深搜
深搜简单来说就是一直递归到底,然后返回,以二叉树为例,就是从根节点出发一直搜索到叶子节点,然后想上返回。
这里简单说明一下:深搜的英文缩写是 dfs,下面定义深搜函数名我直接命名为 dfs
实战演练
计算布尔二叉树的值
https://leetcode.cn/problems/evaluate-boolean-binary-tree/description/
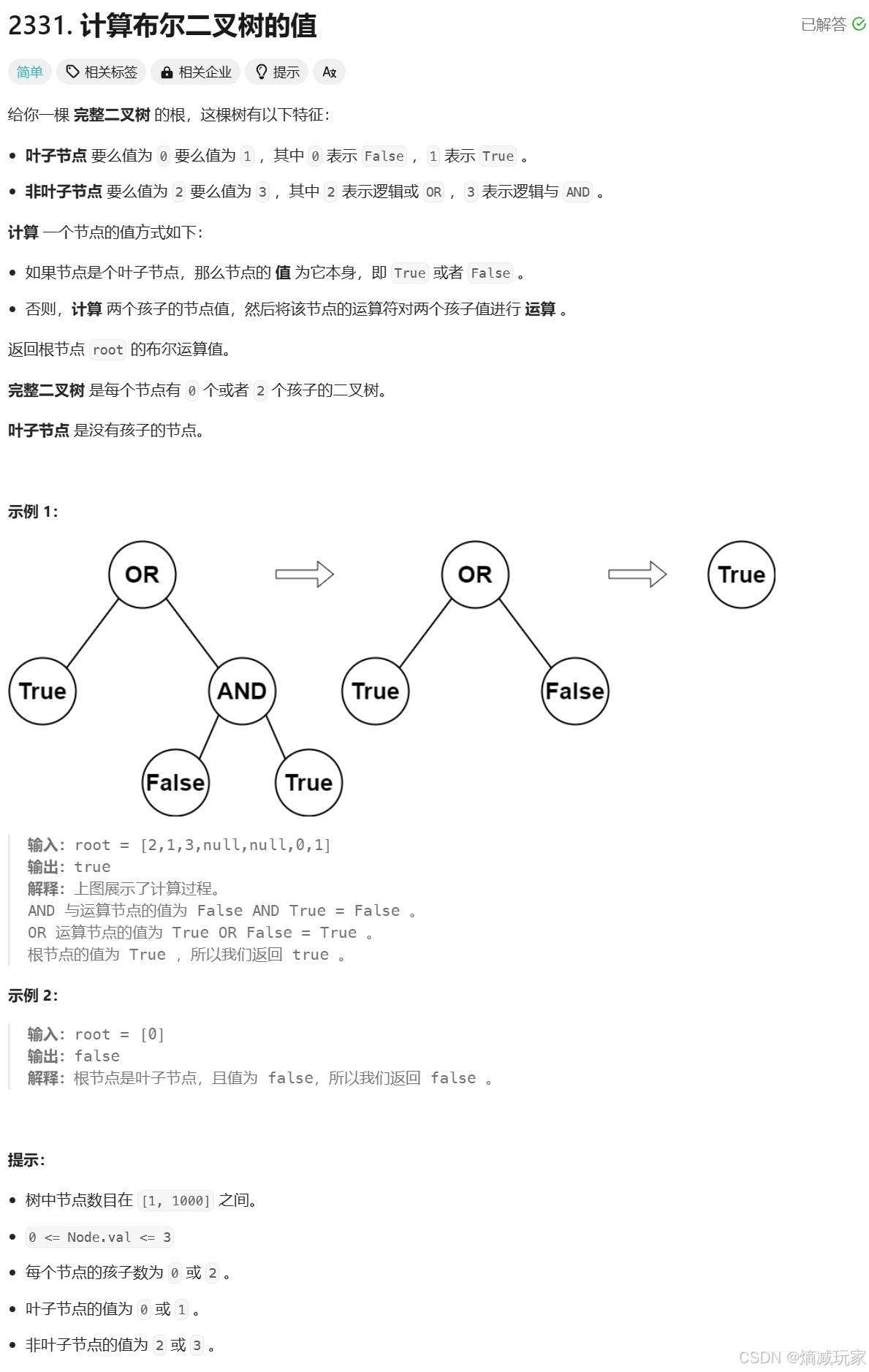
看到二叉树的题目,大家应该都会首选递归来解决,现在我们来思考如何递归:
首先分解主问题,要想求出二叉树布尔值,首先要知道左子树和右子树的布尔值,再通过根节点进行布尔运算
如何得到左右子树的布尔值,还是一样,根据上面的操作,那么我们就完成了问题的拆分,成功获得了子问题,函数的参数是需要根节点即可。
最后我们来看一下递归的出口,当我们遇到的节点为0 / 1 时,我们直接返回 false / true 即可。
回顾上面的递归操作,从根节点一直递归到叶子节点,这就是深搜。
class Solution { public boolean evaluateTree(TreeNode root) { if(root.val == 1) return true; else if(root.val == 0) return false; boolean left = evaluateTree(root.left); boolean right = evaluateTree(root.right); return root.val == 2 ? left | right : left & right; }}求根节点到叶节点数字之和
