计算机视觉拥有众多细分领域,但在语义分割板块始终有一个绕不开的网络模型,它以独到的架构,提升了模型的计算效率,它以独有的方式,改善了分割物体边界划分不清的问题,它以出色的性能,深受工业界从业者的喜爱,它就是SegNet。
本文基于《SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation》论文,详细解读SegNet网络模型及其设计理念,并从基准测试的角度入手,对比其与其它典型分割模型的差别。
论文:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
论文链接:https://arxiv.org/abs/1511.00561
简介
SegNet是由剑桥大学团队开发的语义分割项目,论文最初于2015年在计算机视觉与模式识别大会(Conference on Computer Vision and Pattern Recognition,CVPR)发表,实际发布于2017年的《模式分析与机器智能》(IEEE Transactions on Pattern Analysis and Machine Intelligence)国际期刊,其第一作者Vijay Badrinarayanan 是一位在计算机视觉和深度学习领域具有丰富经验与成就的研究者,他在剑桥大学计算机实验室攻读博士学位,主要研究方向是计算机视觉和深度学习。
模型架构
SegNet是一款端到端(end-to-end)深度学习语义分割模型,其模型主要流程为:
图像输入 --> 编码器网络 --> 解码器网络 --> softmax分类器 --> 像素分割结果输出
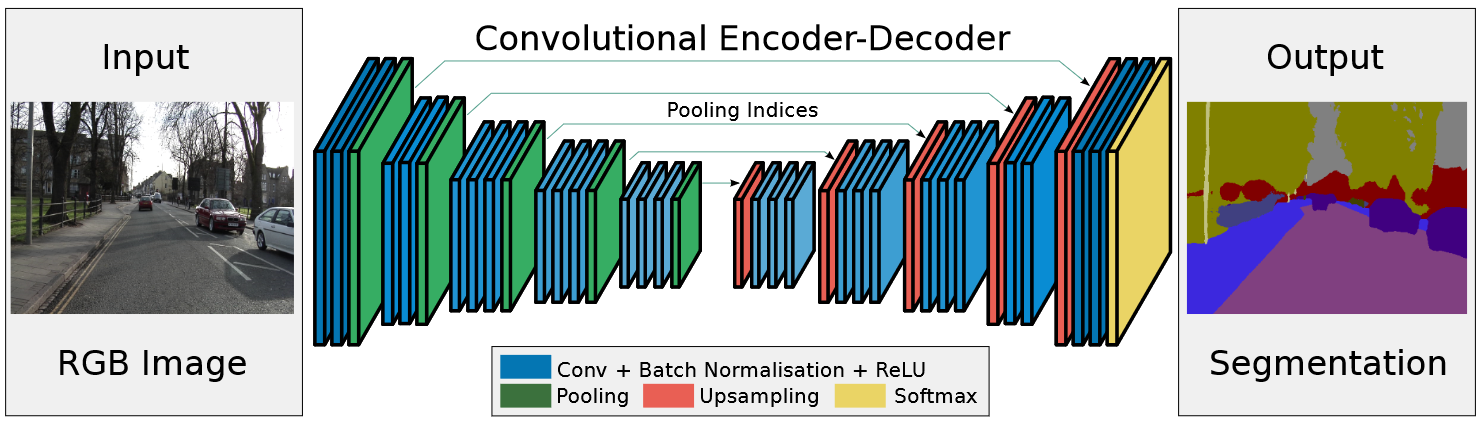
SegNet网络结构图
来源:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
编码器网络
编码器网络由13个卷积层组成,对应于 VGG16 网络中的前 13个卷积层,并丢弃了VGG16的全连接层,这大大减少了SegNet编码器网络中的参数数量。将13个卷积层和5个池化层划分为5个编码器,单个编码器的组成部分如下:
· 滤波器组:由负责提取图像特征的多个卷积层组成:
· BN层:为执行批量归一化操作的Batch Normalization;
· 非线性层:为执行非线性操作的ReLU激活函数;
· 最大池化层:使用2*2大小、步长为2的滑动窗口进行下采样操作;
2*2 Max Pooling(stride=2)
来源:SegNet图像分割网络直观详解 - 知乎
解码器网络
在SegNet网络结构中,编码器网络部分负责提取图像特征,并生成特征图,而解码器部分主要负责将特征图恢复到原始输入图像相同的空间分辨率,并生成分割结果。SegNet的编码器网络-解码器网络结构呈现对称结构,因此解码器网络也包含5个解码器组成,单个解码器组成部分如下:
· 上采样层:用于将图像恢复到更高空间分辨率;
· 滤波器组:由对经过上采样的特征图进行特征提取和整合的多个卷积层组成:
· BN层:为执行批量归一化操作的Batch Normalization;
· 非线性层:采用执行非线性操作的ReLU激活函数;
· softmax层:为k类的分类器,用于预测每个像素的类别,其在解码器的最后一层。
存储最大池化索引
即便编码器网络的多层最大池化可以通过平移不变性增强模型的鲁棒性,但随着特征图的空间分辨率不断降低,图像的边界细节也会逐渐损失,造成分割中不利于划定物体边界的问题,为此作者提出了独到的解决思路:存储最大池化索引。
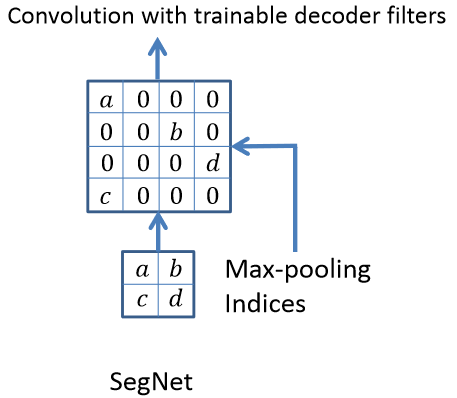
结果最大池化索引进行上采样流程
来源:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
存储边界信息的方式可以一定程度上解决物体边界划分不清的问题,假设在推理期间时的内存不受限制,应当储存所有的边界信息,但实际应用中是不现实的,因此退而求其次,作者选择在下采样时存储最大池化索引的方式,也就是保存编码器特征图中最大特征值的位置,然后,在解码器部分,使用这些位置信息来将特征图恢复到更高的分辨率,由于这些信息是直接从原始输入图像中获取的,因此它们能够更准确地反映物体的边界,这种方式虽然会给精度带来一定损失,但大大降低了内存占用,同时改善了物体边界划分不清的程度,在整体上更加适用于实际应用。
损失函数
SegNet在损失函数选取上较为简单,采用交叉熵的方式进行损失函数的计算,交叉熵损失函数适用于多分类问题,对概率分布较为敏感,有利于梯度下降。
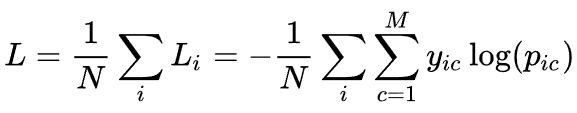
· M :类别的数量;
· yic :符号函数( 0 或 1 ),如果样本 i 的真实类别等于 c 取 1 ,否则取 0;
· pic:样本 i 属于类别 c 的预测概率;
