1. 技术背景
1.1 风格化概念介绍
风格迁移通常指的是将一张图像的风格转移到另一张图像上,具体而言,对于一张风格图像和一张内容图像,风格迁移算法需要将内容图像转化为这个风格,并尽可能保留其内容。对应于视频风格迁移,则是将全部视频帧转换为对应风格图像的风格,此外,视频风格迁移需要解决风格变化导致的闪烁抖动、伪影等帧间不一致的挑战。
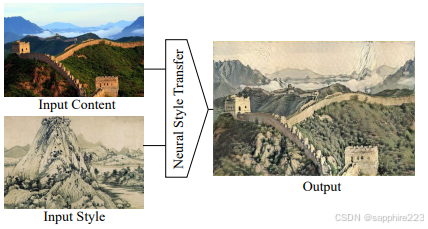
风格化/风格融合则是一个更宽泛的说法,因为现在通常也将文本描述作为风格输入,不再只是局限在图像之间风格迁移、转换的概念。视频风格化则是将一整段内容视频转化为具有指定风格的视频(使用风格图像或文本提示词指定)。
1.2 生成技术简介
风格迁移作为图像生成技术的一个分支,其发展离不开生成技术的发展。因此,有必要先介绍一下风格迁移与图像生成之间的关系,以及图像生成技术的基本技术原理。
1.2.1 图像生成VS风格化
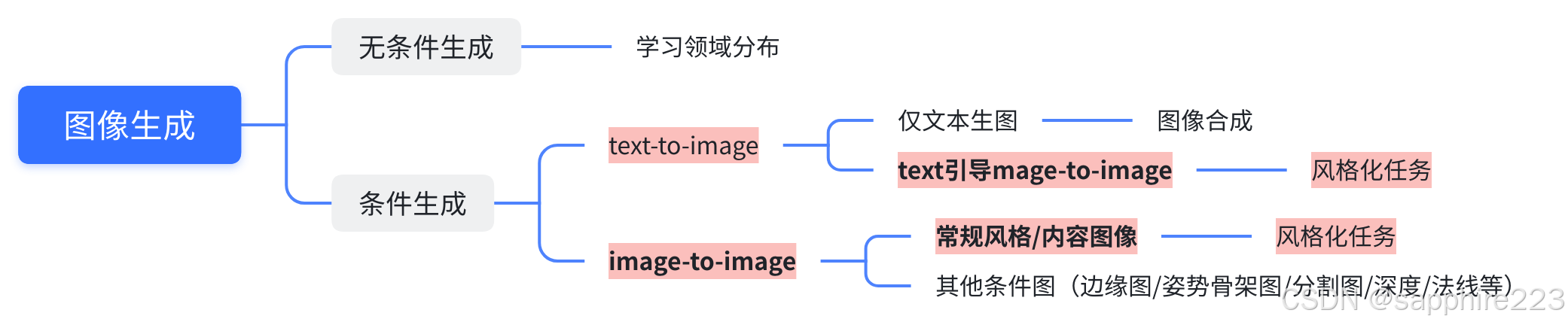
图像生成是指运用人工智能技术,根据给定的数据进行单模态或跨模态生成图像的过程。根据任务目标和输入条件的不同,图像生成主要包根据现有的图片生成新图像(image-to-image),以及根据文本描述生成符合语义的图像(text-to-image)等。