https://leetcode.cn/problems/sum-root-to-leaf-numbers/
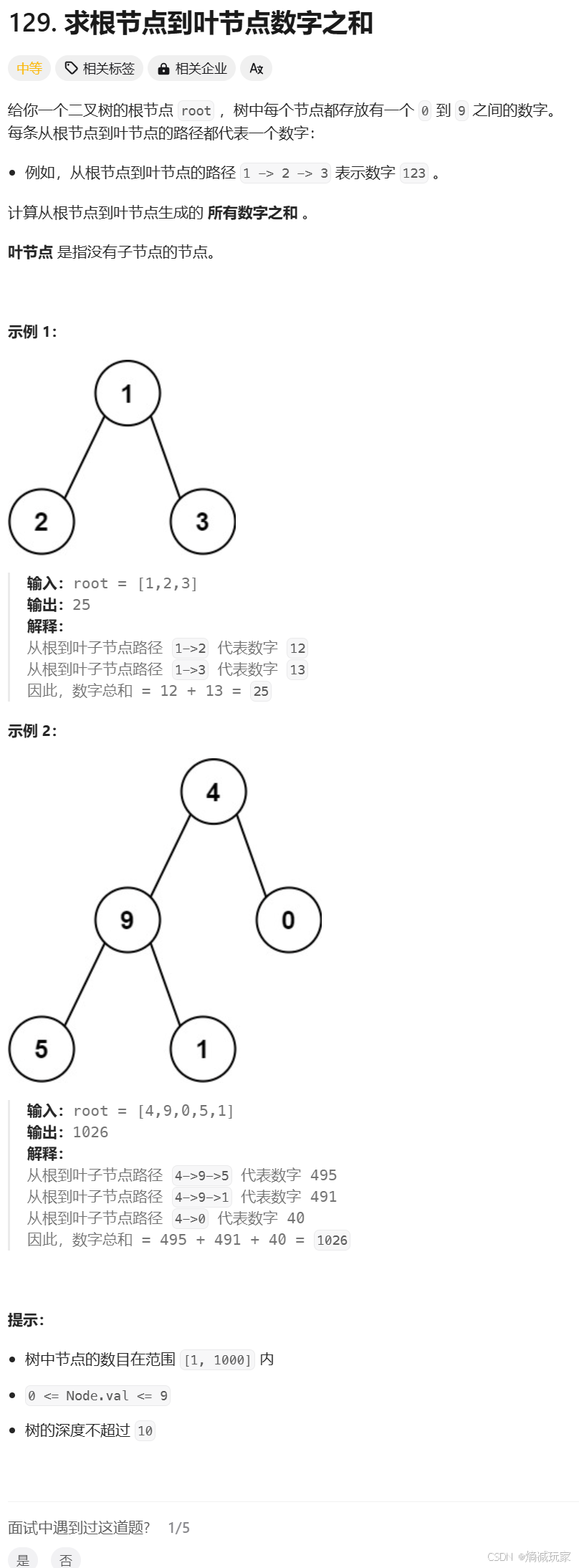
找出子问题:要想求出根节点到叶子节点的数字之和,需要知道左子树和右子树的数字之和,然后进行相加,就可以得出答案,要想求出左右子树的数字之和,还是按照上面的操作。
现在我们来分析函数参数的设计,首先根节点是一定要知道的,其次就是前面得到的数字之和,有了前面的数字之和我们就可以计算当前节点的数字之和:
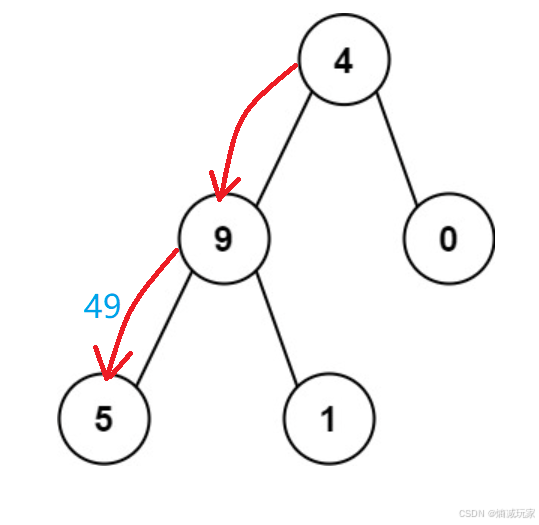
就像上图所示,当递归到 5 这个节点的时候,我们需要获取到前面的 49, 然后计算得到目前节点的数值 49 * 10 + 5 = 495
我们先看代码:
class Solution { public int sumNumbers(TreeNode root) { return dfs(root, 0); } int dfs(TreeNode root, int sum) { sum = sum * 10 + root.val; int count = 0; if(root.left != null) count += dfs(root.left, sum); if(root.right != null) count += dfs(root.right, sum); return count == 0 ? sum : count; }}你会发现我这里没有设计函数的出口,为什么?