
欢迎关注个人主页:逸狼
创造不易,可以点点赞吗~
如有错误,欢迎指出~
目录
网络层 => IP协议
IP协议报头结构
4位版本
4位首部长度
8位服务类型(TOS)
16位总长度(字节数), 16位标识
3位标志位
13位片偏移
8位生存时间(TTL)
8位协议
16位首部检验和
32位源IP地址/32位目的IP地址
关于IP地址
特殊的IP地址
主机号 全为0(二进制)
主机号全为1(二进制)
127.* 环回IP
解决IP地址不够用的问题
方案一:动态分配IP地址
方案二:NAT网络地址转换
NAT网络地址转换
NAT机制的缺点
方案三:IPv6
网络层 => IP协议
在复杂的⽹络环境中确定⼀个合适的路径.
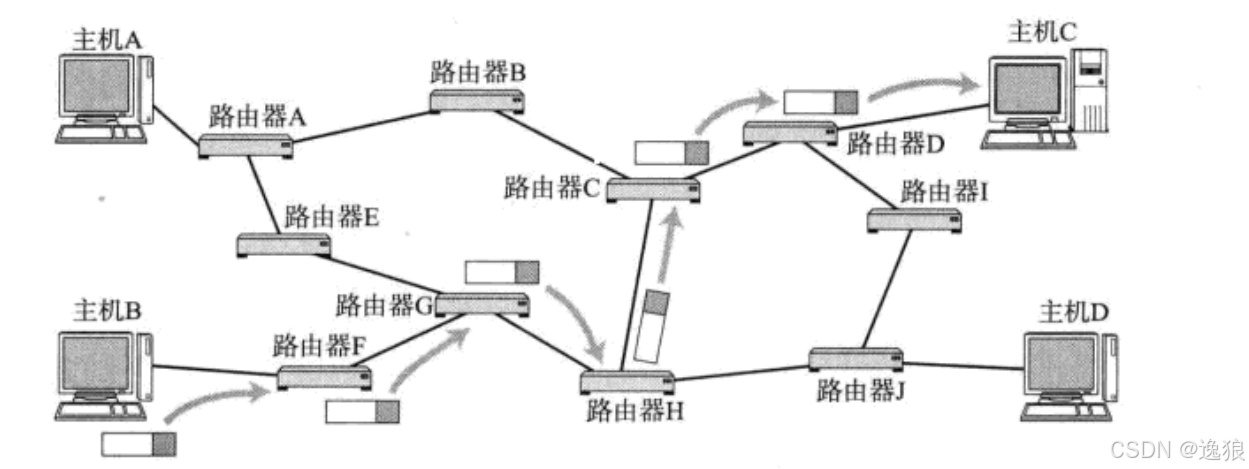
IP协议和普通的程序员联系比较浅,除了专门开发网络设备的程序员(开发路由器,交换机,防火墙....)
IP协议主要涉及地址管理
地址管理=>IP地址
路由选择=>数据报传输的路径进行规划
IP协议报头结构

4位版本
实际上只有两个取值
4 ->IPv4(主流)6 ->IPv64位首部长度
IP协议报头也是变长的,取值范围:0~15
实际上报头长度要*4
如4位首部长度取值15时,报头长度就是15*4
8位服务类型(TOS)
8位服务类型(TypeOfService)包括 3位优先权字段(已经弃⽤),4位TOS字段,和1位保留字段(必须置为 0).
4位TOS分别表⽰:最⼩延时,最⼤吞吐量,最⾼可靠性,最⼩成本.这四者相互冲突,只能选择⼀个.(对于ssh/telnet这样的应⽤程序,最⼩延时⽐较重要;对于ftp这样的程序,最⼤吞吐量⽐较重要.)
最小延时:数据从A到B的时间消耗最短最大吞吐量:数据从A到B单位时间内,传输的数据量最多最高可靠性->IP协议不像TCP那样有严格的可靠性,IP一些机制也会影响到丢包的概率,利用这些机制减少丢包率,增加可靠性最小成本:设备上消耗的资源较小16位总长度(字节数), 16位标识
16位总长度(字节数) 是IP数据报的长度16位标识 用于区分是否是同一个数据包IP协议内置了拆包和组包机制,单个IP数据报确实没法超过64KB,但是IP可以自动把大的数据包拆成多个IP数据报携带传输,在接收方再进行拼装.