from torch import nnfrom torch.nn import functional as Fimport torch as tclass Segnet(nn.Module): def init(self, input_nc, output_nc): super(Segnet, self).init() # Encoder self.conv11 = nn.Conv2d(input_nc, 64, kernel_size=3, padding=1) ##[4,256,256]-->[64,256,256] self.bn11 = nn.BatchNorm2d(64) self.conv12 = nn.Conv2d(64, 64, kernel_size=3, padding=1) self.bn12 = nn.BatchNorm2d(64) self.conv21 = nn.Conv2d(64, 128, kernel_size=3, padding=1) self.bn21 = nn.BatchNorm2d(128) self.conv22 = nn.Conv2d(128, 128, kernel_size=3, padding=1) self.bn22 = nn.BatchNorm2d(128) self.conv31 = nn.Conv2d(128, 256, kernel_size=3, padding=1) self.bn31 = nn.BatchNorm2d(256) self.conv32 = nn.Conv2d(256, 256, kernel_size=3, padding=1) self.bn32 = nn.BatchNorm2d(256) self.conv33 = nn.Conv2d(256, 256, kernel_size=3, padding=1) self.bn33 = nn.BatchNorm2d(256) self.conv41 = nn.Conv2d(256, 512, kernel_size=3, padding=1) self.bn41 = nn.BatchNorm2d(512) self.conv42 = nn.Conv2d(512, 512, kernel_size=3, padding=1) self.bn42 = nn.BatchNorm2d(512) self.conv43 = nn.Conv2d(512, 512, kernel_size=3, padding=1) self.bn43 = nn.BatchNorm2d(512) self.conv51 = nn.Conv2d(512, 512, kernel_size=3, padding=1) self.bn51 = nn.BatchNorm2d(512) self.conv52 = nn.Conv2d(512, 512, kernel_size=3, padding=1) self.bn52 = nn.BatchNorm2d(512) self.conv53 = nn.Conv2d(512, 512, kernel_size=3, padding=1) self.bn53 = nn.BatchNorm2d(512) # Decoder self.conv53d = nn.Conv2d(512, 512, kernel_size=3, padding=1) self.bn53d = nn.BatchNorm2d(512) self.conv52d = nn.Conv2d(512, 512, kernel_size=3, padding=1) self.bn52d = nn.BatchNorm2d(512) self.conv51d = nn.Conv2d(512, 512, kernel_size=3, padding=1) self.bn51d = nn.BatchNorm2d(512) self.conv43d = nn.Conv2d(512, 512, kernel_size=3, padding=1) self.bn43d = nn.BatchNorm2d(512) self.conv42d = nn.Conv2d(512, 512, kernel_size=3, padding=1) self.bn42d = nn.BatchNorm2d(512) self.conv41d = nn.Conv2d(512, 256, kernel_size=3, padding=1) self.bn41d = nn.BatchNorm2d(256) self.conv33d = nn.Conv2d(256, 256, kernel_size=3, padding=1) self.bn33d = nn.BatchNorm2d(256) self.conv32d = nn.Conv2d(256, 256, kernel_size=3, padding=1) self.bn32d = nn.BatchNorm2d(256) self.conv31d = nn.Conv2d(256, 128, kernel_size=3, padding=1) self.bn31d = nn.BatchNorm2d(128) self.conv22d = nn.Conv2d(128, 128, kernel_size=3, padding=1) self.bn22d = nn.BatchNorm2d(128) self.conv21d = nn.Conv2d(128, 64, kernel_size=3, padding=1) self.bn21d = nn.BatchNorm2d(64) self.conv12d = nn.Conv2d(64, 64, kernel_size=3, padding=1) self.bn12d = nn.BatchNorm2d(64) self.conv11d = nn.Conv2d(64, output_nc, kernel_size=3, padding=1)def