【卷积神经网络】卷积层详解【数学+python代码】
1、简介
学习目标:
掌握卷积计算过程掌握特征图大小计算方法掌握PyTorch卷积层API基本概念:
①在计算机视觉领域,往往我们输入的图像都很大,使用全连接网络的话,计算的代价较高。
另外图像也很 难保留原有的特征 ,导致图像处理的准确率不高。
②卷积神经网络(Convolutional Neural Network)是含有 卷积层 的神经网络;
卷积层的作用就是用来自动学习、提取图像的特征。
③CNN网络主要有三部分构成:卷积层、池化层和全连接层构成;
卷积层负责提取图像中的局部特征;
池化层用来大幅降低参数量级(降维);
全连接层类似人工神经网络的部分,用来输出想要的结果。
关于卷积层的python的API,提取表格如下:
| API | 参数 | 说明 |
|---|---|---|
| nn.Conv2d | in_channels | 输入通道数,如 RGB 图像有 3 个通道,RGBA 图像有 4 个通道。 |
| out_channels | 输出通道数,即卷积核的数量,决定输出特征图的深度。 | |
| kernel_size | 卷积核的大小,可以是单个整数(如 3 表示 3x3)或元组(如 (3, 3))。 | |
| stride | 卷积操作的步幅,默认值为 1。 | |
| padding | 填充方式,默认值为 0,表示不填充。 | |
| torch.tensor | data | 输入数据,通常是一个数组或图像数据。 |
| permute | dims | 重新排列张量的维度顺序,如 permute(2, 0, 1) 将 (H, W, C) 变为 (C, H, W)。 |
| unsqueeze | dim | 在指定位置插入一个维度,如 unsqueeze(0) 在第 0 维度插入一个新维度。 |
| squeeze | dim | 删除指定位置的单维度,如 squeeze(0) 删除第 0 维度。 |
| detach | 分离张量,使其不再跟踪梯度。 | |
| numpy | 将 PyTorch 张量转换为 NumPy 数组。 |
接下来,学习卷积核的计算过程,即:卷积核是如何提取特征的
2、卷积计算
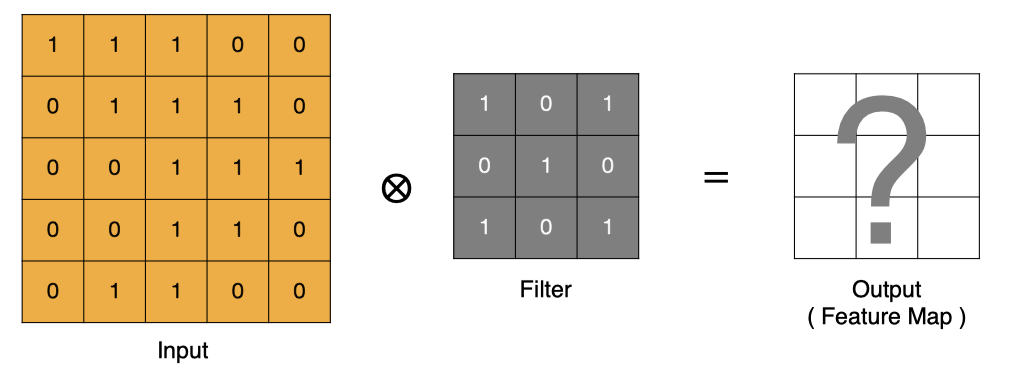
卷积核,也叫做 滤波器input 经过 filter 的得到输出为最右侧的图像,该图叫做 特征图 那么, 它是如何进行计算的呢?卷积运算本质上就是在滤波器和输入数据的局部区域间做点积。
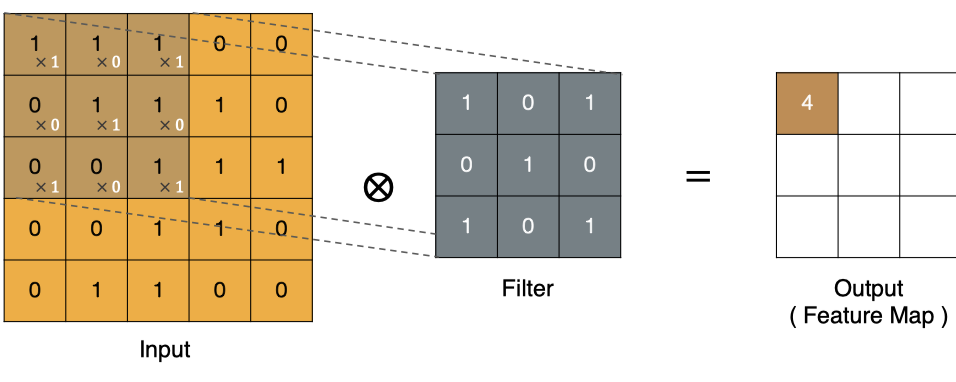
左上角的点计算方法:
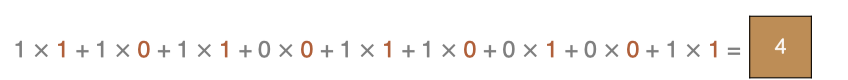
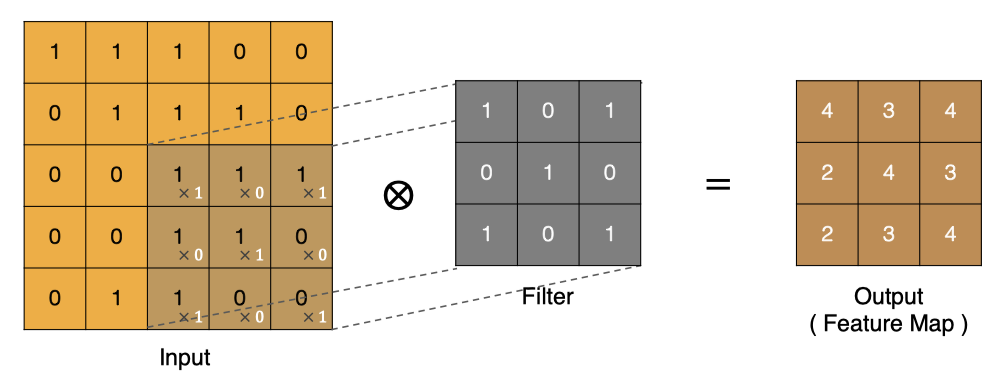
按照上面的计算方法可以得到最终的特征图为:
3、Padding
通过上面的卷积计算过程,我们发现最终的特征图比原始图像小很多,如果想要保持经过卷积后的图像大小不变, 可以在原图周围添加 padding(填充) 来实现。
这里通过添加一圈“0”来保证大小一致
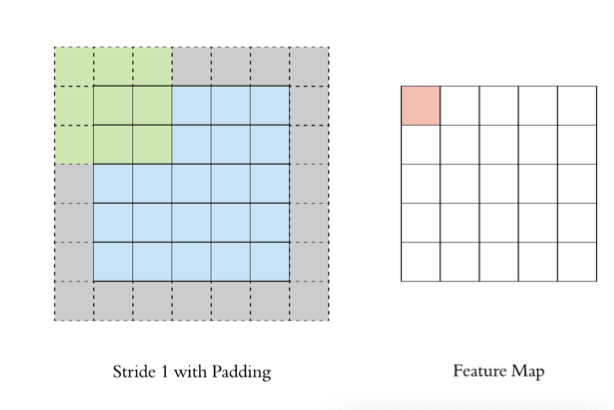
以下是关于填充的详细解释:
1. 填充的目的:
2. 填充的类型:
a. Valid Padding(无填充):
