note
内容概况:结合京粉app学习agent的实践
Agent架构:通过模型训练提升LLM识别工具的准确性;设计可扩展并安全可控的agent架构扩展业务能力。记忆:多轮对话应用中如何组织、存储和检索记忆来提升大模型对用户的理解。快捷回复:利用快捷回复做用户意图的路径规划,实现业务目标。Agent落地具体场景,需要定制:
Prompt 模板中 few shot 中的内容。function calling 中的外部工具定义。注意事项:
本质上所有的 Agent 设计模式都是将人类的思维、管理模式以结构化prompt的方式告诉大模型来进行规划,并调用工具执行,且不断迭代的方法。未来展望:
1、垂类领域用户意图的理解:结合垂类业务的特点,通过自然语言沟通交流的方式,更加精准更快速的识别用户的意图,模型上需要大量的真实可靠的业务数据来进行训练,机制上需要对Agent进行升级,多个更加专业的助理进行协作,例如multi Agent的应用。2、生成式推荐技术:对现有推荐系统进行技术变革,从召回、排序、重排固有的推荐链路演变成直接生成用户所需的内容或商品。3、成本效率:大语言模型虽然很强大,但是其应用也带来巨大的成本和效率上的考验,如何在垂类领域采用较小的模型实现大模型的效果,如何对模型推理加速,提高计算利用效率,降低机器成本,也是我们长期需要考虑和优化的地方。
文章目录
note一、LLM based agent实践二、实战1-AI Agent1. 工具识别2. Agent实现(1)Agent的两阶段(2)合理的架构 三、实战2- 记忆四、实战3-快捷回复五、ReAct原理和实现1. PromptTemplate2. ReAct过程 Reference
一、LLM based agent实践
某东客户端背景:一个助手帮助推客,随时解答用户问题、利用数据分析指导用户进行选品推广、提醒活动、经营指导、素材生成等。
Agent:进行规则、决策、执行。同时智能体拥有记忆、使用工具能力。
痛点:解决LLM对垂直场景专业知识不足、知识的时效性、容易出现幻觉等。
挑战:
工具的识别:开源模型对于外部工具使用能力准确率有待提高Agent架构:智能客服->智能创意->推荐系统->自动驾驶->智能机器人二、实战1-AI Agent
1. 工具识别
system prompt:不稳定把工具训练到模型:利用ToolLLM框架提供的数据构建、模型微调、评测框架来增强对工具的使用能力2. Agent实现
