昇腾AI处理器的计算核心 - AI Core即DaVinci Core
flyfish
从一段代码的解释开始
template <typename T>class GlobalTensor {public: void setGlobalBuffer(T* buffer, uint32_t buffersize) { // 在这里实现设置全局缓冲区的逻辑 }};语法的说明,主要用于理解上面的代码,非内部实现
template <typename T>:
这是模板声明。它告诉编译器接下来定义的类或函数是一个模板,T 是一个类型参数。typename 是一个关键字,表示 T 是一种类型。
class GlobalTensor:
这是定义模板类 GlobalTensor,GlobalTensor 是一个通用类,其内部数据类型由模板参数 T 指定。
通过模板,GlobalTensor 类可以处理不同类型的数据,而无需为每种数据类型编写单独的类。例如,可以创建 GlobalTensor<int> 来处理整数类型的全局数据,或者创建 GlobalTensor<float> 来处理浮点数类型的全局数据。
#include <iostream>// 定义模板类 GlobalTensortemplate <typename T>class GlobalTensor {public: // 设置全局缓冲区的方法 void setGlobalBuffer(T* buffer, uint32_t buffersize) { this->buffer = buffer; this->buffersize = buffersize; } // 打印缓冲区中的内容 void printBuffer() const { for (uint32_t i = 0; i < buffersize; ++i) { std::cout << buffer[i] << " "; } std::cout << std::endl; }private: T* buffer; // 指向缓冲区的指针 uint32_t buffersize; // 缓冲区的大小,元素的个数};int main() { // 创建一个int类型的缓冲区 int intBuffer[] = {1, 2, 3, 4, 5}; uint32_t