首先题目的节点个数是大于等于 1 的,所以我们在进行递归的时候,如果发现不存在左子树就不用进去,不存在右子树也不用进去,这其实就是剪枝的思想,既然我们不会进到空节点,也就没有 节点为空的情况,自然不需要再前面加递归的出口。
然后就是先计算当前节点的数字之和,接着获取左子树和右子树的数字之和,最后返回两者之和即可。
这里要注意 count 这个变量,因为初始状态设置为 零,所以当我们遇到叶子节点的时候,是不会进行左右子树的搜索的,这时候就不能直接返回 count ,而是返回这个节点的数字之和。
二叉树剪枝
https://leetcode.cn/problems/binary-tree-pruning/description/
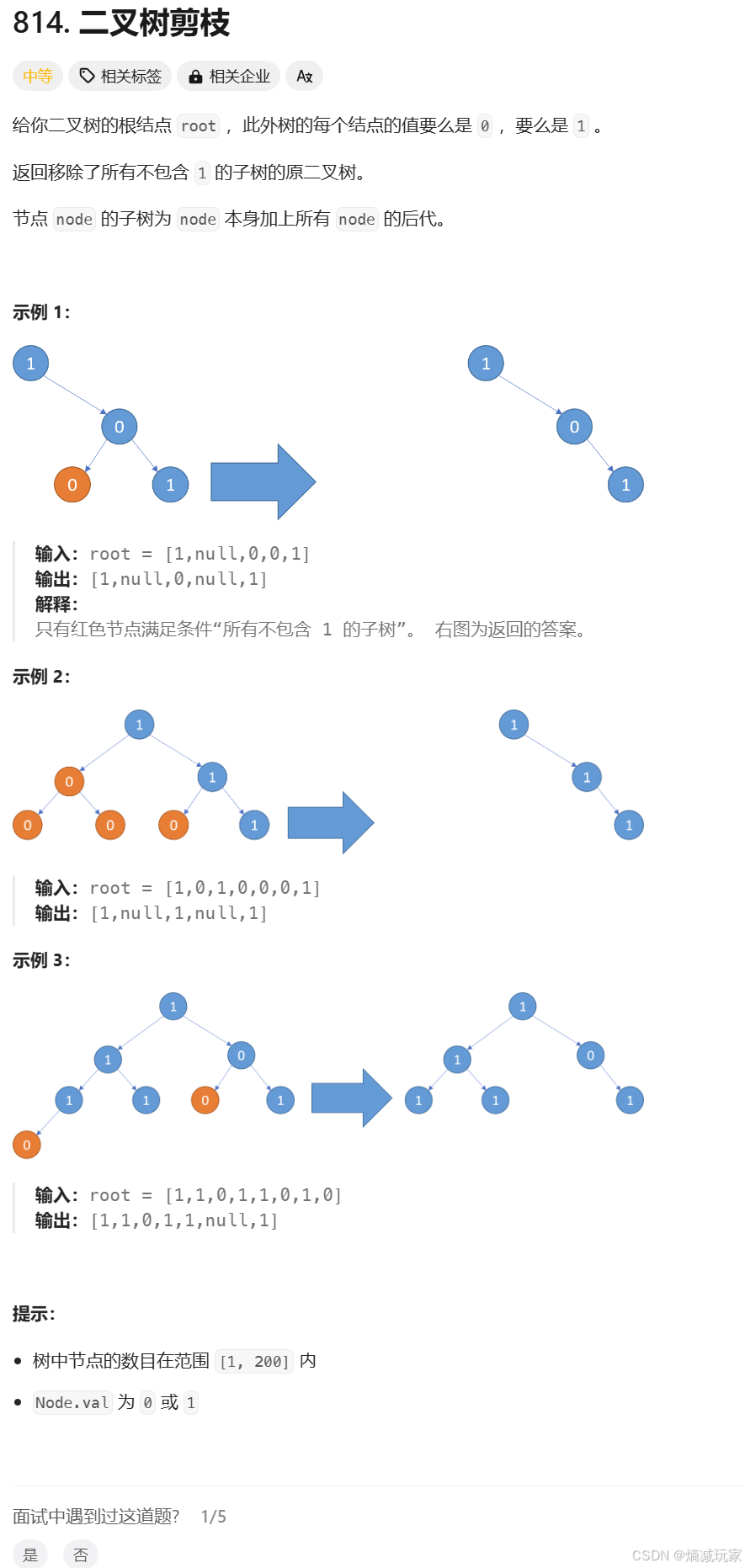
我们进行深搜的时候,什么时候进行剪枝?当发现根节点的左边和右边都为空并且根节点的数值为 0 的时候,需要裁剪,那么函数需要传递的参数就是根节点。
函数体的设计:首先我们要得到根节点左右子树是否为空,那么需要进行递归,先看看左子树是否需要裁剪,再看看右子树是否需要裁剪,最后根据前面我们得到的条件来判断是否需要进行根节点的裁剪。
递归出口:当节点为空,直接返回。
class Solution { public TreeNode pruneTree(TreeNode root) { if(root == null) { return root; } root.left = pruneTree(root.left); root.right = pruneTree(root.right); if(root.val == 0 && root.left == null && root.right == null) { return null; } return root; }}验证二叉搜索树
