目录
一、什么是 SimpleQA?二、SimpleQA 的多元化与校准功能三、SimpleQA 的三大特点1、设置简单到爆2、挑战性大,前沿模型也跪了3、参考答案经得起时间考验 四、SimpleQA 的构建过程五、如何使用 SimpleQA 比较大模型?六、SimpleQA 的其他用途七、SimpleQA 的限制八、结语最后回顾一下OpenAI近期的重磅更新模型众多,该如何选择?[如何直接使用ChatGPT4o、o1、OpenAI Canvas](https://www.nezhasoft.cn/)
10月31日凌晨,OpenAI 宣布,为了衡量语言模型的准确性,将开源一个名为 SimpleQA 的新基准,可衡量语言模型回答简短的事实寻求(fact-seeking)问题的能力。
在人工智能的奇妙世界里,AI 大模型时常“一本正经地胡说八道”,这可让 OpenAI 感到头疼。为了解决这一顽疾,他们推出了一款新武器——SimpleQA,这是一款全新的开源基准测试工具,专门用来检测大模型在回答事实性问题时的准确性。
OpenAI 的研究科学家 Jason Wei 指出,之前缺乏有效的事实性基准测试,促使团队自己动手,创建一个简单、可靠、易用的评估工具,以便所有 AI 研究人员都能使用。

一、什么是 SimpleQA?