(1)Agent的两阶段
最初agent实现,是基于langchain的agent来开发的 langchain的开发问题:过度封装、异步并发效率低、版本前后不兼容、核心功能难易控制,由于langchain是用python实现:解释性语言进行速度慢、并发处理能力较弱、适合做实验或小型应用。在ReAct范式上,结合内部组件、自研组件,融入了工具/接口的接入、自定义工具的编排、记忆模块、vearch向量检索、prompt引擎、流式回调函数、各模块的监控、用golang重写了agent架构等,提升了系统稳定性、高并发能力。 Agent分为2各阶段: 初始化阶段: 对环境信息的收集,包括用户的输入、历史记忆加载、工具的接入、prompt接入、模型的接入、流式/非流式回调接入,langchain中agent启动阶段很耗时。针对每轮用户的交互,agent需要初始化,采用agent复用的方式进行预加载,除了用户的输入、历史记忆,其他模块全部提前加载,提升效率 迭代执行阶段:预处理模块、规划、后处理模块、执行 预处理模块需要维护一个阶段状态(第几轮迭代)和数据的拼接处理(用户的输入+大模型回复+执行结果)。规划阶段主要是通过大模型推理阶段,这里需要预留对工具的解析模块,因为不同的模型对于工具的输入是不一样的。后处理模块是对模型规划的结果进行解析,有部分需要注意对模型规划的结果做区分,结束或调用工具,需要在这里进行流式和非流式的结果存储和返回,如果需要调用工具,就进入执行模块。执行阶段将工具的调用结果送入预处理模块进行下一轮的迭代,在模型的调用和工具的调用中都预设了自定义钩子,用户可以根据需求在自定义工具执行的任意阶段进行流式输出。(2)合理的架构
(1)完全智能化架构:系统的运行完全依靠agent自主执行
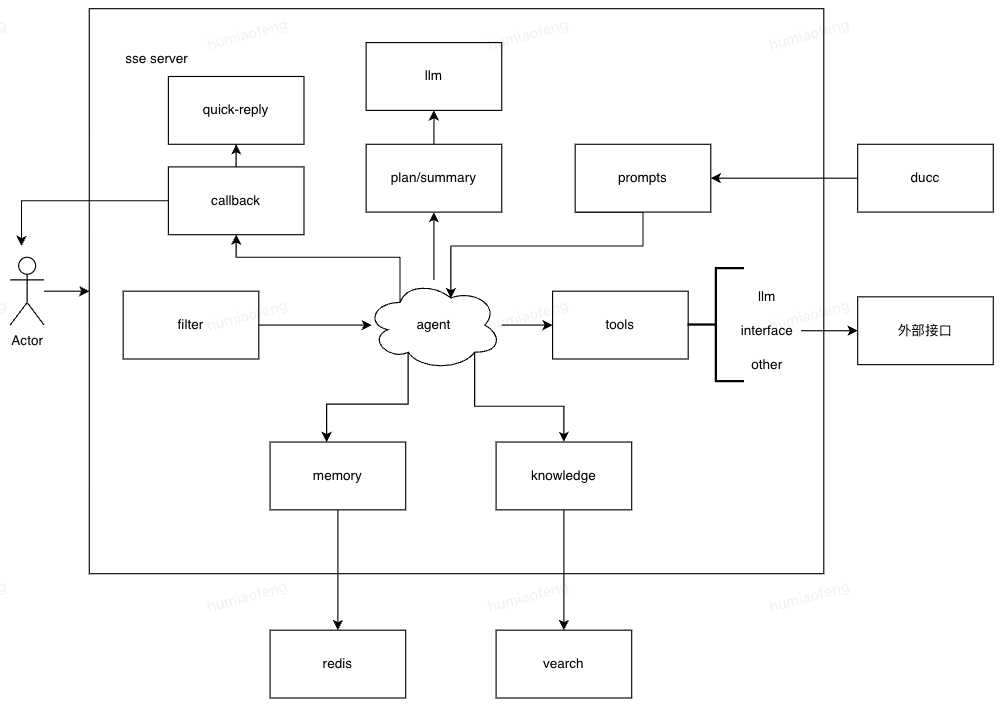
(2)安全性架构:系统运行依靠提前编写的任务流,agent只做流程的选择和判断。
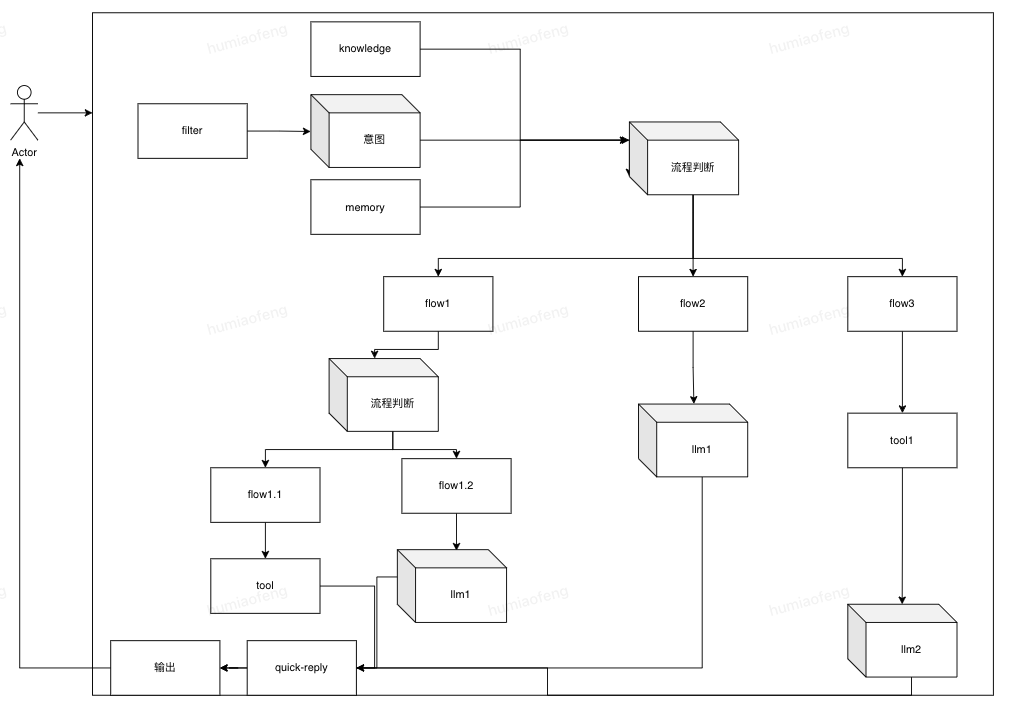
京粉智能推广助手的业务主要需求:
| 功能 | 描述及解决方案 | 依赖 |
|---|---|---|
| 知识问答 | 京东联盟有很多针对推客的使用介绍、规则、常用问题。可以通过外挂知识库解决 | 知识库 |