intBufferSize = 5;//sizeof(intBuffer) / sizeof(intBuffer[0]); std::cout << sizeof(intBuffer)<<":" <<sizeof(intBuffer[0]) <<std::endl; // 创建一个GlobalTensor<int>实例 GlobalTensor<int> intTensor; intTensor.setGlobalBuffer(intBuffer, intBufferSize); std::cout << "Integer buffer: "; intTensor.printBuffer(); // 创建一个float类型的缓冲区 float floatBuffer[] = {1.1f, 2.2f, 3.3f, 4.4f, 5.5f}; uint32_t floatBufferSize = 5;//sizeof(floatBuffer) / sizeof(floatBuffer[0]); // 创建一个GlobalTensor<float>实例 GlobalTensor<float> floatTensor; floatTensor.setGlobalBuffer(floatBuffer, floatBufferSize); std::cout << "Float buffer: "; floatTensor.printBuffer(); return 0;}输出
20:4Integer buffer: 1 2 3 4 5Float buffer: 1.1 2.2 3.3 4.4 5.5语法解释
sizeof(intBuffer) / sizeof(intBuffer[0]) 和 sizeof(floatBuffer) / sizeof(floatBuffer[0]) 这两个表达式确实表示的是缓冲区(数组)中元素的个数。
sizeof(intBuffer):计算整个 intBuffer 数组的总大小(以字节为单位)。
假设 intBuffer 是一个包含 5 个 int 元素的数组,每个 int 占用 4 个字节,那么 sizeof(intBuffer) 就是 5 * 4 = 20 字节。
sizeof(intBuffer[0]):计算数组中第一个元素的大小,也就是 int 类型的大小(在大多数系统中是 4 字节)。