这种模式下,不对输入进行填充,卷积核只在原始输入图像内滑动。这会导致输出特征图的尺寸小于输入图像。
输出尺寸公式:((输入尺寸 - 核尺寸) / 步长) + 1
b. Same Padding(相同填充):
这种模式下,填充使得卷积核可以完全覆盖输入图像,即输出特征图的尺寸与输入图像相同。
为了实现这一点,通常在输入图像的边界周围添加适当数量的零。
输出尺寸公式:输入尺寸 / 步长
3. 填充的实现:
a. 零填充(Zero Padding):
最常见的填充方法是在输入图像的边界添加零值。这种方法简单易行,并且效果良好。
b. 镜像填充(Mirror Padding):
边界填充的像素是输入图像边界像素的镜像。这种方法有时可以减少边界效应,提高特征提取的效果。
c. 常数填充(Constant Padding):
用一个常数值填充输入图像的边界,可以是零以外的其他值。
d. 复制填充(Replication Padding):
边界填充的像素是输入图像边界最近的像素的复制。这种方法可以在某些情况下保留更多的图像特征。
5. 公式:
假设输入尺寸为 n × n n \times n n×n,卷积核尺寸为 k × k k \times k k×k,步长为 s s s,填充大小为 p p p。
则输出特征图的尺寸为: [ 输出尺寸 = ( n + 2 p − k s ) + 1 ] [ \text{输出尺寸} = \left(\frac{n + 2p - k}{s}\right) + 1 ] [输出尺寸=(sn+2p−k)+1]
6. 总结:
填充是卷积神经网络中一个关键的技术细节,它不仅影响输出特征图的尺寸,还影响卷积核对边界区域特征的提取效果。通过适当的填充,可以使卷积操作更灵活、更有效地提取图像特征。
4、Stride
Stride:步幅
按照步长为1来移动卷积核,计算特征图如下所示:

如果我们把 Stride 增大为2,也是可以提取特征图的,如下图所示:

Stride 在卷积操作中的作用:
影响输出尺寸:步幅会直接影响输出特征图的尺寸。较大的步幅会减少特征图的尺寸,因为滤波器每次移动时会跳过更多的像素。例如,在二维卷积中,如果输入图像的大小为 N × N N \times N N×N,滤波器的大小为 F × F F \times F F×F,步幅为 S S S,那么输出特征图的大小为: 输出宽度 = ⌊ N − F S + 1 ⌋ \text{输出宽度} = \left\lfloor \frac{N - F}{S} + 1 \right\rfloor 输出宽度=⌊SN−F+1⌋
计算效率:较大的步幅可以减少计算量,因为需要处理的特征图像素变少了。这对于计算资源有限的情况或者需要加速推理的场景很有帮助。
信息损失:使用较大的步幅可能会导致输入图像中一些细节信息被忽略,因为滤波器在图像上跳过了更多的像素。这在某些任务中可能会降低模型的精度。
例子说明:
假设有一个 6 × 6 6 \times 6 6×6 的输入图像,一个 3 × 3 3 \times 3 3×3 的滤波器,步幅为 2。
卷积过程如下:
这个过程会生成一个较小的输出特征图,因为每次滤波器移动的步长较大。
具体应用:
总结:
Stride 是卷积神经网络中的一个重要参数,通过控制滤波器在输入图像上的移动步长,影响输出特征图的尺寸、计算效率和信息保留。
合理选择步幅是模型设计中的一个关键步骤,需要根据具体应用场景进行调整。
5、多通道卷积计算
实际中的图像都是多个通道组成的,我们怎么计算卷积呢?
