的更深, 来增强模型的拟合能力.Norm表示LayerNorm, 层级别的数值标准化操作, 作用是防止参数过大过小导致的学习过程异常, 模型收敛特别慢的问题.位置编码器Positional Encoding
Transformer中采用三角函数来计算位置编码.因为三角函数是周期性函数, 不受序列长度的限制, 而且这种计算方式可以对序列中不同位置的编码的重要程度同等看待.
在Transformer结构中的Decoder模块的输入, 区分于不同的Block, 最底层的Block输入有其特殊的地方. 第二层到第六层的输入一致, 都是上一层的输出和Encoder的输出.
最底层的Block在训练阶段, 每一个time step的输入是上一个time step的输入加上真实标签序列向后移一位. 具体来看, 就是每一个time step的输入序列会越来越长, 不断的将之前的输入融合进来.
最底层的Block在训练阶段, 真实的代码实现中, 采用的是MASK机制来模拟输入序列不断添加的过程.
最底层的Block在预测阶段, 每一个time step的输入是从time step=0开始, 一直到上一个time step的预测值的累积拼接张量. 具体来看, 也是随着每一个time step的输入序列会越来越长. 相比于训练阶段最大的不同是这里不断拼接进来的token是每一个time step的预测值, 而不是训练阶段每一个time step取得的groud truth值.

?若能为您的学习之旅添一丝光亮,不胜荣幸?
?期待您的宝贵意见,让我们共同进步共同成长?
登录后可发表评论
点击登录