当地时间10月8日,瑞典皇家科学院宣布,2024年度诺贝尔物理学奖授予美国科学家约翰·霍普菲尔德(John Hopfield)以及加拿大学者杰弗里·辛顿(Geoffrey Hinton),以表彰他们“为利用人工神经网络进行机器学习做出的基础性发现和发明”。

美国科学家翰·霍普菲尔德(John Hopfield)和英国裔加拿大科学家杰弗里·欣顿(Geoffrey Hinton)分享2024年诺贝尔物理学奖。
约翰·霍普菲尔德和杰弗里·欣顿分别因其在神经网络与机器学习领域的开创性贡献而广为人知,并且他们的研究在生物学和人工智能领域产生了深远的影响。
约翰·霍普菲尔德 (John Hopfield) 的主要贡献
霍普菲尔德是普林斯顿大学的物理学家和计算神经科学家,他的主要贡献是在1982年提出了霍普菲尔德网络(Hopfield Network)。这种网络是一种递归神经网络,模拟了生物神经系统的功能,并在神经计算和联想记忆的研究中起到了奠基性的作用。霍普菲尔德网络最重要的特征之一是它能够通过能量函数进行自组织,网络的状态会趋向于局部最小值,因此能够在一定程度上模拟大脑的联想记忆过程。这种工作不仅在神经科学上具有重大影响,也为后来的人工智能和机器学习发展奠定了基础。
霍普菲尔德的贡献使得他成为计算神经科学的奠基人之一,他的工作为理解生物神经网络如何处理信息提供了新的视角。

美国普林斯顿大学教授、2024年诺贝尔物理学奖得主约翰·霍普菲尔德(John Hopfield)
杰弗里·欣顿 (Geoffrey Hinton)的主要贡献
杰弗里·欣顿是加拿大多伦多大学的计算机科学家,因其在深度学习领域的开创性贡献而闻名。他是深度神经网络及其训练方法(特别是反向传播算法)的主要推动者之一,反向传播使得神经网络能够通过梯度下降有效地调整权重,从而实现复杂的模式识别任务。欣顿的研究极大推动了现代人工智能的发展,尤其是在计算机视觉、语音识别和自然语言处理等领域。
欣顿和他的学生们在2006年提出了深度信念网络(Deep Belief Networks),这种网络结构是现代深度学习的基础之一。此后,他的研究团队通过一系列实验展示了深度神经网络在处理大规模数据集上的优势,从而掀起了全球范围内的深度学习浪潮。
欣顿还致力于发展胶囊网络(Capsule Networks),试图解决传统卷积神经网络(CNN)中的一些局限性。欣顿的工作使得人工智能进入了深度学习时代,并使得计算机在图像识别、语音识别等领域达到了前所未有的精度。

