同志们大家好,今天出一期在windows、linux & ubantu系统中部署yolo or rtdetr项目的流程,供小白快速入门!(声明:以下流程均在蓝耘GPU平台和魔鬼面具的rtdetr项目下进行,其他项目如yolo系列均可使用该方法)
目录
一、准备工作
二、pycharm连接远程服务器方法
三、项目环境配置---RTDETR 和YOLO环境相同
四、训练教程---RTDETR 和YOLO相同
五、训练过程中的一些小技巧
一、准备工作
在此之前需要提前下载以下工具
1.显卡资源(自用电脑 或 服务器平台
2.Pycharm专业版,Vscode,或GPU平台的Jupyter界面(以下教程在Pycharm专业版中展示)
3.XFTP文件传输助手(个人习惯,可使用其他文件传输软件,较为方便)
相关链接附文章末尾
二、pycharm连接远程服务器方法
以下流程均在b站有对应视频
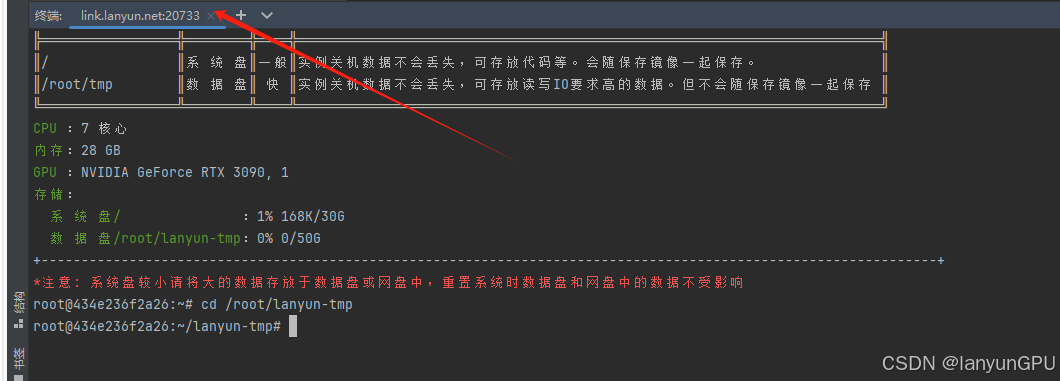
0.首先需要先找到远程服务器的ssh链接及密码,例如
ssh -p 20733 root@link.lanyun.net
rppfoklk5zmp22su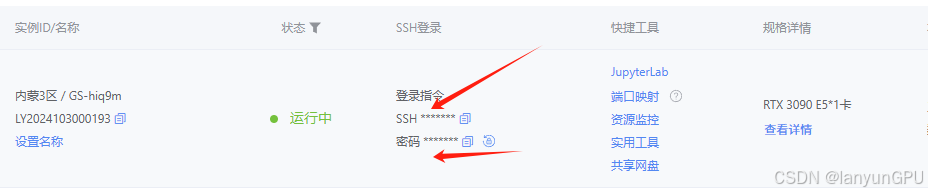
1.打开pycharm专业版,依次点击工具---部署--配置
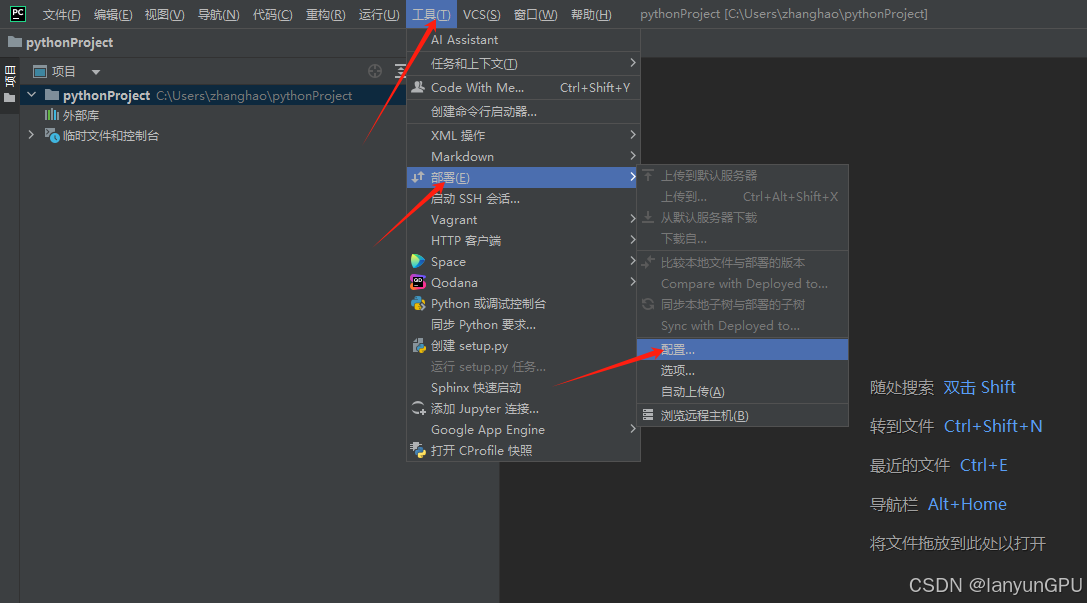