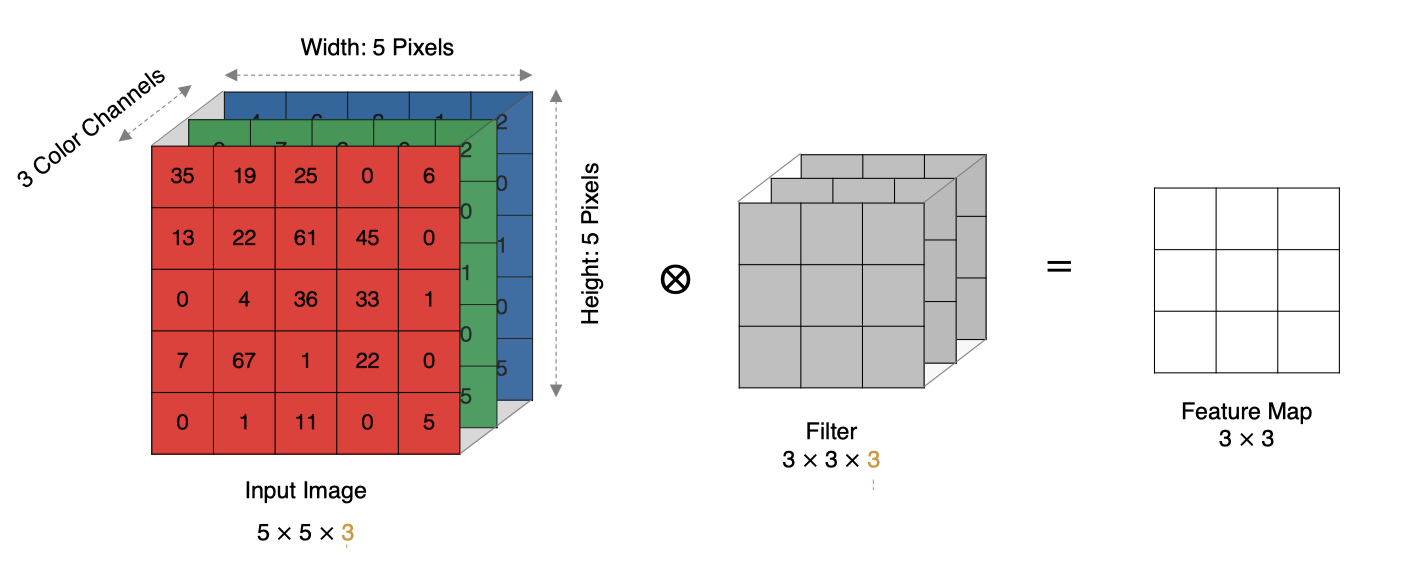
计算方法如下:
如下图所示:
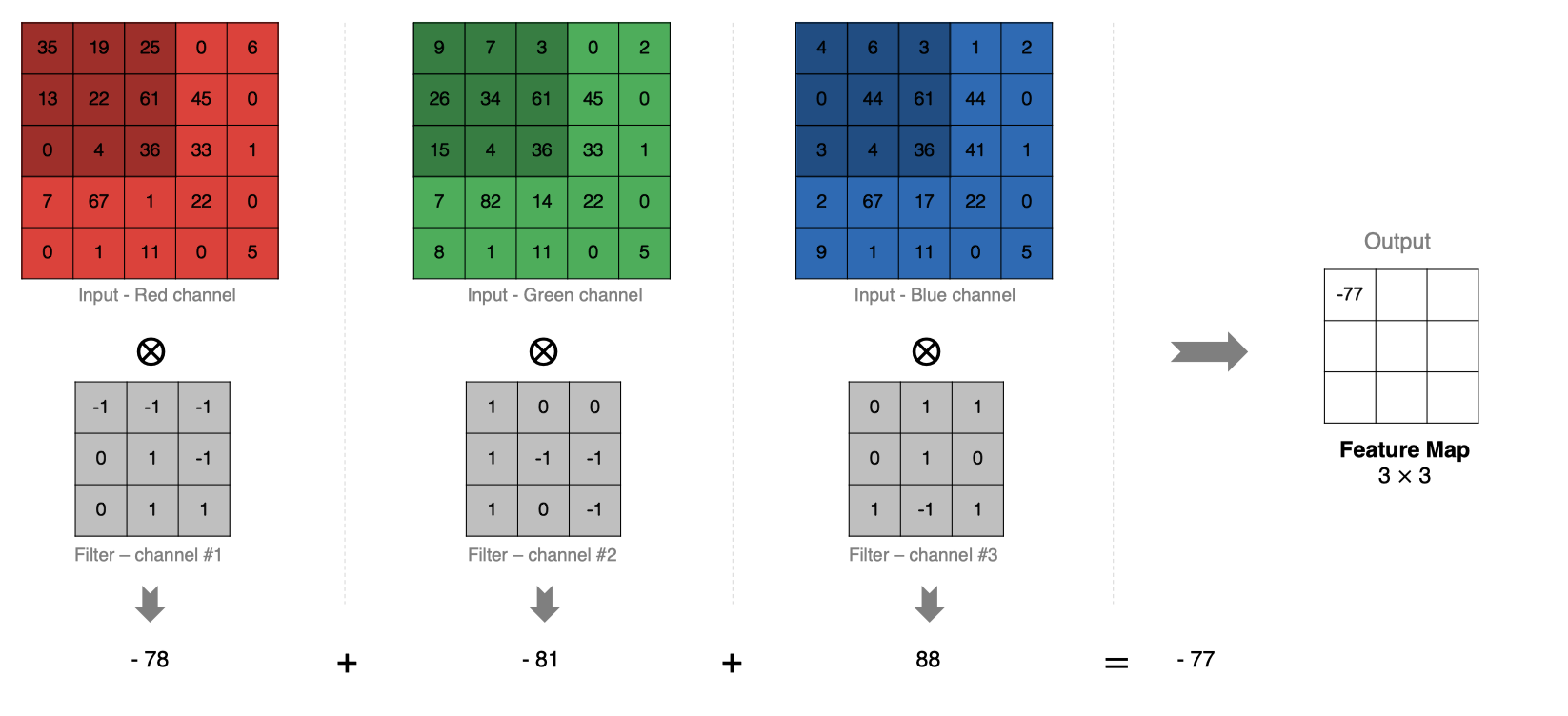
多通道卷积计算详解:
在卷积神经网络(CNN)中,多通道卷积是一个常见且重要的概念。它主要用于处理具有多个通道的输入数据,例如彩色图像的 RGB 三个通道。
1. 多通道卷积的概念:
假设我们有一个多通道输入图像,其大小为 H × W × D in H \times W \times D_{\text{in}} H×W×Din,
其中 H H H 是图像的高度, W W W 是图像的宽度, D in D_{\text{in}} Din 是输入图像的通道数。
滤波器的大小为 F × F × D in F \times F \times D_{\text{in}} F×F×Din,
其中 F F F 是滤波器的宽度和高度, D in D_{\text{in}} Din 与输入图像的通道数相同。
在多通道卷积中,每个滤波器不仅在空间上进行卷积操作,还会跨越输入图像的所有通道。
滤波器的每个通道会对应地与输入图像的每个通道进行卷积,然后将所有通道的卷积结果相加,形成单个输出特征图。
2. 计算步骤:
下面是详细的多通道卷积计算步骤:
输入与滤波器:
计算过程:
每个滤波器与输入图像的每个通道进行卷积:对于每个滤波器的每个通道 d d d( d = 1 , 2 , . . . , D in d = 1, 2, ..., D_{\text{in}} d=1,2,...,Din),我们执行以下操作: conv ( I d , K d ) \text{conv}(I_d, K_d) conv(Id,Kd)其中, I d I_d Id 是输入图像的第 d d d 个通道, K d K_d Kd 是滤波器的第 d d d 个通道。对通道进行求和:将上述卷积结果对所有通道进行求和,得到一个单通道输出特征图: O = ∑ d = 1 D in conv ( I d , K d ) O = \sum_{d=1}^{D_{\text{in}}} \text{conv}(I_d, K_d) O=∑d=1Dinconv(Id,Kd)多滤波器操作:对于每个滤波器重复以上步骤,得到 N filters N_{\text{filters}} Nfilters 个输出特征图。最终的输出特征图大小为 H out × W out × N filters H_{\text{out}} \times W_{\text{out}} \times N_{\text{filters}} Hout×Wout×Nfilters,其中 H out H_{\text{out}} Hout 和 W out W_{\text{out}} Wout 由输入图像大小、滤波器大小和步幅决定。3. 数学表示:
假设输入图像大小为 H × W × D in H \times W \times D_{\text{in}} H×W×Din,滤波器大小为 F × F × D in F \times F \times D_{\text{in}} F×F×Din,步幅为 S S S,填充为 P P P,输出特征图的大小为 H out × W out H_{\text{out}} \times W_{\text{out}} Hout×Wout,则:
H out = ⌊ H − F + 2 P S ⌋ + 1 H_{\text{out}} = \left\lfloor \frac{H - F + 2P}{S} \right\rfloor + 1 Hout=⌊SH−F+2P⌋+1
W out = ⌊ W − F + 2 P S ⌋ + 1 W_{\text{out}} = \left\lfloor \frac{W - F + 2P}{S} \right\rfloor + 1 Wout=⌊SW−F+2P⌋+1
输出特征图的深度为滤波器的个数,即 N filters N_{\text{filters}} Nfilters。
4. 示例:
假设输入图像大小为 6 × 6 × 3 6 \times 6 \times 3 6×6×3(RGB 图像),滤波器大小为 3 × 3 × 3 3 \times 3 \times 3 3×3×3,步幅为 1,没有填充(即 P = 0 P=0 P=0),有 2 个滤波器。
则输出特征图的大小为:
H out = ⌊ 6 − 3 + 2 ⋅ 0 1 ⌋ + 1 = 4 H_{\text{out}} = \left\lfloor \frac{6 - 3 + 2 \cdot 0}{1} \right\rfloor + 1 = 4 Hout=⌊16−3+2⋅0⌋+1=4
W out = ⌊ 6 − 3 + 2 ⋅ 0 1 ⌋ + 1 = 4 W_{\text{out}} = \left\lfloor \frac{6 - 3 + 2 \cdot 0}{1} \right\rfloor + 1 = 4 Wout=⌊16−3+2⋅0⌋+1=4
输出特征图的深度为 2。所以,最终输出特征图的大小为 4 × 4 × 2 4 \times 4 \times 2 4×4×2。
5. 总结:
多通道卷积在处理多维数据(如彩色图像)时非常重要。
通过对每个通道进行卷积并累加结果,可以捕捉到更多的信息和特征。
这种计算方法在卷积神经网络中被广泛应用,尤其是在图像分类和目标检测等任务中。
6、多卷积核的卷积计算
上面的例子里我们只使用一个卷积核进行特征提取, 实际对图像进行特征提取时, 我们需要使用多个卷积核进行特征提取。
这个多个卷积核可以理解为从不同到的视角、不同的角度对图像特征进行提取。
那么,当使用多个卷积核时,应该怎么进行特征提取呢?