加拿大多伦多大学教授、2024年诺贝尔物理学奖得主杰弗里·欣顿(Geoffrey Hinton)
人工智能发展史的三个重要阶段
此前大家预测的物理学奖热门领域(如凝聚态物理或量子物理)最终都没有获奖,出乎很多人的意料。虽然诺奖委员会强调,“两位诺贝尔物理学奖得主,利用物理学工具开发出当今强大机器学习的基础方法。”
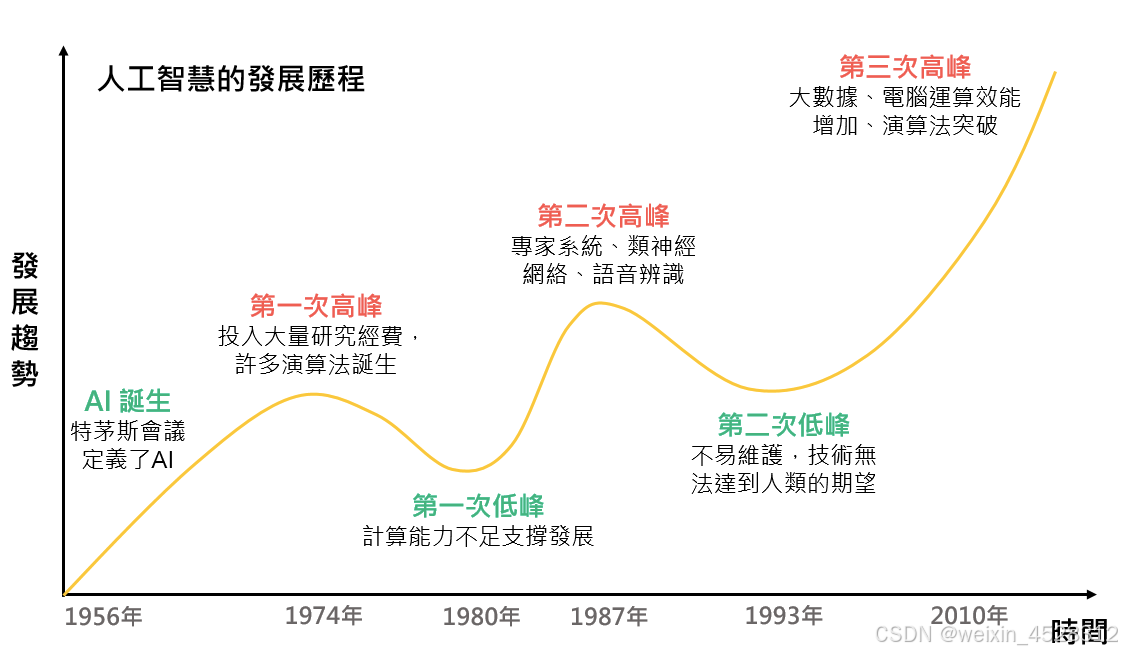
近几年,人工智能(AI)在人们身边卷起了一股热潮,我们很容易认为这是一项近期的创新。事实上,人工智能以各种形式存在已有70多年了。回顾AI工具的研究发展历程,对于我们理解这个大热领域未来的发展之路会很有帮助。
每一代AI工具都可以被视为对前代的改进,但值得注意的是,没有一种AI正在朝着“有意识”的方向发展。今年诺贝尔物理学奖获奖者之一,被誉为“AI教父”的杰弗里·辛顿也认为,虽然AI有可能变得比人类更聪明,但应该将其视为与人类完全不同的智能形式。
人工智能(AI)的发展历史可以追溯到20世纪中期,并经历了数个重要阶段,涵盖了早期的理论研究、算法进步、计算能力的提升,以及深度学习的崛起。
从时间上来看,AI的发展历程可以大致分为三个阶段:符号主义AI、连接主义AI和当前的深度学习时代。
阶段一:符号主义AI时代(1950s-1980s)
1950年,计算机先驱艾伦·图灵在一篇开创性的文章中提出:“机器能思考吗?”
并提出了“模仿游戏”的概念(现在通常被称为图灵测试)。在这项测试中,如果一台机器在纯文本形式对话中的表现无法与真人区分开来,就被认为是拥有智能的。
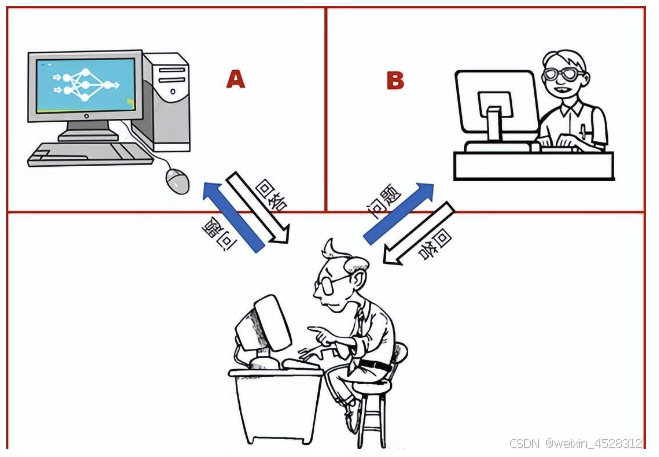
图灵测试示意图:有一个人和一台机器,在一个隔音室里,这个人必须通过提问来确定哪个是机器,哪个是人。如果这个人无法准确地区分机器和人,那么这台机器就通过了图灵测试,被认为具有了“智能”。
五年后,“人工智能”这个术语首次在著名的达特矛斯会议中出现,标志着AI研究的正式开始。这个时期的AI主要以符号主义为主导,试图通过类似于人脑的逻辑推理和知识表示来模拟人类思维。
从20世纪60年代开始,一类被称为“专家系统”(Expert systems)的AI分支开始发展。这些系统旨在捕捉特定领域的人类专业知识,并使用明确的知识表示。
这类系统是“符号AI”的典型例子,早期出现了许多广为人知的成功案例,包括用于识别有机分子、诊断血液感染和勘探矿物的系统。其中最引人注目的是名为R1的专家系统,据报道,1982年它通过设计高效的小型计算机系统配置,为数字设备公司每年节省2500万美元。