https://leetcode.cn/problems/validate-binary-search-tree/description/

首先我们知道二叉树搜索树中序遍历会得到一个有序的数据,所以我们可以利用这一个特性来解决这个问题。
首先深搜使用的是中序遍历,参数为根节点,然后我们需要一个全局变量来记录上一个节点的数值
这里直接上代码:
class Solution { long prev = Long.MIN_VALUE; public boolean isValidBST(TreeNode root) { if(root.left != null && !isValidBST(root.left)) return false; if(root.val > prev) { prev = root.val; } else { return false; } if(root.right != null && !isValidBST(root.right)) return false; return true; }}当我们知道左子树已经不是二叉搜索树的时候,我们就不需要进行后面的操作,直接返回false,这就是剪枝的思想。
这里要注意由于二叉树最小数值可能为 2 ^ -31,所以我们设置 prev 全局变量的时候,要使用 Long.MIN_VALUE。
二叉搜索树中第 k 小的元素
https://leetcode.cn/problems/kth-smallest-element-in-a-bst/description/
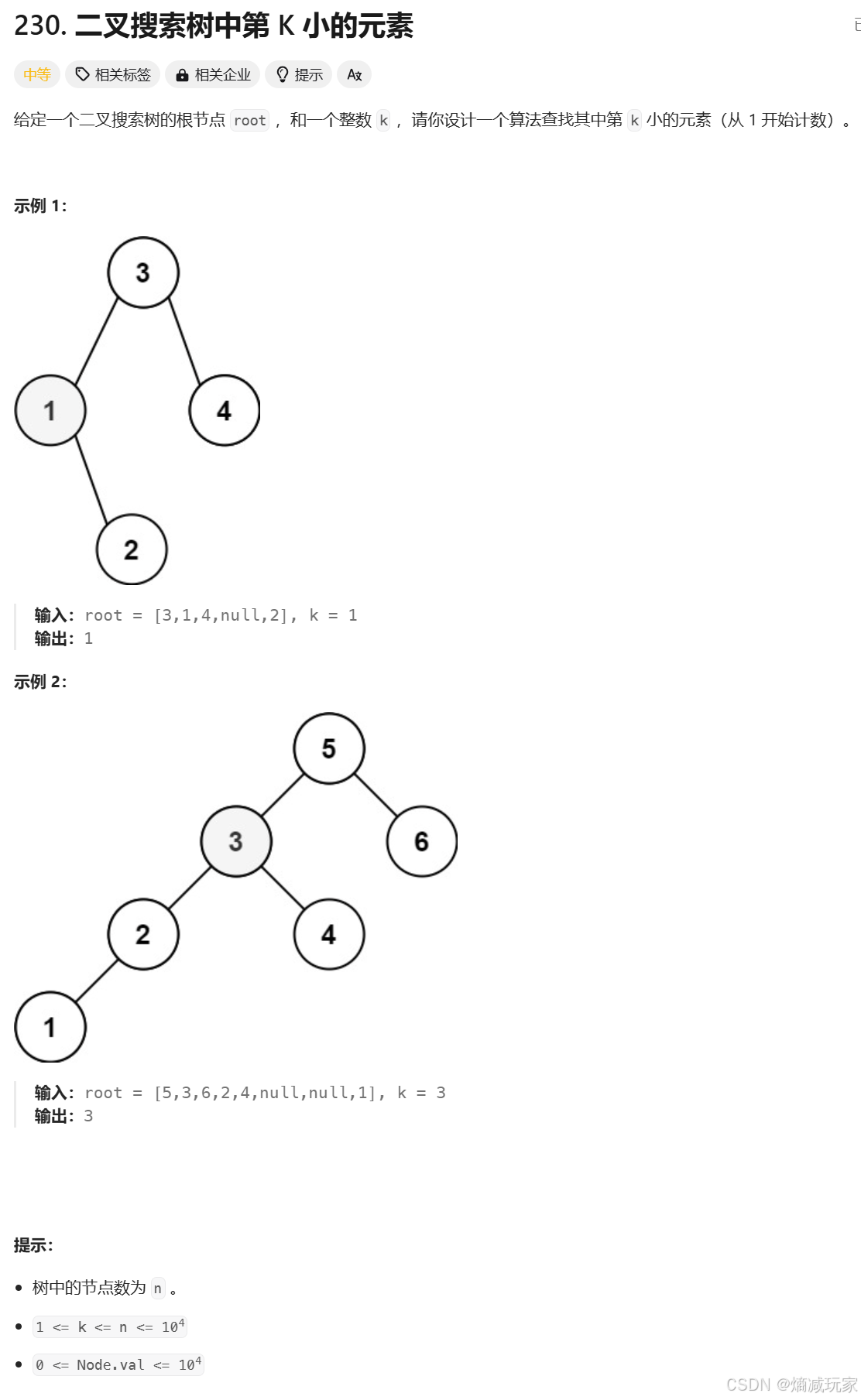
这里定义两个全部变量,一个记录当前是否为第 k 小,一个记录当前获得的数值。
之后进行中序遍历,当 count == 0 时直接返回答案。
这里要注意当左子树不为空,才进行深搜,右子树同理。
class Solution { int prev = 0; int count = 0; public int kthSmallest(TreeNode root, int k) { count = k; return dfs(root); } int dfs(TreeNode root) { if(count == 0) { return prev; } if(root.left != null) { dfs(root.left); } if(count == 0) { return prev; } else { prev = root.val; count--; } if(root.right != null) { dfs(root.right); } return prev; }}二叉树的所有路径
https://leetcode.cn/problems/binary-tree-paths/description/
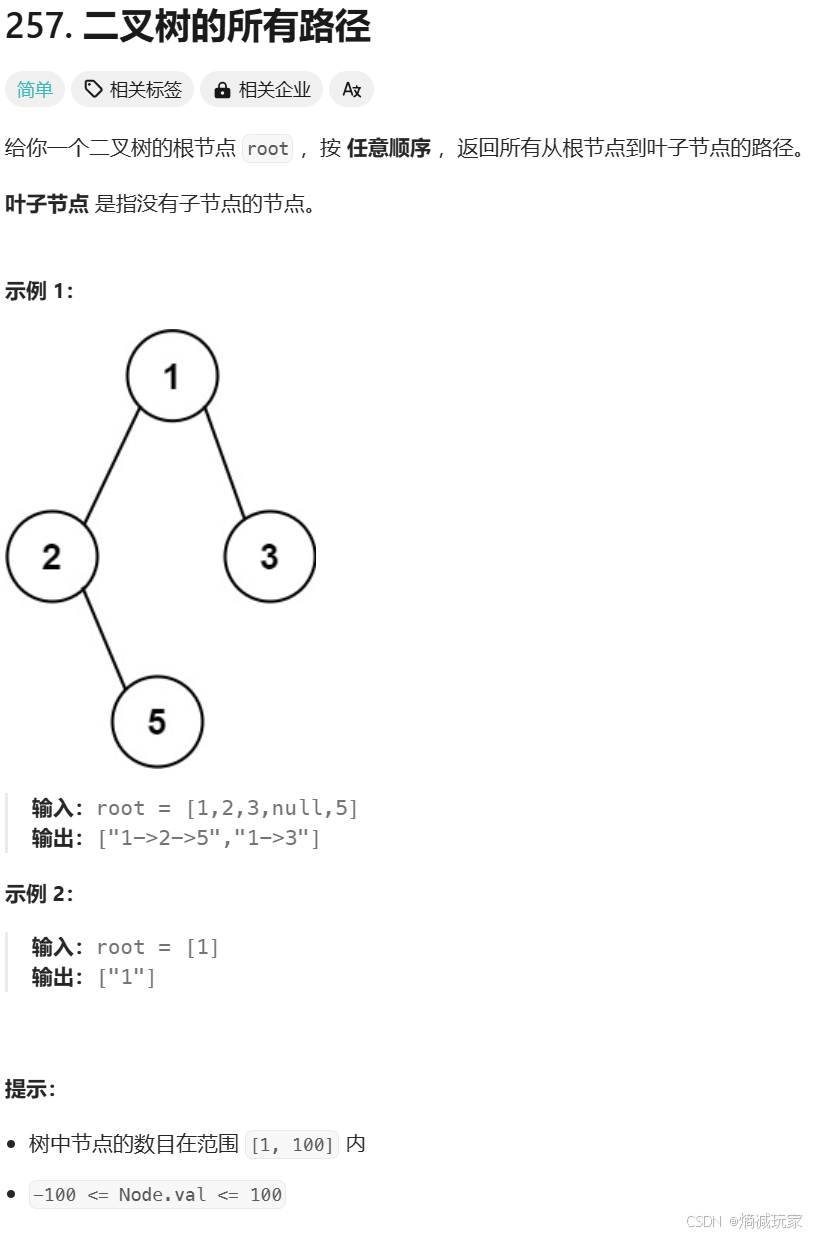
这里我们使用 StringBuffer 来作为参数,因为 String 进行频繁的插入是很慢的。
定义全部变量 ans ,进行链表的接收。
注意在深搜函数中我们不能直接修改 参数 _path,因为这是一个引用变量,你的修改是真的会影响到这个 path的,所以这里采用新建立一个 path
函数递归流程:首先先拼接当前节点的数值,然后检查该节点是否为叶子节点,如果是,则直接返回链表,如果不是则需要添加一个 ->,然后进行左子树和右子树的深搜,这里我采用剪枝的思想,只用左右子树存在的时候才进行深搜,所以没有递归出口 root == null 这种情况的出现。
class Solution { List<String> ans = new ArrayList<>(); public List<String> binaryTreePaths(TreeNode root) { return dfs(root, new StringBuffer()); } List<String> dfs(TreeNode root, StringBuffer _path) { StringBuffer path = new StringBuffer(_path); path.append(root.val); if(root.left == null && root.right == null) { ans.add(path.toString()); return ans; } path.append("->"); if(root.left != null) { dfs(root.left,path); } if(root.right != null) { dfs(root.right,path); } return ans; }}