〔探索AI的无限可能,微信关注“AIGCmagic”公众号,让AIGC科技点亮生活〕
本文作者:AIGCmagic社区 刘一手
前言
AI多模态大模型发展至今,每年都有非常优秀的工作产出,按照当前模型设计思路,多模态大模型的架构主要包括以下几个部分:
模态编码器(Modality Encoder, ME):负责将不同模态的输入编码成特征。常见的编码器包括图像的NFNet-F6、ViT、CLIP ViT等,音频的Whisper、CLAP等,视频编码器等。
输入投影器(Input Projector):负责将其他模态的特征投影到文本特征空间,并与文本特征一起输入给语言模型。常用的投影器包括线性投影器、MLP、交叉注意力等。
语言模型骨架(LLM Backbone):利用预训练的语言模型,负责处理各种模态的特征,进行语义理解、推理和决策。常用的语言模型包括Flan-T5、ChatGLM、UL2等。
输出投影器(Output Projector):负责将语言模型输出的信号转换成其他模态的特征,以供后续模态生成器使用。常用的投影器包括Tiny Transformer、MLP等。
模态生成器(Modality Generator, MG):负责生成其他模态的输出。常用的生成器包括图像的Stable Diffusion、视频的Zeroscope、音频的AudioLDM等。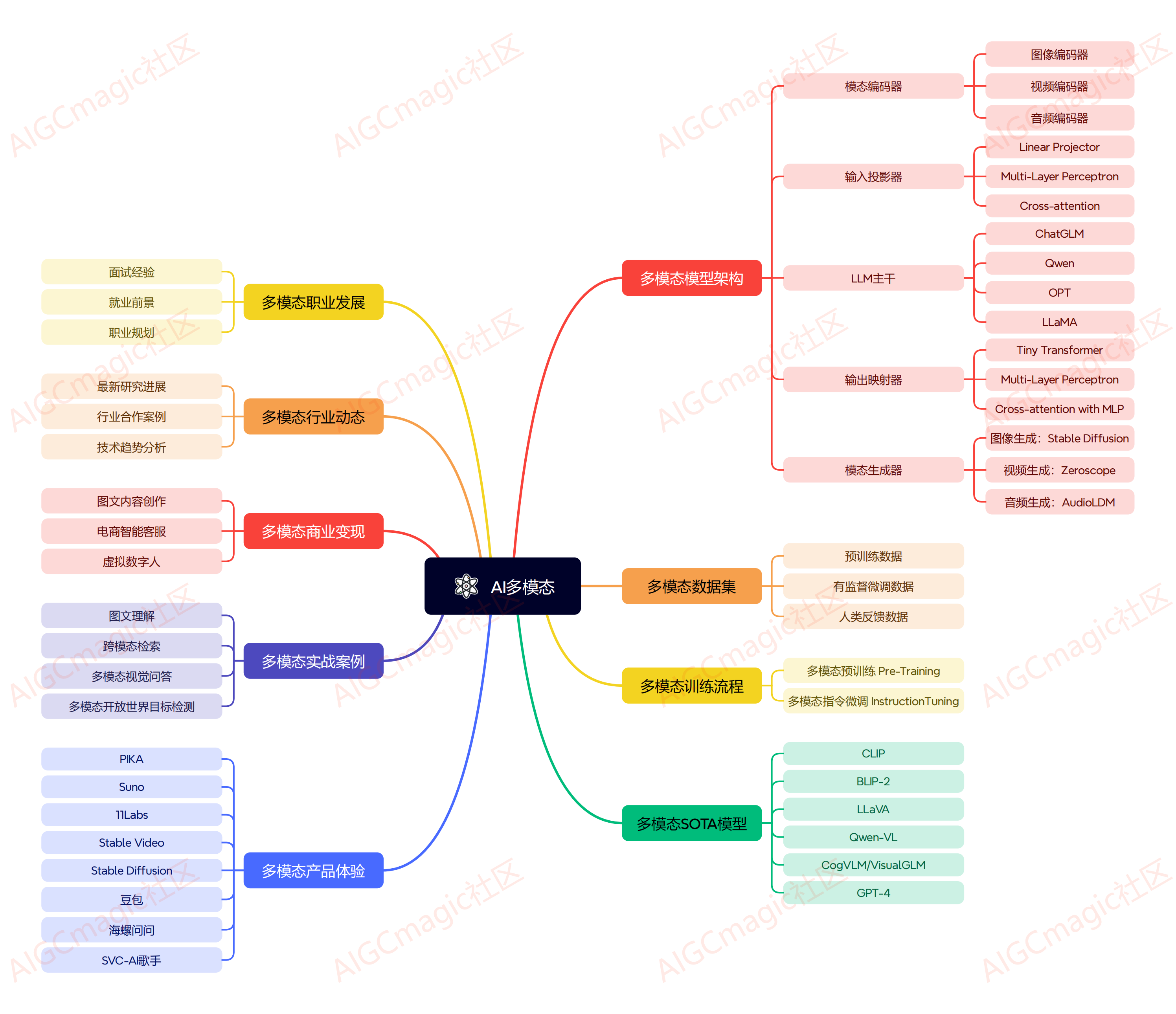
本文一手会详细解读AI多模态架构中的输入投影器(Input Projector),并从线性投影器(Linear Projector)、多层感知器(Multi-Layer Perception, MLP)和交叉注意力(Cross-Attention)三个角度,总结当前主流的工作方案!