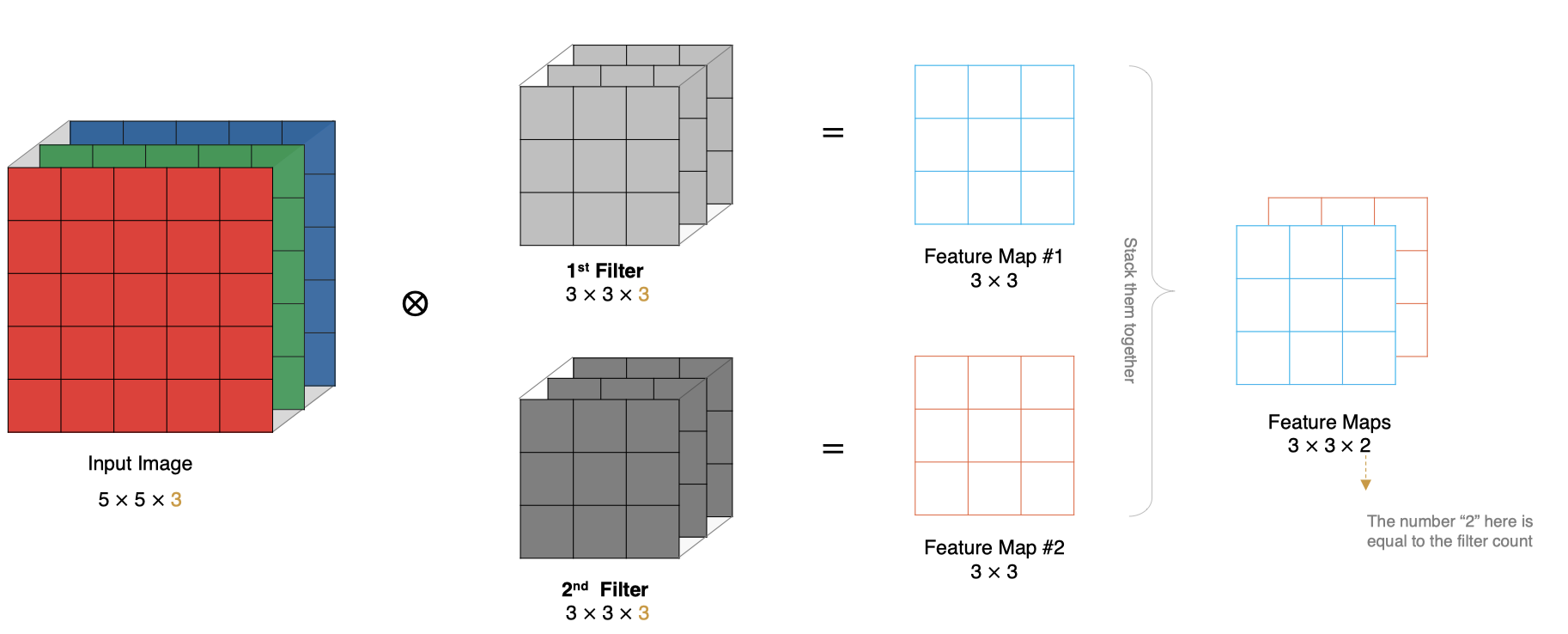
堆叠特征图:
滤波器数量。 在卷积神经网络(CNN)中,多卷积核(filter)的卷积是关键的操作,它通过对输入数据应用多个卷积核来提取丰富的特征。
下面详细说明多卷积核卷积计算的步骤和原理。
1. 多卷积核卷积的概念:
假设我们有一个输入图像,其大小为 H × W × D in H \times W \times D_{\text{in}} H×W×Din,其中 H H H 是图像的高度, W W W 是图像的宽度, D in D_{\text{in}} Din 是输入图像的通道数。我们有 N filters N_{\text{filters}} Nfilters 个卷积核,每个卷积核的大小为 F × F × D in F \times F \times D_{\text{in}} F×F×Din,其中 F F F 是卷积核的宽度和高度, D in D_{\text{in}} Din 是输入图像的通道数。
每个卷积核都会与输入图像进行卷积操作,生成一个特征图,最终的输出是多个特征图的集合。
2. 计算步骤:
输入与卷积核:
计算过程:
每个卷积核与输入图像的每个通道进行卷积:对于第 k k k 个卷积核的每个通道 d d d( d = 1 , 2 , . . . , D in d = 1, 2, ..., D_{\text{in}} d=1,2,...,Din),我们执行以下操作: conv ( I d , K k , d ) \text{conv}(I_d, K_{k,d}) conv(Id,Kk,d)其中, I d I_d Id 是输入图像的第 d d d 个通道, K k , d K_{k,d} Kk,d 是第 k k k 个卷积核的第 d d d 个通道。对通道进行求和:将上述卷积结果对所有通道进行求和,得到一个单通道输出特征图: O k = ∑ d = 1 D in conv ( I d , K k , d ) O_k = \sum_{d=1}^{D_{\text{in}}} \text{conv}(I_d, K_{k,d}) Ok=∑d=1Dinconv(Id,Kk,d)多卷积核操作:对于每个卷积核重复以上步骤,得到 N filters N_{\text{filters}} Nfilters 个输出特征图。