RVC(基于检索的语音转换)是一种AI驱动的语音转换器,可以学习使用大约 10 分钟的短音频样本执行高质量的语音转换。
传统的语音转换器需要两组数据:自己的声音和要转换的目标声音,这带来了需要准备个人语音数据集的挑战。RVC 通过使用一种名为 HuBERT 的多功能特征提取模型克服了这一问题,实现了从任何声音到特定目标声音的转换。
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
2、RVC模型架构
RVC 使用两种模型: Hubert 用于特征提取, net_g 用于音频生成。
HuBERT 是一种多功能的特征提取模型。它就像 BERT 的音频版本,用于自然语言处理。HuBERT 经过训练,可以在提取每帧的 MFCC(梅尔频率倒谱系数)后预测掩蔽的 MFCC。该模型的架构基于 Transformer。
HuBERT 的输入是 PCM(脉冲编码调制),它输出一个特征向量。当输入大小为 (1, 156736) 的 PCM 时,HuBERT 生成的特征向量为 (1, 489, 256)。
net_g 的输入是特征向量,它输出 PCM。RVC 中有 4 种 net_g 变体,具体取决于版本(1 或 2)以及用于音高引导的 if_f0 的存在与否(下一节将详细介绍)。
self.if_f0 = cpt.get("f0", 1)self.version = cpt.get("version", "v1")if self.version == "v1": if self.if_f0 == 1: self.net_g = SynthesizerTrnMs256NSFsid( *cpt["config"], is_half=config.is_half ) else: self.net_g = SynthesizerTrnMs256NSFsid_nono(*cpt["config"])elif self.version == "v2": if self.if_f0 == 1: self.net_g = SynthesizerTrnMs768NSFsid( *cpt["config"], is_half=config.is_half ) else: self.net_g = SynthesizerTrnMs768NSFsid_nono(*cpt["config"])net_g 的内部结构由几个组件组成:
Embedding:对 HuBERT 中的特征向量进行编码。TextEncoder:对音调进行编码。PosteriorEncoder:生成 z,即潜在表示或特征向量,用于捕获输入音频信号的基本特征ResidualCouplingBlock:计算 z_p(后验编码向量),该向量体现了产生所需输出语音所需的修改特征,结合目标语音的各个方面,同时保留原始输入的语言内容。GeneratorNSF:从处理后的数据生成 PCM。 这些组件按顺序工作,将编码的音频特征转换为 PCM 音频格式,有效地改变语音的特征,同时保持输入的原始音调和节奏。
2.1 音调引导
RVC 包含一项称为音调引导(pitch guidance)的功能,由名为 if_f0 的标志进行内部管理。当 if_f0 设置为 True 时,在 net_g 中的语音合成过程中会额外提供输入语音的基频 (f0)。
有多种方法可用于提取输入语音的 f0,包括 WORLD 声码器和基于 CNN 的模型,例如我们在本文中介绍的 Crepe。f0 提取方法的选择不需要与训练期间使用的方法相匹配,可以在推理时任意选择。
通过使用 f0,可以反映原始语音的语调(例如音调),使其适用于唱歌和其他需要保持原始旋律或音调模式的应用。