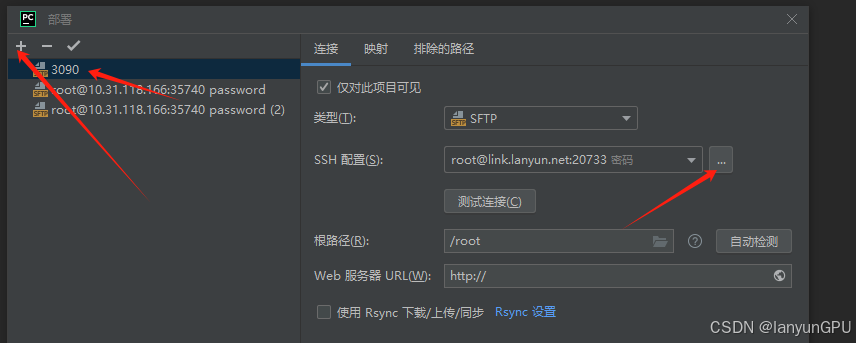
2.添加新配置,按以下图片流程添加ssh信息,测试连接(不懂请看b站视频)

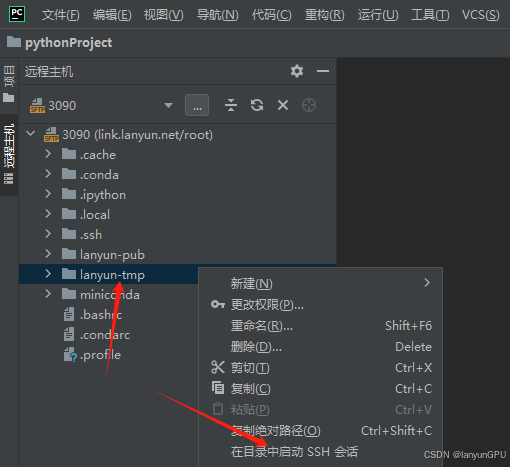
3.打开远程主机Remote Host(远程服务器目录)
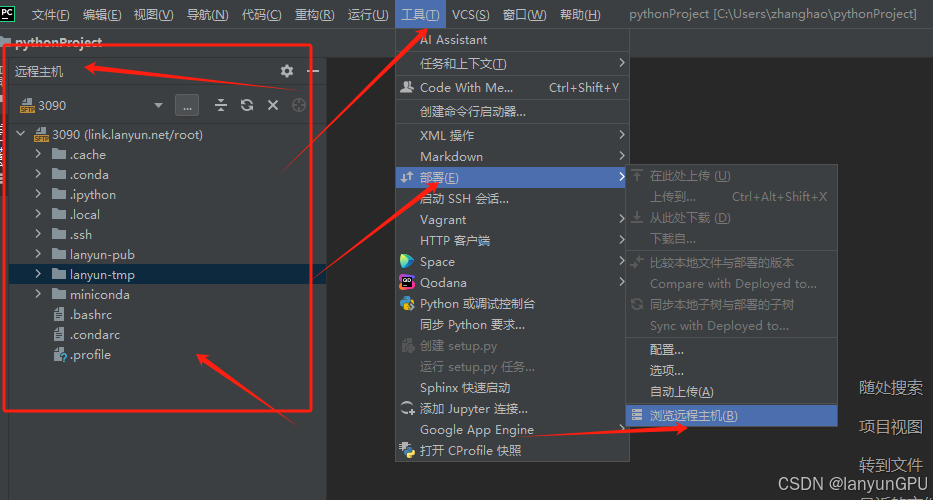
4.打开远程终端
三、项目环境配置---RTDETR 和YOLO环境相同
1.本地需要提前准备好Conda环境以便安装虚拟环境及torch及后续操作
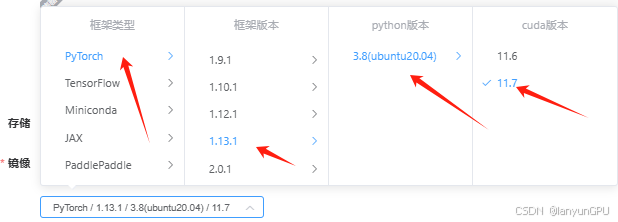
conda create -n yolo python=3.8 #创建虚拟环境(云GPU若有对应环境可不用创建)conda init(可选)conda activate(可选)conda activate yolo #进入虚拟环境#yolo可替换其他名字2.云GPU服务器直接选定以下torch和cuda版本直接部署,或创建虚拟环境后按装下方相关包。
以下代码装好虚拟环境后可直接全部复制进去,或者一条一条复制,一般不会出现报错情况。
(若网络下载过慢,可尝试切换其他镜像源)
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117 -i https://pypi.tuna.tsinghua.edu.cn/simplepip