最终的输出特征图大小为 H out × W out × N filters H_{\text{out}} \times W_{\text{out}} \times N_{\text{filters}} Hout×Wout×Nfilters,其中 H out H_{\text{out}} Hout 和 W out W_{\text{out}} Wout 由输入图像大小、卷积核大小、步幅和填充决定。3. 数学表示:
假设输入图像大小为 H × W × D in H \times W \times D_{\text{in}} H×W×Din,卷积核大小为 F × F × D in F \times F \times D_{\text{in}} F×F×Din,步幅为 S S S,填充为 P P P,输出特征图的大小为 H out × W out H_{\text{out}} \times W_{\text{out}} Hout×Wout,则:
H out = ⌊ H − F + 2 P S ⌋ + 1 H_{\text{out}} = \left\lfloor \frac{H - F + 2P}{S} \right\rfloor + 1 Hout=⌊SH−F+2P⌋+1
W out = ⌊ W − F + 2 P S ⌋ + 1 W_{\text{out}} = \left\lfloor \frac{W - F + 2P}{S} \right\rfloor + 1 Wout=⌊SW−F+2P⌋+1
输出特征图的深度为卷积核的个数,即 N filters N_{\text{filters}} Nfilters。
4. 示例:
假设输入图像大小为 6 × 6 × 3 6 \times 6 \times 3 6×6×3(RGB 图像),卷积核大小为 3 × 3 × 3 3 \times 3 \times 3 3×3×3,步幅为 1,没有填充(即 P = 0 P=0 P=0),有 2 个卷积核。则输出特征图的大小为:
