目录
什么是泛型
泛型的语法
泛型类的使用
类型推导
裸类型
泛型的上界
泛型方法
通配符
无界通配符
上界通配符
下界通配符
泛型是如何编译的
擦除机制
什么是泛型
泛型 是在 JDK 1.5 引入的新语法,是 Java 中的一个特性,在定义类、接口或方法时,使用类型参数来提高代码的灵活性和可重用性。通过泛型,可以在编写代码时不指定具体的类型,而是在使用时再指定,从而实现更通用的代码
例如:
需要实现一个 Box 类,类中包含一个数组成员 contents,contents 中存放数据的类型可以自行定义,可以通过方法获得数组中某个下标的值
我们可以想到:所有类的父类,都默认为 Object,那么,是否可以用 Object 来实现?
public class Box { private Object[] contents = new Object[20]; public void setContent(int pos, Object content) { if (pos < 0 || pos > contents.length) { throw new RuntimeException("下标越界"); } contents[pos] = content; } public Object getContent(int pos) { if (pos < 0 || pos > contents.length) { throw new RuntimeException("下标越界"); } return contents[pos]; }}尝试存放数据:
public class Test { public static void main(String[] args) { Box box = new Box(); box.setContent(0, "abc"); box.setContent(1, 20); }}由于 setContent 方法中,传递的元素数据类型为 Object,因此,数组中可以存放任意类型的数据
当我们获得数组中某个下标的值时,需要进行强制类型转换:
public class Test { public static void main(String[] args) { Box box = new Box(); box.setContent(0, "abc"); box.setContent(1, 20); String str = (String) box.getContent(0); String str2 = (String) box.getContent(1); }}若存放的元素类型与转换的类型不匹配时,就会抛出异常

因此,我们需要知道每个下标所存放的元素类型
在这种情况下,即使数组中存放的都是同一种类型的数据,但在取出元素时都需要进行强转
且数组可以存放任意类型的数据,但在更多情况下,我们希望其能够只存储一种数据类型,而不是同时存储多种数据类型
此时,我们就可以使用泛型,将我们需要的类型进行传递,指定当前容器需要持有什么类型的对象,让编译器去做检查
接下来,我们就来学习泛型的语法
泛型的语法
泛型类的定义:
class 泛型类名<类型形参列表> {
}
例如:
class Box<T> {}类名后面的 <T> 代表占位符,表示当前类是一个泛型类
T 代表了类型参数,表示未知类型,通常使用一个大写字母表示
在泛型类中,可以定义多个类型参数作为占位符:
public class Pair<K, V> {}其中,K 和 V 是两个不同的占位符,分布表示键和值的类型
在 Java 中,类型参数一般使用一个大写字母表示,且常用的名称有:
T:表示类型(Type)
E:表示元素(Element),常用于集合类
K 和 V:表示键(Key)和 值(Value),常用于映射(Map)
其中,类型参数不能为基本数据类型(如 int、char 等),可以使用其对应的包装类(如 Integer、Character 等)
我们对 Box 类进行改写:
但是,当我们创建 T 类型数组时:
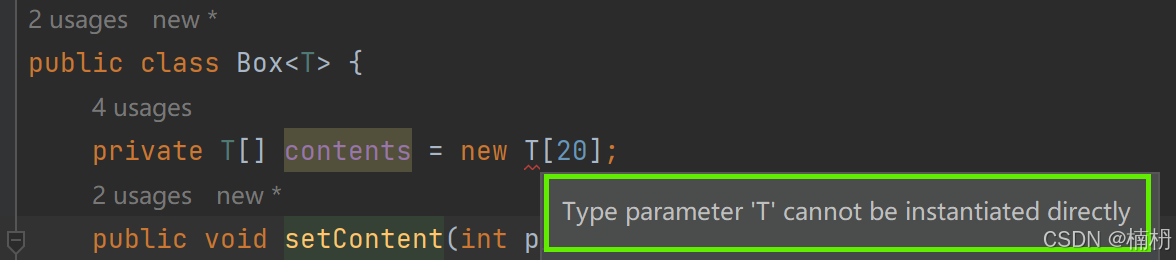
类型参数 T 不能直接实例化,也就是说,不能 new 泛型类型的数组
这是为什么呢?