sizeof(intBuffer) / sizeof(intBuffer[0]):用数组的总大小除以单个元素的大小,得到数组中元素的个数。
对于上述例子,计算过程为 20 / 4 = 5,所以这个表达式的结果就是 5,也就是数组中的元素个数。
昇腾 AI Core 架构
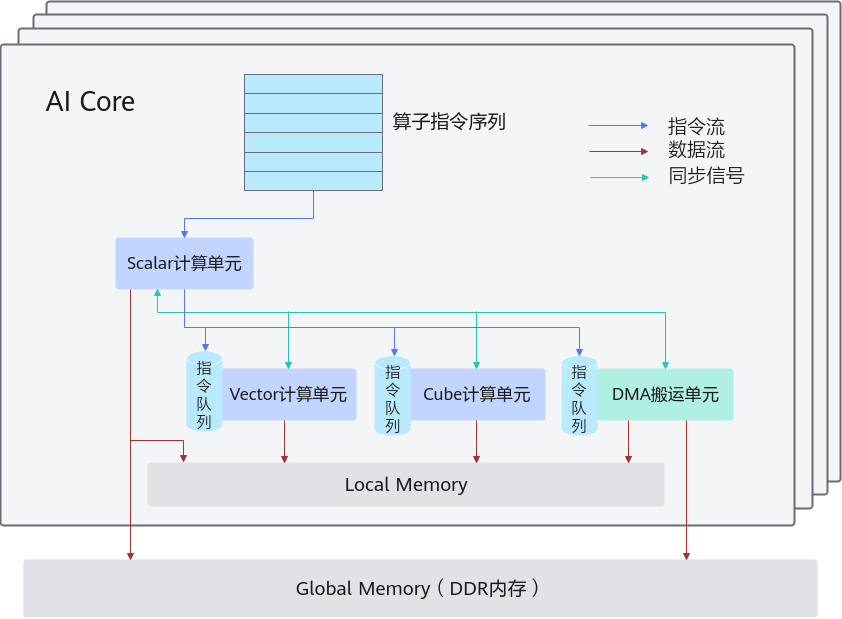
不同于传统的支持通用计算的CPU和GPU,也不同于专用于某种特定算法的专用芯片ASIC(Application Specific Integrated Circuit),AI Core架构本质上是为了适应某个特定领域中的常见应用和算法,通常称为“特定域架构”(Domain Specific Architecture,DSA)。因为不一样所有就起了新的名字 达芬奇。
Al Core内部并行计算架构抽象
使用Ascend C编程语言开发的算子运行在AICore上,AI Core是昇腾AI处理器中的计算核心一个AI处理器内部有多个AICore,AICore中包含计算单元、存储单元、搬运单元等核心组件
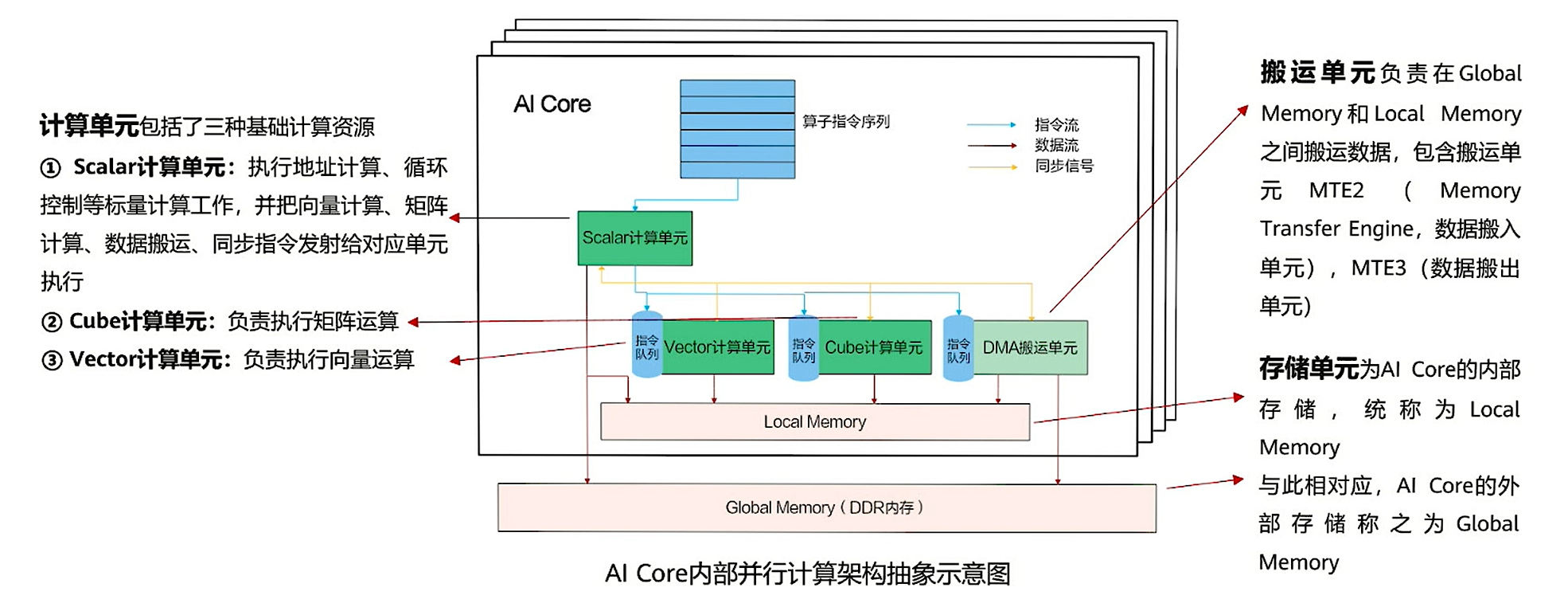
昇腾AI处理器的计算核心主要由AI Core构成,从控制上可以看成是一个相对简化的现代微处理器的基本架构。它包括了三种基础计算资源:。这三种计算单元各司其职,形成了三条独立的执行流水线,在系统软件的统一调度下互相配合达到优化的计算效率。此外在矩阵计算单元和向量计算单元内部还提供了不同精度、不同类型的计算模式。
AI Core内部核心组件
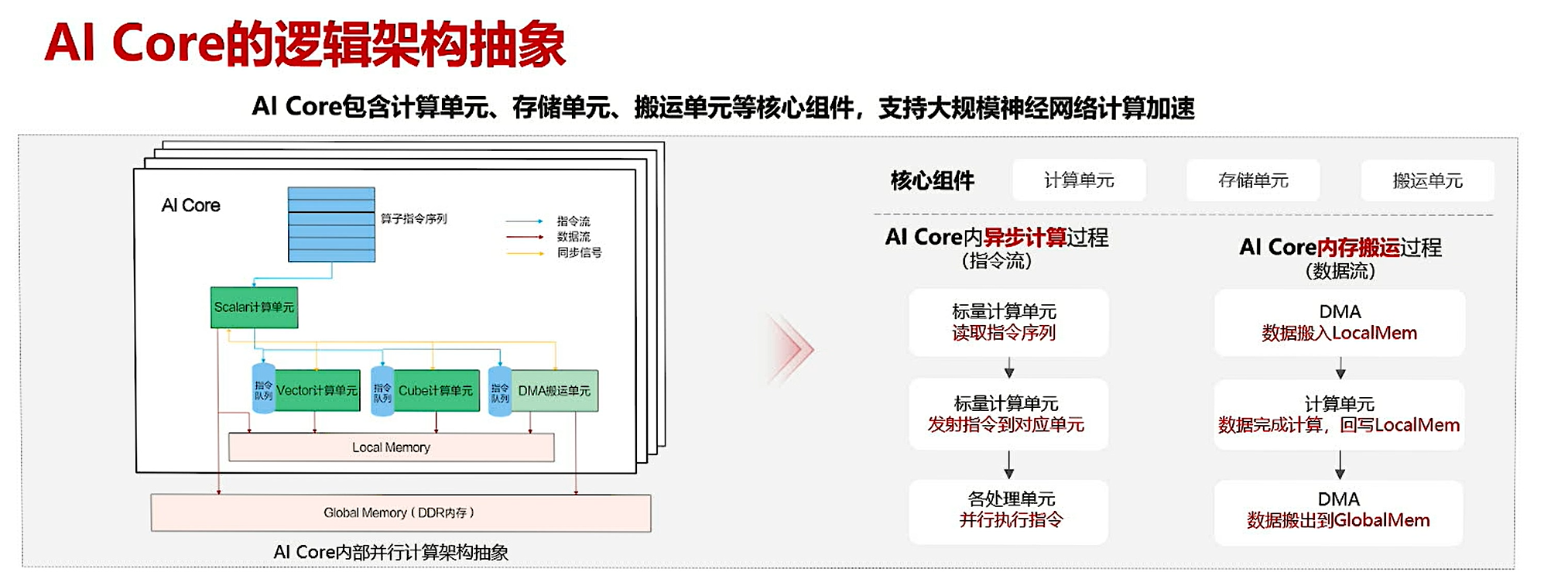
计算单元
AI Core包括了三种基础计算资源:Cube计算单元、Vector计算单元和Scalar计算单元(矩阵计算单元(Cube Unit)、向量计算单元(Vector Unit)和标量计算单元(Scalar Unit))。
存储单元
存储单元包括内部存储和外部存储:
AI Core中存在内部存储,AI Core需要把外部存储(通常包括L2、HBM、DDR等)中的数据加载到内部存储中,才能完成相应的计算。AI Core的主要内部存储包括:L1 Buffer(L1缓冲区),L0 Buffer(L0缓冲区),Unified Buffer(统一缓冲区)和Scalar Buffer(标量缓冲区)。
