最近涉及到了3D医学影像的分割,网络上相关的实现比较少,因此进行实现记录。
3DUnet实现3D医学影像的有效分割
1.配置代码环境2.配置数据集以及模型文件3.训练4.预测
1.配置代码环境
这里介绍一个很好的开源项目,git为: https://github.com/ellisdg/3DUnetCNN.git。
安装环境为:
nibabel>=4.0.1numpy>=1.23.0#torch>=1.12.0monai>=1.2.0scipy>=1.9.0pandas>=1.4.3nilearn>=0.9.1pillow>=9.3.0这里以Conda为例,很慢的话,可以-i 清湖镜像源:
conda create -n 3DUnet python=3.8conda activate 3DUnet git clone https://github.com/ellisdg/3DUnetCNN.gitcd 3DUnetCNNpip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple2.配置数据集以及模型文件
这里以 examples/brats2020/brats2020_config.json的json配置文件为例。
在同级文件夹下创建我们的任务的配置文件。随后,对json文件中比较重要的参数进行说明
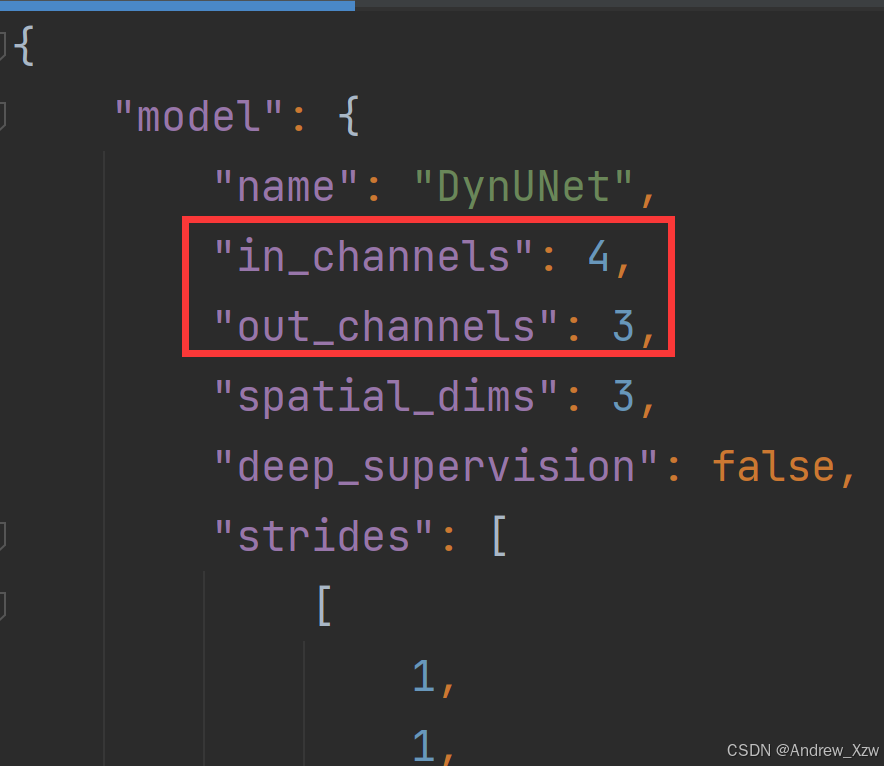
json文件中,in_channels表示模型的输入通道,out_channels表示模型的输出通道数。
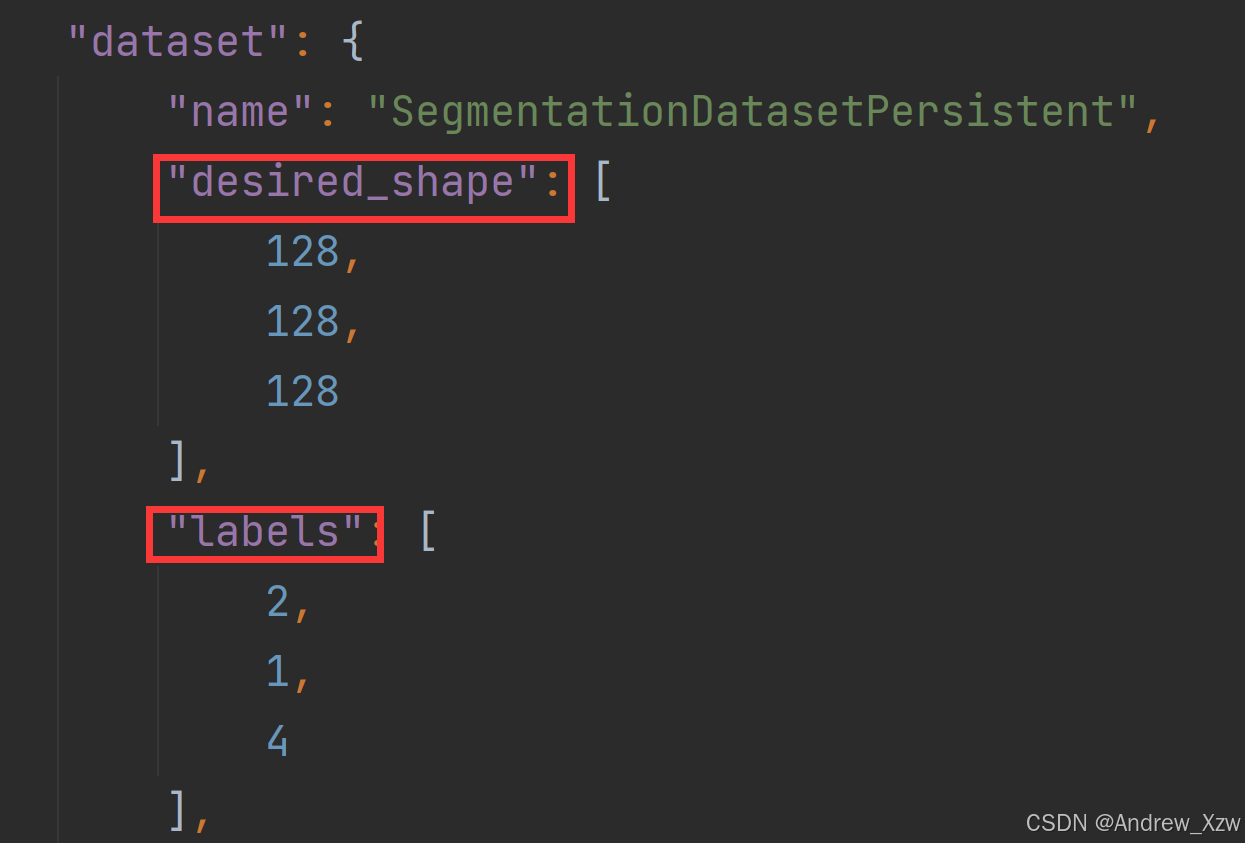
dataset字典中,desired_shape就是经过monai数据预处理库处理后的图片的WxHxC统一到128x128x128。labels就是数据集有几类,如果只有1类,那就只有0(背景)、1(前景之分)。该项目会将label转换成one hot编码。
接下来,比较重要的参数就是training_filenames,其中分为image和label,也就是图像以及其对应的标签。
bratsvalidation_filenames就是测试集,只存图片image。
由于这是参考的 examples/brats2020/brats2020_config.json的大脑分割json配置文件,这里的数据集路径要更换为我们的,这里这里附上更改我们自己的数据集的脚本代码。
import jsonimport os.path'''将自己的数据集进行划分并添加到json配置文件'''#原json文件路径filename = r'D:\jiedan\3DUnetCNN\examples\tooth_me\tooth_me_config.json'#自己数据集的图片路径my_data_dir = r'D:\jiedan\tooth_segmentation\image'#自己数据集的label路径my_data_label_dir = r'D:\jiedan\tooth_segmentation\label_32_pre'#进行数据集划分my_data_file = os.listdir(my_data_dir)train_num, val_num = int(len(my_data_file) * 0.8), int(len(my_data_file) - len(my_data_file) * 0.8)train_data_file = my_data_file[:train_num]val_data_file = my_data_file[train_num:]with open(filename, 'r') as opened_file: data = json.load(opened_file) #这里因为读取的所参考的examples/brats2020/brats2020_config.json #该数据集的图片数远远大于我们自己的数据集,所以只要截取到和我们的数据集一致的长度就行 train_file = data["training_filenames"][:train_num] val_file = data["bratsvalidation_filenames"][:val_num] for index, file in enumerate(train_file[:train_num]): file["image"] = os.path.join(my_data_dir, train_data_file[index]) file["label"] = os.path.join(my_data_label_dir, train_data_file[index].replace('.nii.gz', '.nii')) for index_v, j in enumerate(val_file[:val_num]): images_val = j['image'] j['image'] = os.path.join(my_data_dir, val_data_file[index_v])#进行数据集的路径字典更新data["training_filenames"] = train_filedata["bratsvalidation_filenames"] = val_filewith open(filename, 'w') as opened_file: json.dump(data, opened_file, indent=4) # 使用indent参数格式化保存的JSON数据,以便更易于阅读3.训练
下面是 训练的脚本。
python unet3d/scripts/train.py --config_filename./examples/tooth_me/tooth_me_config.json<config_filename>指向我们刚才处理好的我们自己的数据集以及模型的json文件。
4.预测
下面是 预测的脚本。
python unet3d/scripts/train.py --config_filename./examples/tooth_me/tooth_me_config.json<config_filename>指向我们刚才处理好的我们自己的数据集以及模型的json文件。
由于该git项目预测仅仅只是通过使用训练好的权重初始化的模型来输出预测图像,格式与输入图像一致,为nii.gz。
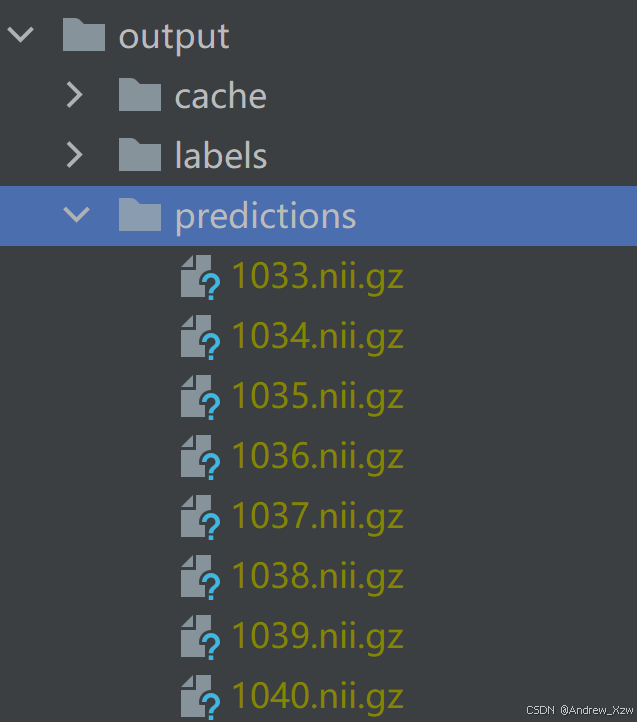
这个预测脚本 predict.py是没有衡量指标的计算的,比如Dice分数。
我们参考monai的官方文档的class monai.metrics.CumulativeIterationMetric类。
下面为官方文档使用说明:
dice_metric = DiceMetric(include_background=True, reduction="mean")for val_data in val_loader: val_outputs = model(val_data["img"]) val_outputs = [postprocessing_transform(i) for i in decollate_batch(val_outputs)] # compute metric for current iteration dice_metric(y_pred=val_outputs, y=val_data["seg"]) # callable to add metric to the buffer# aggregate the final mean dice resultmetric = dice_metric.aggregate().item()# reset the status for next computation rounddice_metric.reset()我们,首先定位到unet3d/scripts/predict.py,定位到 unet3d/predict/volumetric.py文件的volumetric_predictions函数。
