目录
一、前言
二、在异构加速卡AI部署yolo v8模型
2.1购买服务
2.2选择官方基础镜像
2.3部署yolo v8模型
2.4实验1
2.5实验2
2.6实验3
2.7国产卡计算性能分析
三、平台【AI计算】加速卡上手后体验感受
四、平台异构加速卡AI相关问题反馈
一、前言
我是一名图像处理工程师,现就职于某科技公司,同时我也是一名科技博主,最近了解到“超算互联网平台(www.scnet.cn)”推出了国家超算互联网「AI跃升季」:谁是下一个“AI”跃人 - AI算力体验活动(https://www.scnet.cn/home/subject/modular/index272.html)。只要体验该平台的三款加速卡便有好礼相送,于是我便简单使用了这三款产品,在平台的三款加速卡上分别进行了“yolo v8”的测试应用。简单介绍一下YOLOv8,这是YOLO系列算法的比较新的版本。这个版本的算法在保持高效、准确的同时,还进一步优化了算法结构,提高了运行速度。YOLOv8采用了全新的网络结构和损失函数,使得模型在训练过程中更加稳定,同时也提高了模型的泛化能力。所以YOLOv8,是一个比较先进的计算机视觉目标识别和预测模型,通过实验证明了该平台的三款加速卡均可完成yolo v8的快速部署。



下面跟着通信汪一起在异构加速卡AI上部署自己的yolo v8模型服务吧!
二、在异构加速卡AI部署yolo v8模型
2.1购买服务
为了体验产品,首先充值了20块钱,也有官方提供的免费试用资源,偶尔需要排下队。

2.2选择官方基础镜像
官方的模型镜像中有一个部署好的yolo v5模型服务的镜像,由于要部署的yolo版本不一样,这里我选择了一个基础镜像来自己部署yolo V8。选择好开发镜像后点击创建按钮。到此便完成了实例的创建。
2.3部署yolo v8模型
点击JupyterLab,进入JupyterLab控制面板。
点击Terminal,进入实例命令行界面
现在我们正式开始部署yolo v8模型服务:
博主选择的是torch 2.2和torchvision 0.17,由于官方镜像已经预装了torch 2.2,所以这里再安装一下opencv和torchvision就行啦:
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simplepip install torchvision==0.17.0 -i https://pypi.tuna.tsinghua.edu.cn/simple下载安装yolo v8:
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple2.4实验1
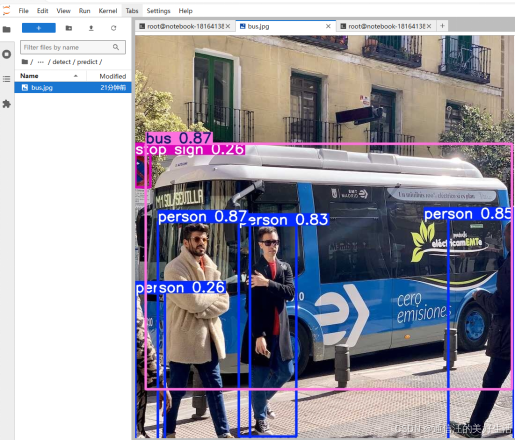
运行测试程序命令:
yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'下图是预测一张标准样例图片所需的时常,detect 4个人,1辆车,一个停车标志所用时间为70.6ms。
运行结果:

2.5实验2
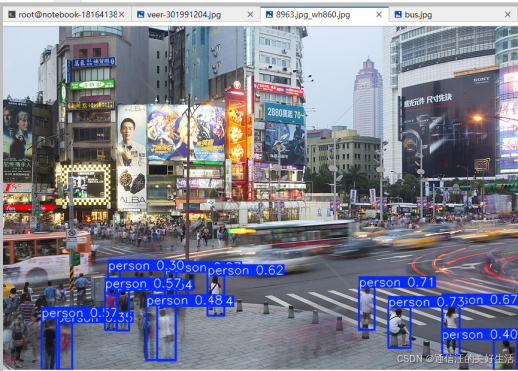
在复杂大人流量街区环境中,测试一张比较复杂的图片,算法检测出了13个人,用时107.8ms。
实验结果:
2.6实验3
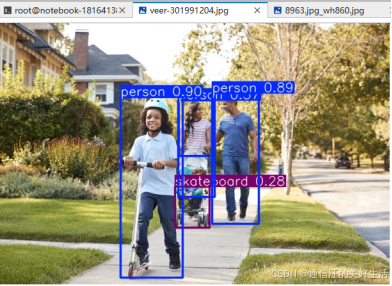
在公园小人流量环境中,选取图片进行测试,算法检测出了4个人,一个婴儿车,用时64.4ms。
测试结果:
2.7国产卡计算性能分析
下面聊AI计算方面的性能,在我上面几个不同环境下的实验运行截图可以看到模型在推理时的表现:
推理性能:大概640*480大小的图片,用时70ms左右,基本是实时输出,我觉得这是一个优秀的成绩。而且目标检测结果也是十分准确和优秀的。模型加载:yoloV8的模型,加载大概在5s到10s之间,速度在我的体验中也是可以接受的,甚至不输 L20、L40的性能,大于 A6000等型号。模型微调:微调时加载的是非量化版本,速度也比较快,基本没有感觉到等待的痛苦,并且在我所选参数组的情况下,微调的速度有点让我惊喜,比我之前在 L40上微调的速度要快一些,虽然没有严格测试,只是从感官上讲。
补充一些性能上的横向对比数据,用 rocm-smi、hy-smi、rocminfo 命令仔细检查了下,所使用的加速卡的型号。观察到,在微调时,加载 yoloV8模型用到了加速卡 20% 的 VRAM。
这款 异构加速卡AI 在 FP32/TF32 精度下分别有 49/98 T的算力,FP16/BF16 精度下都有 196TFLOPS 算力,INT8是392T,其实光看这几个数值上的表现,基本上达到了 Nvidia A100 的 50% 到 60% 左右,虽然距离 H100 还有差距,但是在国产工艺下,还支持双精度运算,并且在真实使用体感上已经还可以了。但我觉得,N卡对比国产算力卡,优势不止在于技术工艺上,还在生态、高速计算网络、持续迭代、多卡互联等这些能力上,所以希望国产卡在这些方面也能全面发展。
三、平台【AI计算】加速卡上手后体验感受
本次对于“超算互联网平台”的异构加速卡AI在配置使用上做了日常使用和一些模型训练、推理、转换上的基本使用,前期主要实现了常用配置及opencv、yolo v8的安装使用,开“超算互联网平台”的异构加速卡AI的使用体感流畅度都能保证,性能也能满足正常的使用,运行yoloV8有着非常不错的流畅性。
四、平台异构加速卡AI相关问题反馈
总的来说这是一次非常不错的体验过程,异构加速卡AI的计算性能在多种环境下均表现优异,但是在一些比较细微的地方我更觉仍有可以改进的地方,以下是一些小建议:
1、在操作人员关闭实例时会默认保存镜像,但是保存镜像的时长大概在4分钟,时间略长。
2、没有一个合适的地方可以直观的看到自己本次操作已经进行了具体多长时间。
3、访问自定义服务这个地方做的太粗糙,不够灵活多样。
以上都是一些比较真实的感受啦,当然了“国家超算互联网”也有专业的工程师客服来进行一对一服务,真的非常的人性化和为客户服务,特别是对第一次使用该产品的人来说十分用心。“超算互联网平台”的异构加速卡AI是一款非常优秀云服务器产品,优秀的价格推动AI 部署的普遍化的进程,让每一个人都有机会能使用到高性能的AI开发资源,推动AI整个生态环境的进步,希望有更多的小伙伴能在“国家超算互联网”这种高性价比云服务的基础上快速学习和成长。 “国家超算互联网”也推出了很多的活动,最近活动优惠力度比较大的有:免费领算力活动:AI算力不够用?参与 谁是下一个“AI”跃人 -AI体验推介活动,赢取千元算力券!(https://www.scnet.cn/home/subject/modular/index270.html)。