搬运单元
DMA(Direct Memory Access)搬运单元:负责在Global Memory和Local Memory之间搬运数据。
为了配合AI Core中的数据传输和搬运,AI Core中还包含BIU(Bus Interface Unit,总线接口单元),MTE1(Memory Transfer Engine,存储转换引擎),MTE2,MTE3。其中BIU为AI Core与总线交互的接口;MTE为数据搬运单元,完成不同Buffer之间的数据搬运。
不同类型的昇腾AI处理器,存储单元大小不同,用户可通过get_soc_spec接口获取。
Global Memory
AI Core能够访问的外部存储称之为Global Memory,对应的数据类型为GlobalTensor。

Local Memory
AI Core的内部存储,统称为Local Memory,对应的数据类型为LocalTensor。由于不同芯片间硬件资源不固定,可以为UB、L1、L0A、L0B等。

SIMD与SPMD

Ascend C算子编程是SPMD(Single-Program Multiple-Data)编程
SPMD并行计算示意图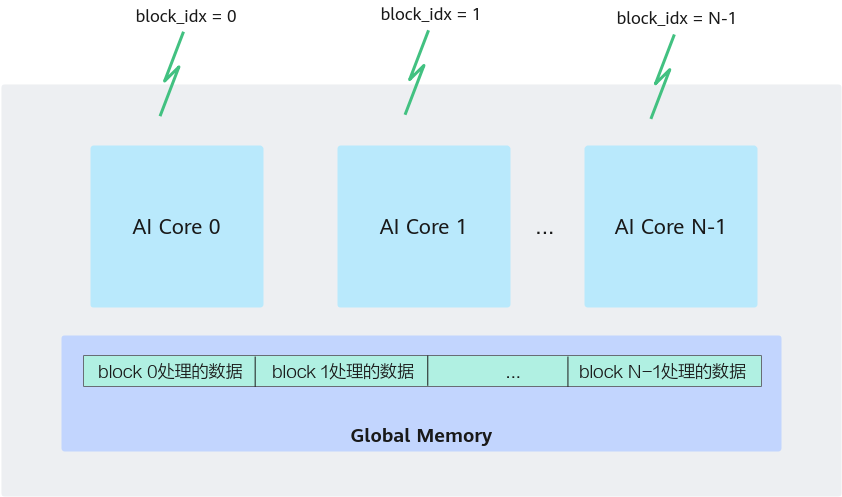
核内(Intra-Core):指的是单个处理核心内部的执行。例如,SIMD 是在一个处理核心内执行的,即核内的并行操作。多个数据元素通过一个核心的 SIMD 单元同时处理。
核间(Inter-Core):指的是多个处理核心之间的协作。SPMD 通常涉及核间的并行处理,即多个核心同时运行相同的程序代码,但处理不同的数据集。
具体关系
SIMD 核内操作:SIMD 是一个核内的并行机制。它利用处理器内的硬件资源来执行单条指令在多个数据上的操作,通常在一个核心内部通过向量处理单元来实现。SIMD 不涉及多个核心之间的协作,而是关注如何在单个核心内高效利用并行性。
SPMD 核间协作:SPMD 则更多涉及核间的协作。多个核心(或多个线程)同时运行相同的程序,但各自操作不同的数据。每个核心运行的程序可以是独立的,程序中的不同实例可能根据处理的数据不同而采取不同的执行路径。这意味着多个核心之间协作来完成更大规模的并行计算任务。