
目录
前言
NumPy
常见IO函数
save()和load()
savez()
loadtxt()和savetxt()
练习
前言
在数据分析中,我们经常需要从文件中读取数据或者将数据写入文件,常见的文件格式有:文本文件txt、CSV格式文件(用逗号分隔)、二进制文件等。
Numpy可以读写磁盘上的文本数据或者二进制数据。为ndarray对象引入了一个简单的文件格式:npy。用于存储重建ndarray所需的数据、图形、dtype等信息。
NumPy
常见IO函数
在Numpy中,常见的IO函数有:
loadtxt()和savetxt():处理正常的文本文件和CSV文件。load()和save():读写文件数组数据的两个主要函数,默认情况下,是以未压缩的原始二进制格式保存在.npy文件中;savez():用于将多个数写入文件。默认情况下,数组是以未压缩的原始二进制格式保存在扩展名为 .npz 的文件中save()和load()
numpy.save(file, arr, allow_pickle=True, fix_imports=<no value>)
想了解更多关于save函数的知识,可以查看:
numpy.save — NumPy v2.1 手册
file:文件的路径;arr:所要保存的数组;allow_pickle:bool,可选,允许使用python pickles保存对象数组。默认True。fix_imports:bool,可选,不过已经弃用,忽略。文件拓展名为.npy。
numpy.load(file,mmap_mode=None,allow_pickle=False,fix_imports=True,encoding='ASCII')
file:所要读取的文件路径;mmap_mode:None,{‘r+’,'r','w+','c'}可选;一个 内存映射数组保存在磁盘上。但是,可以访问它 并像任何 ndarray 一样进行切片。内存映射特别有用 用于访问大文件的小片段,而无需读取 整个文件复制到内存中。
| ‘r' | 打开现有文件仅供读取 |
| 'r+' | 打开现有文件进行读取和写入 |
| 'w+' | 常见或覆盖现有文件以进行读取和写入。如果shape也必须指定,那么mode='w+' |
| ‘c’ | Copy-on-write:赋值会影响内存中的数据,但更改不会保存到磁盘,磁盘上的文件为只读。 |
max_header_size:int,可选。标头允许的最大大小。大标头可能不安全 以安全地加载,因此需要显式传递更大的值。 有关详细信息,请参阅。 传递 allow_pickle 时,将忽略此选项。在那种情况下 根据定义,该文件是可信的,并且限制是不必要的。
示例:
# 首先存储数组数据,生成.npy文件import numpy as np#这里利用相对路径来存储fileName = './text.npy'# 生成数组a = np.arange(24).reshape(2,3,4)print(a)#保存到文件中np.save(fileName,a)当运行完上面的代码,我们可以打开我们在编写代码下的文件夹:

当我们用记事本打开后,会发现是一堆乱码:
我们来利用load()来读取其中的数据:
a = np.load(fileName)aarray([[[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]], [[12, 13, 14, 15], [16, 17, 18, 19], [20, 21, 22, 23]]])我们可以看到,能够成功读取。
savez()
对于前面的save(),一次只能存储一个数组,那么在numpy中,提供了savez()函数,可以将多个数据保存到一个文件中,生成的文件拓展名是.npz。
savez(file,*args,**kwds)
file:文件的路径;*args:要保存到文件的数组;**kwds:关键字,每个数组都会保存到 output 文件及其相应的关键字名称。示例:
# 将三个数组放到文件中a = np.arange(20).reshape(2,10)b = np.arange(10).reshape(2,5)c = np.arange(40).reshape(5,8)#要保存到的文件路径fileName = './texts.npz'np.savez(fileName,a,b,c)我们可以打开文件查查看,确实生成了texts.npz文件,在打开之后,也是一堆乱码。
同样的,我们需要利用load()函数来读取。
需要注意,如果我们直接接受文件内容,打印出来是这样的:
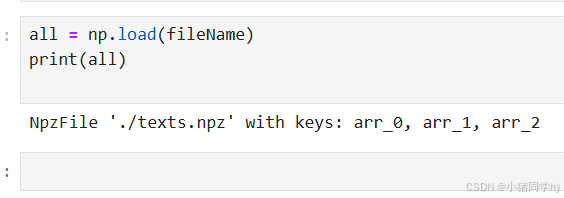
可以看到,直接打印我们得不到我们想要的数组,因为什么呢?