关于这个问题,我们先不解决,在后面 类型擦除 时,再进行理解
我们仍然创建 Object 类型的数组,在传递元素类型时,传递 T 类型的数据,在获取指定下标元素时,返回 T 类型的数据
public class Box<T> { private Object[] contents = new Object[20]; public void setContent(int pos, T content) { if (pos < 0 || pos > contents.length) { throw new RuntimeException("下标越界"); } contents[pos] = content; } public T getContent(int pos) { if (pos < 0 || pos > contents.length) { throw new RuntimeException("下标越界"); } return (T) contents[pos]; }}泛型类创建好了,接下来,我们就来学习如何使用
泛型类的使用
要使用泛型类,我们首先需要实例化一个泛型类对象:
泛型类<类型实参> 变量名 = new 泛型类<类型实参>(构造方法实参);
相比于普通的类,泛型类需要传递类型实参
public class Test { public static void main(String[] args) { Box<String> box = new Box<String>(); }}new Box<String>() 中的实参类型可以省略:
public class Test { public static void main(String[] args) { Box<String> box = new Box<>(); }}这是因为编译器可以根据上下文进行类型推导
类型推导
类型推导(Type Inference)是指编译器根据上下文推断出泛型参数的具体类型。类型推导使得Java代码更简洁,减少了重复的类型参数声明,同时保持了类型安全性
Box<String> box = new Box<>(); // 可以推导出实例化需要的类型为 String
当我们未传递类型参数时,也不会报错:
Box box = new Box();
Box 是泛型类但并没有带类型实参,此时的 Box 是一个裸类型
裸类型
裸类型(Raw Type)是指没有指定类型参数的泛型类或接口。使用裸类型时,编译器不会进行类型检查,因此可能会导致类型安全问题
裸类型是为了兼容老版本的 API 保留的机制,其风险在于编译器无法检查类型的一致性,这也就可能会导致运行时错误
例如:
public class Test { public static void main(String[] args) { // 使用裸类型 Box box = new Box(); // 警告:使用裸类型 box.setContent(0, "Hello"); box.setContent(1, 123); // 允许的,但可能会导致问题 // 不安全的类型转换 String str = (String) box.getContent(1); // 运行时可能抛出 ClassCastException }}因此,我们应该尽量避免使用裸类型
泛型的上界
在定义泛型类时,有时需要对传入的类型变量做一定的约束,此时,可以通过类型边界来约束
类型边界,也就是泛型的上界,可以确保泛型类型参数是某个类或接口的子类或实现类
通过关键字 extends 来指定上界:
class 泛型类名称<类型形参 extends 类型边界> {
}
例如:
public class Box<T extends Number> {}Box 只接受 Number 的子类作为 T 的类型实参