专家系统的主要优势在于,即使没有编程专业知识的某领域专家,也可以参与构建和维护计算机的知识库。专家系统中,一个被称为“推理机”(Inference engine)的组件能够应用这些知识来解决领域内的新问题,并提供解释性的证据链。
这类系统在上世纪80年代非常流行,各组织争相构建自己的专家系统。值得一提的是,专家系统至今仍是AI的一个重要组成部分。然而,专家系统也面临着一些限制,如知识获取瓶颈和难以处理不确定性问题。这些约束促使研究人员探索新的方法。
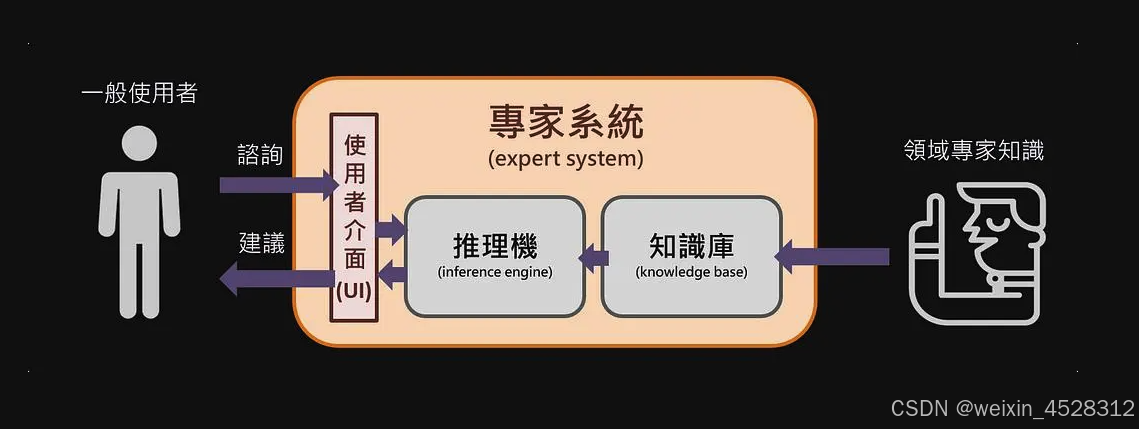
符号主义时代的专家系统
阶段二:联结主义AI与机器学习的崛起(1980s-2000s)
人脑包含约1000亿个神经细胞(神经元),它们通过树突(分支)结构相互连接。受到人脑的启发,一个称为“联结主义”的独立领域也应运而生——与专家系统试图模拟人类推理过程不同的是,这种新方法试图直接模拟人脑的神经网络。
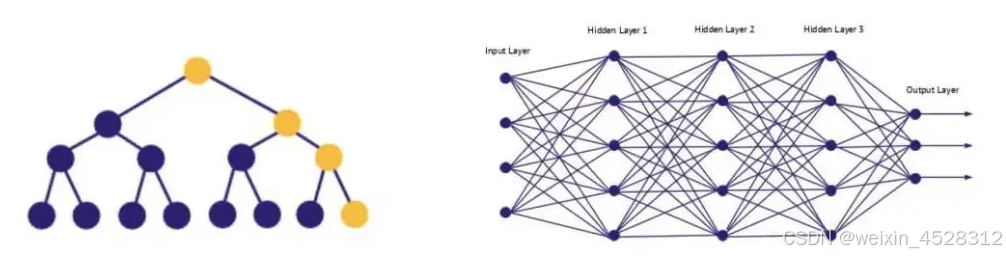
AI的符号主义(Symbolism,左)和 连接主义(Connectionism)的示意图
AI 的符号主义和连接主义是早期人工智能研究的两种主要范式,它们在如何理解和模拟人类智能上有着不同的理念。
符号主义(Symbolism),也被称为基于符号的人工智能,基于逻辑推理和规则系统。符号主义者认为,智能是通过操纵符号来进行的,类似于人类使用语言和逻辑思维的方式。符号主义AI主要依赖于明确的规则、逻辑和知识库,旨在通过定义复杂的符号和逻辑规则来解决问题。
工作方式:符号主义系统使用规则和推理引擎来处理预定义的符号。例如,专家系统使用“如果-那么”的规则进行推理。优势:擅长处理明确的逻辑推理和有明确结构的知识。局限性:不太擅长处理不确定性、模糊信息或复杂的感知任务(如图像识别、语音识别等)。连接主义(Connectionism)的AI,受人脑神经网络的启发,重点在于通过大量的简单单元(类比为神经元)和它们之间的连接来实现智能。人工神经网络是连接主义的核心,主要通过数据驱动的学习过程来发现模式和进行决策。
