本文主要讲述Ubuntu部署Stable Diffusion WebUI应用的部署教程,及在部署过程中可能遇到的问题及解决方法。
1. 部署教程
本次安装教程使用的系统配置是:
CPU :10核,内存:220GB
GPU :L20, 显存:48GB,1张
系统:Ubuntu 22.04.3 LTS,Python版本:3.10.13
①安装pytorch(安装教程使用的是torch2.2.0+cuda12.1)
pip install torch torchvision torchaudio
(生成安装pytorch命令相关链接:https://pytorch.org/)
②下载Stable Diffusion WebUI项目下载到你自己的目录下:
Git clone GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI
若上述代码报错,则可手动将项目下载到本地,解压后上传至自己的目录
③安装程序需要的依赖
定位到下载的Stable Diffusion WebUI项目,然后依次执行如下命令:
pip install -r requirements_versions.txt
pip install -r requirements.txt
pip 安装包缓慢可换源解决,以下是一些国内的pip源:
阿里云:https://mirrors.aliyun.com/pypi/simple/中国科技大学:https://pypi.mirrors.ustc.edu.cn/simple/豆瓣(douban):http://pypi.douban.com/simple/清华大学:Simple Index命令格式:pip install <packetname> -i <sourceUrl>
如:pip install modelscope -i
启动Stable Diffusion WebUI项目,运行如下命令:
python launch.py
注意:运行时程序也会安装很多依赖包,若安装依赖包安装缓慢或装不上,可以单独找出来pip install XXXX(包名)
项目中自带的模型路径:models/Stable-diffusion/v1-5-pruned-emaonly.safetensors。
若出现如下显示,说明程序启动成功了。
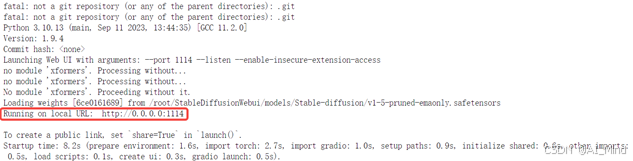
这步就可访问webUl了。。
2. 可能遇到的问题及解决方法
问题1:listen开启后,安装扩展插件时报错:AssertionError: extension access disabled because of command line flags
解决1:python launch.py --enable-insecure-extension-access 加入这个参数即可。
问题2:报错信息:
![]()
解决2:这个错误表示在您的系统上缺少 libgthread-2.0.so.0 共享库文件。具体解决方法如下:
①检查库文件路径:确认 libgthread-2.0.so.0 库文件是否存在于系统中,并且在正确的路径上。您可以使用命令 locate libgthread-2.0.so.0 或者 find / -name libgthread-2.0.so.0 来查找库文件。
如果找到了库文件,请确保路径被正确配置;您可以通过设置 LD_LIBRARY_PATH 环境变量来指定库文件的搜索路径。例如,如果库文件位于 /usr/local/lib 目录下,您可以执行以下命令来设置环境变量:
export LD_LIBRARY_PATH=/usr/local/lib:$LD_LIBRARY_PATH
如果没找到库文件,您可以尝试使用以下命令安装 libglib2.0-0 包来获得该库文件:
sudo apt-get install libglib2.0-0
问题3:git报错:SSL certificate problem:self signed certificate in certificate chain
解决3:添加如下代码:
export GIT _SSL_NO_VERIFY=true
git config --global http.sslVerify "false"
问题4:一直在install requirements
解决4:具体执行代码在这里:stable-diffusion-webui-master\modules\launch_utils.py

打开requirements_versions.txt,用如下命令行依次去手动安装依赖包:
pip install XXXX(包名)
问题5:clip报错或下载缓慢
解决5:可根据提示的下载地址自行手动下载,具体是运行如下代码:
git clone GitHub - openai/CLIP: CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image
然后放入指定文件夹,放到如下地址:
stable-diffusion-webui\stable-diffusion-webui\venv\Scripts
问题6:报错:Could not load library libcudnn_cnn_infer.so.8. Error: libnvrtc.so: cannot open shared object file: No such file or directory
解决6:运行如下命令:
cd yourenv/lib/python3.10/site-packages/torch/lib
ln -s libnvrtc-672ee683.so.11.2 libnvrtc.so
问题7:报错:TypeError: 'NoneType' object is not subscriptable
解决7:这个报错一般是在stable-diffusion软件成功安装并运行后出现的。一般是显卡的显存太小导致的,如果GPU显存比较小,建议不要画太大的图片,如果只有4GB的显存,又要画2000*3000的图片,肯定会报错的。将画面调小一点,例如调成512*512或者512*768对于4GB显存来说一般都没问题。
问题8:torch.cuda.OutOfMemoryError: CUDA out of memory.
解决8:这个报错是典型的显存不足,例如4GB显存的显卡,画968*968分辨率图像是正常的,画968*1152的分辨率图像也是正常的,画968*1264图像就报上面的错误了。
问题9:点“生成”按钮就退出程序,报错如下:

解决9:修改webui-env.sh,将原来的内容修改为如下内容:
export COMMANDLINE_ARGS="--skip-torch-cuda-test --upcast-sampling --no-half-vae --use-cpu interrogate --no-half"
问题10:报错:Torch is not able to use GPU
![]()
解决10:修改webui-user.bat文件,将原来的内容修改为如下内容:
注意:这是使用CPU去渲染图片,会非常慢。

问题11:报错:

解决11:添加git的全局设置

问题12:使用自己训练的Stable Diffusion模型无法生成图片
解决12:解决步骤如下:
①检查模型超参数:确保模型超参数设置合适。不合适的超参数可能导致模型无法生成图片。可以考虑调整学习率、批量大小等参数,以找到最适合当前任务的设置。
②改善训练数据集质量:如果训练数据集质量不足,也可能导致模型无法生成图片。可以尝试对数据进行预处理,如归一化、去噪等,以提高数据质量。同时,确保数据集的多样性,以使模型更好地泛化。
③检查模型架构:确保模型架构具有良好的数值稳定性和梯度流动性。数值稳定性对于避免在训练过程中出现NaN值至关重要,而梯度流动性则有助于更好地优化模型参数。
问题13:训练Stable Diffusion模型时NaNs Unet报错
解决13:解决步骤如下:
①检查训练过程中的损失函数:如果在训练过程中发现损失函数溢出,这可能导致NaNs Unet报错。可以尝试降低学习率,以减少优化过程中的振荡,从而避免损失函数溢出。
②使用Batch Normalization等技术:Batch Normalization等技术可以帮助解决梯度消失/爆炸问题,从而避免NaNs Unet报错。它可以使每一层的梯度保持在一个相对稳定的范围内,从而避免梯度消失或爆炸。
③处理异常值:如果输入数据存在异常值,这些异常值可能导致计算过程中出现NaN值。可以使用数据标准化等预处理方法,将输入数据处理为正常范围内的值,从而避免NaNs Unet报错。
④调试和详细分析:解决这些问题需要进行详细的调试和分析。可以通过打印关键变量的值、逐步执行代码等方式,找到导致问题的具体原因。然后根据具体原因,尝试不同的解决方案,直到问题得到解决。