因为被压缩了,需要根据文件所给的key关键字名称当做索引来进行打印。
all = np.load(fileName)print(all)print(all['arr_0'])print(all['arr_1'])print(all['arr_2'])NpzFile './texts.npz' with keys: arr_0, arr_1, arr_2[[ 0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19]][[0 1 2 3 4] [5 6 7 8 9]][[ 0 1 2 3 4 5 6 7] [ 8 9 10 11 12 13 14 15] [16 17 18 19 20 21 22 23] [24 25 26 27 28 29 30 31] [32 33 34 35 36 37 38 39]]loadtxt()和savetxt()
这两个函数只能够读写一维或者二维数组的文本文件,同时我们也可以给定分隔符、跳过行数等。
numpy.savetxt(fname,array,fmt='%.18e',delimiter=None,newline='\n', header='', footer='', comments='# ', encoding=None)
fname:文件路径array:要写入文件的数组(可以是一维或者二维数组);fmt:写入文件的格式,如:%d、%f、%.18e。默认是%.18e。delimiter:分隔符;header:将在文件开头写入的字符串;footer:在文件末尾写入的字符串;comments:附加在header和footer之间的字符串,为注释。encoding:所使用的字符集编码。生成的文件可以是txt文件或者是CSV文件。
numpy.loadtxt(fname,dtype=type’float’>,comments=’#’,delimiter=None, converters=None,skiprows=0,usecols=None,unpack=False,ndmin=0,encoding=‘bytes’)