forward(self, x): # Stage 1 x11 = F.relu(self.bn11(self.conv11(x)), inplace=True) x12 = F.relu(self.bn12(self.conv12(x11)), inplace=True) x1p, id1 = F.max_pool2d(x12, kernel_size=2, stride=2, return_indices=True) # Stage 2 x21 = F.relu(self.bn21(self.conv21(x1p)), inplace=True) x22 = F.relu(self.bn22(self.conv22(x21)), inplace=True) x2p, id2 = F.max_pool2d(x22, kernel_size=2, stride=2, return_indices=True) # Stage 3 x31 = F.relu(self.bn31(self.conv31(x2p)), inplace=True) x32 = F.relu(self.bn32(self.conv32(x31)), inplace=True) x33 = F.relu(self.bn33(self.conv33(x32)), inplace=True) x3p, id3 = F.max_pool2d(x33, kernel_size=2, stride=2, return_indices=True) # Stage 4 x41 = F.relu(self.bn41(self.conv41(x3p)), inplace=True) x42 = F.relu(self.bn42(self.conv42(x41)), inplace=True) x43 = F.relu(self.bn43(self.conv43(x42)), inplace=True) x4p, id4 = F.max_pool2d(x43, kernel_size=2, stride=2, return_indices=True) # Stage 5 x51 = F.relu(self.bn51(self.conv51(x4p)), inplace=True) x52 = F.relu(self.bn52(self.conv52(x51)), inplace=True) x53 = F.relu(self.bn53(self.conv53(x52)), inplace=True) x5p, id5 = F.max_pool2d(x53, kernel_size=2, stride=2, return_indices=True) # Stage 5d x5d = F.max_unpool2d(x5p, id5, kernel_size=2, stride=2) x53d = F.relu(self.bn53d(self.conv53d(x5d)), inplace=True) x52d = F.relu(self.bn52d(self.conv52d(x53d)), inplace=True) x51d = F.relu(self.bn51d(self.conv51d(x52d)), inplace=True) # Stage 4d x4d = F.max_unpool2d(x51d, id4, kernel_size=2, stride=2) x43d = F.relu(self.bn43d(self.conv43d(x4d)), inplace=True) x42d = F.relu(self.bn42d(self.conv42d(x43d)), inplace=True) x41d = F.relu(self.bn41d(self.conv41d(x42d)), inplace=True) # Stage 3d x3d = F.max_unpool2d(x41d, id3, kernel_size=2, stride=2) x33d = F.relu(self.bn33d(self.conv33d(x3d)), inplace=True) x32d = F.relu(self.bn32d(self.conv32d(x33d)), inplace=True) x31d = F.relu(self.bn31d(self.conv31d(x32d)), inplace=True) # Stage 2d x2d = F.max_unpool2d(x31d, id2, kernel_size=2, stride=2) x22d = F.relu(self.bn22d(self.conv22d(x2d)), inplace=True) x21d = F.relu(self.bn21d(self.conv21d(x22d)), inplace=True) # Stage 1d x1d = F.max_unpool2d(x21d, id1, kernel_size=2, stride=2) x12d = F.relu(self.bn12d(self.conv12d(x1d)), inplace=True) x11d = self.conv11d(x12d) # output = t.sigmoid(x11d) return x11d基于pytorch编译的SegNet模型结构代码