工作方式:连接主义系统通过大量的数据训练,调整网络中的连接权重来学习复杂的模式。例如,深度学习模型通过多层神经网络来处理图像、语音等任务。优势:擅长处理海量数据,能够从复杂的非结构化数据中学习,如图像、语音、自然语言处理等。局限性:通常被认为是“黑箱”,因为它们的推理过程难以解释。另外,这些模型往往需要大量的数据和计算资源进行训练。其实,早在1943年,两位美国学者沃伦·麦卡洛克和沃尔特·皮茨就提出了人类神经元联结的数学模型,每个神经元根据输入的二进制信号,产生对应的二进制输出。这为后来的神经网络奠定了基础。
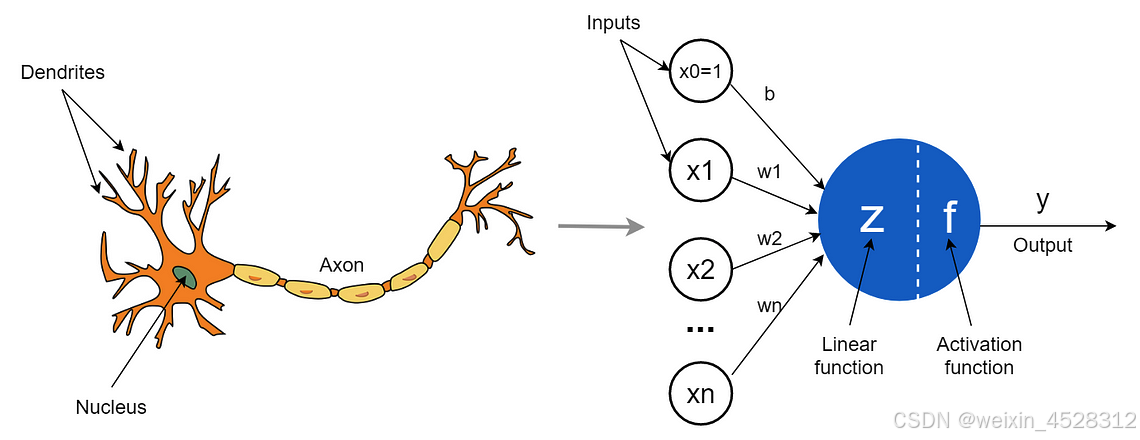
神经元和神经网络示意图
1960年,弗兰克·罗森布拉特(Frank Rosenblatt)提出了“感知器”(Perceptron)的概念,这是一种简单的人工神经网络。同年,伯纳德·维德罗(Bernard Widrow)和泰德·霍夫(Ted Hoff)开发了ADALINE(ADAptive LInear NEuron),这些是模拟神经元的最早实践,虽然有趣,但实际应用都很有限。
1969年,达特茅斯会议的发起人之一马文·明斯基和西摩·佩珀特(Seymour Papert)在他们的著作《感知器》中指出了单层神经网络的局限性,这导致了神经网络研究的短暂停滞。然而,这个挫折也促使研究人员探索“更复杂”的网络结构。
1986年,今年诺贝尔物理学奖获得者之一的杰弗里·辛顿,与几位合作者发表了一篇开创性论文,介绍了反向传播算法,这为“多层感知器”(Multi-Layered Perceptron,MLP)的学习算法奠定了基础。
反向传播算法允许神经网络探索数据内部的深层表征,因此神经网络才能解决以前被认为无法解决的问题。这是一项重大突破,实现了从一组示例(训练)数据中学习,然后进行归纳总结,以便对以前未见过的输入数据(测试数据)进行分类。

Hopfield网络、Hinton的Boltzmann网络和受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)是三种不同的神经网络架构示意图。其中,Hopfield网络是全连接对称网络,用于联想记忆,通过最小化能量函数恢复存储模式。Boltzmann机是全连接的随机网络,具有显层和隐层,利用吉布斯采样进行无监督学习,但训练复杂且缓慢。受限玻尔兹曼机(RBM)是Boltzmann机的简化版本,去掉了层内连接,显层和隐层之间双向连接,训练更高效,常用于特征提取和降维。总体来讲,Hopfield网络用于模式记忆,Boltzmann机和RBM用于无监督学习,RBM更为简化和高效。