在数据收集阶段,SimpleQA 的问题和参考答案由两名独立的 AI 训练员确定。训练员在创建问题时还需提供支持答案的网页链接,以确保答案的可靠性。例如,针对“谁是苹果公司的创始人之一”这一常识性问题,训练员会根据历史资料和官方信息确认答案为“史蒂夫·乔布斯”,并附上如苹果公司官方网站等相关链接。
问题设计上,SimpleQA 确保每个问题仅有一个明确且无可争议的答案,避免模糊和歧义。例如,“哪一年 iPhone 首次发布?”这个问题的答案清晰明确为“2007 年”。此外,SimpleQA 的评估问题和答案非常简短,使得运行速度快,操作简单。使用 OpenAI API 进行评分时也相当迅速。
数据集中包含 4326 个问题,这大大降低了不同次运行之间的方差,使评估结果更加稳定可靠。这样,在对多个模型进行测试时,不会因为数据集的不稳定性导致结果波动,从而能够更准确地比较模型之间的性能差异。
二、SimpleQA 的多元化与校准功能
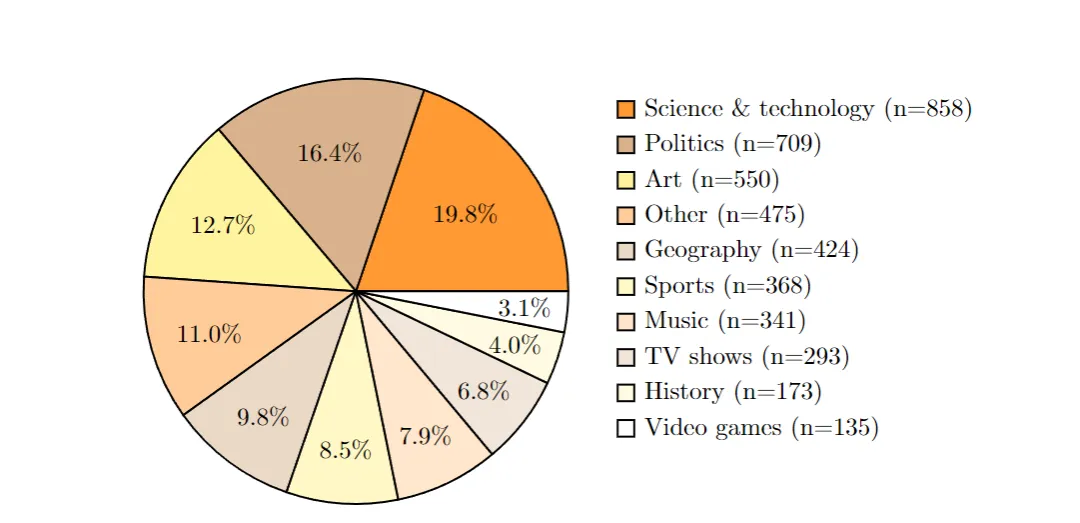
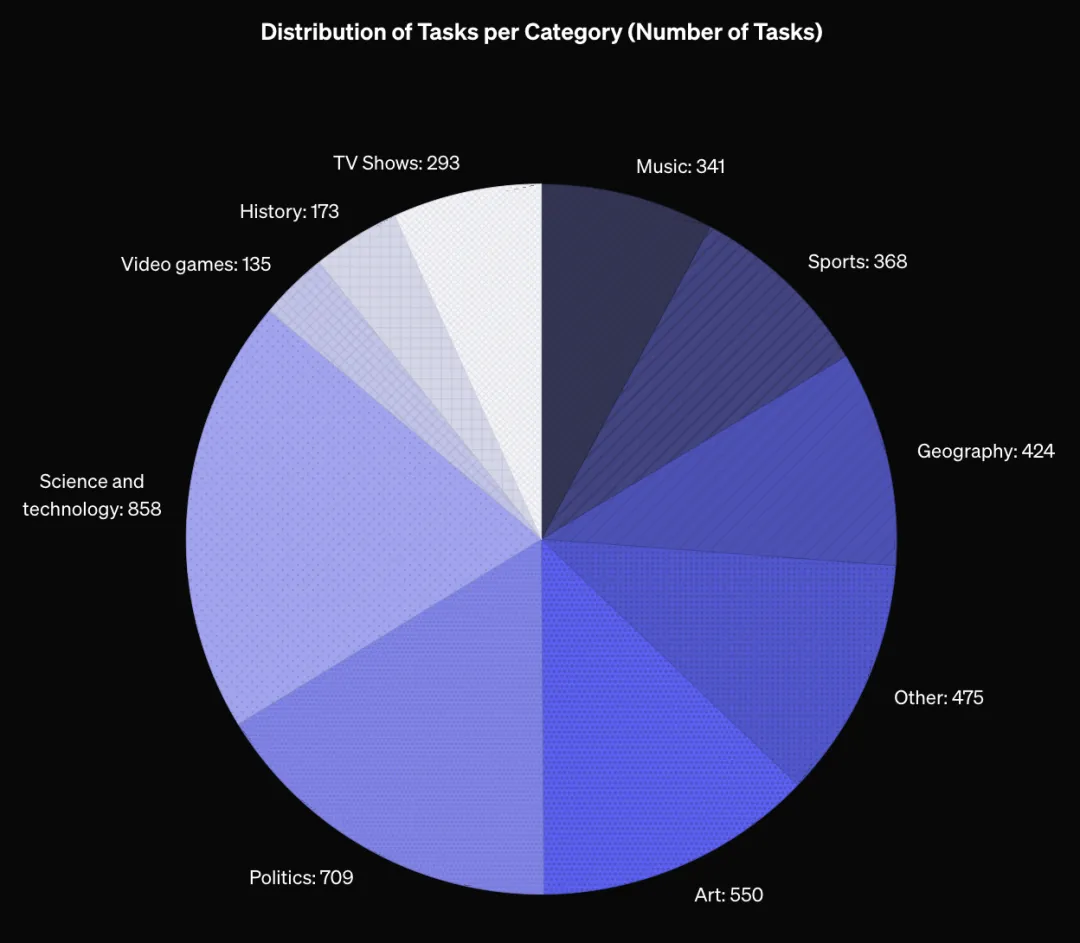
SimpleQA 的评估集涵盖历史、科学技术、艺术、地理、电视节目等多个领域。这种多样性使得评估结果更具普遍性和代表性,能够全面检验模型在不同知识领域的事实性回答能力。更重要的是,SimpleQA 具备校准测量功能,研究者可以询问模型对其答案的信心,从而了解模型是否真正了解自己知道什么。如果一个模型能准确评估自己的信心水平,那它就是一个经过良好校准的模型。