H out = ⌊ 6 − 3 + 2 ⋅ 0 1 ⌋ + 1 = 4 H_{\text{out}} = \left\lfloor \frac{6 - 3 + 2 \cdot 0}{1} \right\rfloor + 1 = 4 Hout=⌊16−3+2⋅0⌋+1=4
W out = ⌊ 6 − 3 + 2 ⋅ 0 1 ⌋ + 1 = 4 W_{\text{out}} = \left\lfloor \frac{6 - 3 + 2 \cdot 0}{1} \right\rfloor + 1 = 4 Wout=⌊16−3+2⋅0⌋+1=4
输出特征图的深度为 2。所以,最终输出特征图的大小为 4 × 4 × 2 4 \times 4 \times 2 4×4×2。
5. 总结:
多卷积核卷积在处理多维数据(如彩色图像)时非常重要。通过对每个通道进行卷积并累加结果,可以捕捉到更多的信息和特征。这种计算方法在卷积神经网络中被广泛应用,尤其是在图像分类和目标检测等任务中。
7、特征图大小
输出特征图的大小与以下参数息息相关:
size: 卷积核/过滤器大小,一般会选择为奇数,比如有 11, 33, 55Padding:零填充的方式Stride:步长那计算方法如下图所示:
输入图像大小:W x W卷积核大小:F x FStride:SPadding:P输出图像大小: N x N N = W − F + 2 P S + 1 N = \frac{W - F + 2P}{S} + 1 N=SW−F+2P+1
以下图为例:
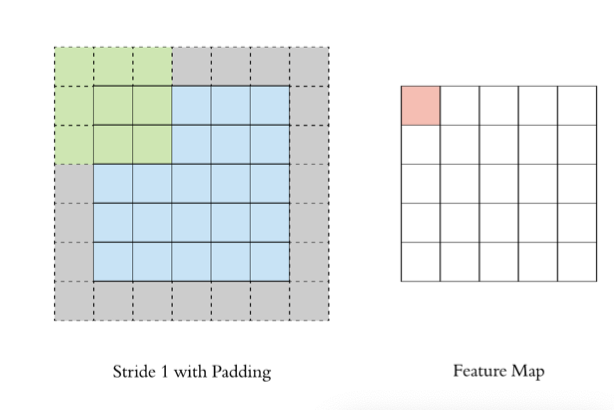
8、PyTorch 卷积层 API
我们接下来对下面的图片进行特征提取:

先写一个展示图像的函数:

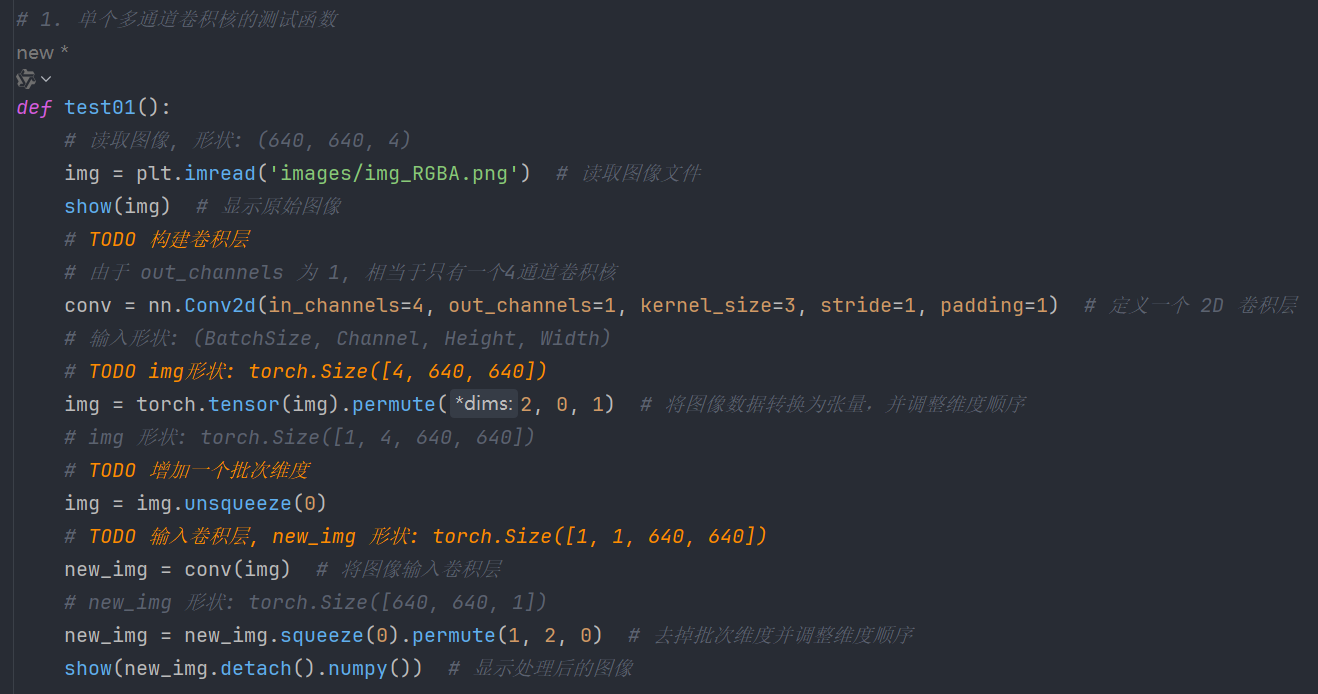
8.1、单个多通道卷积核
图示:

代码:
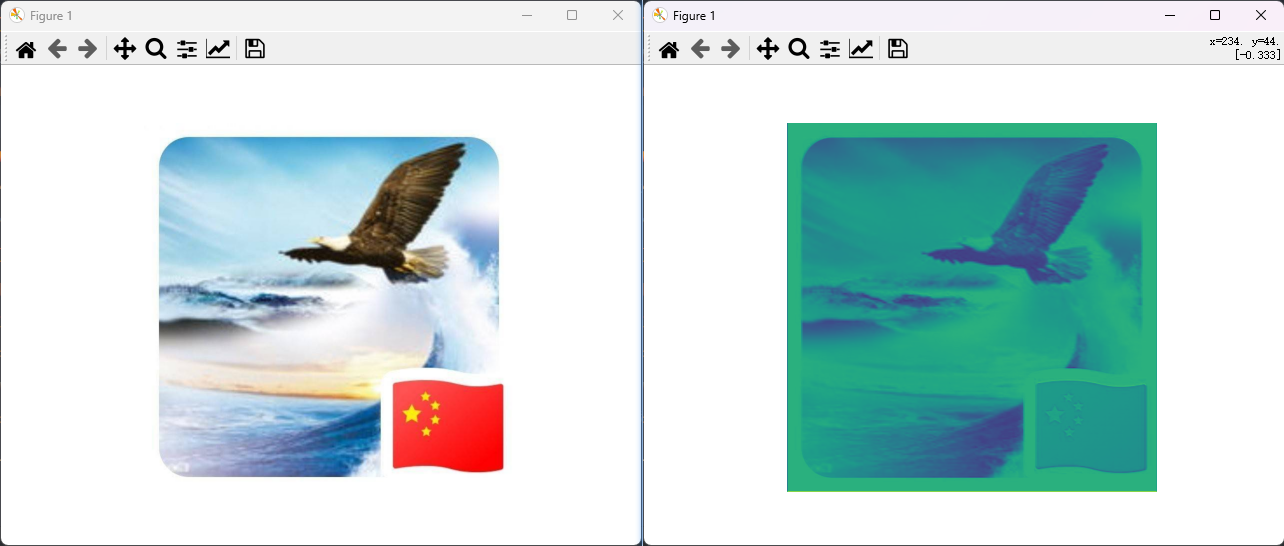
实现效果:
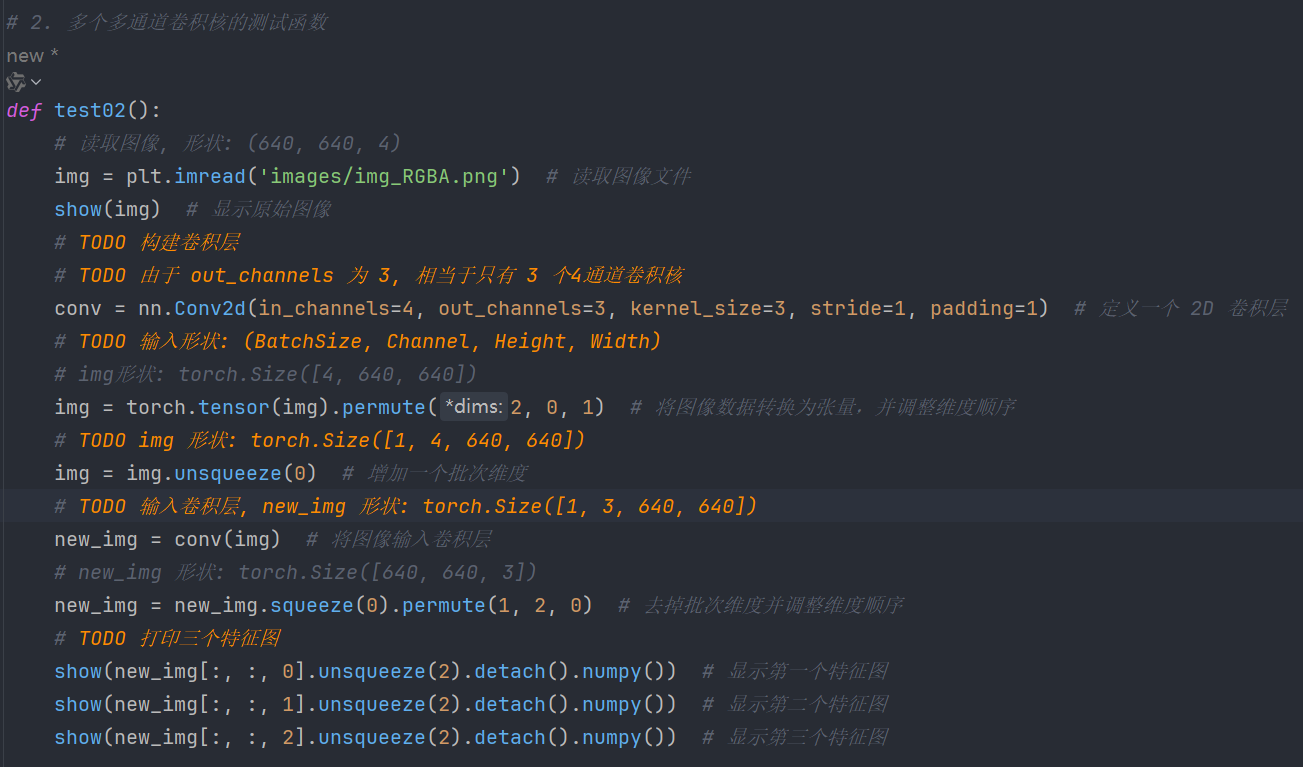
8.2、多个多通道卷积核
图示:

注意:这里的卷积核不是平行的,而是链式的!