此时,多个IP数据报的16位标识是相同数值
3位标志位
3位标志位只有两个有效,剩下一个是保留位
其中一个 表示这个包是否需要组包(是否是拆包的一部分)另一个表示当前包是否是组包中的最后一个单位13位片偏移
13位片偏移决定组包时数据包的位置(解决后发先至问题)
8位生存时间(TTL)
TTL决定了一个数据包在网络中最多存活多长时间,单位是 "次数"(指经过路由器转发的次数)
假设构造一个数据报,目的IP写错了,如果让这个数据报无线传输,就会消耗很多的网络资源,TTL约定了传输时间的上限,达到上限之后,数据报就会自动被丢弃掉
发送一个IP数据报时,会有一个初始的TTL的值(32,64,128...),数据报每经过一个路由器转发(经过交换机不减),TTL就会-1,一旦TTL减到0,此时这个数据包就会被当前路由器直接丢弃掉
在正常情况下,TTL=64是非常富裕的.
8位协议
通过8位协议中不同的数值 感知到接下来要把数据交给TCP解析还是UDP解析,还是其他协议解析(类似于TCP/UDP报头中的端口)
16位首部检验和
验证数据在传输过程中是否出错(只是针对首部,IP报头),载荷部分TCP/UDP都有自己的校验和了
32位源IP地址/32位目的IP地址
IP数据包中最关键的信息,描述了数据报从哪里来,到哪里去
IP地址是 32位的整数,不方便人进行阅读理解,通过将IP地址写成"点分十进制"的形式方便人们阅读,把32位(4字节)通过3个圆点分割开,每一个部分是一个字节,范围0-255
关于IP地址
IP地址32位,左半部分是网络号,右半部分是 主机号,需要通过"子网掩码"区分出哪里是网络号,哪里是主机号
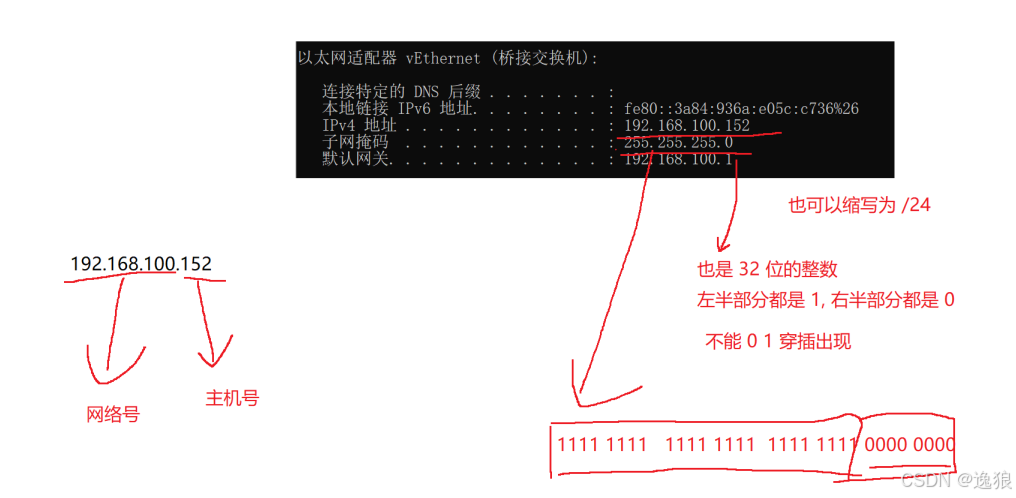
网络中规定:
同一个局域网中的设备,网络号必须相同,主机号必须不同;两个相邻的局域网,网络号必须不同特殊的IP地址
主机号 全为0(二进制)