OpenAI 通过 SimpleQA 对多个前沿模型进行了综合测试,包括 GPT-4o、o1-preview 和 Claude-3 等。结果显示,较大模型通常具有更高的性能,但即使是这些前沿模型在 SimpleQA 上的表现也并非完美。
三、SimpleQA 的三大特点
1、设置简单到爆
SimpleQA 包含 4000 道由人类编写、清晰无歧义的事实性问题,每个问题都只有一个无可争议的正确答案。模型的回答会被自动评分器评为“正确”、“错误”或“未尝试”。
2、挑战性大,前沿模型也跪了
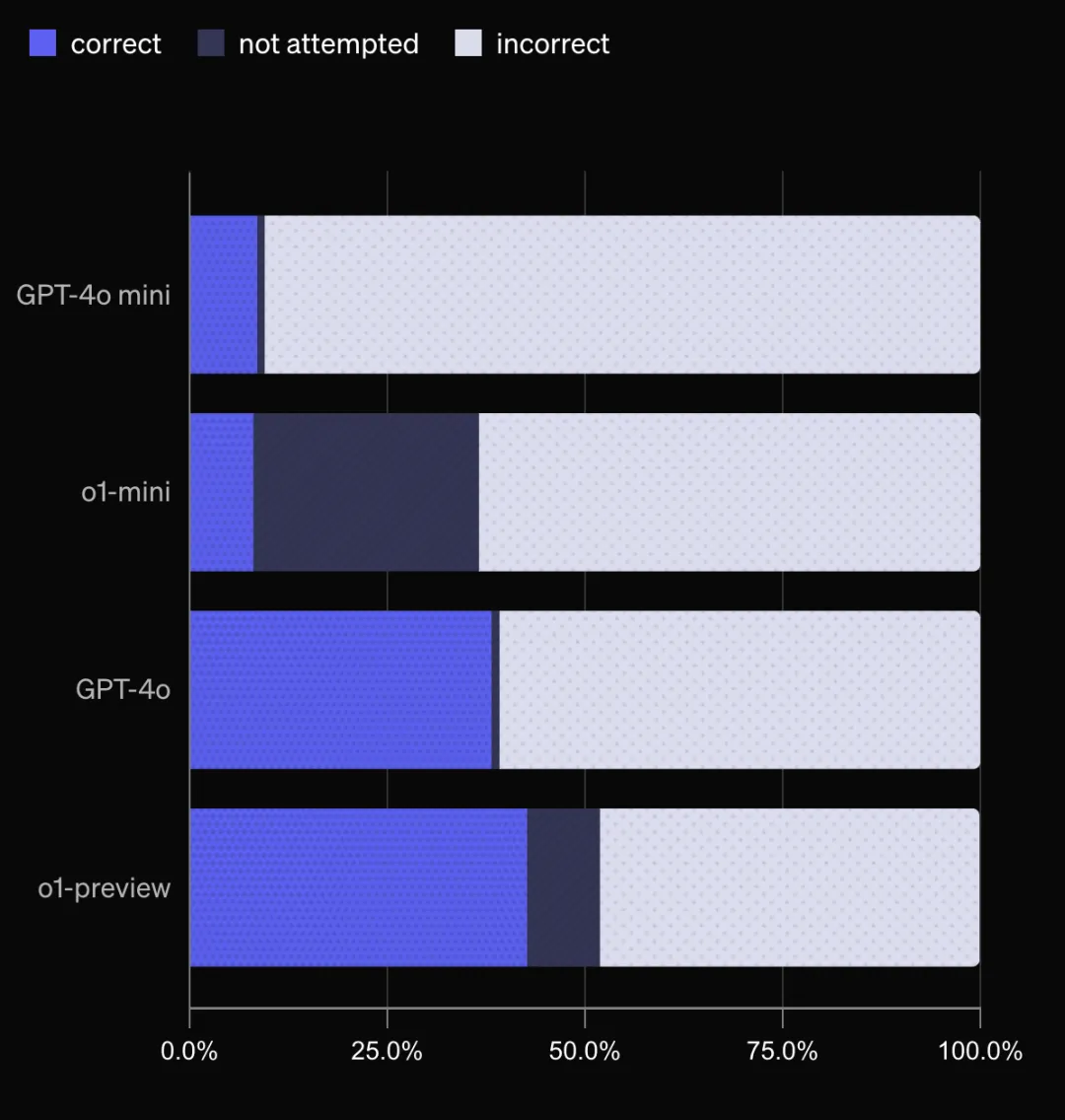
SimpleQA 对目前最先进的大模型构成了巨大挑战!连 o1-preview 和 Claude Sonnet 3.5 的准确率都不足 50%!
3、参考答案经得起时间考验
所有问题都经过精心设计,参考答案由两位独立标注员验证,确保准确可靠。即使在 5 年或 10 年后,SimpleQA 仍然是一个有用的基准测试,相当耐用!
四、SimpleQA 的构建过程
OpenAI 聘请了 AI 训练师从网上收集问题和答案,并制定严格标准:答案必须唯一、准确、不会随时间变化,且大多数问题能诱导 GPT-4o 或 GPT-3.5 产生“幻觉”。为保证质量,第二位 AI 训练师独立回答每个问题,只有两位训练师的答案一致时,问题才会被收录。最后,还有第三位训练师对 1000 个随机问题进行验证,最终估算出数据集的固有错误率约为 3%。
五、如何使用 SimpleQA 比较大模型?