MLP通常是三层或四层简单模拟神经元的排列,每一层与下一层完全互连。MLP通过在神经元之间的连接上附加数值权重并调整它们来实现学习,以获得最佳的训练数据分类,以便对新的、未见过的数据进行分类。
在这个阶段中,今年另一位诺贝尔物理学奖获得者约翰·霍普菲尔德也做出了重要贡献。1982年,他提出了“霍普菲尔德网络”,这是一种递归神经网络模型,能够作为内容可寻址的记忆系统。霍普菲尔德网络的引入,为神经网络研究带来了新的活力,并为后来的深度学习发展奠定了重要基础。他的工作展示了如何使用物理学概念(如能量最小化)来理解神经网络的行为,为后续的神经网络研究提供了新的视角。
只要数据以适当的格式呈现,MLP就可以广泛处理各种实际问题。一个经典例子是手写笔迹的识别,但前提是图像需要经过“预处理”(Pre-processing)以提取关键特征。这个时期还出现了其他重要的机器学习算法,如支持向量机(SVM)和决策树,它们在某些任务上表现出色。
阶段三:深度学习时代(21世纪)
随着计算机算力的显著提升和大数据时代的萌芽,深度学习在21世纪初开始兴起。2006年,杰弗里·辛顿提出了“深度信念网络”(Deep Belief Networks, DBNs),这被认为是深度学习时代的开端。
MLP取得成功后,开始出现了多种新型神经网络。其中一个重要的是1998年由法国计算机科学家杨立昆(Yann LeCun)等人提出的“卷积神经网络”(Convolutional Neural Network,CNN)。CNN与MLP类似,但增加了额外的神经元层,用于识别图像的关键特征,从而消除了预处理的需要。如今,CNN在图像识别和计算机视觉任务领域取得了巨大成功。
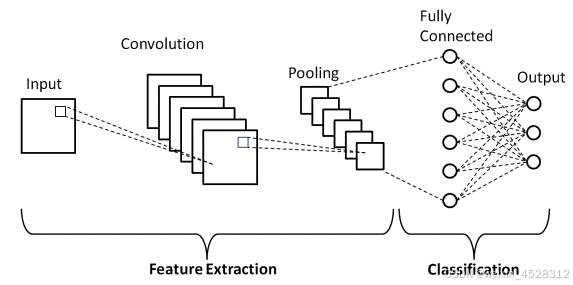
卷积神经网络(Convolutional Neural Network, CNN)是一种专为处理图像数据设计的深度学习模型,擅长捕捉图像中的空间特征。CNN通过卷积层提取局部特征,利用卷积核(filter)对输入图像进行滑动操作,自动学习边缘、纹理等低级特征。随着网络的加深,卷积层逐渐提取更抽象的高级特征。池化层(Pooling)则用于下采样,减少特征图的尺寸,降低计算复杂度,同时保留重要信息。最后,通过全连接层进行分类或回归任务。CNN广泛应用于图像分类、目标检测、自然语言处理等领域,具有高效的特征提取能力和出色的性能。
前面所说的MLP和CNN都属于擅长分类、判断、预测的“判别模型”(Discriminative Model)。而近几年来,不断涌现的各种能写诗、画画的“生成模型”(Generative Model),也开始大放异彩。