这个IP表示当前网段(相当于网络号),因此,给局域网中的某个设备分配IP地址时,不能把主机号设为全0
主机号全为1(二进制)
这个表示 广播IP,往这个IP地址发送数据包,相当于给整个局域网中所有设备都发了一次数据包
很多看到的"业务上的广播"都是通过应用层编写代码来实现的,而不是借助广播IP
广播IP应用场景 举例:手机投屏 ,手机触发投屏按钮时,往对应的广播IP发送一个数据包(UDP)(TCP不支持广播,只能一对一),如果收到这个数据包的设备不具有投屏功能,就不吱声;反之,就会返回一个响应 (设备是什么,IP是多少)
127.* 环回IP
自发自收,给这个IP发一个数据包,设备就会从这个IP上再收到同一个数据
环回IP一般用于测试,写的网络程序大多情况都是为了跨主机通信,往往需要先自行测试,一台主机测试客户端和服务器之间能否正常交互,一般使用的环回IP时127.0.0.1,其他的比较少见
解决IP地址不够用的问题
32位表示的数据范围是0~42亿9千万,但是放到现如今移动互联网时代,人手一部手机,甚至好几部,可能就不够用了
方案一:动态分配IP地址
一个设备上网就分配IP地址,不上网就先不分配
方案二:NAT网络地址转换
使用一个IP代表一大波设备
把IP地址分为两大类,要求公网IP必须是唯一的,但是私网IP允许重复(在不同的局域网中允许重复)
内网IP/私网IP外网IP/公网IPNAT网络地址转换
同一个局域网内,主机A访问主机B,不会涉及到NAT机制公网上的设备A,访问公网上的设备B,不会涉及到NAT机制一个局域网中的主机A,访问另一个局域网中的主机B,NAT机制中是不允许的局域网内部的设备A,访问公网中的设备B,NAT机制主要就是针对这个情况进行生效一个公网IP服务于一个片区,上万个设备
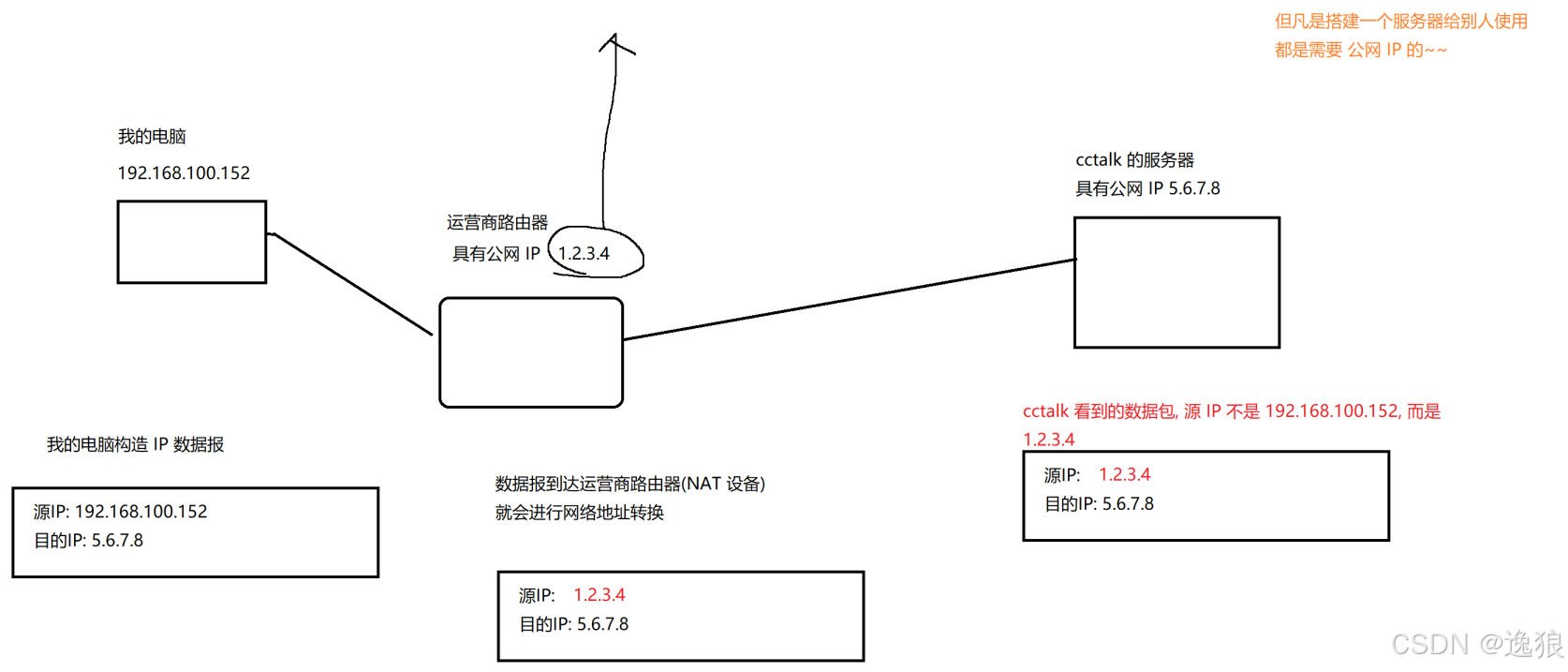
发送数据时,"我的电脑" 的源IP会在运营商路由器进行 网络地址转换.