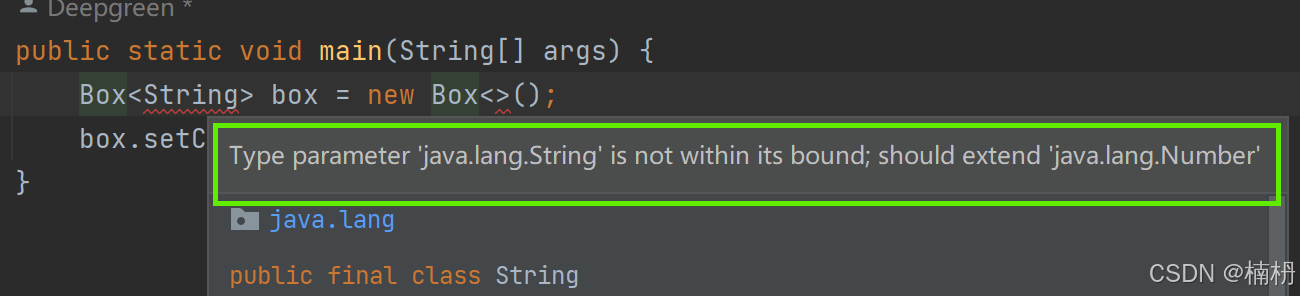
此时传递 String 类型,就会编译出错
使用上界,可以确保类型参数是某个类的子类,从而避免类型不匹配的问题
而当泛型的上界为接口时,表示传入的类型必须是实现了该接口的:
public class Box<T extends Comparable<T>> {}T 必须是实现了 Comparable 接口的
而在前面我们没有指定类型边界时,可看做 E extends Object
泛型方法
在方法中使用泛型类型参数,这使得方法可以处理不同类型的数据,而不需要进行强制类型转换
访问修饰符 <类型形参列表> 返回值类型 方法名称(形参列表) {
}
例如:
public class MyArray { // 泛型方法 public static <T> void printArray(T[] array) { for (T element : array) { System.out.println(element); } }}当使用静态的泛型方法时,需要在 static 后面用 <> 声明泛型类型参数
泛型方法也可以有多个类型参数:
public class Pair<K, V> { private K key; private V value; public Pair(K key, V value) { this.key = key; this.value = value; } public K getKey() { return key; } public V getValue() { return value; } // 泛型方法,返回 Pair 的字符串表示 public static <K, V> String displayPair(Pair<K, V> pair) { return "Key: " + pair.getKey() + ", Value: " + pair.getValue(); }}
通配符
? 在泛型中表示通配符
通配符是一种特殊的类型参数,表示一个不确定的类型
无界通配符
无界通配符使用 ? 表示,表示可以接受任何类型,常用于方法参数中:
public void printList(List<?> list) { for (Object element : list) { System.out.println(element); }}
上界通配符
上界通配符使用 ? extends T 表示,表示可以接受 T 的子类或 T 本身,常用于需要读取数据但不修改数据的情况:
public void processAnimals(List<? extends Animal> animals) { for (Animal animal : animals) { animal.makeSound(); // 只读取 Animal 类型 }}在使用上界通配符时,可以安全地读取数据,因为集合中的元素是 T 类型或其子类,因此,我们可以调用 T 的方法
但我们只知道集合中的元素类型是 T 的某个子类,无法确定其具体的类型,因此,无法向集合中添加元素:
List<? extends Animal> animals = new ArrayList<Dog>();animals.add(new Cat()); // 编译错误在上述例子中,animals 可以是 Dog 类型的列表,也可以是 Cat 类型的列表,若我们允许添加 Cat,就会破坏 List<Dog> 的类型,导致类型不一致
下界通配符
下界通配符使用 ? super T 表示,表示可以接受 T 的超类或 T 本身,常用于需要向集合中添加数据的情况:
List<? super Dog> animals = new ArrayList<Animal>();animals.add(new Dog());在使用下界通配符时,我们可以安全的添加类型为 T 及其子类的对象,因为集合中的元素类型是 T 的超类或 T 本身,因此,可以确保我们添加的数据是合法的
但是,由于我们只知道集合中的元素类型是 T 的超类,无法确定实际的元素类型,由于可能会存在多种不同的超类,因此,无法安全地将读取到的元素强制转换为 T 或其子类
List<? super Dog> animals = new ArrayList<Animal>();Animal animal = animals.get(0); // 编译错误,因为我们不知道具体类型
泛型是如何编译的
我们查看 Box 的字节码文件:
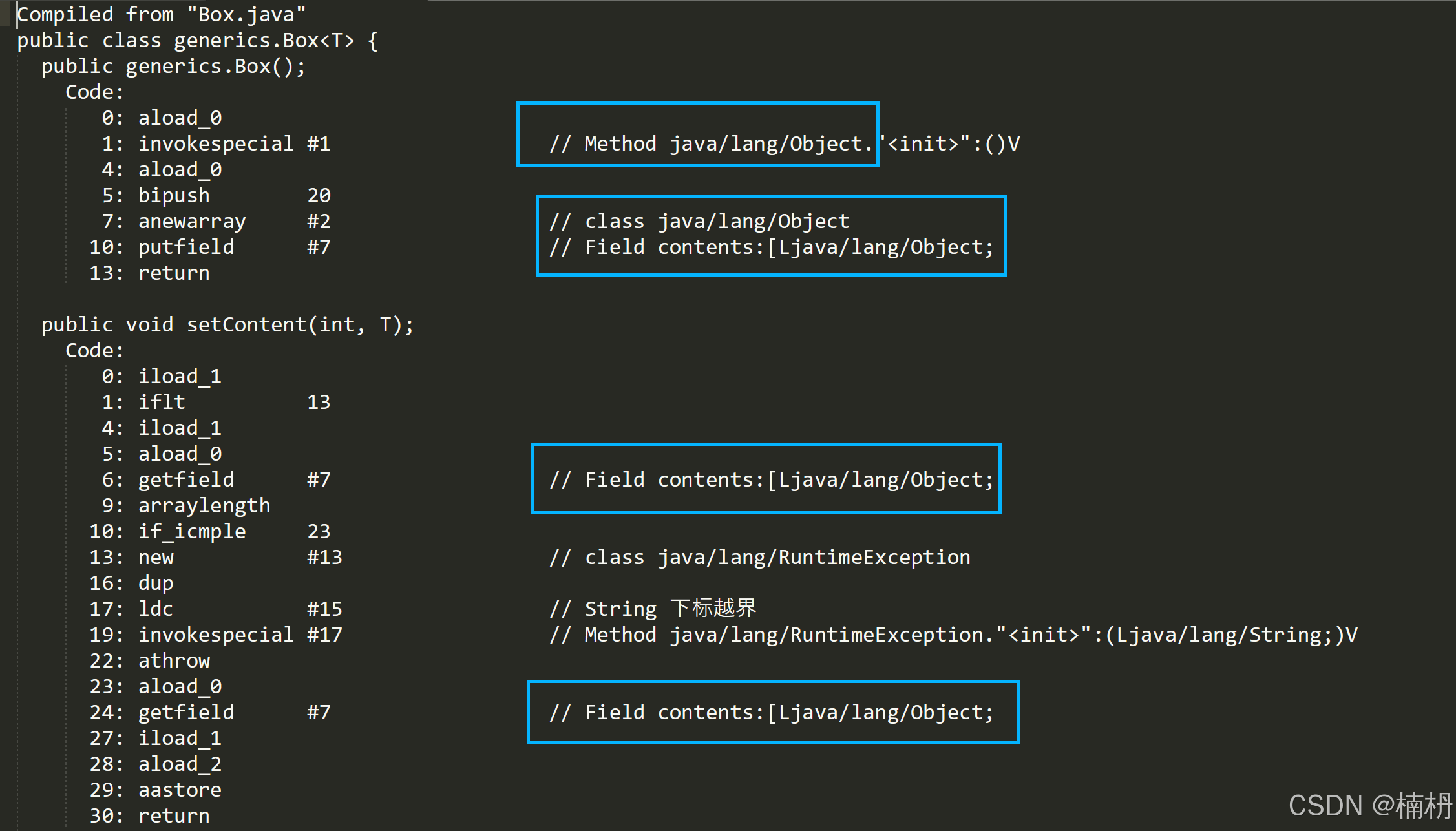
可以看到,所有的 T 都是 Object 类型的
在编译过程中,将所有的T替换为 Object 这种机制,我们称为:擦除机制
擦除机制
在Java中,类型擦除是指在编译期间,泛型类型的信息被移除的过程。这意味着在运行时,Java虚拟机(JVM)只知道原始类型,而不保留泛型类型参数的信息。这种机制确保了Java的兼容性,同时允许泛型代码与旧版本的Java代码一起工作。
当编译器遇到泛型类型时,会进行以下操作:
(1)替换类型参数: 将泛型类型参数替换为其边界类型或 Object(如果没有边界)
(2)添加强制类型转换:在需要时添加类型转换,以确保类型安全
例如,存在泛型类:
public class Box<T> { private T item; public void setItem(T item) { this.item = item; } public T getItem() { return item; }}在编译时,编译器会生成与以下非泛型类等效的代码:
public class Box { private Object item; public void setItem(Object item) { this.item = item; } public Object getItem() { return item; }}正是由于擦除机制的存在,因此不能创建泛型类型的实例,如 new T(),因为 Java 的泛型实现依赖于类型擦除。在编译时,泛型类型参数(如 T)会被替换为其边界类型(如 Object),这意味着在运行时,JVM并不知道 T 是什么类型。因此,无法创建一个特定类型的实例
上述不能 new 泛型类型的数组也是由于擦除机制的存在,编译时,泛型类型会被替换为它们的原始类型。这意味着在运行时,所有的泛型信息都被丢失。因此,如果允许创建泛型数组,就会导致运行时类型不安全
那么,能否这样写呢?
private T[] contents = (T[]) new Object[20];
也是不能的
因为在进行类型擦除时,意味着 T 的实际类型信息在运行时是不可用的。因此,直接将 Object 数组转换为 T 类型数组可能会导致类型安全问题,例如,在 contents 中存放了不符合 T 类型的对象,在读取时就会抛出 ClassCastException
这行代码也会触发 unchecked cast 警告:

因为编译器无法保证 Object[] 中的元素能被安全地视为 T[]
那么,我们就是想要创建 T 类型的数组,该如何实现呢?
可以通过反射创建指定类型的数组:
public class Box<T extends Student> { private T[] contents = null; public Box(Class<T> c, int capacity) { contents = (T[]) Array.newInstance(c, capacity); }}