2014年,美国学者伊恩·古德费洛(Ian Goodfellow)等人又提出了“生成对抗网络”(Generative-Adversarial Networks,GANs)。GANs的一个重要组成部分是“判别器”(Discriminator),即一个内置的批评者,不断要求“生成器”(Generator)提高输出质量。GANs在AI图像生成、风格迁移等任务中表现出色。
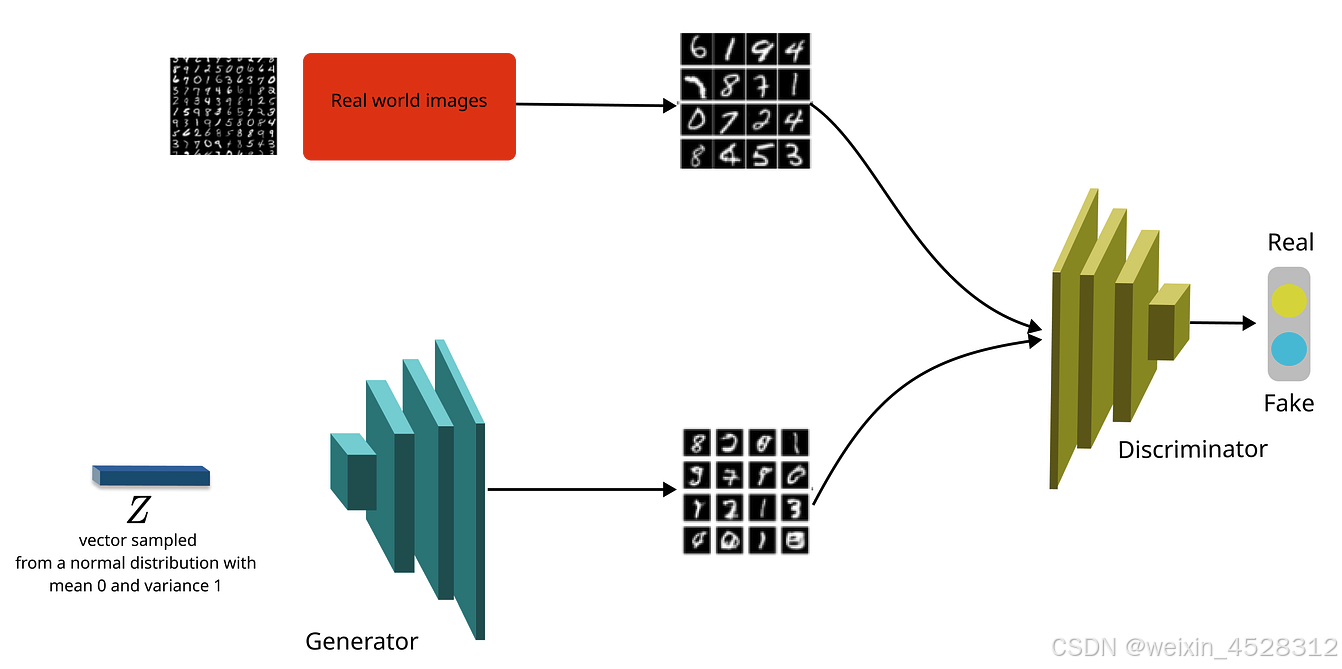
生成对抗网络(Generative Adversarial Network, GAN)是一种由两部分组成的神经网络架构:生成器(Generator)和判别器(Discriminator)。生成器通过从随机噪声中生成伪造数据,试图欺骗判别器;而判别器则试图区分真实数据和生成数据。这两个网络在训练中相互对抗,生成器不断改进生成数据的质量,判别器提高识别伪造数据的能力。最终,生成器能够生成与真实数据非常接近的样本。GAN被广泛应用于图像生成、数据增强、风格转换等领域,具有强大的生成能力,但训练过程容易出现不稳定性。
2017年,谷歌的研究人员提出了“转换器”(Transformer)架构,这是一种基于自注意力机制(Self-Attention)的神经网络模型。传统神经网络的编码器需读取和处理整个输入数据序列,而新的架构并不按顺序处理数据,而是使模型能够同时查看序列的不同部分,并确定哪些部分最重要。
基于转换器的新兴模型(如BERT和GPT系列等),在自然语言处理任务中取得了突破性进展,推动了“大型语言模型”(Large-Language Models,LLMs)领域的发展。这些大型语言模型从互联网上抽取海量数据集进行训练。通过强化学习(Reinforcement Learning),人类训练师们提供的反馈进一步提升了它们的性能。
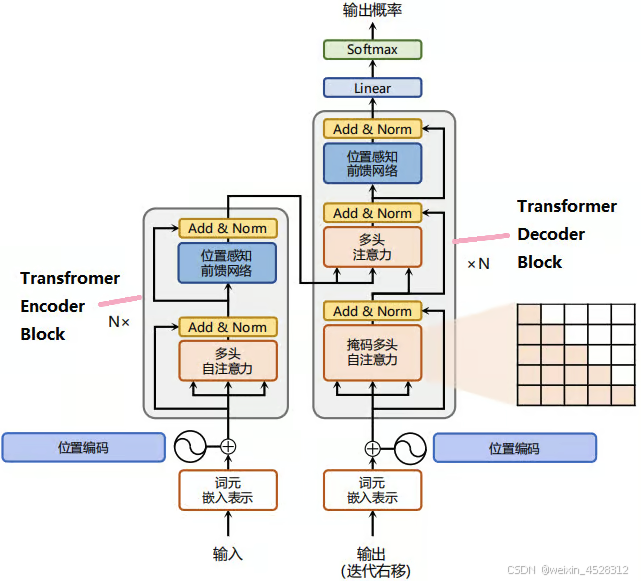
Transformer是一种基于自注意力机制的深度学习模型。它最初用于自然语言处理任务。与传统的序列模型(如RNN和LSTM)不同,Transformer无需逐步处理序列数据,而是通过自注意力机制并行处理整个输入序列。模型主要由编码器和解码器组成,编码器提取输入的上下文信息,解码器利用这些信息生成输出。Transformer通过多头注意力机制捕捉不同位置之间的依赖关系,尤其擅长处理长距离依赖问题。其并行计算能力使训练速度更快,并在机器翻译、文本生成等任务中取得了显著的效果,是近年来深度学习的核心模型之一。