一般认为风格迁移属于image-to-image此类任务。随着多模态协同日渐紧密,可以广义将风格迁移概念扩展为生成有某种特定风格的图像的方法,也称为风格化。
1.2.2 技术原理介绍
此节简单介绍AE、GAN和DM三类生成算法,为下文具体风格迁移方法的基础骨干。
(1)自编码器(Auto-encoder, AE)
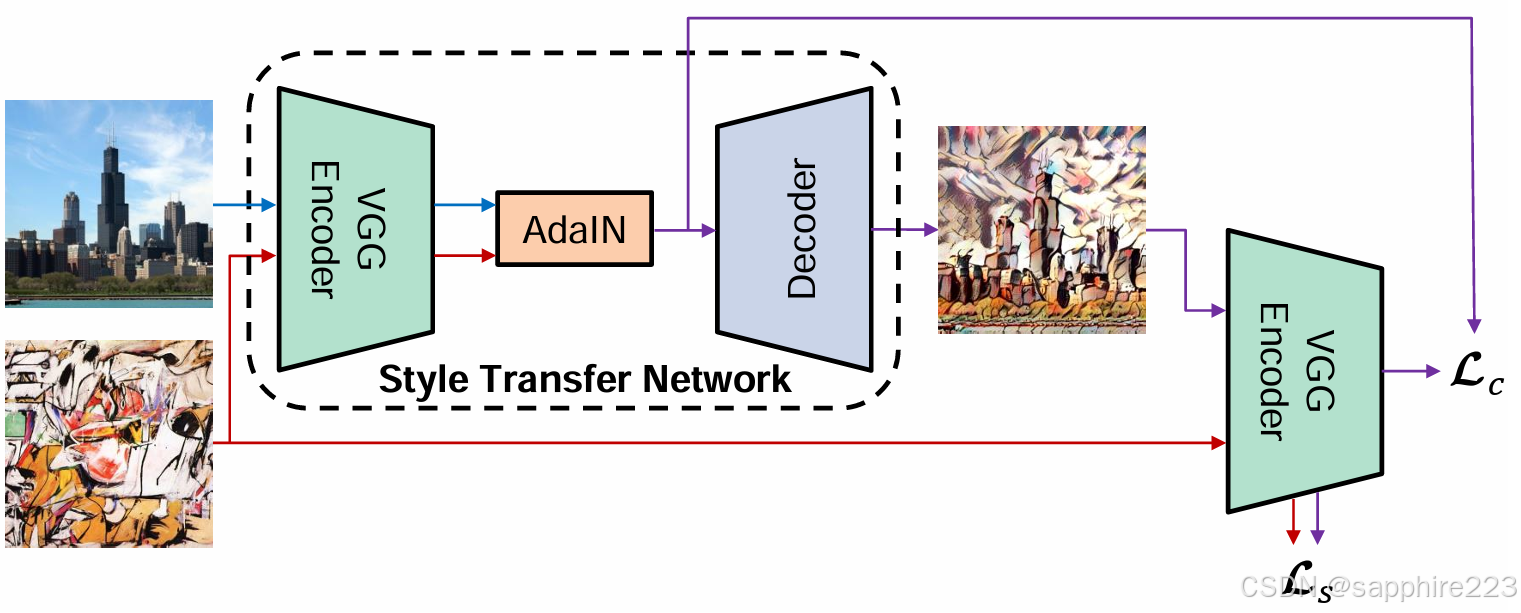
自编码器由编码器-解码器构成。此结构为神经风格迁移的常用的骨干结构,风格迁移技术会在bottleneck部分加入变换模块来进行风格转换。如下图为风格迁移方法Adain的具体框架:
|
|
|

(2)生成对抗网络(Generative Adversarial Networks,GAN)
2014年 Ian GoodFellow提出了生成对抗网络,成为早期最著名的生成模型。GAN使用零和博弈策略学习,在图像生成中应用广泛。以GAN为基础产生了多种变体,如DCGAN,StyleGAN,CycleGAN等。
GAN包含两个部分:
生成器:学习生成合理的数据。对于图像生成来说是给定一个向量,生成一张图片。其生成的数据作为判别器的负样本。 判别器:判别输入是生成数据还是真实数据。网络输出越接近于0,生成数据可能性越大;反之,真实数据可能性越大。生成器与判别器相互对立。在不断迭代训练中,双方能力不断加强,最终的理想结果是生成器生成的数据,判别器无法判别是真是假。