def volumetric_predictions(model, dataloader, prediction_dir, activation=None, resample=False, interpolation="trilinear", inferer=None): output_filenames = list() writer = NibabelWriter() # 使用DiceMetric实例化metric对象 dice_metric = DiceMetric(include_background=True, reduction="mean") ...... with torch.no_grad(): for idx, item in enumerate(dataloader): x = item["image"] x = x.to(next(model.parameters()).device) # Set the input to the same device as the model parameters ..... predictions = model(x) batch_size = x.shape[0] for batch_idx in range(batch_size): _prediction = predictions[batch_idx] _x = x[batch_idx] if resample: _x = loader(os.path.abspath(_x.meta["filename_or_obj"])) #在这里加上读取label的代码并转移到对应的device上 _label = loader(os.path.abspath(_x.meta["filename_or_obj"]).replace('image', 'label_32_pre').replace('nii.gz', 'nii')) _label = _label.to(next(model.parameters()).device) # Set the input to the same device as the model parameters _prediction = resampler(_prediction, _x) #将模型预测的输出与加代码读取的label送进去 # compute metric for current iteration dice_metric(y_pred=_prediction, y=_label) # callable to add metric to the buffe writer.set_data_array(_prediction) writer.set_metadata(_x.meta, resample=False) out_filename = os.path.join(prediction_dir, os.path.basename(_x.meta["filename_or_obj"]).split(".")[0] + ".nii.gz") writer.write(out_filename, verbose=True) output_filenames.append(out_filename) #最后求平均得到最终的Dice分数 # aggregate the final mean dice result metric = dice_metric.aggregate().item() return output_filenames还有很多衡量的评价指标,可以参考monai的官方文档:
https://docs.monai.io/en/stable/metrics.html