在深度神经网络训练中,随着反向传播逐层传递梯度,梯度的值逐渐变得非常小,最终接近于零。这使得前面层的权重无法有效更新,网络难以学习到有用的特征,导致训练停滞。这个问题叫做“梯度消失”。梯度消失问题尤其在深层网络中更加明显,阻碍了模型向更深层次的扩展。2015年,何凯明和他的同事提出了一种残差网络(Residual Network, ResNet)通过引入残差连接(skip connections),对解决梯度消失问题作出了贡献。
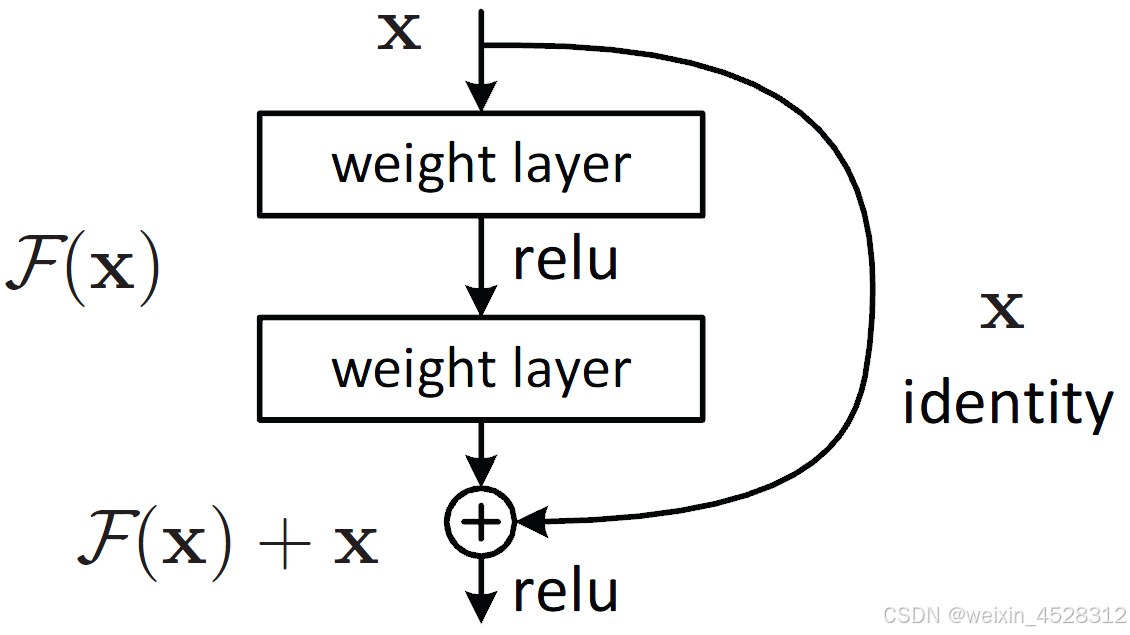 残差网络(ResNet)示意图
残差网络(ResNet)示意图
残差连接让输入能够直接跳过几层传递到后面的层,将“输入”和“输出的变化”建模为残差。这种结构的核心思想是,让网络去学习与输入的差异,而不是直接学习复杂的映射。这样使得梯度能够更容易地从后层传播到前层,解决了梯度消失和退化问题。ResNet的设计使得非常深的网络(如上千层)也能成功训练,并显著提高了图像分类、检测等任务的准确率,成为现代深度学习网络架构的重要基石。
物理学家反对物理诺奖授予AI领域吗?
2024年诺贝尔物理学奖与诺贝尔化学奖均授予了人工智能(AI)领域,分别表彰了神经网络先驱以及研究和预测蛋白质的计算工具的开发者。但并非所有研究人员都为此感到兴奋。据《自然》报道,在瑞典皇家科学院揭晓今年诺贝尔物理学奖得主后不久,社交媒体上一片沸腾,数位物理学家表示,物理学奖得主的工作应该归于计算机科学,而非物理学。
与此同时,也有许多物理学家表示支持,他们认为神经网络先驱者的研究跨学科,将物理学、数学、计算机科学和神经科学结合在了一起,尽管不是最纯粹意义上的理论物理学,但植根于物理学的技术和概念。2021年因复杂系统获得诺贝尔物理学奖的科学家Giorgio Parisi也表示:“我认为诺贝尔物理学奖应该继续扩展到更多的物理知识领域,物理学正变得越来越广泛,它包含了许多过去不存在的知识领域,或者不属于物理学的一部分。”自 1901 年设立以来,诺贝尔奖一直关注研究对社会的影响,并奖励实用发明,而不仅仅是纯科学。科普作家Anil Ananthaswamy指出,从这方面来说,2024年的物理和化学奖项并不是特例。

前诺贝尔物理学奖的科学家Giorgio Parisi认为物理学正在变动越来越广泛
诺奖获得者的担忧:AI可能会接管人类吗?
