
在 C++ 中,bitset 和 Bloom Filter 是两种重要的数据结构,分别用于处理位操作和概率性数据存储。接下来,我们将详细探讨这两种结构的定义、实现、应用场景及其优缺点。
一、C++ 中的 bitset
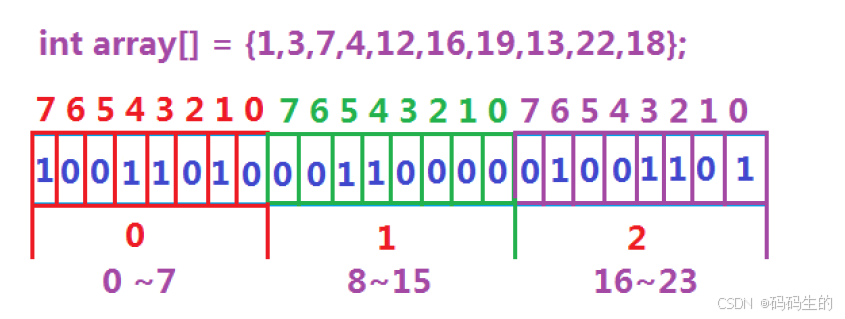
1. 定义
bitset 是 C++ 标准库中的一个类模板,主要用于管理固定大小的位集合。它能够在一个单一的对象中存储多个二进制位,非常适合用于需要高效存储和快速访问位信息的场景。
2. 基本特性
固定大小:创建bitset 时需要指定大小,一旦定义,大小不能改变。位操作:支持与、或、异或等位操作。高效存储:每个位占用一个比特空间,内存使用效率高。访问便利:支持下标操作,可以直接通过索引访问某个位。 3. 使用示例
#include <iostream>#include <bitset>int main() { std::bitset<8> bset; // 创建一个大小为8的bitset bset.set(1); // 设置第1位为1 bset.set(3); // 设置第3位为1 std::cout << "Bitset: " << bset << std::endl; // 输出:00001010 bset.flip(2); // 翻转第2位 std::cout << "After flip: " << bset << std::endl; // 输出:00001110 std::cout << "Size: " << bset.size() << std::endl; // 输出:8 std::cout << "Count of set bits: " << bset.count() << std::endl; // 输出:3 return 0;}4. 应用场景
标记数据:适用于需要标记大量布尔值的场景,比如图的遍历。内存管理:用于管理大量的开关状态。算法优化:在某些算法中,如快速查找、去重等场景中,能够提高性能。5. 优缺点
优点:
内存占用少,速度快。支持丰富的位操作,灵活性强。缺点:
大小固定,无法动态调整。仅适用于较小规模的位操作。6.模拟实现
#include<iostream>#include<vector>using namespace std;namespace zone{template<size_t n>class bitset{bitset(){bit.resize(N / 32 + 1, 0);//记得要加1;}void set(size_t x){size_t i = x / 32;size_t j = x % 32;bit[i] |= 1 << j;//要求第j个比特位是1,其余位都是0//因为vs是小端存储,1是这样:(低)01 00 00 00(高),而左移并不是向左移动,而是向高位移动!!!!}void reset(size_t x){size_t i = x / 32;size_t j = x % 32;bit[i] &= ~(1 << j);//要求第j个比特位是0,其余位都是1,与上文要求相反,可以直接取反}bool test(size_t x){size_t i = x / 32;size_t j = x % 32;return bit[i] &(1<<j);//这里很巧妙,如果原位置上是0,那么返回就是false(0),如果不是0,则无论是多少,都返回true(非零)}private:vector<int> bit;};}二、Bloom Filter
1. 定义
Bloom Filter 是一种空间效率极高的概率性数据结构,主要用于检测某个元素是否在集合中。与 bitset 不同,Bloom Filter 允许出现一定的误判,即可能会错误地判断某个元素在集合中(假阳性),但绝不会漏掉真实存在的元素(假阴性)。
2. 基本特性
多哈希函数:Bloom Filter 使用多个哈希函数来映射元素到位数组。误判概率:通过适当的位数组大小和哈希函数数量,可以控制误判率。不可删除:一旦元素被添加到 Bloom Filter 中,无法删除。3. 使用示例
#include <iostream>#include <vector>#include <functional>#include <bitset>class BloomFilter {private: std::vector<bool> bits; size_t size; int hashCount; size_t hash1(const std::string& str) { std::hash<std::string> hash_fn; return hash_fn(str) % size; } size_t hash2(const std::string& str) { std::hash<std::string> hash_fn; return (hash_fn(str) / size) % size; }public: BloomFilter(size_t n, int k) : size(n), hashCount(k) { bits.resize(n); } void add(const std::string& str) { for (int i = 0; i < hashCount; ++i) { bits[hash1(str)] = true; bits[hash2(str)] = true; } } bool contains(const