fname:所要读取的文件路径;dtype:读取后数据的类型;comments:跳过文件中指定参数开头的行(相当于注释)delimiter:读取文件时的分隔符converters:对读取的数据进行预处理;skiprows:跳过的行数;usecols:指定读取的列;encoding:对读取的文件进行预编码。示例:
现在我们来创建数组保存到文件中。
a = np.arange(12).reshape(3,4)fileName='./text.txt'# 默认fmt是%.18e(浮点数,即保留18位小数)np.savetxt(fileName,a)可以看到,如果我们没有设置格式,那么默认的格式就是%.18e,输出18位小数。
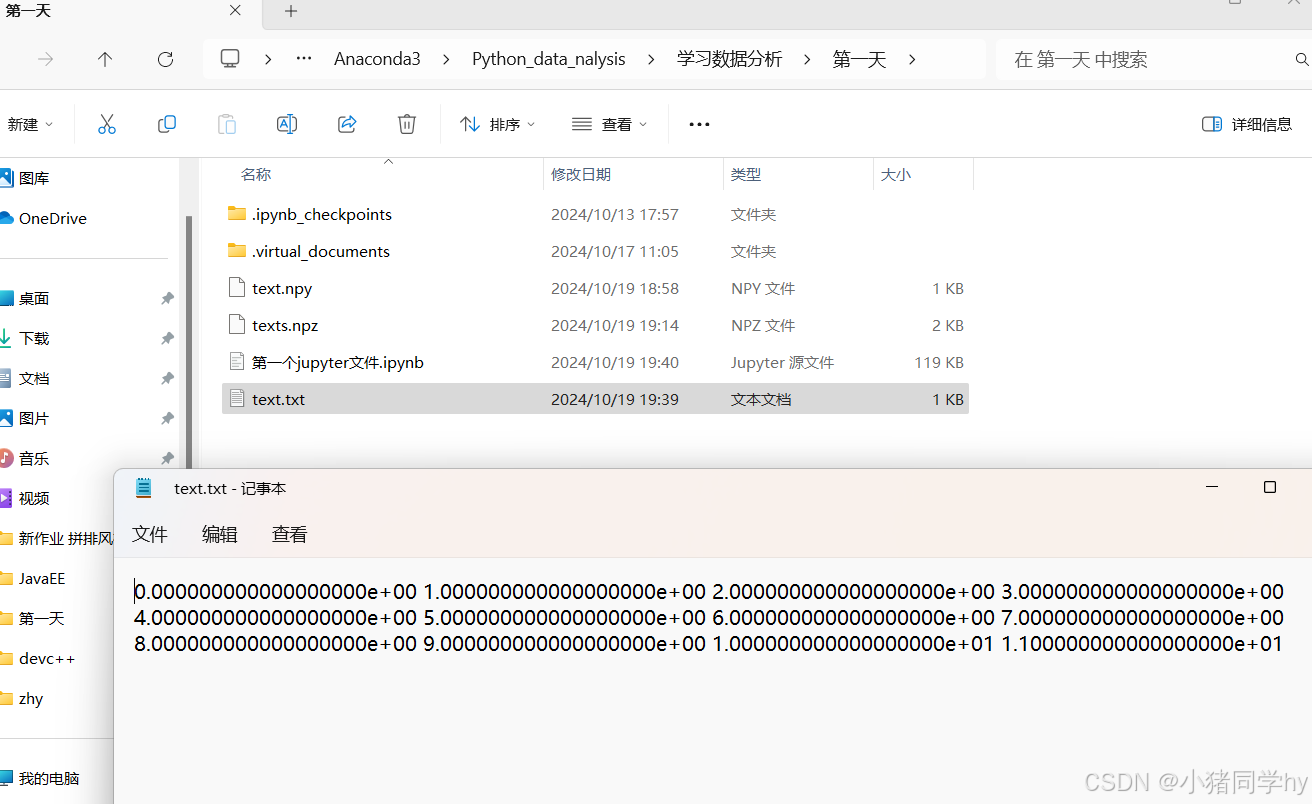
我们可以来设置一下:
a = np.arange(12).reshape(3,4)fileName='./text.txt'# 默认fmt是%.18e(浮点数,即保留18位小数)np.savetxt(fileName,a,fmt='%d') 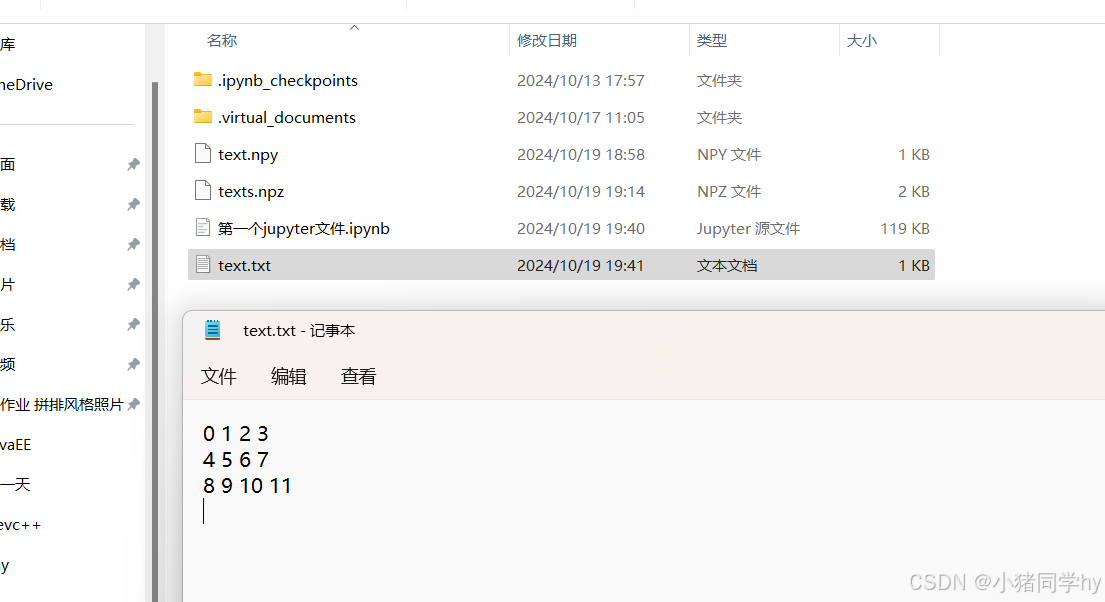
可以看到,我们指定输出格式为整数,那么在输出的时候就是整数。
我们来读取一下:
a = np.arange(12).reshape(3,4)fileName='./text.txt'# 默认fmt是%.18e(浮点数,即保留18位小数)np.savetxt(fileName,a,fmt='%d')#读取文件a = np.loadtxt(fileName,dtype=np.int32)print(a)结果:
[[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]]那么如果我们生成的是csv文件,那么会是什么样的?