来源:https://github.com/fuweifu-vtoo/Semantic-segmentation/blob/master/models/seg_net.py
基准测试
测试数据
测试场景采用具有挑战性的室内场景数据集:SUN RGB-D,该数据集包含5285张训练图像及5050张测试图像,数据集的室内分割对象包括墙壁、地板、天花板、桌子、椅子、沙发、床等37个物体类型,由于不同对象具有各种形状、各种大小的姿势,且每个测试图像中通常存在许多不同的类别,对象之间常常会出现局部遮挡情况,使得分割任务变得困难。

SUN RGB-D数据集样图
来源:https://blog.csdn.net/u011622208/article/details/111152218
超参数设置
将SegNet与FCN ,DeepLabLargFOV 、DeconvNet等几种效果良好的深度分割模型进行基准测试比对。
为测试公平起见,各模型超参数统一设置为:
· 图像分辨率:360*480; · 优化器:SGD;
· 学习率:固定为10-3; · 动量:0.9;
· Epoch:100; · Batch-Size:4;
· Dropout:0.5;
精度测试

各模型在不同迭代次数上的精度结果
来源:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
· 随着训练迭代次数的不断增加,SegNet在整体精度上的提升要明显优于其他模型,并在迭代次数大于140k时,SegNet在全局准确率(Global Accracy,G)、类别准确率(Class Accracy,C)及边界F1分数(Boundary F1 Score,BF)上数值最优,在平均交并比(Mean Intersection over Union,mIoU)上略低于DeepLab-LargeFOV。
· 即便在测试结果上SegNet的表现最好,但实际各精度数值并不高, 一方面表明分割SUN RGB-D室内场景数据集的难度确实高,另一方面说明SegNet的依然有较大的改进空间。

SUN RGB-D 基准数据集中 37 个室内场景类别的 SegNet 预测的类平均准确率
来源:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
· 参照SegNet对37个室内场景的类平均准确率可以发现,像地板(Floor)、天花板(Ceiling)、储藏柜(Cabinet)等较大物体类别具有较合理的准确性,而较小的物体类别的准确率较低,从中可知,SegNet对较小目标物体的分割能力有限,本人认为可以通过输入更大尺寸数据的方式,以此加大SegNet对小目标物体的感知能力,从而提升整体的准确率。
图像测试
在图像测试结果中,SegNet的分割结果表现出了2个明显特征:
· 分割的各目标物体较为完整;
· 物体与物体之间的边界较为清晰且平滑;
在其余模型的分割结果中,DeepLab-LargeFOV的物体边界的锯齿状情况严重,DeconvNet的目标物体误分情况较多。

各模型图像测试结果
来源:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
存储成本、精度准确性及推理时间之间的平衡
SegNet虽然在架构上延用了编码器-解码器方式,但在结构上做出了一定改进,SegNet去掉了VGG16模型上的全连接层、并使用批量归一化,以及在上采样过程中利用池化索引等方式,降低了网络的计算量和存储需求,加快了网络推理速度。

360 × 480 分辨率图像下各模型的内存占用及推理时间
来源:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
· 由于DeepLab-LargrFOV及FCN(learnt deconv)在模型结构中不具有解码器结构,因此推理速度要优于SegNet,但在精度准确性上要低于SegNet;
· 与同样具有编码器-解码器结构的DeconvNet对比中,SegNet的结构更小,推理速度及精度准确性上明显占优;
· SegNet以1052MB的GPU内存占用率,远远小于其它模型的存储成本;
总结
相较于当前计算机视觉领域,各模型一味单方面追求速度或性能指标上,SegNet团队另辟蹊径,采用“中庸”策略,不断寻求存储成本、精度准确性及推理时间之间的平衡,减小模型架构、提升计算效率。
在解决物体边界划定不清的问题上,作者也有自己独到的见解,通过在编码阶段的下采样过程中存储最大池化索引,在解码阶段依据索引位置信息进行上采样,从而保留原始图像中更细致准确的边界信息。
SegNet并不是完美的,其在处理尺寸较小物体上的能力有限,分割效果不佳。在当前小尺寸分割依然困扰着每一位从业者,如何提升小尺寸分割精度仍然是未来的难点。
参考资料
【1】SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation;
【2】https://zhuanlan.zhihu.com/p/38871860;
【3】https://github.com/fuweifu-vtoo/Semantic-segmentation/blob/master/models/seg_net.py;
【4】https://blog.csdn.net/u011622208/article/details/111152218
【5】https://arxiv.org/abs/1511.00561