| 上班苦上班累,上班就想打瞌睡。 |

在当今信息爆炸的时代,数据的获取和处理变得越来越重要。网络爬虫作为获取网络数据的重要工具,已经成为许多开发者和数据科学家的必备技能。今天,我们将介绍一个广受欢迎的Java网络爬虫框架——WebMagic。


文章目录
? WebMagic简介? 主要特性1. 简单易用2. 强大的插件系统3. 多线程支持4. 灵活的爬虫管理 ? 安装和使用? 应用场景? 下载地址? 结论? 参考文献
![]()
? WebMagic简介
WebMagic是一个简单而强大的Java网络爬虫框架,它使得开发者能够轻松地编写爬虫程序来抓取网页数据。它不仅支持多线程抓取,还提供了丰富的插件系统,包括数据解析、数据存储和爬虫监控等功能。
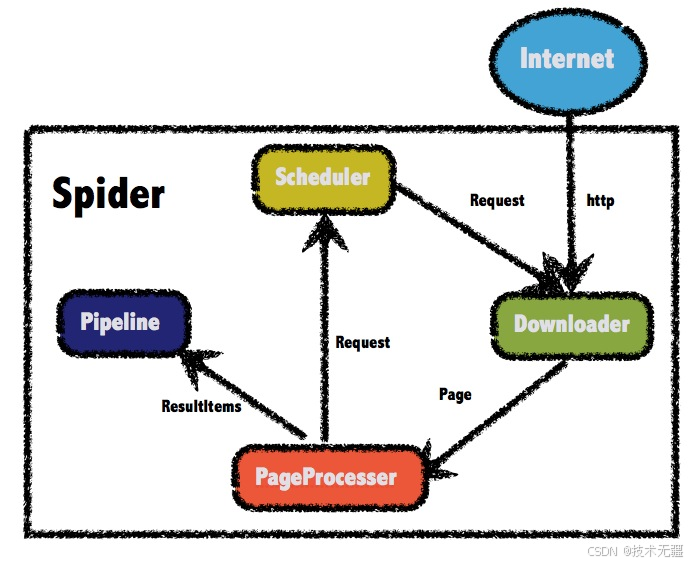
![]()
? 主要特性
1. 简单易用
WebMagic的设计哲学是简单易用。开发者可以通过简单的API快速构建爬虫,无需深入了解网络爬虫的复杂细节。
2. 强大的插件系统
WebMagic提供了丰富的插件系统,包括但不限于:
数据处理插件:支持多种数据处理方式,如JSON、XML等。数据存储插件:支持将抓取的数据存储到数据库、文件等。爬虫监控插件:实时监控爬虫的运行状态,包括抓取速度、错误率等。3. 多线程支持
WebMagic支持多线程抓取,可以显著提高数据抓取的效率。
4. 灵活的爬虫管理
WebMagic允许开发者灵活地管理爬虫任务,包括爬虫的启动、停止和重启等。
![]()
? 安装和使用
要开始使用WebMagic,你首先需要将其添加到你的Java项目中。以下是通过Maven添加WebMagic的步骤:
添加依赖:在你的项目的pom.xml文件中添加WebMagic的依赖项。 <dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-core</artifactId> <version>0.7.3</version></dependency>us.codecraft.webmagic.Site和us.codecraft.webmagic.PageProcessor类。 import us.codecraft.webmagic.Site;import us.codecraft.webmagic.Page;import us.codecraft.webmagic.processor.PageProcessor;public class MySpider implements PageProcessor { private Site site = Site.me().setDomain("example.com").setSleepTime(1000); @Override public void process(Page page) { page.addTargetRequests(page.getHtml().links().regex(".*").all()); page.putField("title", page.getHtml().xpath("//title/text()")); } @Override public Site getSite() { return site; }}us.codecraft.webmagic.Spider类来启动你的爬虫。 import us.codecraft.webmagic.Spider;public class RunSpider { public static void main(String[] args) { Spider.create(new MySpider()).run(); }}![]()
? 应用场景
WebMagic可以应用于多种场景,包括但不限于:
数据抓取:从网站抓取数据,用于数据分析和挖掘。信息监控:监控特定网站的信息更新,如新闻网站、博客等。价格比较:抓取不同网站的商品价格,进行比较分析。![]()
? 下载地址
WebMagic 最新版 下载地址
![]()
? 结论
WebMagic是一个功能强大且易于使用的Java网络爬虫框架,它为开发者提供了一种快速、灵活的方式来抓取和处理网络数据。无论是进行数据挖掘、信息监控还是其他网络数据相关的任务,WebMagic都是一个值得尝试的工具。
![]()
? 参考文献
WebMagic 官网WebMagic GitHub仓库