a = np.arange(12).reshape(3,4)fileName='./text.csv'# 默认fmt是%.18e(浮点数,即保留18位小数)np.savetxt(fileName,a,fmt='%d')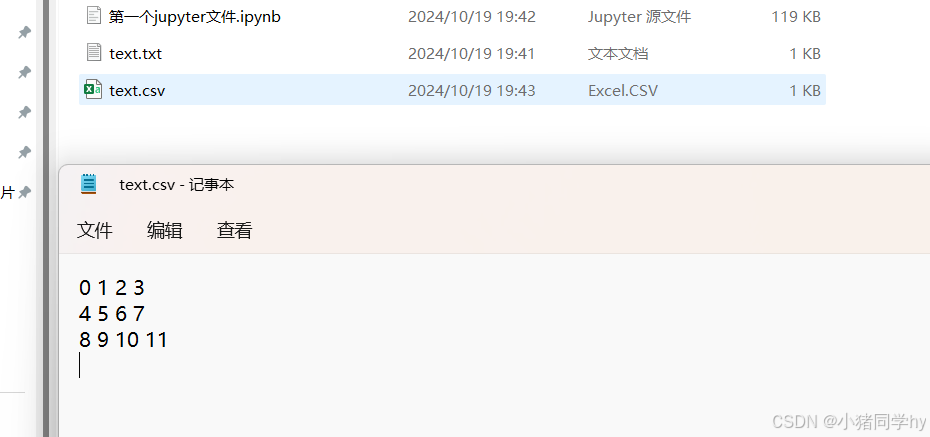
我们来读取一下:
a = np.arange(12).reshape(3,4)fileName='./text.csv'# 默认fmt是%.18e(浮点数,即保留18位小数)np.savetxt(fileName,a,fmt='%d')#读取文件a = np.loadtxt(fileName,dtype=np.int32)print(a)[[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]]那如果我们只想要第二三行,那么我们可以指定一下跳过几行(skiprows=1)
#读取文件a = np.loadtxt(fileName,dtype=np.int32,skiprows=1)print(a)[[ 4 5 6 7] [ 8 9 10 11]]在此基础上,我们只需要第2、4列,那么我们可以设置一下usecols=(1,3)
#读取文件a = np.loadtxt(fileName,dtype=np.int32,skiprows=1,usecols=(1,3))print(a)[[ 5 7] [ 9 11]]练习
现在有一个学生成绩单,根据需求,我们要读取出学生的成绩,并计算其总分。;
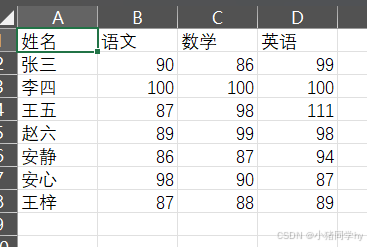
我们可以打开记事本查看,会发现中间有逗号隔开,所以我们在读取的时候,也需要设置一下分隔符:
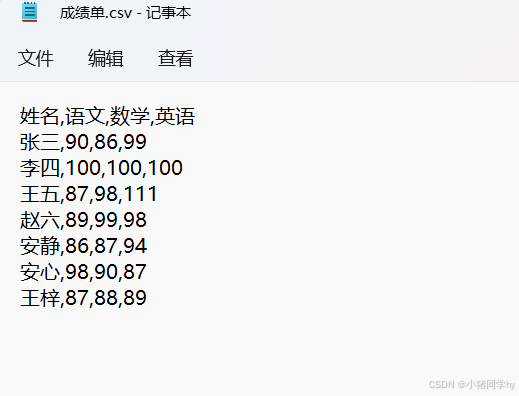
#首先我们需要创建一个结构化类型stu_type = np.dtype([('name',np.str_,2),('Chinese','i2'),('Math','i2'),('English','i2')])fileName='./成绩单.csv'#进行读取,跳过第一行student = np.loadtxt(fileName,skiprows=1,dtype=stu_type,delimiter=',')print(student)# 这里我们需要取出各科成绩Chinese = student['Chinese']Math = student['Math']English = student['English']print(Chinese)print(Math)print(English)# 计算总分sum = Chinese + Math + Englishprint('每个同学的总分为:',sum)averge =sum/3#设置格式np.set_printoptions(formatter={'float': '{: 0.3f}'.format})print('每个同学的平均分为:',averge)[('张三', 90, 86, 99) ('李四', 100, 100, 100) ('王五', 87, 98, 111) ('赵六', 89, 99, 98) ('安静', 86, 87, 94) ('安心', 98, 90, 87) ('王梓', 87, 88, 89)][ 90 100 87 89 86 98 87][ 86 100 98 99 87 90 88][ 99 100 111 98 94 87 89]每个同学的总分为: [275 300 296 286 267 275 264]每个同学的平均分为: [ 91.667 100.000 98.667 95.333 89.000 91.667 88.000]
以上就是本篇所有内容咯~
若有不足,欢迎指正~
后续慢慢改进~~~