install timm==0.9.8 thop efficientnet_pytorch==0.7.1 einops grad-cam==1.4.8 dill==0.3.6 albumentations==1.3.1 pytorch_wavelets==1.3.0 tidecv -i https://pypi.tuna.tsinghua.edu.cn/simplepip install -U openmim -i https://pypi.tuna.tsinghua.edu.cn/simple mim install mmengine -i https://pypi.tuna.tsinghua.edu.cn/simple mim install "mmcv>=2.1.0" -i https://pypi.tuna.tsinghua.edu.cn/simpleapt-get update apt install libgl1-mesa-glx pip install psutil -i https://pypi.tuna.tsinghua.edu.cn/simple3.装好环境的同时将魔导的项目文件上传进去,可以用XFTP上传或直接上传
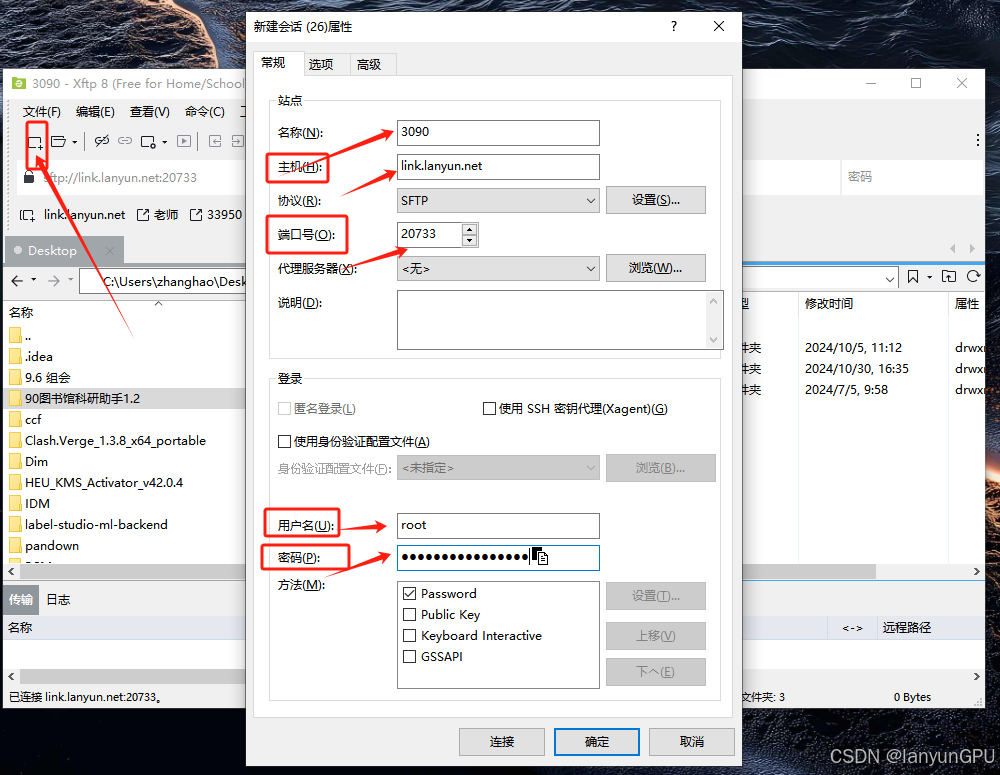
首先使用XFTP连接远程服务器
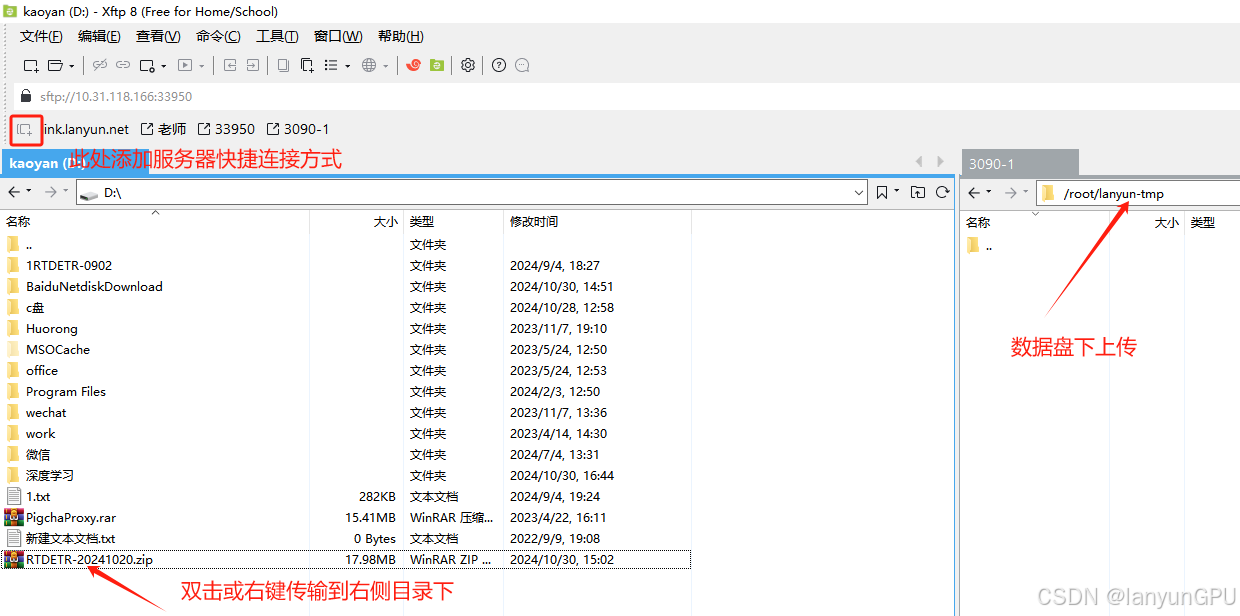
