最近一直在研究如何打算属于我自己的J.A.R.V.I.S.(钢铁侠中的机器人管家)。
上一篇写了我最近在部署自己的大模型,使用llama3.1, 和通义千问2。虽然最终结果也是成功了,过程却十分地坎坷。
所以这一篇文章一是总结其中遇到的问题,软件、硬件,想到什么就写什么,算是随笔吧。也给后面自己部署的同学们写个避雷指南。

关于自己部署AI大模型踩的坑 之二 —— GPU篇
关于CPU和GPU运算的区别,相信稍微涉及到计算机底层运行的同学们都会了解。这也是为什么在运算量如此之大,参数如此之多的大模型环境下,更需要GPU的原因了。
一秒看懂CPU和GPU的区别
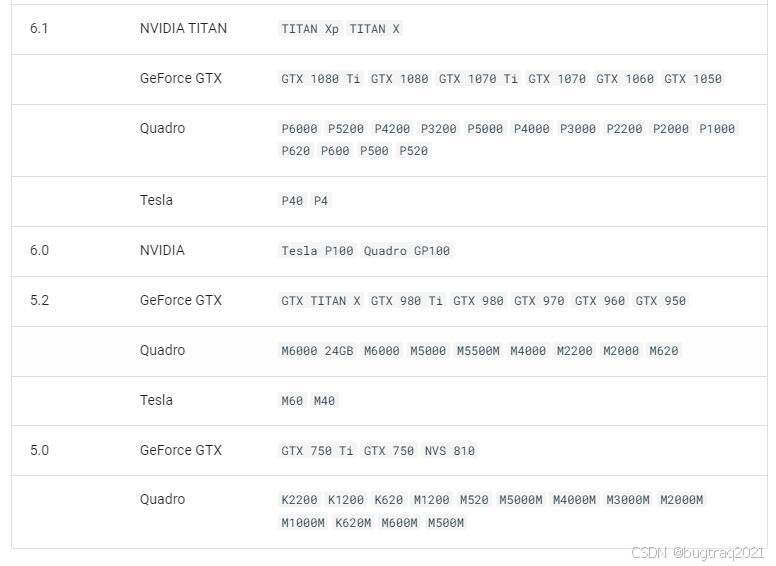
GPU选择之关键——计算能力(Compute Capability)
比如我现在使用的是Ollama部署大模型,而Ollama对于GPU的推荐使用计算能力要在6.0或以上,对于5.0和5.2的设备支持,但有时候会有些小问题,对于不支持的设备,Ollama会自动回退到CPU模式,GPU将不会被使用。
NVIDIA GPU 算力表见链接:
https://developer.nvidia.com/cuda-gpus
CUDA C++ Programming Guide
Nvidia显卡 Compute Capability表

Ollama 支持以下 AMD GPU:

Ollama 利用 AMD ROCm 库,该库不支持所有 AMD GPU。在某些情况下,您可以强制系统尝试使用类似的 LLVM 目标。例如,Radeon RX 5400 是 gfx1034(也称为 10.3.4),但 ROCm 当前不支持此目标。最接近的支持是 gfx1030。您可以使用环境变量 HSA_OVERRIDE_GFX_VERSION 与 x.y.z 语法。例如,要强制系统在 RX 5400 上运行,您应设置环境变量 HSA_OVERRIDE_GFX_VERSION="10.3.0"。如果您有不受支持的 AMD GPU,可以尝试使用下面列出的受支持类型。
目前已知的受支持 GPU 类型为以下 LLVM 目标。此表显示了映射到这些 LLVM 目标的一些示例 GPU:

GPU选择总结:
如果还没有购买GPU的同学,可以认真阅读理解这篇文章。尽量部署Ollama支持的GPU。
当然,如果你已经有GPU,并且算力支持,那恭喜你,可以开始下一步部署工作了;如果不支持,后期我也会写修改和编译Ollama源码,支持GPU的内容。