(3)扩散模型(Diffusion Model,里程碑式模型)
扩散是受到非平衡热力学的启发,定义一个扩散步骤的马尔科夫链,并逐渐向数据中添加噪声,然后学习逆扩散过程,从噪声中构建出所需的样本。扩散模型的最初设计是用于去除图像中的噪声。随着降噪系统的训练时间越来越长且越来越好,可以从纯噪声作为唯一输入,生成逼真的图片。
一个标准的扩散模型分为两个过程:前向过程与反向过程。在前向扩散阶段,图像被逐渐引入的噪声污染,直到图像成为完全随机噪声。在反向过程中,利用一系列马尔可夫链在每个时间步逐步去除预测噪声,从而从高斯噪声中恢复数据。
前向扩散过程,向原图中逐步加入噪声,直到图像成为完全随机噪声。
反向降噪过程,在每个时间步逐步去除噪声,从而从高斯噪声中恢复源数据。
扩散模型的工作原理是通过添加噪声来破坏训练数据,然后通过逆转这个噪声过程来学习恢复数据。换句话说,扩散模型可以从噪声中生成连贯的图像。
扩散模型通过向图像添加噪声进行训练,然后模型学习如何去除噪声。然后,该模型将此去噪过程应用于随机种子以生成逼真的图像。
| 整体来说,在生成模型的发展历程中,著名的是生成对抗网络(Generative Adversarial Network,GAN),但是难以训练,模型训练过程通常会崩溃,做了多年的结果也不尽如人意。另外AE类的方案,实际生成质量不是很高。最近流行的扩散模型(Diffusion Model),能够实现稳定的训练,而且能够产生高质量和多样性的图像,这是现在主流的研究方向。 |