四、训练教程---RTDETR 和YOLO相同
1.终端下解压项目文件
①unzip RTDETR-20241020.zip (解压指令)
②cd RTDETR-main/ (cd到文件目录下)
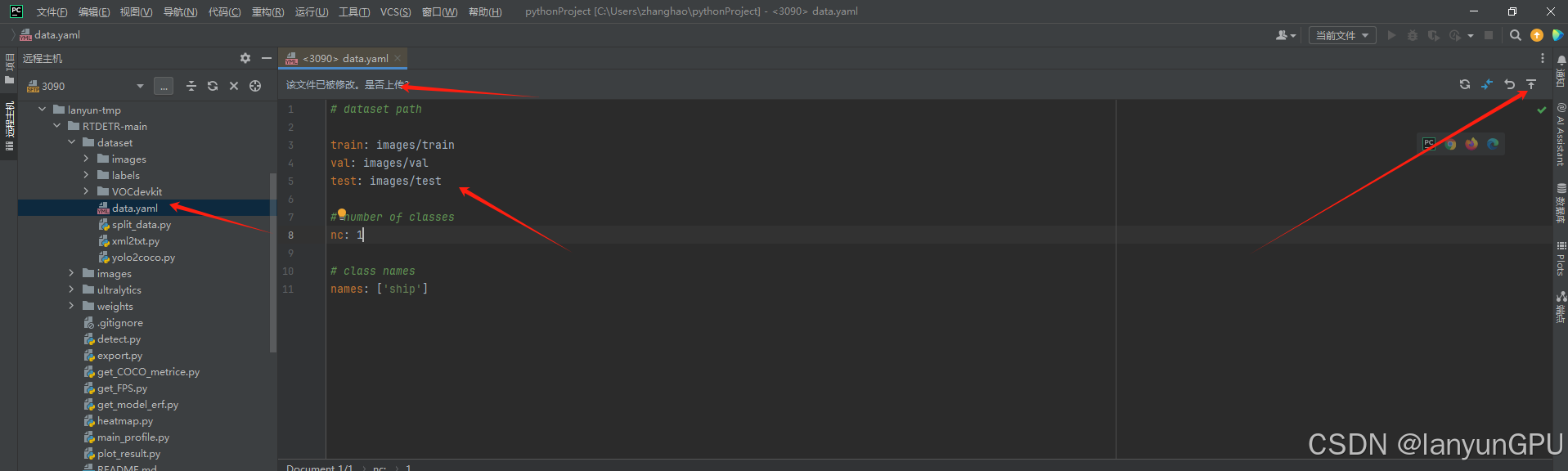
③修改数据集路径(使用项目默认数据集测试,修改后上传保存)
④运行python train.py 指令提示报错,原因是因为路径错误,datasets出现了两次
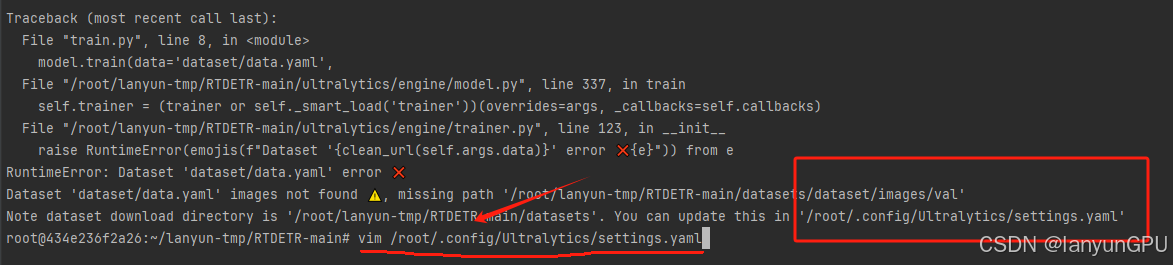
⑤vim /root/.config/Ultralytics/settings.yaml (---vim到上方报错路径)
按键盘上的“i”键进入改写模式,删除路径后方的datasets,改成以下路径后按ESC退出改写模式后,按Shift+Z+Z保存代码退出

⑥再次运行python train.py 指令后成功运行,或者可能会出现字体下载卡顿
如出现以下卡顿情况,请点击下载链接在本地下载后上传到和train.py同级目录,然后在终端使用以下指令:即可解决该问题,
mv Arial.ttf /root/.config/Ultralytics/Arial.ttf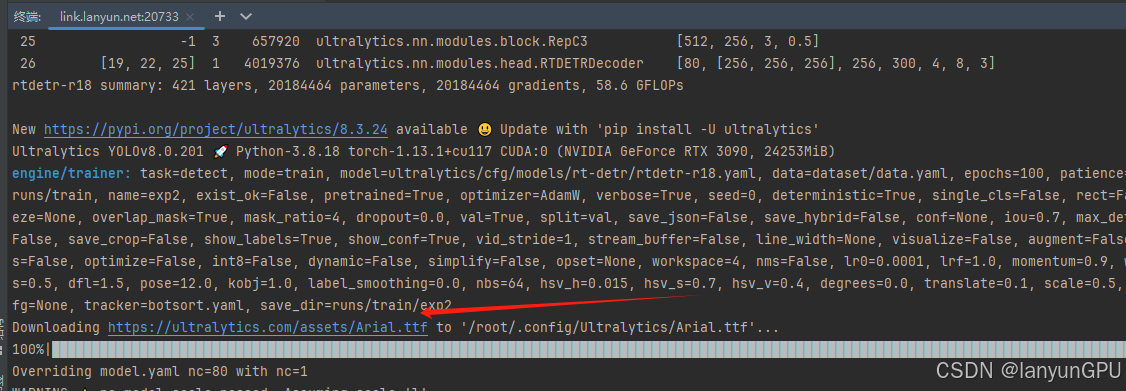
最后成功运行代码
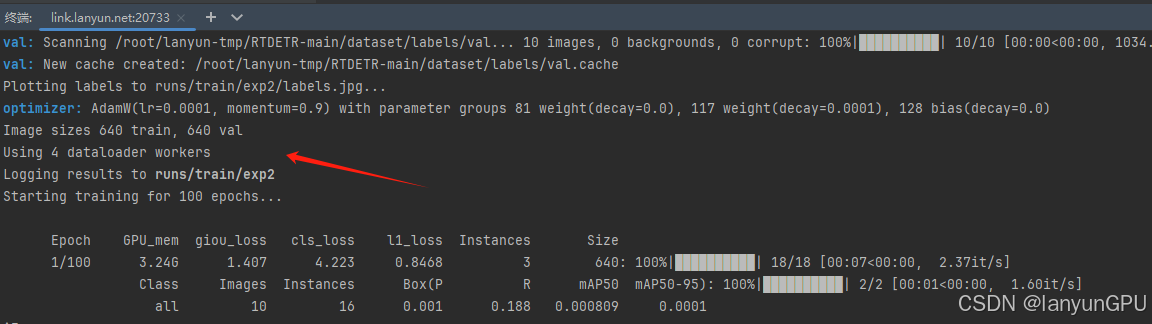