一年前,被誉为“人工智能教父”的杰弗里·辛顿,也就是本届诺贝尔物理学奖的主角之一,警告说,人工智能存在危险,希望政府和企业仔细考虑如何安全地推进这项技术。
在接受《60 分钟》的采访时,这位英国计算机科学家和认知心理学家表示:“我认为在五年内,AI 的推理能力可能会超过我们。”
辛顿以他对人工智能框架的研究而闻名,他质疑人类是否完全理解这项正在快速发展的技术,他说:“我认为我们正在进入一个前所未有的时期,我们面对的东西比我们更聪明。”
辛顿认为,理解技术的思维方式就像读懂人类的心思一样困难,他称:“我们大致知道它在做什么,但是一旦它变得非常复杂,我们就不再知道发生了什么,就像我们不知道你的大脑里发生了什么一样。”
辛顿表示,如果人类失去了对人工智能的控制,那将是令人担忧的,他说:“我们正在进入一个充满不确定性的时期,我们要处理一些从未做过的事情。通常第一次处理一些全新的事情,你会做错,而我们不能负担得起这些事情出错。”
辛顿警告称,人工智能有可能有一天会取代人类,他说:“我不是说它一定会发生。如果我们能阻止它们永远不想这样做,那就太好了。但是我们不能确定我们能阻止它们永远不想这样做。”
辛顿相信人工智能将有助于提高生产力和效率,但他担心许多人可能会因为人工智能而失去工作,并且可能没有足够的工作来取代那些丢掉的工作。他表示,现在是进行实验来更好地理解人工智能,并通过法律来确保技术被合理使用的时候了。
尽管如此,也有不同的观点则认为,人工智能的最大威胁不是AI本身,而将是人类选择使用它的方式,就像核武器本身并不伤害人类,但使用它的人才会遭遇疯狂。所以即使是看似无害的高级 AI 形式也可能被恶意使用。最近,计算机科学家不得不缩减一个“类似变色龙”的语言预测系统,称其太危险而不能向公众发布。
Meta 的首席人工智能(AI)科学家杨立昆(Yann LeCun)不久前在巴黎举行的 Viva Tech 会议上表示,“AI 目前的智力水平连狗都不如,不应将其视作对人类的威胁。” 他说,“那些 AI 系统仍然非常有限,它们对现实世界的基本现状没有任何理解,只是纯粹基于大量的文本进行训练。但大部分人类知识与语言无关,所以这部分人类经验不会被人工智能捕捉到。”

人工智能两夺桂冠,诺奖进入“AI时代”?
无独有偶,物理学界的震惊还未平息,诺贝尔化学奖又在一天之后再次将荣誉授予了AI领域。
10月9日,瑞典皇家科学院宣布,将2024年诺贝尔化学奖授予戴维·贝克(David Baker),以表彰其在计算蛋白质设计方面的贡献;另一半则共同授予英国伦敦谷歌旗下人工智能公司“深层思维”(DeepMind)的德米斯·哈萨比斯(Demis Hassabis)和约翰·江珀(John M. Jumper),以表彰其在蛋白质结构预测方面的贡献。

美国华盛顿大学David Baker教授和谷歌DeepMind两位科学家Demis Hassabis,John M. Jumper分享2024年诺贝尔化学奖
诺贝尔奖委员会评价称,哈萨比斯和江珀开发了一种名为AlphaFold2的人工智能模型,这种模型解决了一个已有50年历史的难题,能够预测大约两亿种已知蛋白质的复杂结构,并且已被全球200多万人使用。
至此,2024年诺贝尔奖中,科学类的三个奖项:生理学或医学奖、物理学奖、化学奖已全部揭晓,AI领域无疑成为了“最大赢家”。
尤其是“物理学奖花落AI”,出乎了许多人的意料。在奖项揭晓前的各种预测中,几乎从未出现过这两位获奖者的名字。然而,回顾两位科学家的研究成果,人们不难理解其获奖原因。正如诺贝尔奖委员会所评价的:“尽管计算机无法思考,但现在,机器已经可以模仿人的记忆并具备学习等功能。今年的物理学奖得主为实现这一目标作出了贡献。”
今年诺贝尔三大科学奖两项颁给了AI,深刻反映出AI技术作为一股不可忽视的力量,在全球科研舞台上的崛起与影响。
机器学习的重要研究和发展,与物理学有着千丝万缕的关系。一方面,物理学早已突破传统领域,研究的范围更广;另一方面,随着AI工具被广泛使用,越来越多的科研人员也正使用机器学习,继续拓展着物理、化学、生物等研究边界。
此外,今年的诺奖也引发了科学界对于交叉研究的深入讨论。近年来,诺贝尔物理学奖越来越垂青于那些跨越多个学科领域的交叉研究。从2020年颁给数学家彭罗斯,到2021年颁给研究复杂系统的气象学家真锅淑郎和克劳斯·哈塞尔曼,再到今年的霍普菲尔德和辛顿,这些获奖者无一不是“跨界高人”。
总体来讲,今年的诺贝尔物理学奖和化学奖颁给AI领域的科学家,不仅是对他们卓越贡献的肯定,更是对科学界的一次深刻启示:在未来的科学探索中,技术与学科的交叉融合将成为常态,而AI作为这一融合过程中的核心驱动力之一,将推动科学研究不断突破传统框架,实现更加深远、更加广泛的创新。