std::string& str) { for (int i = 0; i < hashCount; ++i) { if (!bits[hash1(str)] || !bits[hash2(str)]) { return false; // 如果有一个哈希位置为0,说明一定不在 } } return true; // 否则可能在 }};int main() { BloomFilter bf(100, 2); bf.add("hello"); bf.add("world"); std::cout << "Contains 'hello': " << bf.contains("hello") << std::endl; // 输出:1 std::cout << "Contains 'world': " << bf.contains("world") << std::endl; // 输出:1 std::cout << "Contains 'test': " << bf.contains("test") << std::endl; // 输出:0(可能误判为1) return 0;}4. 应用场景
数据库:在数据库中快速判断某个记录是否存在于索引中。网络:在网络应用中检查请求的 URL 是否在某个黑名单中。缓存系统:在大规模缓存中快速判断数据是否在缓存中,避免不必要的查找。5. 优缺点
优点:
占用内存少,适合大规模数据。能够快速判断元素是否存在。缺点:
可能产生误判。无法删除元素,更新数据时可能会导致误判率增加。6.模拟实现
#include<iostream>#include<string>#include<bitset>using namespace std;namespace zone{struct BKDRHash{size_t operator()(const string& s){// BKDRsize_t value = 0;for (auto ch : s){value *= 31;value += ch;}return value;}};struct APHash{size_t operator()(const string& s){size_t hash = 0;for (long i = 0; i < s.size(); i++){if ((i & 1) == 0){hash ^= ((hash << 7) ^ s[i] ^ (hash >> 3));}else{hash ^= (~((hash << 11) ^ s[i] ^ (hash >> 5)));}}return hash;}};struct DJBHash {size_t operator()(const string& s){size_t hash = 5381;for (auto ch : s){hash += (hash << 5) + ch;}return hash;}};template<size_t N,class K=string,class hashfunc1= BKDRHash, class hashfunc2=APHash, class hashfunc3=DJBHash>class boomfilter{void Set(const K& key){size_t hash1 = hashfunc1()(key) % N;//这里使用了临时变量生成了函数size_t hash2 = hashfunc2()(key) % N;size_t hash3 = hashfunc3()(key) % N;bs.set(hash1);bs.set(hash2);bs.set(hash3);}bool Test(const K& key){//false一定是准确的size_t hash1 = hashfunc1()(key) % N;//这里使用了临时变量生成了临时函数size_t hash2 = hashfunc2()(key) % N;size_t hash3 = hashfunc3()(key) % N;if (bs.test(hash1) == false)return false;if (bs.test(hash2) == false)return false;if (bs.test(hash3) == false)return false;//true是有可能误判的return true;} private: bitset<N> bs;};三、总结与比较
1. 相同点
高效存储:两者都能够在内存使用上做到高效。位操作:都可以在位级别进行操作,适合处理布尔类型的数据。2. 不同点
用途:bitset 主要用于存储和操作固定数量的布尔值,而 Bloom Filter 是一种概率性数据结构,主要用于检测元素是否存在于集合中。误判:bitset 是准确的,而 Bloom Filter 则允许一定的误判。大小调整:bitset 大小固定,而 Bloom Filter 可以根据需要动态调整。 3. 选择建议
如果你的应用场景需要准确的布尔值存储和操作,且数据规模不大,使用bitset 更加合适。如果你处理的是海量数据,且可以接受一定的误判,Bloom Filter 是一个更好的选择。 四、总结
bitset 和 Bloom Filter 是 C++ 中处理位操作和概率性存储的强大工具。通过深入理解这两种数据结构的特性、应用及其优缺点,我们可以在实际开发中做出更好的选择。在现代应用中,掌握这些工具能极大提升程序的性能和内存利用率,是程序员必备的技能之一。