2. 视频风格化关键挑战
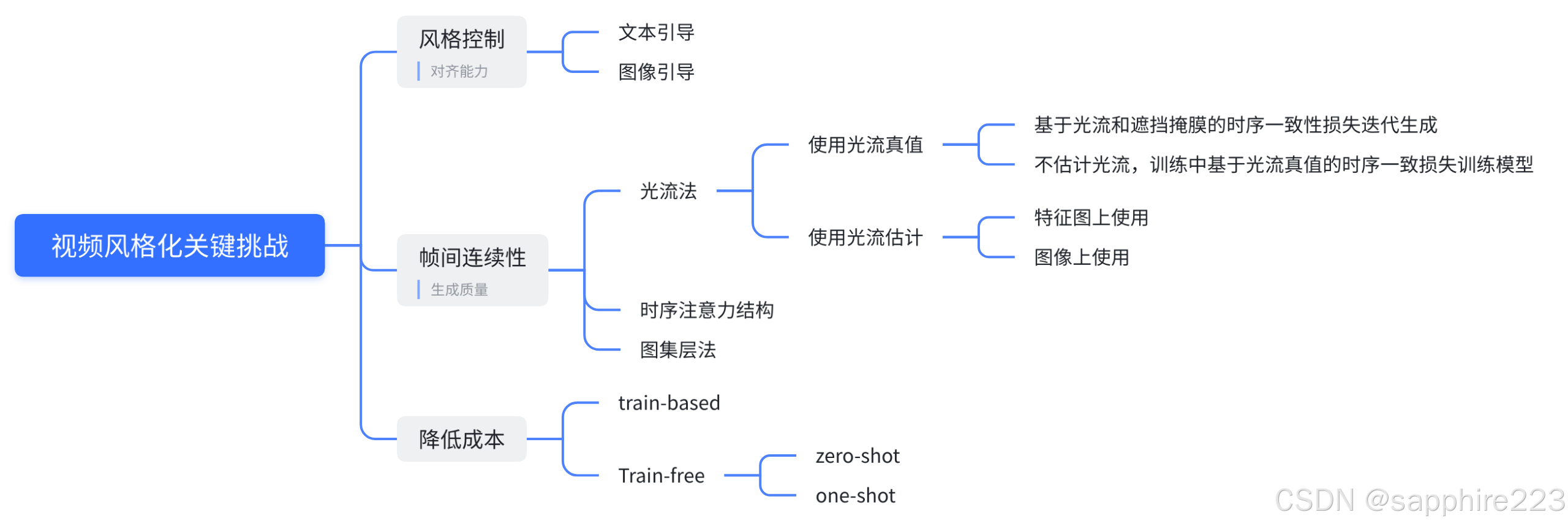
2.1 如何控制风格
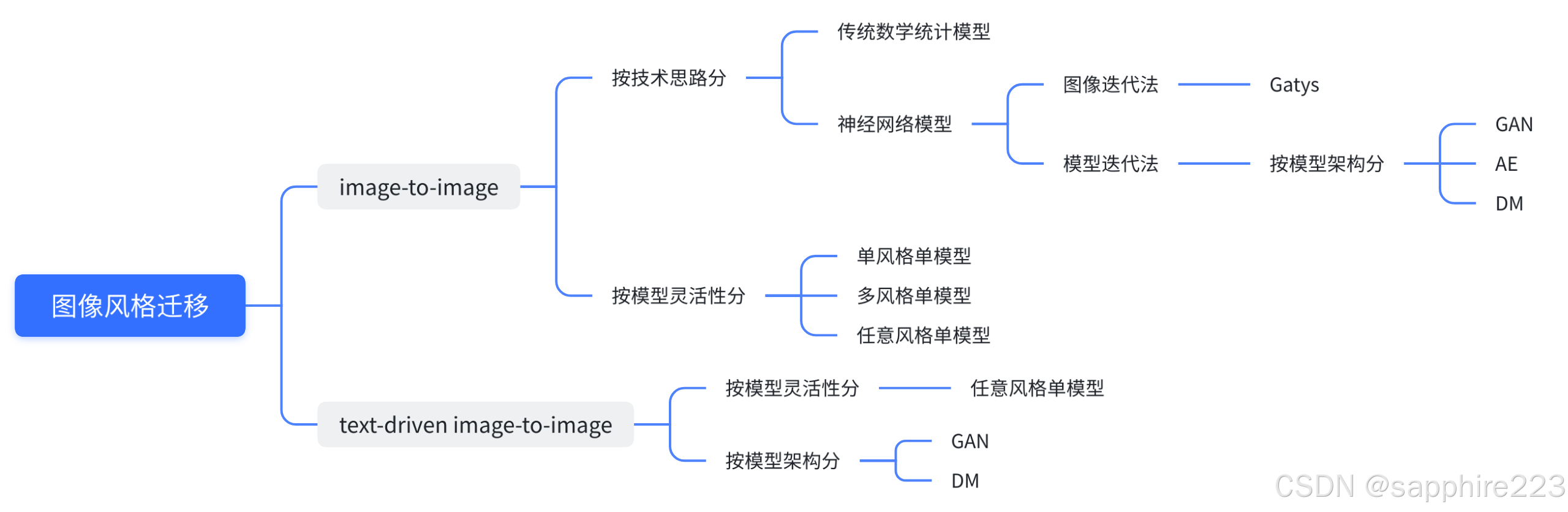
风格其实是一个难以定义的问题。到底怎么把一个说都说不清的东西变成一个可执行的程序,是研究者面临的关键问题。
Image to image风格迁移阶段在神经网络之前,图像风格迁移共同的思路是:分析某一种风格的图像,给那一种风格建立一个数学或者统计模型,再改变要做迁移的图像让它能更好的符合建立的模型。这样做出来在特定场景中效果还是不错的,但是一个算法基本只能做某一种风格或者某一个场景,因此基于传统风格迁移研究的实际应用非常有限。
改变这个现状的是Gatys等人,从此风格迁移进入了神经风格迁移时期,生成效果已经可以达到模拟梵高画作。Gatys主要利用神经网络提取高层特征,并构建风格损失和内容损失以分别约束风格和内容的生成。
|
|
|

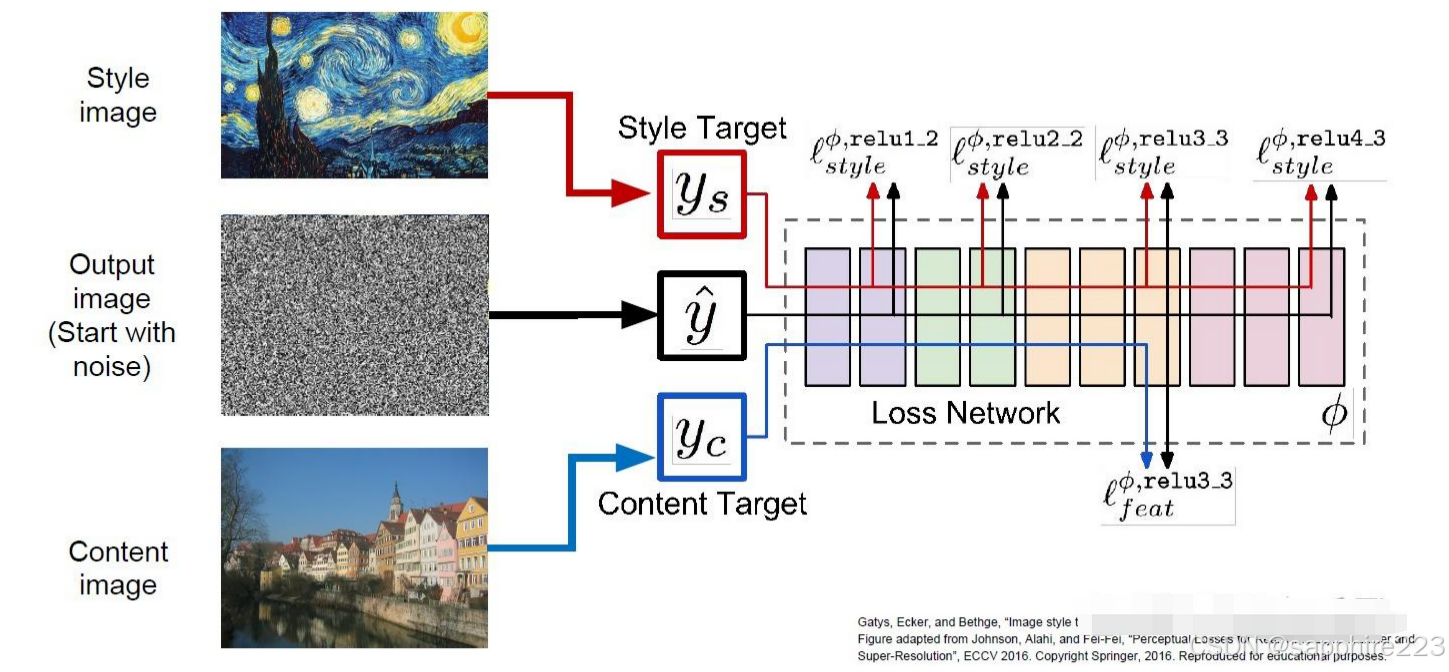
然而由于Gatys的方法是迭代生成图像,推理速度非常慢(5-20min/img)。后续研究人员提出基于模型迭代的方法,通过使用大量图像训练可生成风格化图像的模型,能够很大程度上解决图像迭代方法计算效率低下的问题。
