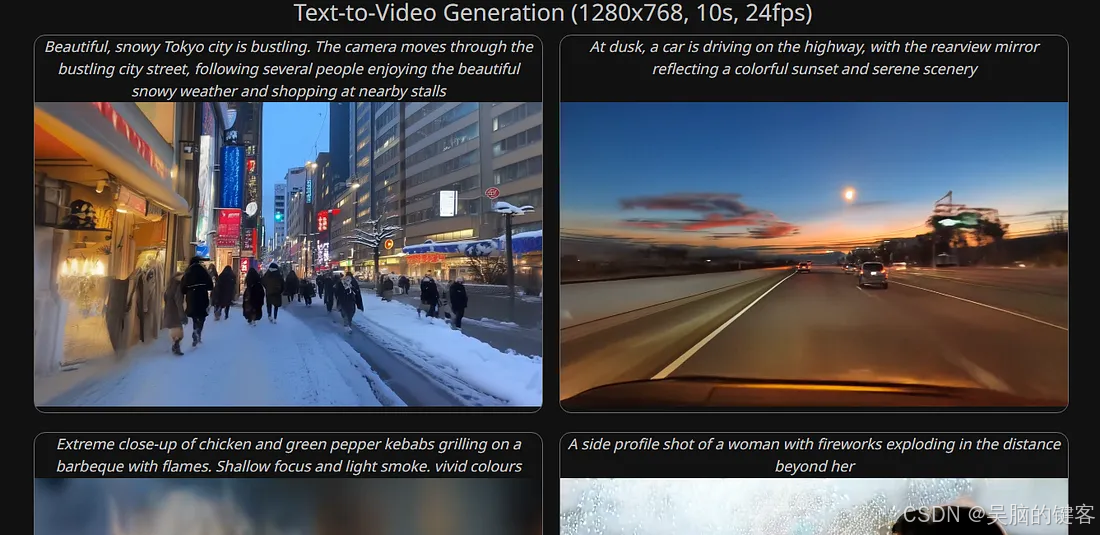
在 "生成式人工智能 "中的文本生成模型和图像生成模型大行其道之后,现在该是文本-视频模型大显身手的时候了,这个列表中的新模型就是 pyramid-flow-sd3,它是一个开源模型,用于从文本或图像生成长达 10 秒的视频,而且是 24fps 的视频!
该模型非常重要的点,
可以免费使用,并且开源,因此本地用户也可以使用代码使用该模型
生成较长的人工智能视频(最长 10 秒),是其他模型(5 秒)的两倍。
它既能生成文本视频,也能生成图像视频。
它是在开源数据集上训练的。
该模型可在 HuggingFace 上下载,并可使用 python
了解金字塔流
随着 pyramid-flow-sd3 的发布,该模型所基于的团队也引入了一个新概念,即金字塔流(Pyramid Flow)。 从官方 Github 代码库中摘录如下
Pyramid Flow, a training-efficient Autoregressive Video Generation method based on Flow Matching.
让我们来解释一下这些行话
自回归视频生成技术
自回归视频生成技术是一种按顺序生成视频每一帧画面的技术,每一帧新画面都会根据之前生成的画面进行预测。
这种方法可确保视频中的时间关系得以保留,从而使最终输出更加逼真。 该模型可学习理解运动和变化是如何随时间发生的,这对于创建流畅、可信的视频序列至关重要。
流匹配
流匹配是一种用于将生成数据的分布与真实数据的分布相一致的方法。 它涉及对数据点(在本例中为视频帧)如何随时间从一种状态过渡到另一种状态进行建模。
通俗地说 : 流匹配是一种帮助计算机学习如何使生成的视频看起来真实的技术。 它的重点是理解视频的一帧应该如何变化到下一帧。 通过了解这些变化,该模型可以制作出看起来自然可信的视频,就像现实生活中的运动一样。
Pyramid Flow(金字塔流)
Pyramid Flow(金字塔流)指的是视频生成中的一种分层方法,可在多个分辨率下运行,类似于金字塔结构。
这种方法允许模型从较低分辨率的表征开始,逐步细化为较高分辨率的表征。 通过这种方式处理数据,Pyramid Flow 提高了计算效率,并保持了帧间的连续性,这对于生成逼真的视频至关重要。
Pyramid Flow 与流量匹配有什么关系?