| 经营分析 | 对于推客经营状进行分析,包括收入、客群画像、推广建议。可以通过联盟各种已有工具接口进行数据的接入。 | 推查/用户画像/活动等工具接口 |
| 推广选品 | 目标明确的(搜索iphone15 pro max)、目标模糊的(过年送长辈的礼物)、无目的对于推荐的商品,要有推荐理由。同步相似品牌多维度对比(佣金、价格、销量、评论等)分别简单任务和复杂任务。复杂任务可以通过特定的任务流实现 | 商品接口/历史数据/同品相似品牌数据 |
| 文案生成 | 对于选好的商品,帮助推客自动化生推广文案和分享链接 | 转链工具 |
三、实战2- 记忆
对于多轮对话形式的大模型应用来说,上下文信息对于模型理解人类需求有很大的帮助,如果没有记忆,在多轮对话中,大模型的表现会比较割裂,长期的记忆也会让模型对用户的习惯、偏好有更好的认知。
重点:
模拟人类大脑记忆和检索方式,构建长/短期记忆多轮对话中的垂类领域知识的结构化记忆技术方案:记忆的构建可以概括为理解、存储、删除和检索的过程。
短期记忆:短期记忆的设计比较容易,包括短期滑窗多轮对话的方式和定长时间内的多轮对话都可以作为短期记忆,短期记忆要尽可能的存储细节信息,但是轮数要尽可能的少。长期记忆:将短期的记忆提取实体信息(通过NER抽取实体信息;通过LLM对缓存进行总结、压缩,按照记忆片段和时间戳进行向量表征并存入向量库中)垂类领域知识:比如京东的skuid,是一个数字类型,不代表任何语义信息,在前面的对话中可能会输出给用户某个skuid,如果短期记忆已被压缩成长期记忆,就会导致不包含任何语义信息的数字类型消失,我们可以通过自定义结构化信息存储的方式将这类信息与长/短时记忆进行融合存储和检索,这样在用户多轮次对话中就可以通过(“分析上一个商品”)从记忆中获取结构化的skuid来查找并分析该商品,而不是必须输入分析上一个商品的“skuid”才能够识别。检索时同时检索短时缓存记忆和向量库长时记忆检索(通过vearch实现)以及垂类领域知识,将三部分进行融合后,作为整体的记忆模块,节省记忆空间。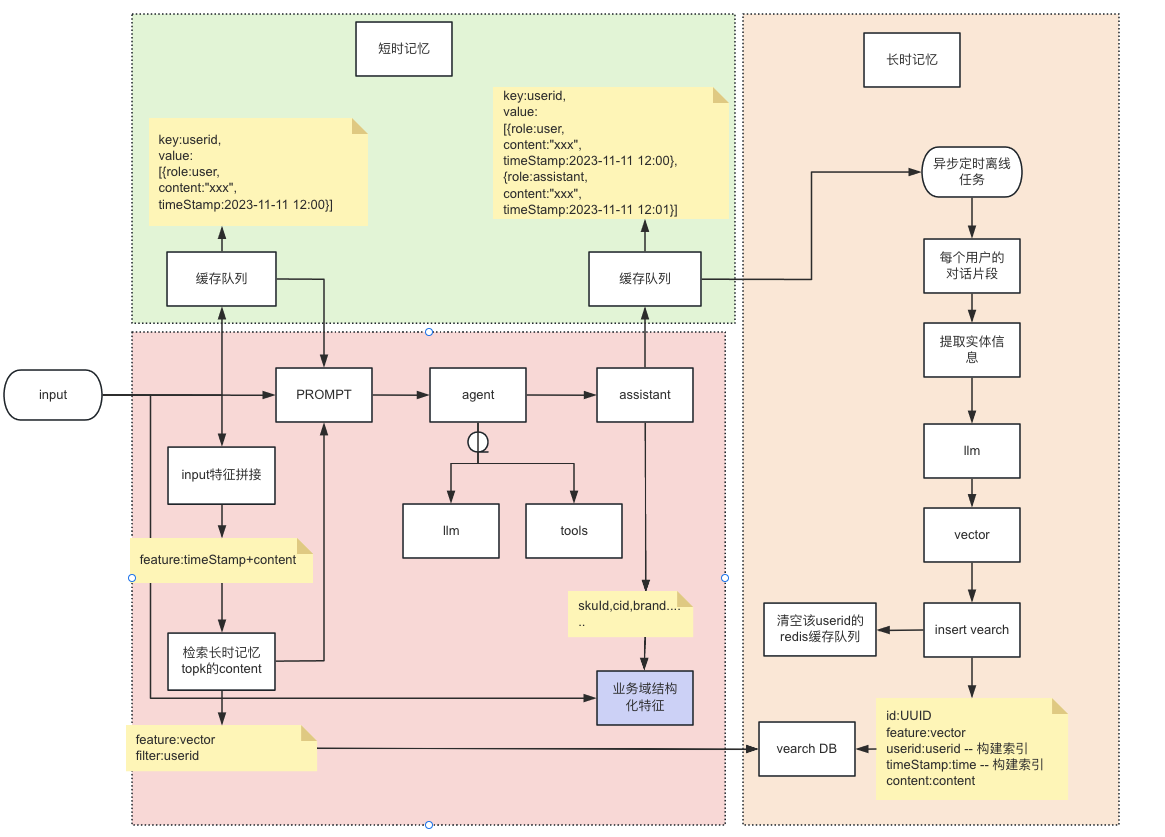
四、实战3-快捷回复
1.通过历史信息和用户的当前输入,利用大模型总结续写能力,生成一些用户可能继续输入的内容。
2.结合应用的功能预设一些常用问题。