在对话应用中,为了减少处理负荷,可以使用不使用 f0 的模型。这种灵活性允许在性能和计算效率之间取得平衡,具体取决于用例的具体要求。
2.2 Faiss
RVC 利用名为 Faiss 的向量搜索库来增强其与原始语音的紧密匹配能力。此功能通过从训练数据集中选择与 Hubert 提取的输入语音特征向量距离最近的特征向量来工作。通过对输入语音的 HuBERT 特征进行加权平均,系统可以更接近原始语音的特征。
使用 Faiss 时,启用 Protect 模式会根据基频 (f0) 调整流程。如果 f0 小于 1,则认为该片段无声,并且原始语音特征的反映程度会增加。这种方法更容易在合成语音中反映出呼吸声等细微差别,从而增强语音转换的自然度和表现力。
3、RVC使用方法
官方 RVC 可以作为 Web UI 启动。
首先克隆存储库并安装依赖库。在撰写本文时,依赖库与 Python 3.11 不兼容,因此使用 Python 3.10。
完整的设置过程在此处描述,适用于 Windows 和 Mac,以及 NVidia / AMD / Intel 硬件。你也可以直接下载完整包的zip 文件。
对于 macOS,由于与某些层的兼容性问题,必须在 CPU 上运行。这可以通过使用以下命令实现:
export PYTORCH_ENABLE_MPS_FALLBACK=13.1 推理
启动 Web UI 后,指定模型并输入音频文件,然后按转换按钮。如果你使用的模型包含 F0 并希望从男声转换为女声,请在 UI 中名为 Transpose 的音调变化设置中指定 +12。
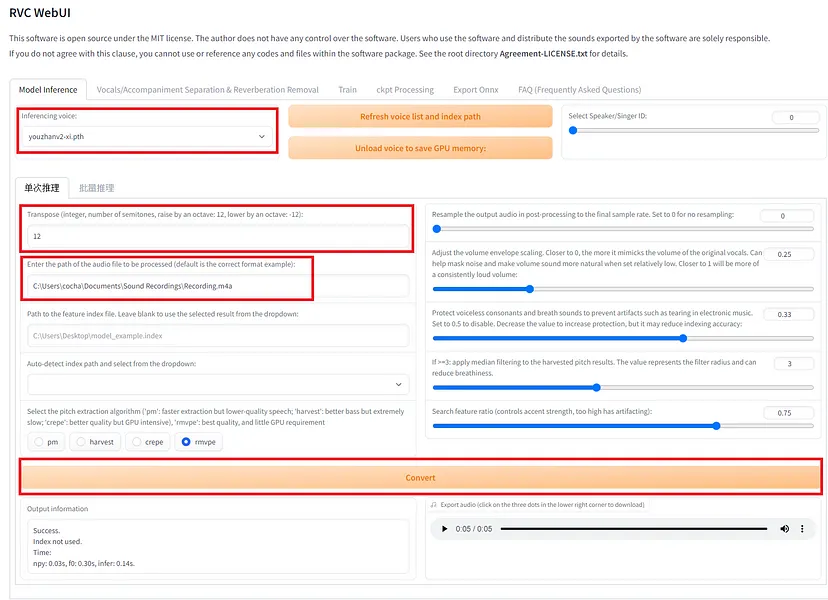
界面版本更新为 1006v2
3.2 训练
对于训练,请使用 Train 选项卡。
从huggingface下载初始权重文件 f0G40k.pth,并将其放在 pretrained_v2 目录中。
将要训练的音频文件存储在一个文件夹中,并在 UI 中设置此文件夹路径。然后单击“处理数据”、“特征提取”,最后单击“训练模型”:
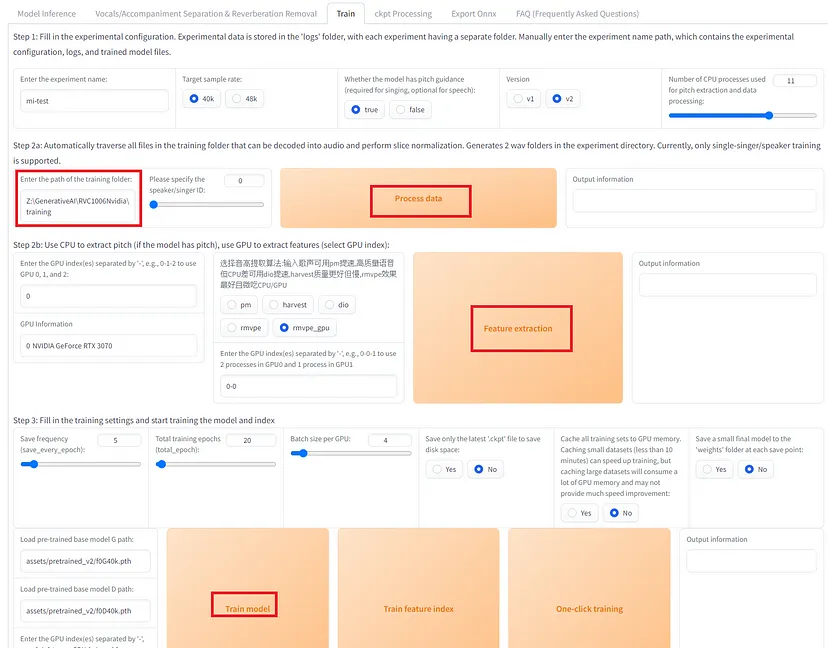
界面版本更新为 1006v2
如有必要,要获取 Faiss 的特征,请单击“训练特征索引”。训练结果将存储在“权重”文件夹中。训练大约需要 5 分钟,音频长度为 7 分钟。
3.3 RVC v1 和 v2
训练 RVC 时,你可以在版本 v1 和 v2 之间进行选择。在 v1 中,HuBERT 的输出和 net_g 的输入为 256 维。在 v2 中,这些变为 756 维。这种维度差异会影响语音转换的细节和质量,由于 v2 具有更高维度的特征空间,因此可能提供更细致入微的语音转换。
3.4 转换为 ONNX
RVC 正式支持将 net_g 模型转换为 ONNX 格式。要执行转换,请选择导出 ONNX 选项卡,指定 .pth 文件作为 RVC 模型路径,指定 .onnx 文件作为 ONNX 输出路径,然后按导出按钮。此功能方便在支持 ONNX 的各种环境和平台上使用 RVC 模型,增强语音转换模型的通用性。
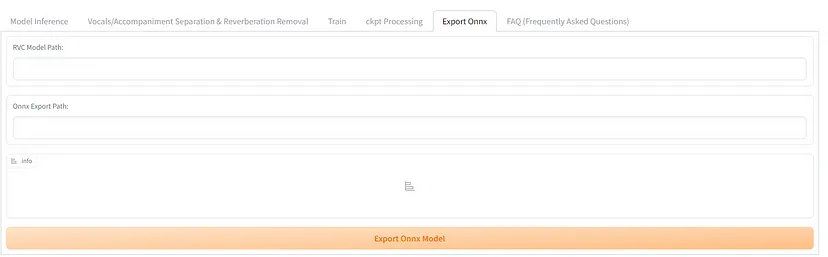
关于HuBERT,可以使用torch nightly版本通过修改RVC的源代码将其转换为ONNX。由于HuBERT与音频源无关且常用,因此你可以直接使用我们已经转换好的ONNX文件。
hubert_base 的模型大小为 293.5MB, net_g 的模型大小为 110.2MB。
原文链接:RVC语音转换AI模型 - BimAnt