Pyramid Flow 使用流量匹配来改进视频生成。
当模型创建视频时,它会使用 "流匹配 "来确保金字塔的每一步(或层)都能顺利过渡到下一步。 这意味着,从模糊版本到清晰版本,它都能保持一切看起来真实流畅。
Pyramid Flow is like building a video step by step, while Flow Matching makes sure that every step looks good and flows well into the next one.
rain1011/pyramid-flow-sd3
这是 Pyramid Flow 的官方资源库,Pyramid Flow 是一种基于流匹配(Flow Matching)的训练效率高的自回归视频生成方法。 通过仅在开源数据集上进行训练,它能以 768p 分辨率和 24 FPS 的速度生成高质量的 10 秒视频,并自然支持图像到视频的生成。
安装
我们建议使用 conda 设置环境。 代码库目前使用 Python 3.8.10 和 PyTorch 2.1.2,我们正在积极努力支持更广泛的版本。
git clone https://github.com/jy0205/Pyramid-Flowcd Pyramid-Flow# create env using condaconda create -n pyramid python==3.8.10conda activate pyramidpip install -r requirements.txt然后,您可以直接从 Huggingface 下载模型。 我们提供 768p 和 384p 两种视频生成的模型检查点。 384p 检查点支持以 24FPS 的速度生成 5 秒钟的视频,而 768p 检查点支持以 24FPS 的速度生成长达 10 秒钟的视频。
from huggingface_hub import snapshot_downloadmodel_path = 'PATH' # The local directory to save downloaded checkpointsnapshot_download("rain1011/pyramid-flow-sd3", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')使用
要使用我们的模型,请按照此链接中的 video_generation_demo.ipynb 中的推理代码进行操作。 我们将其进一步简化为以下两个步骤。 首先,加载下载的模型:
import torchfrom PIL import Imagefrom pyramid_dit import PyramidDiTForVideoGenerationfrom diffusers.utils import load_image, export_to_videotorch.cuda.set_device(0)model_dtype, torch_dtype = 'bf16', torch.bfloat16 # Use bf16 (not support fp16 yet)model = PyramidDiTForVideoGeneration( 'PATH', # The downloaded checkpoint dir model_dtype, model_variant='diffusion_transformer_768p', # 'diffusion_transformer_384p')model.vae.to("cuda")model.dit.to("cuda")model.text_encoder.to("cuda")model.vae.enable_tiling()然后,您可以尝试根据自己的提示将文字转换成视频:
prompt = "A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors"with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch_dtype): frames = model.generate( prompt=prompt, num_inference_steps=[20, 20, 20], video_num_inference_steps=[10, 10, 10], height=768, width=1280, temp=16, # temp=16: 5s, temp=31: 10s guidance_scale=9.0, # The guidance for the first frame, set it to 7 for 384p variant video_guidance_scale=5.0, # The guidance for the other video latent output_type="pil", save_memory=True, # If you have enough GPU memory, set it to `False` to improve vae decoding speed )export_to_video(frames, "./text_to_video_sample.mp4", fps=24)作为一个自回归模型,我们的模型还支持(以文本为条件的)图像到视频的生成:
image = Image.open('assets/the_great_wall.jpg').convert("RGB").resize((1280, 768))prompt = "FPV flying over the Great Wall"with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch_dtype): frames = model.generate_i2v( prompt=prompt, input_image=image, num_inference_steps=[10, 10, 10], temp=16, video_guidance_scale=4.0, output_type="pil", save_memory=True, # If you have enough GPU memory, set it to `False` to improve vae decoding speed )export_to_video(frames, "./image_to_video_sample.mp4", fps=24)通过添加 cpu_offloading=True 参数,我们还支持 CPU 卸载,以便在 GPU 内存不足 12GB 的情况下进行推理。 该功能由 @Ednaordinary 提供,详情请参见 #23。
使用技巧
guidance_scale 参数控制视觉质量。 我们建议在文本到视频生成过程中,对 768p 检查点使用 [7, 9] 以内的指导,对 384p 检查点使用 7 以内的指导。视频引导尺度(video_guidance_scale)参数用于控制运动。 数值越大,动态程度越高,自回归生成的劣化程度也就越低,而数值越小,视频就越稳定。对于 10 秒钟的视频生成,我们建议使用 7 级指导等级和 5 级视频指导等级。最后
自今年上半年图生视频的svd开源以后,越来越多的研究者都在尝试复现Sora模型,其中企业闭源的模型有不少,如MiniMax和Luma Dream Machine等,但终于开源社区也迎来了属于自己的文生图模型——CogVideoX。我觉得 Pyramid Flow 的出现也让我们更相信研究的方向是正确的,同时需要更多的实验和实践。吾生也有涯,而学也无涯,以有涯随无涯。