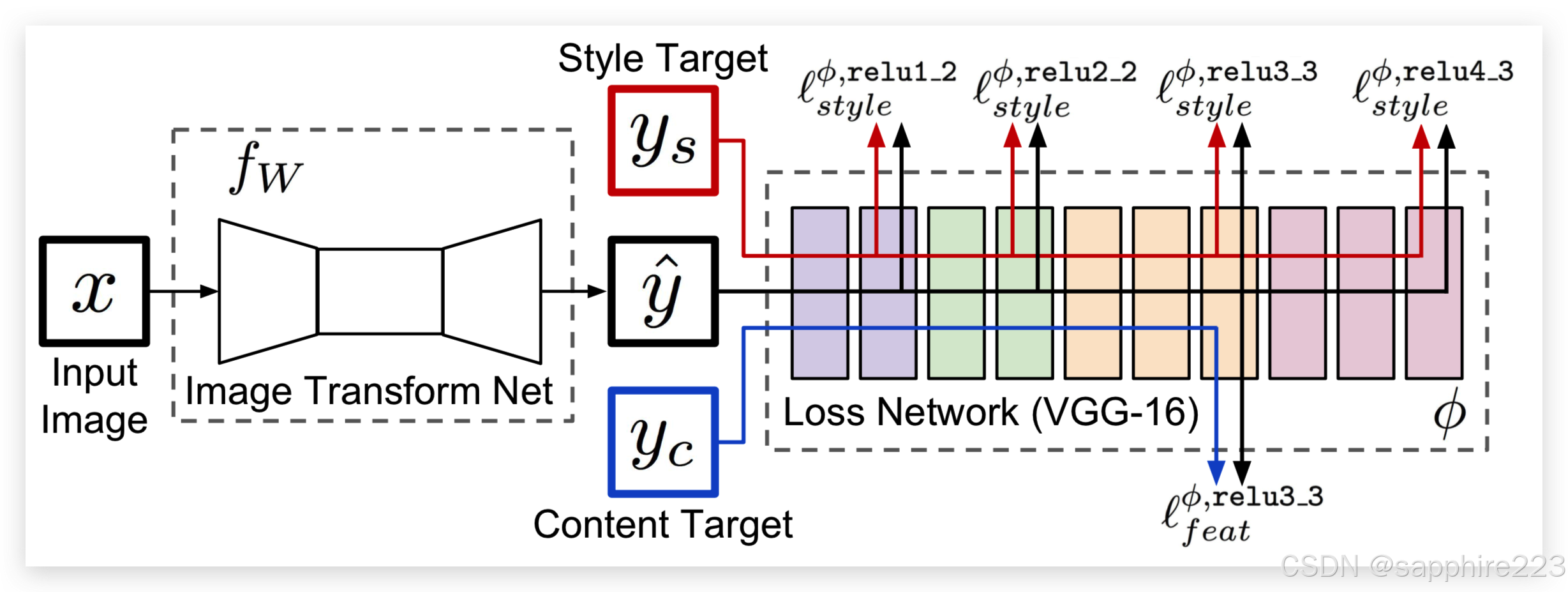
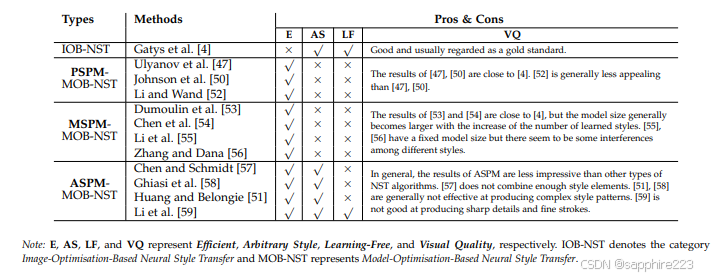
后续涌现了大量基于模型优化的方法,使用图像生成技术的AE模型框架,即编码器-特征转换-解码器的框架。研究者们主要在增大模型的灵活性和不同的风格化效果进行了探索。模型按灵活性的不同可以分为单风格单模型方法,多风格单模型方法以及任意风格迁移算法。此外,不同方案在控制风格效果上有着不同的特点:
具体而言,Huang等提出了一种自适应实例归一化(AdaIN)操作,利用风格特征的均值和方差代替内容特征的均值和方差。但由于风格依赖训练,它通常会给所有风格化图像带来相似的纹理模式 (例如所有风格化结果中的裂纹模式)。Li等利用奇异值分解对图像进行白化,然后重新上色,但这不可避免地带来了不可见的信息和不受约束的模式。之后,注意机制的提出激发了更多的工作。Park等利用内容特征内部的空间相关性来重新排列样式特征。Liu等结合了Huang和Park的核心思想,得到了更加和谐的全局和局部风格化结果。为了捕获更多的远程依赖关系,随后的研究Wu和Deng等人分别使用了transformer编码器而不是cnn,从而产生了更视觉上可信的结果。
总体而言,基于编码器-特征转换-解码器框架已经取得了较好的风格迁移效果,但是人们对于模型生成效果的追求还远远没有停止;此外,更精准地拆解和控制细粒度风格,是另一个人们持续关注并研究的问题。