日常上网的设备,其实大部分都是在不同的局域网中,相当于一个公网IP就可以代表一大批设备
返回数据响应时,cctalk会在运营商路由器中将目的IP转换位局域网中"我的电脑"的源IP
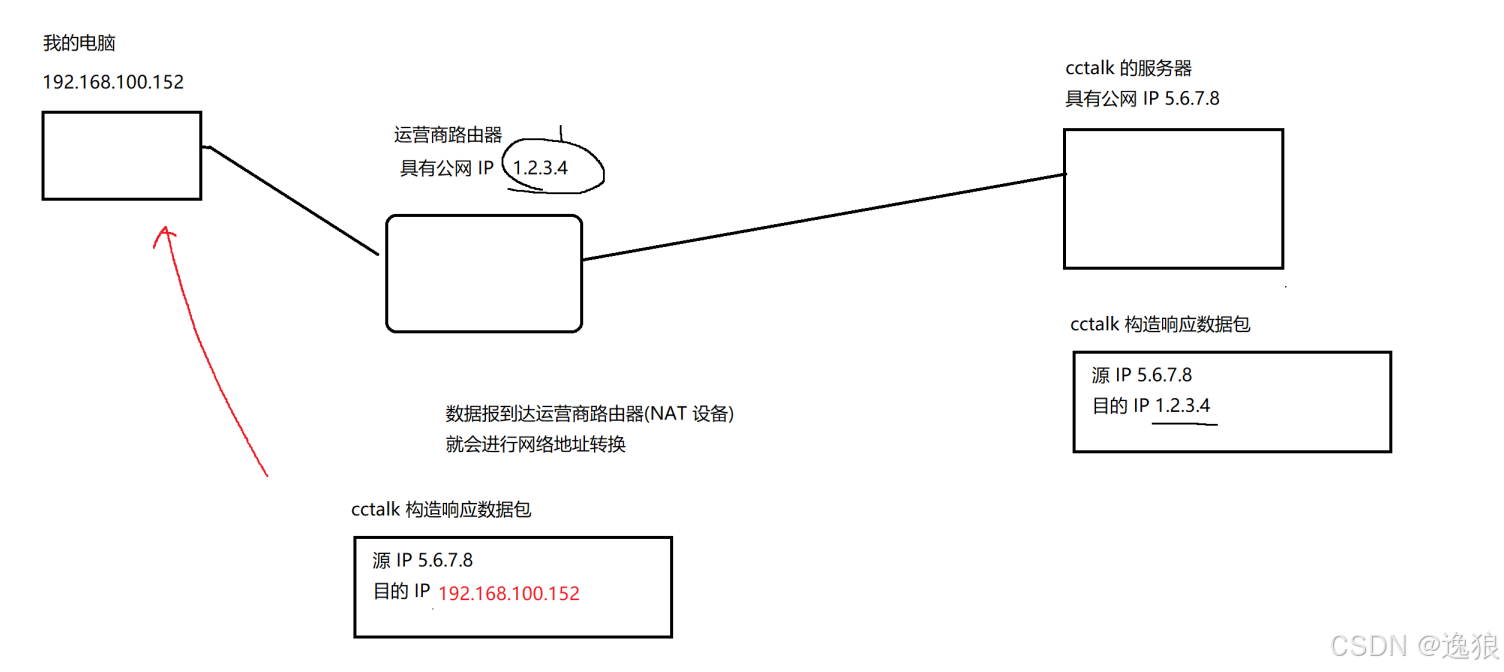
在网络通信中,不仅仅只有IP信息,还有一个关键的是 端口号,端口号本来是区分同一个主机上的不同应用程序的, 在NAT中,端口号就可以用来区分不同主机上的不同的应用程序(端口号是随机分配的空闲端口,出现相同的概率非常小)
运营商路由器在进行IP替换时,会记录这层映射关系
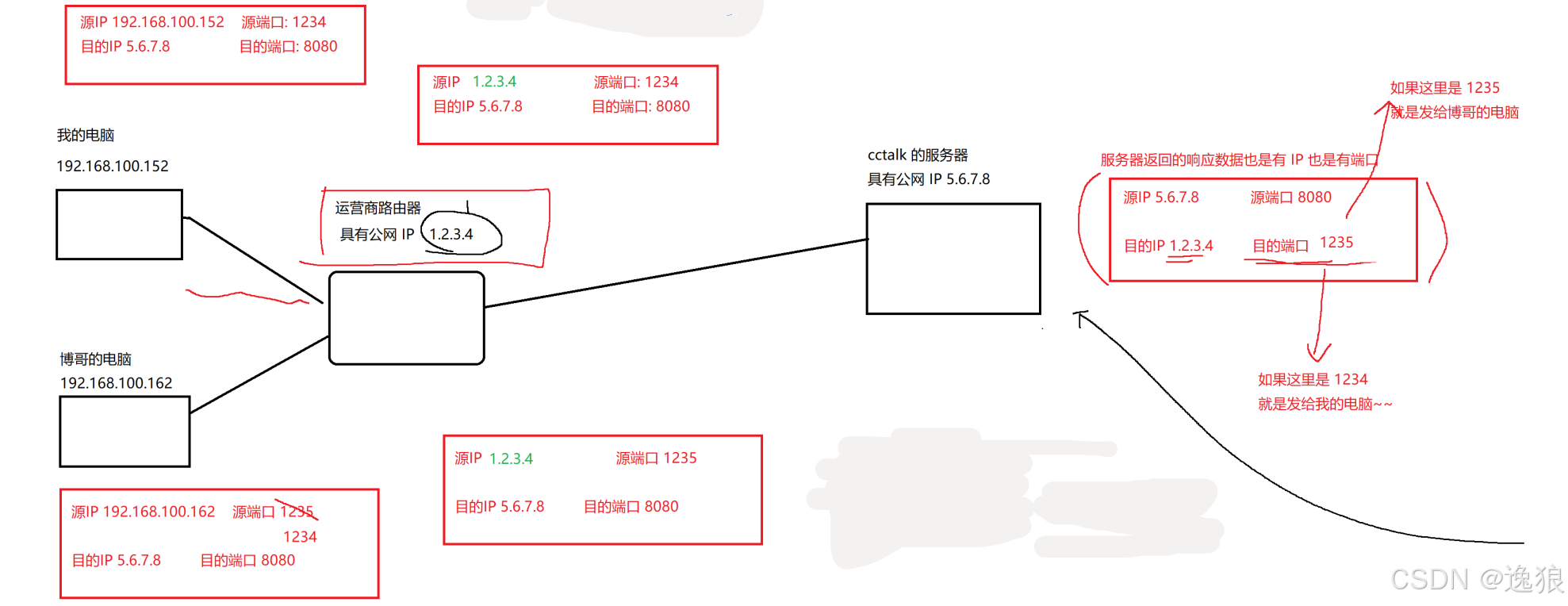
NAT机制的缺点
网络环境太复杂了,替换过程中,每一层路由器都需要维护映射关系,每次转发数据,都需要查询映射关系,都是开销
方案三:IPv6
IPv6从根本上解决了IP地址不够用的问题
IPv6使用128位(16字节)表示IP地址,空间非常大(可以给地球上每一粒沙子都分配一个唯一的IPv6地址)
IPv6提出的时间是上个世纪90年代,时间和NAT其实差不多,IPv6与IPv4不兼容,想使用IPv6,就需要更换新的设备(能支持IPv6的设备),所以推广IPv6 举步维艰, NAT机制只要给路由器设备升级软件即可,硬件不需要改变(成本非常低). IPv6在国内普及程度非常高了,超过了70%