使用经过 prompt 的 ChatGPT 分类器对模型的答案进行评分,分为“正确”、“错误”和“未尝试”三种。目标是尽可能多地正确回答问题,同时最小化错误答案的数量。测试结果显示,o1-preview 效果最佳,而小模型的正确率相对较低,这可能是因为其知识储备不足。
六、SimpleQA 的其他用途
除了评估事实性,SimpleQA 还可以用来测量大模型的校准程度,即模型“知之为知之,不知为不知”的能力。通过让模型给出答案的同时给出置信度,并比较置信度与实际准确率之间的关系,就能评估模型的校准程度。结果显示,模型普遍高估了自己的信心,o1-preview 在这方面的校准程度优于 o1-mini,GPT-4 的校准程度也优于 GPT-4-mini,这与先前的研究一致。
七、SimpleQA 的限制
尽管 SimpleQA 是评估前沿模型事实性的一个简单但具有挑战性的基准,它的主要局限性在于其范围。虽然 SimpleQA 非常准确,但它只在具有单一可验证答案的简短事实查询中测量事实性。这意味着在评估符合事实的简短回答的能力是否与撰写包含大量事实的冗长回答的能力相关,仍是一个待解决的问题。
OpenAI 表示,目标是使用 SimpleQA 创建一个高正确性、多样性且具前沿挑战性的数据集。与早期基准相比,如 TriviaQA(2017 年)或 NQ(2019 年),SimpleQA 在挑战性上更胜一筹,尤其针对如 GPT-4o 等前沿模型(其得分不足 40%)。
八、结语
总之,SimpleQA 是一款简便而有效的工具,它为 AI 研究提供了新的可能性。随着它的开源,OpenAI 希望能进一步推动 AI 研究的发展,使模型更加可信、可靠。在这场 AI 的竞争中,SimpleQA 无疑是一个不可或缺的新利器,期待它能帮助我们更好地理解和评估 AI 的能力!
最后回顾一下OpenAI近期的重磅更新
5月14日,OpenAI GPT-4o横空出世,GPT-4o(“o”代表“全能”)它可以接受任意组合的文本、音频和图像作为输入,并生成任意组合的文本、音频和图像输出。
9月12日,OpenAI更新了o1-preview和o1-mini模型,主打推理能力,号称能解决比以往模型更难的科学、编程和数学问题!
9月25日,OpenAI推出高级语音功能,并且还增加了多种不同风格的声线,东北话、粤语、四川话,上海话、北京话,重庆话统统不在话下,更别提英语、日语、法语等国际语言了,还能设定自定义指令和记忆功能。
10月3日,OpenAI Canvas正式发布,官方的定义是:Canvas 是一个全新的界面,旨在帮助用户与 ChatGPT 在写作和编码方面进行更紧密的协作。
模型众多,该如何选择?
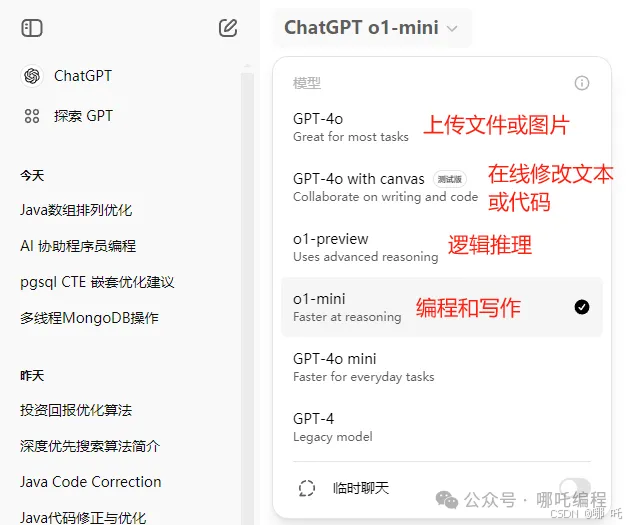
ChatGPT4o:目前最稳定、使用次数最多的版本,24小时300次,可以上传文件或图片,其它模型不支持上传文件。
o1-preview:预览版模型,功能相对较少,但逻辑推理能力强大。
o1-mini:特别擅长编程和写作,目前最强模型。
Canvas:新增了类似 Claude 的 Artifacts 右侧预览功能,可以在线编辑文本、代码。
如何直接使用ChatGPT4o、o1、OpenAI Canvas
GPT-4o知识问答:已同步最新ChatGPT o1、OpenAI Canvas最强代码大模型Code Copilot:代码自动补全、代码优化建议、代码重构等DALL-E AI绘画:AI绘画 + 剪辑 = 自媒体新时代私信哪吒,备注ai,直接使用GPT-4o✅️谷歌浏览器直接访问
ChatGPT:www.nezhasoft.cn