|
|
|

最近,扩散模型(Diffusion Models, DMs)出现并迅速引起人们的兴趣。随着大规模图像-文本数据集的出现,dm显示出强大的视觉生成能力,自然,DMs的成功吸引了更多的研究人员研究如何利用DMs来改善AST结果。
相应的工作可以分为两类:1)training-free的方法和2)training-based的方法。前者通过设计特定的目标来引导反向扩散过程,而不需要模型微调,实现效率高,但主要依赖于所使用的dm的能力。相比之下,基于训练的方法具有更大的潜力。
Ruta(diff-nst)等人提出将风格引导整合到训练好的LDM Unet模块的自注意块中,只对注意块进行微调。 Chen(artfusion)提出将内容和风格图像作为条件注入到LDM模型中,整个模型从头开始训练。它可以通过调整无分类器引导的权值来控制结果的风格化强度。|
|
|
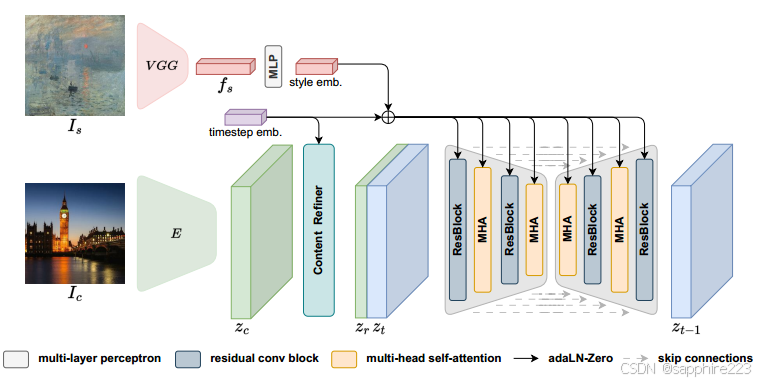

Hicast从Controlnet中获取灵感,尝试将外部更多条件信息插入(使用不同的技术提取必要的控制图,如边缘提取、语义分割和深度估计),获得更多定制化的风格。它的特点是引入了风格适配器,将控制图集成到骨干U-Net中,可以通过在LDM中对齐多级风格信息和内部知识来灵活地操作输出结果。