3.重点:可以根据应用的业务目标,来规划用户使用路径图,使用户按照快捷回复的路径最终达成我们需要的业务目标,在实际业务中可以结合1、2点,既有用户想输入的,又有我们想让用户看到的功能。
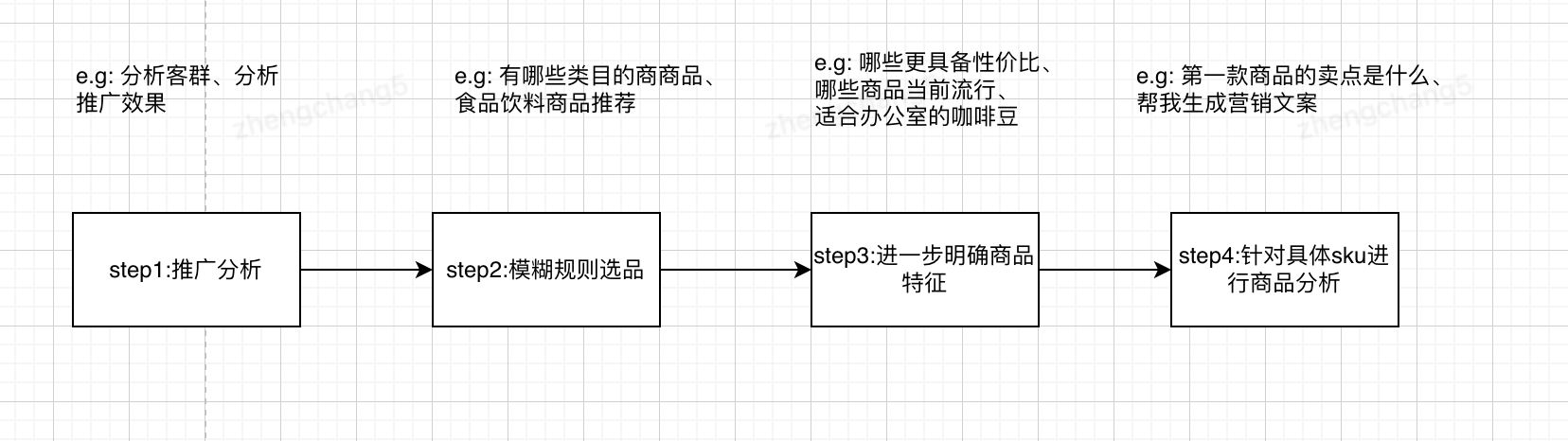
五、ReAct原理和实现
Agent落地具体场景,需要定制:
Prompt 模板中 few shot 中的内容。function calling 中的外部工具定义。LLM agent第一文,发表于2022年10月(chatgpt还没出来),提出让大模型学会工具。在论文的开头作者也提到了人类智能的一项能力就是 Actions with verbal reasoning,即每次执行行动后都有一个“碎碎念 Observation”:我现在做了啥,是不是已经达到了目的。这相当于让 Agent 能够维持短期记忆。
EX:让孩子帮去厨房拿一个胡椒粉。
Action1:先看看台面上有没有;Observation1:台面上没有胡椒粉,执行下一步;Action2:再拉开灶台底下抽屉里看看;Observation2:抽屉里有胡椒粉;Action3:把胡椒粉拿出来。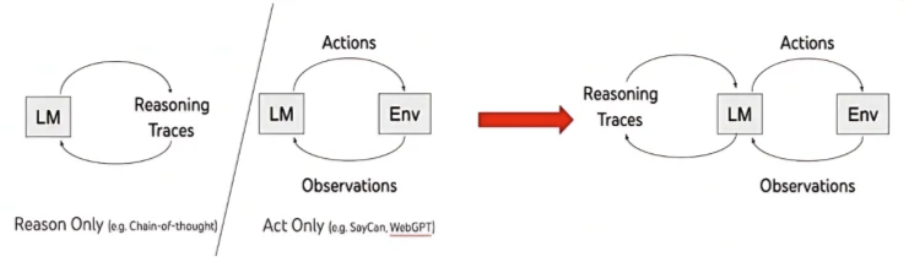
重点:本质上所有的 Agent 设计模式都是将人类的思维、管理模式以结构化prompt的方式告诉大模型来进行规划,并调用工具执行,且不断迭代的方法。
1. PromptTemplate
Answer the following questions as best you can. You have access to the following tools:{tools}Use the following format:Question: the input question you must answerThought: you should always think about what to doAction: the action to take, should be one of [{tool_names}]Action Input: the input to the actionObservation: the result of the action... (this Thought/Action/Action Input/Observation can repeat N times)Thought: I now know the final answerFinal Answer: the final answer to the original input questionBegin!Question: {input}Thought:{agent_scratchpad}2. ReAct过程