代码:
实现效果:
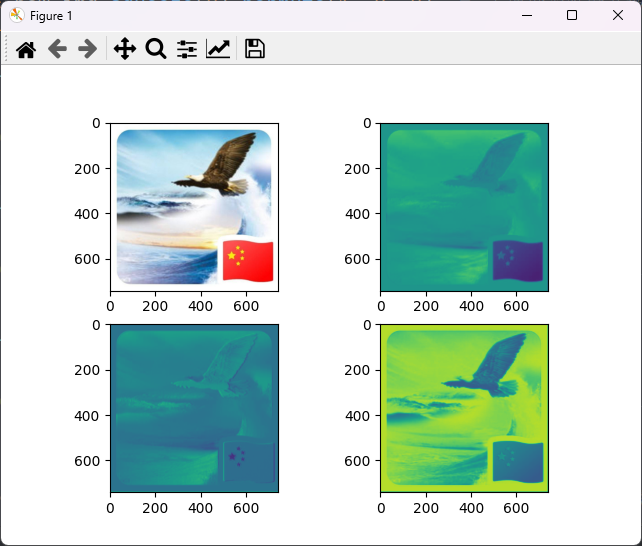
8.3、完整代码
# -*- coding: utf-8 -*-# @Author: CSDN@逐梦苍穹# @Time: 2024/8/2 2:35import torch # 导入 PyTorch 库,用于深度学习import torch.nn as nn # 导入 PyTorch 的神经网络模块import matplotlib.pyplot as plt # 导入 Matplotlib 库,用于数据可视化# 显示图像的函数def show(img): # 输入形状: (Height, Width, Channel) plt.imshow(img) # 显示图像 plt.axis('off') # 关闭坐标轴 plt.show() # 展示图像# 1. 单个多通道卷积核的测试函数def test01(): # 读取图像, 形状: (640, 640, 4) img = plt.imread('images/img_RGBA.png') # 读取图像文件 show(img) # 显示原始图像 # TODO 构建卷积层 # 由于 out_channels 为 1, 相当于只有一个4通道卷积核 conv = nn.Conv2d(in_channels=4, out_channels=1, kernel_size=3, stride=1, padding=1) # 定义一个 2D 卷积层 # 输入形状: (BatchSize, Channel, Height, Width) # TODO img形状: torch.Size([4, 640, 640]) img = torch.tensor(img).permute(2, 0, 1) # 将图像数据转换为张量,并调整维度顺序 # img 形状: torch.Size([1, 4, 640, 640]) # TODO 增加一个批次维度 img = img.unsqueeze(0) # TODO 输入卷积层, new_img 形状: torch.Size([1, 1, 640, 640]) new_img = conv(img) # 将图像输入卷积层 # new_img 形状: torch.Size([640, 640, 1]) new_img = new_img.squeeze(0).permute(1, 2, 0) # 去掉批次维度并调整维度顺序 show(new_img.detach().numpy()) # 显示处理后的图像# 2. 多个多通道卷积核的测试函数def test02(): # 读取图像, 形状: (640, 640, 4) img = plt.imread('images/img_RGBA.png') # 读取图像文件 plt.subplot(2, 2, 1) plt.imshow(img) # 显示图像 # show(img) # TODO 构建卷积层 # TODO 由于 out_channels 为 3, 相当于只有 3 个4通道卷积核 conv = nn.Conv2d(in_channels=4, out_channels=3, kernel_size=3, stride=1, padding=1) # 定义一个 2D 卷积层 # TODO 输入形状: (BatchSize, Channel, Height, Width) # img形状: torch.Size([4, 640, 640]) img = torch.tensor(img).permute(2, 0, 1) # 将图像数据转换为张量,并调整维度顺序 # TODO img 形状: torch.Size([1, 4, 640, 640]) img = img.unsqueeze(0) # 增加一个批次维度 # TODO 输入卷积层, new_img 形状: torch.Size([1, 3, 640, 640]) new_img = conv(img) # 将图像输入卷积层 # new_img 形状: torch.Size([640, 640, 3]) new_img = new_img.squeeze(0).permute(1, 2, 0) # 去掉批次维度并调整维度顺序 # TODO 打印三个特征图 plt.subplot(2, 2, 2) plt.imshow(new_img[:, :, 0].unsqueeze(2).detach().numpy()) # 显示图像 plt.subplot(2, 2, 3) plt.imshow(new_img[:, :, 1].unsqueeze(2).detach().numpy()) # 显示图像 plt.subplot(2, 2, 4) plt.imshow(new_img[:, :, 2].unsqueeze(2).detach().numpy()) # 显示图像 plt.show() # TODO 只是为了一次性显示全部图像才做了如此修改 # show(new_img[:, :, 0].unsqueeze(2).detach().numpy()) # 显示第一个特征图 # show(new_img[:, :, 1].unsqueeze(2).detach().numpy()) # 显示第二个特征图 # show(new_img[:, :, 2].unsqueeze(2).detach().numpy()) # 显示第三个特征图# 主程序入口if __name__ == '__main__': test01() # 运行单个多通道卷积核测试 test02() # 运行多个多通道卷积核测试9、小结
卷积层主要用于提取图像特征,避免对复杂图像特征的手动提取,经过实践表明,基于卷积核实现的自动特征提取在很多场景下的效果要好于手动特征提取。
登录后可发表评论
点击登录