后续更换数据集的话,则按照以上格式,自行根据实际情况更改数据集即可
五、训练过程中的一些小技巧
1.使用nohup指令进行后台训练,防止因断网导致的中断等情况
①使用python train.py指令的话 你电脑网络环境发生变化时(则你的训练后中断,比如开关vpn,电脑息屏,网络不稳定)
②使用nohup python train-s.py > log.log 2>&1 指令的话,你跑通后电脑不管是关机还是啥,他代码都会在服务器后台跑,和自己电脑没关系)
nohup python train.py > log.log 2>&1 nohup python train-1.py > log1.log 2>&1nohup python train-2.py > log2.log 2>&1nohup python train-3.py > log3.log 2>&1#----服务器训练代码请使用nohup指令在后台跑,然后目录下会出现log.log的日志文件,存放你的所有打印的信息以上默认为0卡跑,若存在多卡,请在指令前加 CUDA_VISIBLE_DEVICES=1 例如 CUDA_VISIBLE_DEVICES=1 nohup python train-s.py > log.log 2>&1......2.查看是否跑完 nvidia-smi,//查看显存变化,如果跑一个实验占了8个G显存,然后显存变成0的时候就说明跑完了
3.查看跑到哪一轮了,精度是多少 查看runs/train/exp文件里面的result.csv,主要查看map50 和map50-95 的涨点情况
4.查看代码是否报错,打开日志log.log查看代码报错情况
5.运行一次代码,会出现一个进程号,若代码开始跑了,想提前中断的话,请使用ps aux 指令查看PID进程号了,并且使用kill -9 进程号 中断该进程并释放显存
一些常用终端指令
①rm -rf datasets/ ----删除datasets文件夹
②unzip dataset.zip ----解压dataset文件夹--xftp最好传输压缩包格式文件,这样快
③复制文件请在xftp中ctrl cv复制粘贴
附上相关链接
①文章中项目代码请查看:GitHub - z1069614715/objectdetection_script: 一些关于目标检测的脚本的改进思路代码,详细请看readme.md
1.显卡资源(自用电脑 或 服务器平台)
https://cloud.lanyun.net/#/activity?uuid=efa15431a91abaaf0bdeb212fffe685a
2.Pycharm专业版,Vscode,或GPU平台的Jupyter界面(以下教程在Pycharm专业版中展示)
3.XFTP文件传输助手(个人习惯,可使用其他文件传输软件,较为方便)
家庭/学校免费 - NetSarang Website
如有其他问题请在评论区指出,觉得有用的可以点赞评论,我们下期再见!