(1)生成提示词。首先,将代码中预设好 ReAct 的提示词模板(格式为Quesion->Thought->Action->Observation)和用户的问题进行合并。得到的提示词是这样的。
如果要针对自己的领域定制,需要将fewshot的内容替换,比如action可能有"Send message to someone",这里的send可能对应一个外部接口。
(2)调用大模型生成Thought+Action。 接下来将 few shot 提示词发给大模型。如果直接将上述提示词发给大模型,大模型生成将针对用户问题生成一堆 Thought,Action 和 Observation,但显然这里 Action 还没有展开,我们并不希望大模型输出 Observation。在代码里通过 Stop.Observation 来控制大模型遇到Observation后停止输出,于是大模型仅仅返回 Thought 和 Action,而不会把 Observation 给生成出来。
(3)调用大模型生成Thought+Action。 接下来将 few shot 提示词发给大模型。大模型仅仅返回 Thought 和 Action,而不会把 Observation 给生成出来。
(3)调用外部工具。拿到action后走function call,可以微调。
(4)生成Observation。api返回结果,还会将接口返回内容转换为自然语言输出,生成 Observation,然后将 Observation 的内容,加上刚刚的 Thought, Action 内容输入给大模型,重复第 2,3 步,直至 Action 为Finish 为止。
(5)完成输出。将最后一步的 Observation 转化为自然语言输出给用户。
Reference
[1] 京粉智能推广助手-LLM based Agent在联盟广告中的应用与落地
[2] Agent的九种设计模式(图解+代码)
[3] https://smith.langchain.com/hub/hwchase17/react