多模态大模型需要处理不同类型的输入数据,如图像、文本、音频等。为了将这些不同的数据转换到一个共同的表示空间,引入了输入投影器。
一、Linear Projector(线性投影器, LP)
线性投影器是一种简单的投影方法,通过线性变换将输入数据映射到目标表示空间。
特点
简单高效:计算速度快,易于实现。
参数少:所需参数较少,适合参数敏感的场景。
优缺点
优点:高效,适合大规模数据处理。
缺点:表达能力有限,无法捕捉复杂的非线性关系。
代码/伪代码表示
线性投影器通常使用一个简单的线性层来实现。假设我们有图像和文本作为输入,需要将它们投影到一个共同的表示空间。
import torchimport torch.nn as nnclass LinearProjector(nn.Module): def __init__(self, input_dim, output_dim): super(LinearProjector, self).__init__() self.linear = nn.Linear(input_dim, output_dim) def forward(self, x): return self.linear(x)# 示例输入image_features = torch.randn(32, 2048) # 32个样本,每个样本2048维text_features = torch.randn(32, 300) # 32个样本,每个样本300维# 投影到相同的表示空间projector = LinearProjector(2048, 512)projected_image_features = projector(image_features)projector = LinearProjector(300, 512)projected_text_features = projector(text_features)二、Multi-Layer Perception(多层感知器, MLP)
多层感知器是一种神经网络,由多层线性变换和非线性激活函数组成,能够捕捉输入数据的复杂非线性关系。
特点
非线性:能够表示和捕捉复杂的非线性关系。
层次结构:通过多层结构逐步提取特征,表示数据更好。
优缺点
优点:强大的表示能力,能够捕捉复杂的特征和模式。
缺点:计算复杂度高,训练时间长,容易过拟合。
代码/伪代码表示
多层感知器通过多个线性层和非线性激活函数来实现。
import torchimport torch.nn as nnclass MLPProjector(nn.Module): def __init__(self, input_dim, hidden_dim, output_dim): super(MLPProjector, self).__init__() self.fc1 = nn.Linear(input_dim, hidden_dim) self.relu = nn.ReLU() self.fc2 = nn.Linear(hidden_dim, output_dim) def forward(self, x): x = self.fc1(x) x = self.relu(x) x = self.fc2(x) return x# 示例输入image_features = torch.randn(32, 2048)text_features = torch.randn(32, 300)# 投影到相同的表示空间mlp_projector = MLPProjector(2048, 1024, 512)projected_image_features = mlp_projector(image_features)mlp_projector = MLPProjector(300, 512, 512)projected_text_features = mlp_projector(text_features)三、Cross-Attention(交叉注意力)
交叉注意力机制在多模态模型中非常重要,通过计算不同模态间的注意力权重,实现信息的交互和融合。
特点
信息融合:在不同模态间有效地交换和融合信息。
权重自适应:根据输入动态计算注意力权重,更加灵活和智能。
优缺点
优点:在不同模态之间高效地捕捉相关性,适应不同类型的输入。
缺点:计算复杂度较高,尤其在处理长序列输入时。
代码/伪代码表示
交叉注意力通常用于Transformer架构中,以在不同模态间交换信息。
import torchimport torch.nn as nnclass CrossAttention(nn.Module): def __init__(self, dim, num_heads): super(CrossAttention, self).__init__() self.multihead_attn = nn.MultiheadAttention(embed_dim=dim, num_heads=num_heads) def forward(self, query, key, value): attn_output, _ = self.multihead_attn(query, key, value) return attn_output# 示例输入# 10个图像特征序列,每个特征序列32个时间步,每个时间步512维image_features = torch.randn(10, 32, 512) # 20个文本特征序列,每个特征序列32个时间步,每个时间步512维text_features = torch.randn(20, 32, 512) # 使用交叉注意力cross_attention = CrossAttention(dim=512, num_heads=8)# 让图像特征作为query,文本特征作为key和valueprojected_features = cross_attention(image_features, text_features, text_features)总结
线性投影器简单高效,适用于计算资源有限的场景;多层感知器具有强大的表示能力,适用于需要捕捉复杂关系的任务;交叉注意力在多模态信息融合中表现出色,尤其适用于需要跨模态交互的任务。写在后面
如果大家对多模态大模型感兴趣,可以扫码加群学习交流,二维码失效可以添加我的微信:lzz9527288?
推荐阅读: