目录
一、引言:
二、Transformer的整体结构
三、Transformer的输入
输入嵌入:
信息向量化的实质
独热模型:
Word Embedding
位置编码:
绝对位置编码
1、位置编码的标准:
2、两种简单的位置编码:
3、Transformer中的绝对位置编码
相对位置编码
四、Encoder
Encoder的结构
Block的结构
Multi-Head Attention(多头注意力层)
Add——Residual Networks(残差网络)
1、残差网络产生的背景
2、残差网络的结构
3、对残差网络的理解
4、Transformer的Residual Networks
Norm——Layer Normalization(层标准化)
1、Normalization的背景
2、 Normalization 的通用框架与基本思想
3、BatchNormalization(批标准化)
4、Layer Normalization(层标准化)
5、两种标准化的区别
6、Transformer的Layer Normalization
Feed Forward:
五、Decoder
Masked Multi-Head Attention:
Cross attention:
Decoder的步骤和Softmax 预测输出:
六、Training and Testing
Transformer的Training:
Transformer的Testing:
Training和Testing的注意点:
七、总结
八、后续
一、引言:
由于Transformer里面的内容较多,笔者研究的时间较长,看了很多博客和资料,这些资料都为笔者的学习提供了很多帮助,其中感觉李宏毅老师讲Transformer非常清晰明了,还是向大家强烈推荐李宏毅老师的视频,这篇文章可以用来查缺补漏。
二、Transformer的整体结构
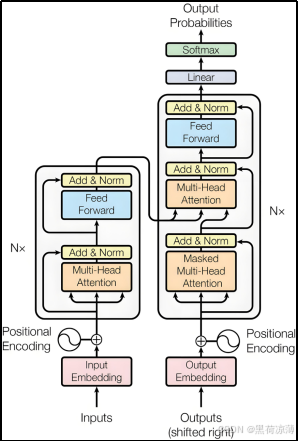
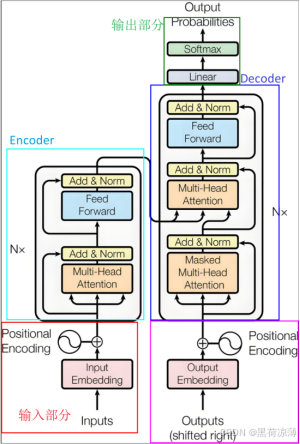
Transformer 是一种基于自注意力机制(Self-Attention)的深度学习模型架构,广泛应用于自然语言处理和其他序列到序列的任务。
上图为Transformer的内部结构图,transformer是建立在Encoder-Decoder模型上的,所以Transformer也分为Encoder和Decoder两个部分,下面将按照输入,Encoder,Decoder的顺序进行讲解。
三、Transformer的输入
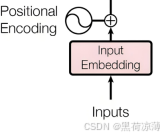
如图可知,输入经过输入嵌入之后与位置编码相加,共同组成Transformer的输入向量。
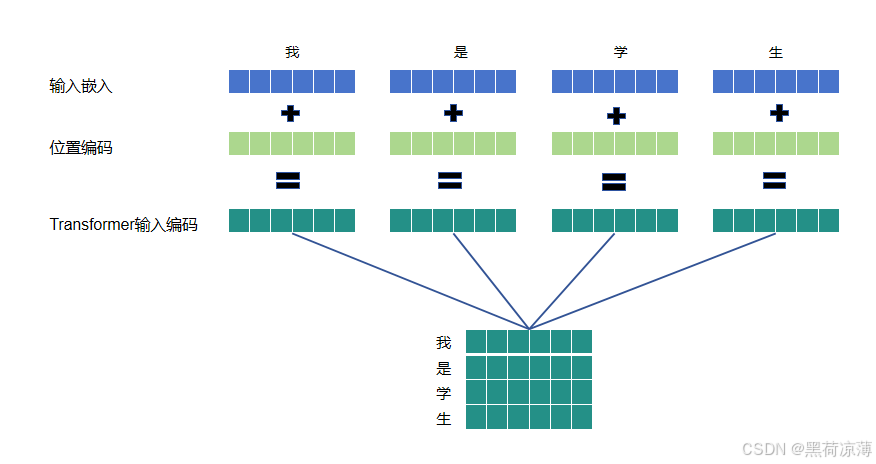
举一个具体的例子:一个句子“我是学生”输入会先经输入嵌入表示为一个包含语意特征信息的特征向量,在与位置编码的位置向量相加之后,才能输入到Transformer结构中,接下来将分别介绍输入嵌入和位置编码。
输入嵌入:
输入嵌入从本质上来说是信息向量化,将文本、图像、音频或其他形式的数据转换为向量的过程,这些向量可以作为神经网络的输入。这个过程对于神经网络的有效性和性能至关重要,因为神经网络通常需要以数值形式的向量来处理和学习数据。
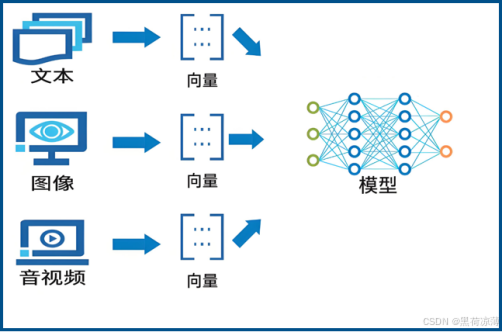
信息向量化的实质
信息向量化的实质就是将信息转换为一个高维空间的向量,这些向量在一定意义上可以体现所代表信息的特征,比如在文本信息向量化中,向量在一定程度上可以代表文字的语意特征,再通过计算这些向量的距离,就可以计算出文字中词语之间的关联程度,从而做到让计算机计算数值一样去计算自然语言的目的。
下面这张图可以很清晰的看出信息向量化的实质,信息被表示为一个个向量,在一个多维空间里就是一个个点,它们之间的距离就代表之间的关系密切程度,而且不同维度的距离还会代表不同种类的关系,神经网络可以通过计算点之间的距离来判断它们之间的关系。

独热模型:
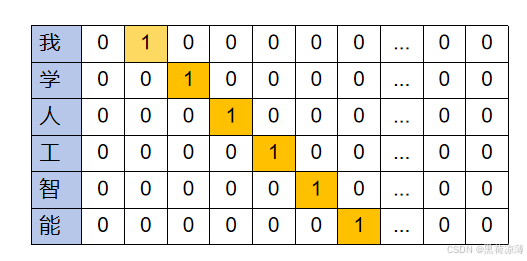
在NLP中有很多将文本信息转换为向量的模型,比如One-Hot(离散表示,或者叫做独热模型),独热模型是将文字信息编码为序列向量,向量长度是预定义的文字信息中拥有的文字量,向量在这一维中的值只有一个位置是1,其余都是0,1对应的位置就是文字信息表中表示这个文字的地方。
比如需要编码的文本信息词汇表有5000个文字,那么独热模型编码词汇表中的每一个文字都是一个1*5000维的向量,这个向量里面只有一个值为1,那么词汇表里面的所有文字都可以表示为一个向量,如下图所示:

比如将一个句子:“我学人工智能”使用独热模型转换为向量,那就是一个5*5000的张量:
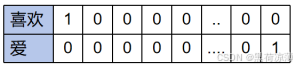
独热模型看上去非常简洁,但是它存在很多问题,比如如果文字词汇表有10k个单词,那么一个词向量的长度就是10k,但是每个向量却只有一个位置是1,其余都是0,这明显是非常浪费内存的存储资源。
而且更严重的问题是独热模型不能体现出词与词之间的关系,比如上面的“喜欢”和“爱”这两个文字意思是非常相近的,但是当按照上面的编码之后,明显在这些向量中,它们两个单词之间的距离是最远的,与它们词的含义大不相同。
这时候就会有的人会说,可以在设计的时候刻意将意义相近的文字信息的向量1的位置靠近一点,但是要知道5000字的排列组合数量是一个多么庞大的数字,靠人力去解决肯定是不可能实现的。因此对于文本信息向量化一般是交给机器处理。
Word Embedding
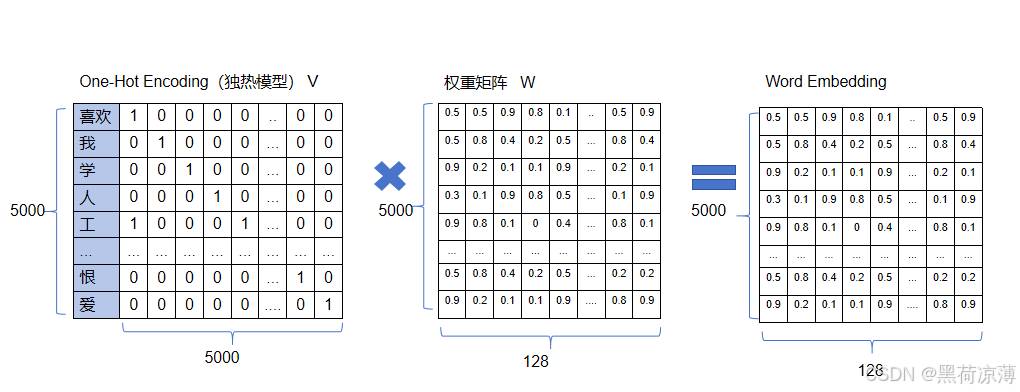
我们首先设置一个随机的m*n的稠密张量作为权重矩阵W,m为词汇表的维度,n为每个词的向量大小,对于上面的5000个文字的词汇表来说,就是设置一个5000*n的稠密张量,这个n可以自行设置,比如设置为128,即5000*128,W与刚才生成的独热模型形成的矩阵V相乘,得到一个随机产生的可以表示一定关系的整个文字词汇表的张量,也就是5000*128,然后经过大量文本数据集的训练学习来更新该权重矩阵,权重矩阵的参数不断调整,直至张量里面向量之间的距离跟向量所对应的文字语意之间的关系程度非常契合时(这句话比较长,意思就是说W随着训练不断变化,直到任意向量之间的距离跟它们对应的文字语意之间关系程度呈一定比例),最后得到包含语意特征的向量。
一般使用文本数据集中的上下文信息或者使用中心词推理上下文的方式来训练学习权重矩阵,常用的训练模型有CBOW(Continuous Bag-of-Words)和Skip-gram,具体的模型训练方式这里就不细讲。
输入嵌入部分相关的参考链接如下:
https://www.paddlepaddle.org.cn/tutorials/projectdetail/3578658#anchor-2
https://zhuanlan.zhihu.com/p/372279569
位置编码:
Transformer架构由于其自注意力机制 (Self-Attention Mechanism) 的特性,对序列中的元素没有固有的顺序感知,所以在处理像NLP中元素的顺序对翻译结果影响很大的情况下,位置编码就变得非常重要。
总的来说,位置编码分为两个类型:绝对位置编码和相对位置编码。
绝对位置编码
1、位置编码的标准:
绝对位置编码为序列中的每个位置分配一个唯一的编码,这种编码直接反映了元素在序列中的绝对位置。
首先我们得知道神经网络对于位置编码的要求。在理想情况下,位置编码应满足以下标准:
每个时间步都有唯一的编码:在处理序列数据时,神经网络需要能够区分序列中不同时间步的元素。唯一的位置编码可以确保每个时间步都有独特的表示,使得网络能够准确地捕捉序列中不同位置的语义和顺序信息。在不同长度的句子中,两个时间步之间的距离应该一致:网络在学习序列信息时,需要具备一定的“空间感知力”,即能够理解不同时间步之间的相对距离和顺序。一致的距离可以帮助网络更准确地捕捉到时间步之间的相对位置关系,而不会因句子长度的不同而导致距离的变化。位置编码不受句子长短的影响,且编码的范围是有限的:位置编码应具有固定的表示范围,不受序列长度的影响,以确保网络在处理不同长度的序列时能够保持稳定性和一致性。此外,编码的范围有限也有助于网络在训练中更容易收敛和处理。位置编码必须是确定性的:确定性的位置编码意味着对于相同位置的输入,始终生成相同的编码,这对于网络的稳定性和可重复性是至关重要的。确定性可以确保在训练和推理时,网络能够始终以相同的方式处理相同的输入。2、两种简单的位置编码:
最容易想到的两种位置编码为:
1)为每个时间步添加一个0-1范围内的数字作为位置编码,其中0表示第一个单词,1表示最后一个单词。
比如:
我正在学人工智能[0,0.16,0.32......1]
我正在认真学人工智能[0,0.125,0.25......1]
可以很明显的看出,这种位置编码不满足上面第二个条件,当句子的长度不同时,位置编码两个时间步的距离不一致,那么模型可能无法准确地区分序列中不同位置的信息,导致信息的损失或错位。
2)对每一个输入的向量,从1开始按顺序向后进行排序。
比如:
我正在学人工智能。[1,2,3,5,7,8]
在这个位置编码中,我们也可以很明显的发现不满足上面的第三个条件,当输入的句子长度不断增加时,位置编码的数字也会不断增加,数字增加也就意味着这个位置占用的权重也就越大,这样就无法凸显每个位置真实的权重。
这两种位置编码都无法满足神经网络位置编码的标准,接下来让我们看看Transformer的作者是如何设计绝对位置编码的。
3、Transformer中的绝对位置编码
Transformer的作者设计了一种基于三角函数的位置编码方式,为每一个输入向量单独生成一个dmoedl维(与前面输入嵌入得到的向量维数相等)的位置向量,代替之前的用一数字表示一个位置向量。
Transformer中的绝对位置编码方式如下:
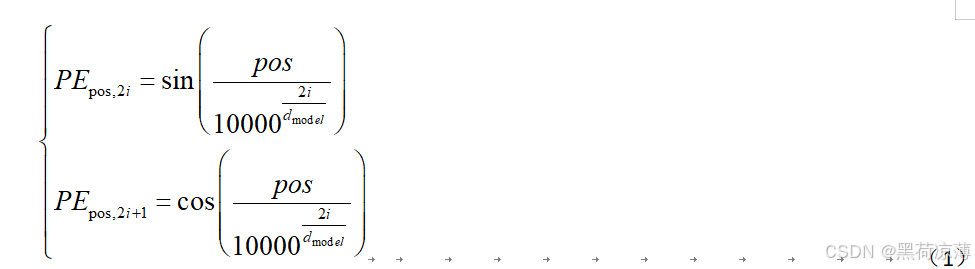
在公式里面PE表示位置编码
pos 是某token(意 见注意)在序列中的位置
d model模型中嵌入维度(embedding dimension)的大小
i 是编码维度的索引,范围为[0,dmodel/2-1]
注意:在自然语言处理(NLP)中,"token"(标记)通常指的是文本处理过程中的最小单元或基本单位。具体来说,tokenization(标记化)是将文本分割成有意义的部分,这些部分可以是单词、词根、符号、短语或其他有意义的单位。每个被分割出来的单元就是一个token。
公式上半部分为pos位置的token的位置编码向量中第2i个元素的值,下半部分为pos位置的token的位置编码向量中第2i+1个元素的值。前面可以直到位置编码向量是要跟输入嵌入向量(也就是语意特征向量)相加的,因此它们的维度应该相等,所以i的取值范围应该是从0到dmoedl。
将其表示为向量形式就是:
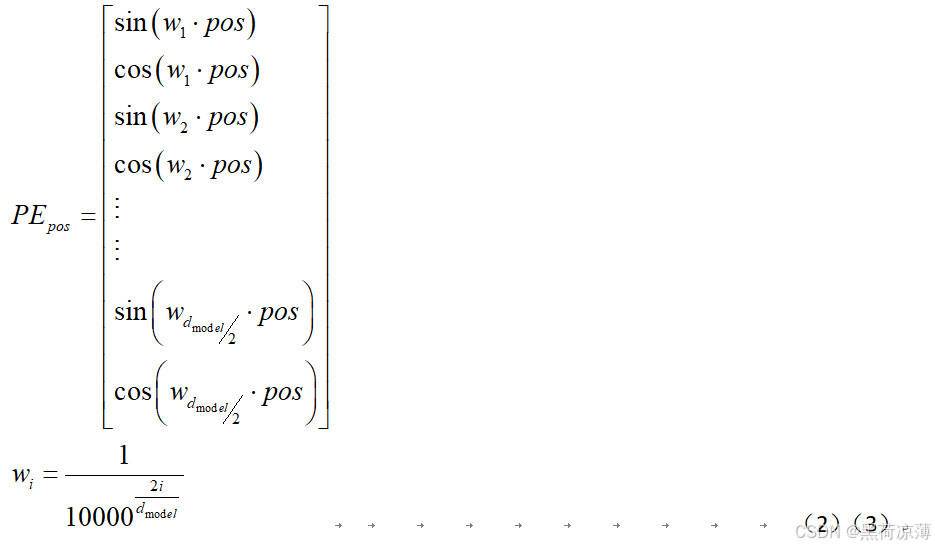
可以看到每一个位置编码向量都是正余弦交替的。
逐一对照一下该编码方法是否满足前面的四个条件:
a.每个时间步都有唯一的编码:可以很明显的看出由于pos的不同,每个时间步的编码都不相同,是唯一的。
b.在不同长度的句子中,两个时间步之间的距离应该一致:两个向量之间的相对距离可用内积来衡量,计算一下任意两个时间步之间的相对距离:
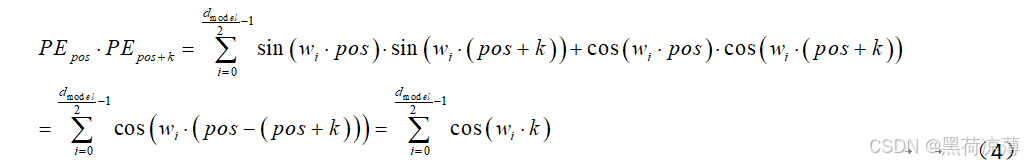
从上式可以看出,在维度固定的前提下,两个时间步的token位置编码向量之间的相对距离结果中只有k为可变的,其余都为固定的。因此在任意长度句子中,只要转换的向量维数相同(也就是dmodel相同)时,相隔同样时间(k相同)的token位置编码向量的相对距离也相同。
c.位置编码不受句子长短的影响,且编码的范围是有限的:由于三角函数的有界性,所以模型每个token的位置编码向量中的每一个元素都是有界的,因此该编码方式不受句子长短的影响且编码范围有限。
d.位置编码必须是确定性的:由公式(1)可知,位置编码至只与token的位置,维度和元素的序列号有关,相同位置的token不管是什么内容,生成的位置编码都相同,因此该编码方式是确定性的。
相对位置编码
Transformer里面暂时不涉及相对位置编码,有需要的同学可以参看这篇文章:Swin Transformer之相对位置编码详解-CSDN博客
输入部分的参考资料:
一文搞懂Transformer的位置编码_transformer位置编码-CSDN博客
Transformer的位置编码_transformer位置编码-CSDN博客
transformer 位置编码_transformer位置编码代码-CSDN博客
四、Encoder
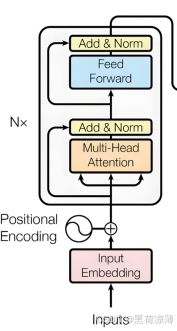
前面通过输入嵌入和位置编码相加得到Transformer的输入向量之后,向量将会进入Transformer的Encoder(编码)部分。
Encoder的结构
首先要知道Encoder的功能结构,在笔者的上一篇文章从ANN到Attention中对Encoder-Decoder架构有所介绍,Encoder其实先对每一个输入计算隐状态,然后得到上下文向量的过程。
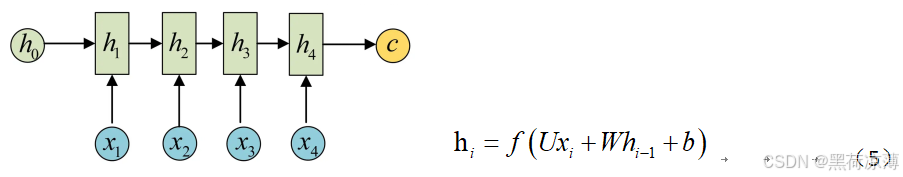
但是在Transformer中的Encoder有所不同,主要的不同点是从输入到隐状态的过程中,不再是简单的单层变换,而是六个相同的Block,最终得到隐状态。
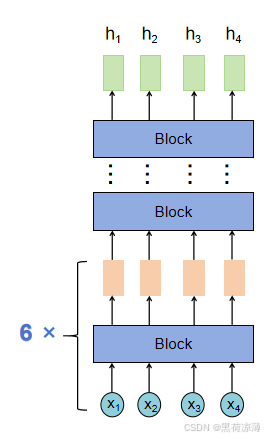
每一个Block里面的结构是相同的,接下来对Block的结构进行详解。
Block的结构
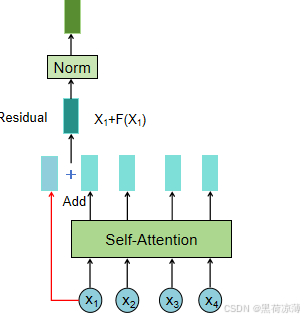
实际上Block的内部结构其实就是Transformer结构图Encoder部分除去输入和N*的部分,依次经过Multi-Head Attention(多头注意力层),Add(残差连接层),Norm(层标准化),Feed Forward(前馈层),最后再通过一次残差连接和层标准化,得到Block的输出。注意,在这里Block输入输出的形状是相同的。
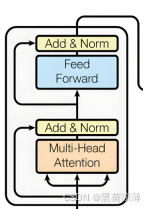
Multi-Head Attention(多头注意力层)
Multi-Head Attention(多头注意力层)在笔者的上一篇文章里有详细的介绍,在这里只是简要概括一下,Multi-Head Attention 是由多个 Self-Attention 组合形成,每一个Self-Attention针对输入的token之间不同种类的相关性进行计算attention得分,最后将输出的结果拼接在一起(Concat)。
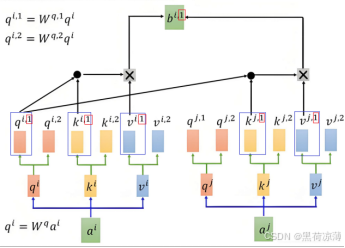
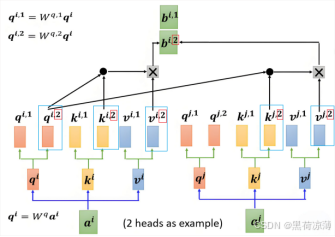
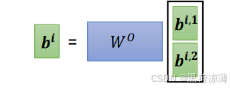
由于Self-Attention的输入输出形状是相同的,所以拼接之后的矩阵形状会在某一维度变为原来的n倍(n为Multi-Head Attention中的Head的数量),要保证Multi-Head Attention的输如输出形状也相同,就得让Multi-Head Attention的输出再传入一个Linear层,得到与输入形状相同的输出层。
Add——Residual Networks(残差网络)
论文:Deep Residual Learning for Image Recognition
[2]He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
Transformer里面这个Add层实质上就是来自这篇论文里残差网络的思想,残差网络(Residual Network,简称ResNet)是一种深度神经网络结构,最早由何凯明等人在2015年提出,用于解决深度神经网络训练过程中的梯度消失和梯度爆炸问题。
1、残差网络产生的背景
首先我们要知道对于目前的人工智能架构来说,更深层的神经网络模型可以学习到更加复杂和抽象的特征表示,从而提升模型在处理复杂任务时的表达能力。深层网络通过层层堆叠的方式可以逐级提取和组合特征,学习到更复杂和更有效的特征表示,从而在各种任务中取得更好的性能。因此构建更深层的网络是人工智能一个重要的研究方向。
网络层数的加深首先带来的就是梯度消失和梯度爆炸的问题,虽然也有一些解决办法,如正则化和标准化,虽然一定程度上解决了梯度的问题,但是却产生了网络性能的退化,网络性能的退化是指随着网络深度的增加,和理论不一致,训练误差出现了先降低后增加的现象。
而Residual Networks,ResNets(残差网络)的提出,就解决了上述问题。
2、残差网络的结构
原论文中的残差结构如下图所示:
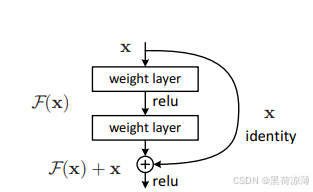
如图所示,正常的神经网络中,增加了一个 short cut 分支结构,也称为捷径连接,或者高速公路,通过捷径连接,上一层的输出x与 以上一层输出x为输入的中间层的输出F(x) 共同组成输出的结果。即:

通过这个公式就可以知道,这个输出结果将原始信息和中间层处理得到的特征信息一起保留下来。
3、对残差网络的理解
残差为什么可以解决前面提到的问题呢?我们来想象一下,当没有残差连接之后,原始的信息会经过中间层提取信息的某一方面的特征,而这个提取特征的能力的程度是经过训练得到的,当训练的过程中由于神经网络的层数过深,导致训练的效果不好,那么该层得到的信息数据传递给下一层时,就是一个残缺版的信息数据,后面的层就算训练的非常完美,最后也不会有很好的效果。
但是当添加上残差连接之后,由于捷径连接的存在,原始信息数据可以无损的通过,所以就算该层学习到的数据不够好,那么叠加上无损通过的原始数据,依然保留了原始数据,后面的层仍然可以继续对原始数据进行特征提取,不至于一步错,步步错。
4、Transformer的Residual Networks
同样,如果该层学习到的效果很好,那么依然会保留着学习到的数据和原始数据,下面的层依然可以在这些数据基础上进一步学习优化。进而让网络模型的表现越来越好。
在Transformer里面的Residual Networks表现在输入和Multi-Head Attention处理之后Add(也就是相加)的地方。
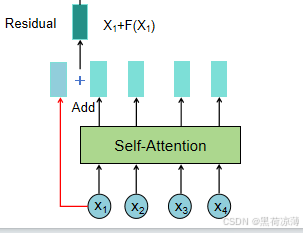
输入Xi与F(Xi)相加就是残差连接,这里的F就是自注意力机制层。
残差网络部分相关参考链接:残差结构详解-CSDN博客
残差结构详解-CSDN博客
图像识别(五)| resnet50 的残差结构到底是什么?-CSDN博客
Norm——Layer Normalization(层标准化)
论文:Layer Normalization
[3]Ba, Jimmy Lei, Jamie Ryan Kiros, and Geoffrey E. Hinton. "Layer normalization." arXiv preprint arXiv:1607.06450 (2016).
这里李宏毅老师讲的 Normalization有关内容非常清晰明了,推荐大家去看看他的讲解。链接:
第五节 2021 - 类神经网络训练不起来怎么办 (五) 批次标准化 (Batch Normalization)_哔哩哔哩_bilibili
1、Normalization的背景
通过前面的介绍可以知道,为了得到效果更好的模型,一般神经网络会叠加很多的层,但是每通过一层,输出与输入之间的数据分布关系会发生变化,通过层层叠加,高层的输入变化会非常剧烈,高层参数需要不断适应新的输入数据分布,将会导致学习速度下降;下层输入的数据变化可能趋于变大或者趋于变小,将会导致梯度爆炸或者梯度消失;Normalization的出现就是为了解决这个问题。
2、 Normalization 的通用框架与基本思想
首先,假设一个神经元的输入为
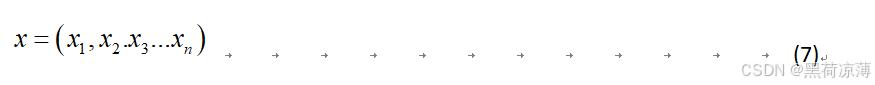
Normalization 的通用框架为:

其中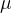 为均值,
为均值,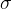 为标准差。
为标准差。
Normalization的基本思想是将 x 送给神经元之前,先对其做平移和伸缩变换, 将 x 的分布规范化成在固定区间范围的标准分布。
经过标准化处理后,原始数据转化为无量纲化指标测评值,各指标值处于同一数量级别,可进行综合测评分析;还可以避免由于有些数值过大引发的数值问题。
3、BatchNormalization(批标准化)
BatchNormalization可以理解为纵向标准化,Batch Normalization 会针对每个通道独立地进行,对于给定的通道,它将计算该通道内所有元素(考虑所有的批量大小、高度、宽度)的平均值和方差,然后使用这些统计量来归一化该通道的值。
具体来说,对于每个通道的每个像素,Batch Normalization 通过以下公式进行操作:

其中,x是输入值,μ是均值,σ 2 是方差,ℇ是一个很小的数,以防止除以零。标准化之后数值平均变为0、标准差变为1。
由于BatchNormalization是对同一时间步进入某一层的一个通道的所有数据先求均值和方差,理论上来说是要计算全部的训练数据的均值和方差,但是考虑GPU的内存,所以是对每一个Batch里面的数据来预估训练数据的均值和方差,所以BatchNormalization需要较大的 batchsize 才能较为合理的代表训练数据。
4、Layer Normalization(层标准化)
LayerNormalization可以理解为横向标准化,与 Batch Normalization 不同,层归一化是对单个样本中所有特征进行标准化,而不是在批量的维度上。这意味着层归一化不依赖于批量的大小,使其特别适用于批量大小不一或需要标准化单个样本的场景。
层标准化计算方法与批标准化的计算方法相同,只是计算的维度不同,LN和BN不同点是标准化的维度是互相垂直的
一般CNN用BN,RNN用LN,时序特征并不能用Batch Normalization,因为一个batch中的序列有长有短,比如NLP中翻译不同的语句,语句的长度是不同的,如果使用BN,由于为了补齐长短不一的样例而添加进去的0使得较长序列中词语的含义向量规模相对变小,较短序列中的词转换为含义向量的规模相对变大。平白无故增添了误差抖动。
5、两种标准化的区别
Batch_Normalization计算同一个批次中所有样本中的某一通道的平均值和方差,来估计整体样本值得平均值和方差,如果在batch_size较小的情况下,就可能导致估计的计算的平均值和方差不是整体样本的平均值和方差。
Layer_Normalization则是计算某一样本内的所有的平均值和方差,这样就不会收到batch_size的影响。
6、Transformer的Layer Normalization
在Transformer中,残差连接之后就会对向量进行层标准化:
层标准化部分相关参考链接:
Layer Normalization(LN) 层标准化 (为什么Transformer用LN)(手写手动实现LN)-CSDN博客
【关于 BatchNorm vs LayerNorm】那些你不知道的事-技术圈
归一化 (Normalization)、标准化 (Standardization)和中心/零均值化 (Zero-centered)-CSDN博客
一文读懂Batch_Normalization和Layer_normalization_batch normalization和layer-CSDN博客
Feed Forward:
Feed Forward 层比较简单,是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数。
对前面得到标准化的数据做两次线性变换,为的是更加深入的提取特征。
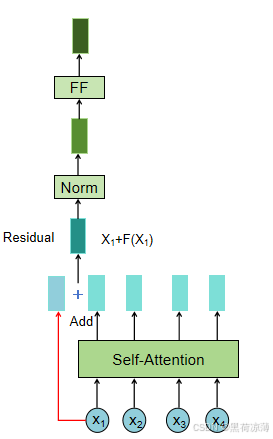
FeedForward的作用是:通过线性变换,先将数据映射到高纬度的空间再映射到低纬度的空间,提取了更深层次的特征。
Feed Forward层输出的数据会再经过一次残差连接。至此,block里面的结构已经讲完了。
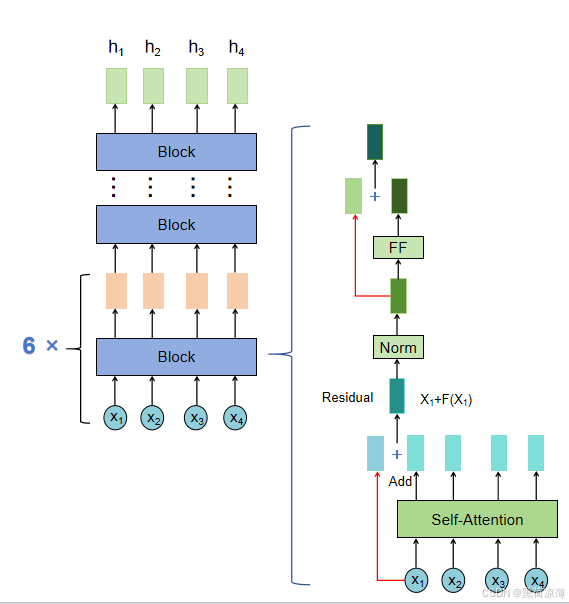
输入向量经过相同结构的六个block之后之后就会得到Encoder的输出,得到蕴含上文编码信息的矩阵 C,传递到Transformer的Decoder结构中。
五、Decoder

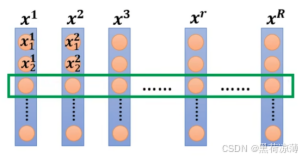
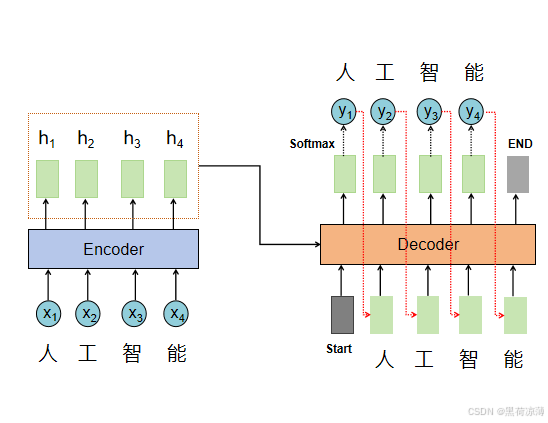
仔细看Decoder的结构图可以看出Decoder有两个输入,第一个输入是前面Encoder的输出,包含了输入向量的特征和上下文信息,第二个输入其实就是前一个时间步Decoder的输出,下面这张图比较直观:

其实讲完Encoder之后再来介绍Decoder就非常简单了,Decoder与Encoder结构上很类似,只有几点区别,了解这些区别之后学习Decoder就会比较简单。主要的区别如下:
Decoder结构中包含两个 Multi-Head Attention 层:
第一个 Multi-Head Attention 层采用了 Masked 操作;
第二个 Multi-Head Attention 层采用了cross attention;
最后有一个 Softmax 层预测输出。
Masked Multi-Head Attention:
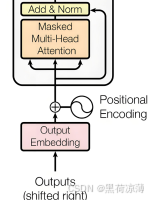
由于Decoder的输入是前一个时间步的Decoder的输出,Decoder不像Encoder一开始就知道整个语句里的每一个token,从而实现并行操作,Decoder的输入必须等前一个时间步的输出出现,也就是Decoder的输入是一个token一个token进行的。
而初始的Self-Attention是要考虑所有输入之间的关联性,如下图所示:
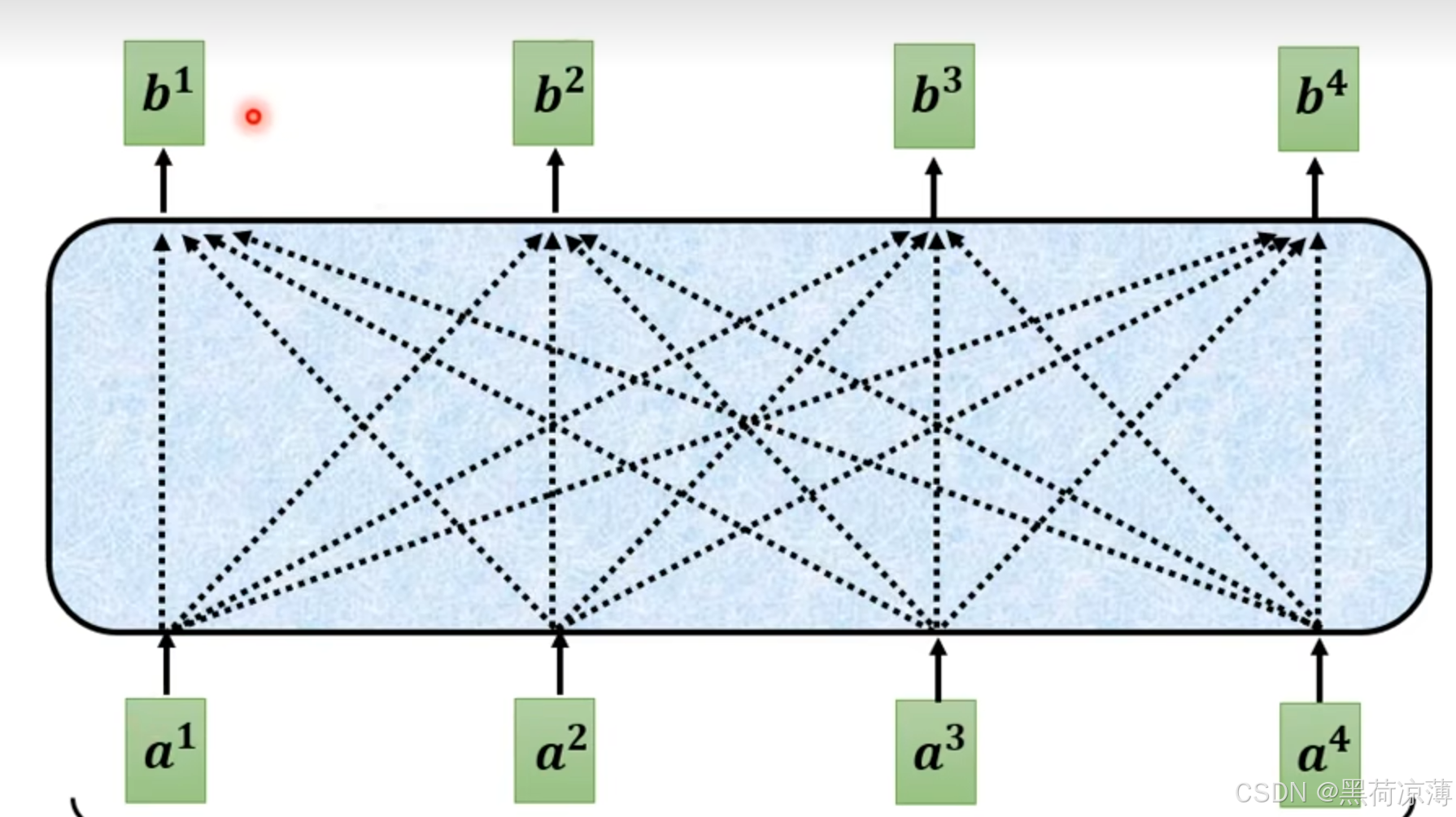
每一个输出b都与所有的输入有关,所有的输入都将参与Attention运算。但是现在输入是一个一个产生的,所以输出只能与现有的输入有关。 
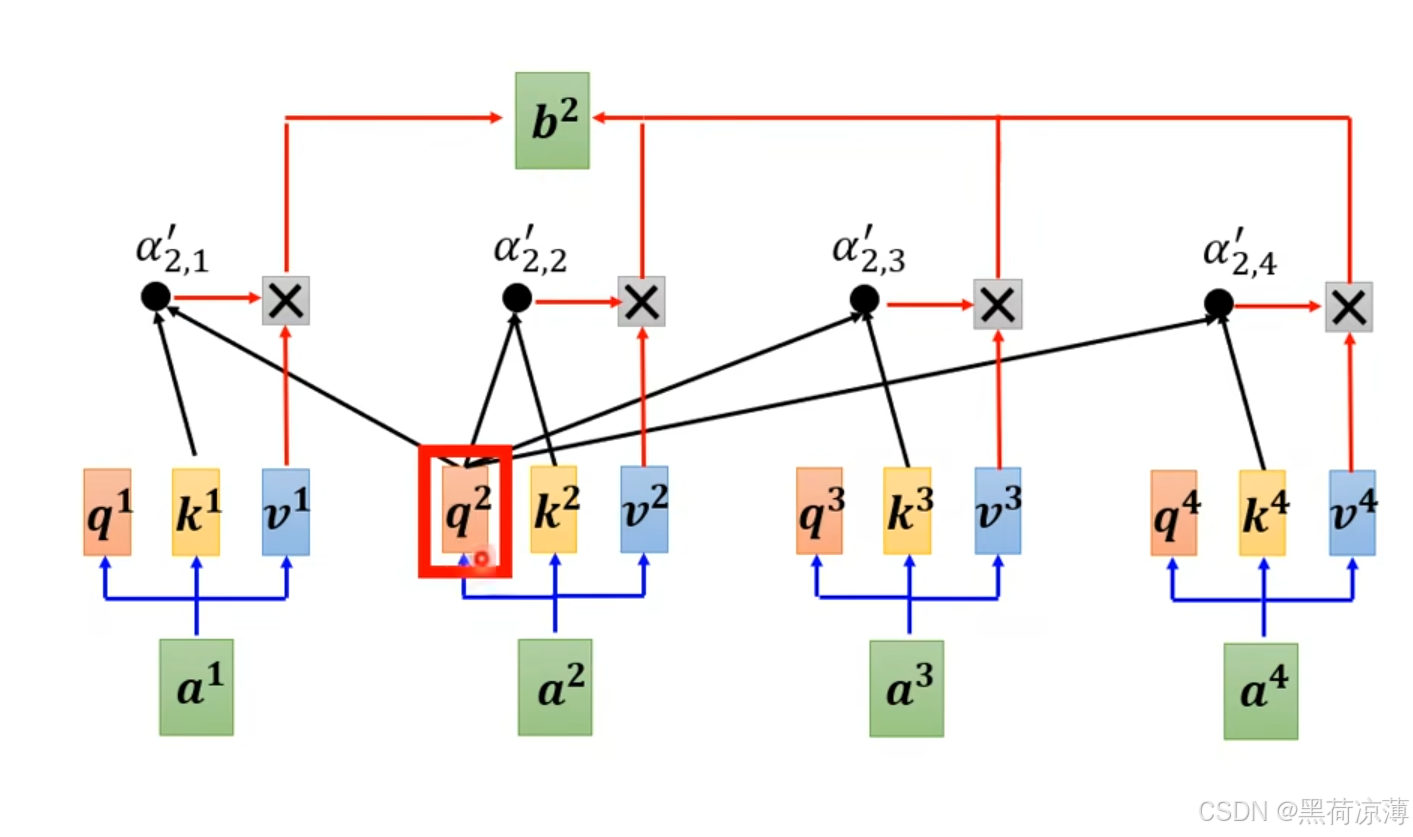
举个例子,比如我们想计算b2,本来如果计算时所有的输入都是存在的,那么应该先算出虽所有输入的Q,K,V,然后使用第二个输入计算得到的q2与所有输入计算得到的ki计算attention得分,最后与vi进行加权求和,如下图所示:
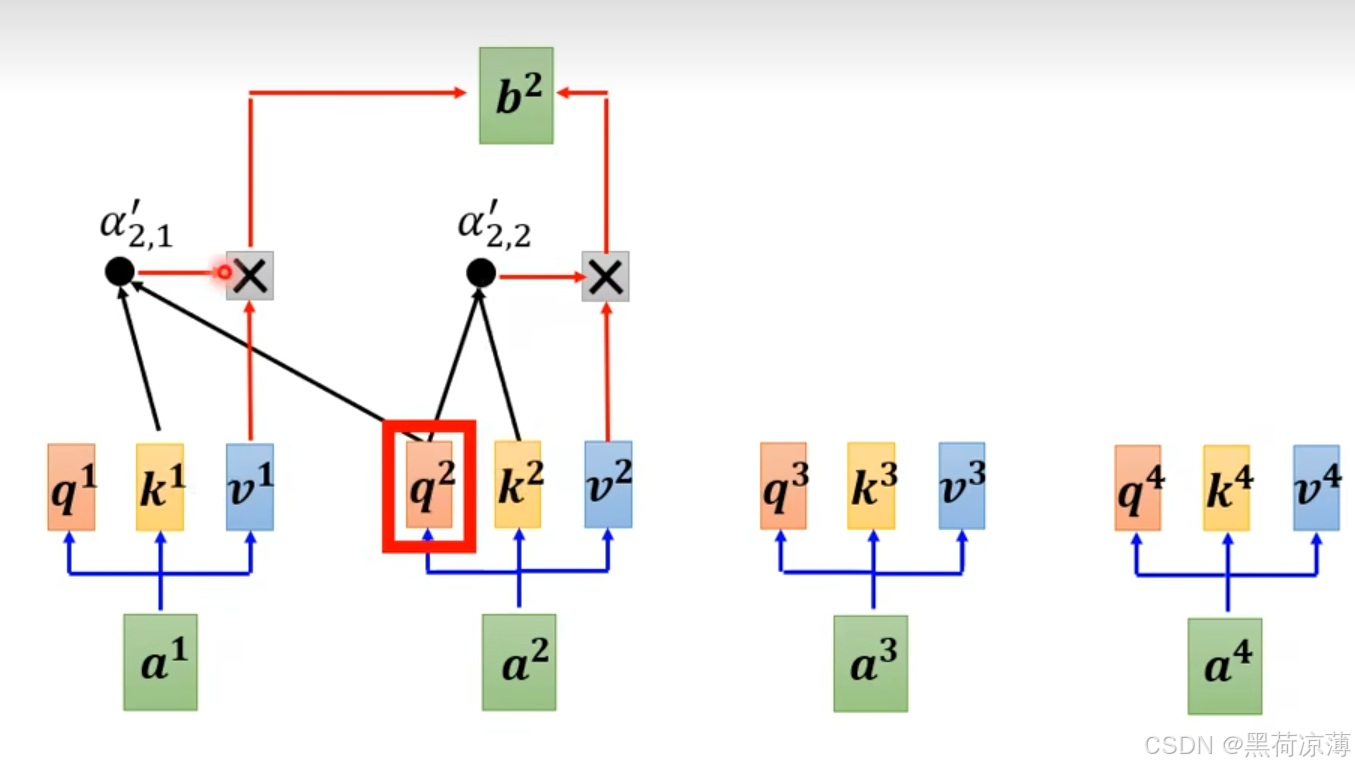
但是其实再求b2时,只有前面两个输入是存在的,后面的输入还没有输出出来,所以,计算b2时只考虑前面两个输入。如下图所示
Masked Multi-Head Attention理论上就是上面所讲的步骤,在实际操作中,为了可以实现并行运算,虽然Transformer推理时是一个一个词预测,但是训练时会把所有的结果一次性给到Decoder的输入,但是会对输入的矩阵进行掩码处理,效果等同于一个一个词给,防止其看到后面的信息,也就是不要让前面的字具备后面字的上下文信息。
Masked Multi-Head Attention部分相关参考链接:
层层剖析,让你彻底搞懂Self-Attention、MultiHead-Attention和Masked-Attention的机制和原理_masked multi-head attention-CSDN博客
2021 - Transformer (下)_哔哩哔哩_bilibili
Cross attention:
Decoder block 第二个 Multi-Head Attention 变化不大,从名字就可以看出来,Cross,交叉Encoder和Decoder两个模块的数据进行attention计算。 具体来说, Self-Attention 的 K, V矩阵不是使用 上一个时间步的 Decoder block 的输出计算的,而是使用 Encoder 的输出计算得到的。
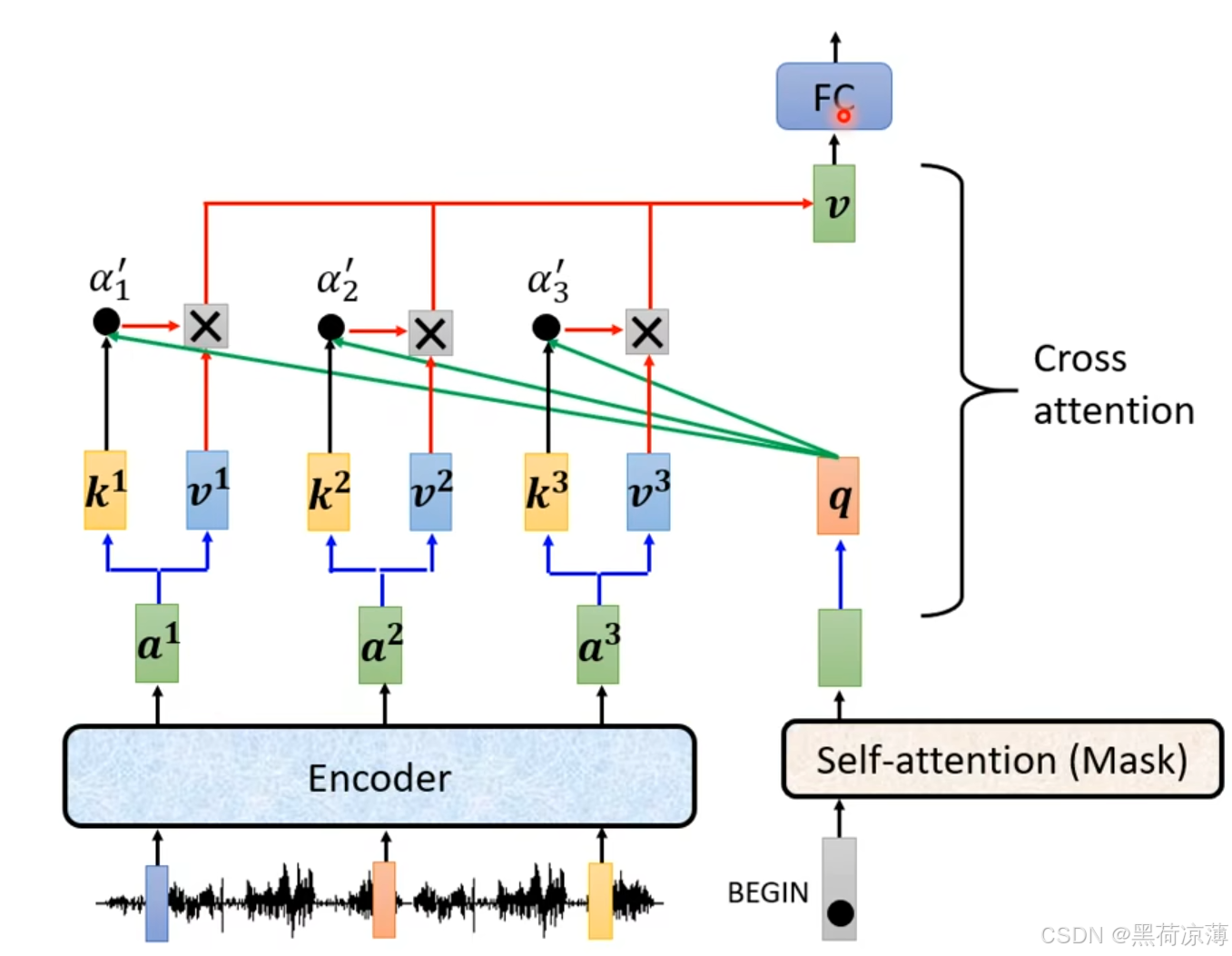
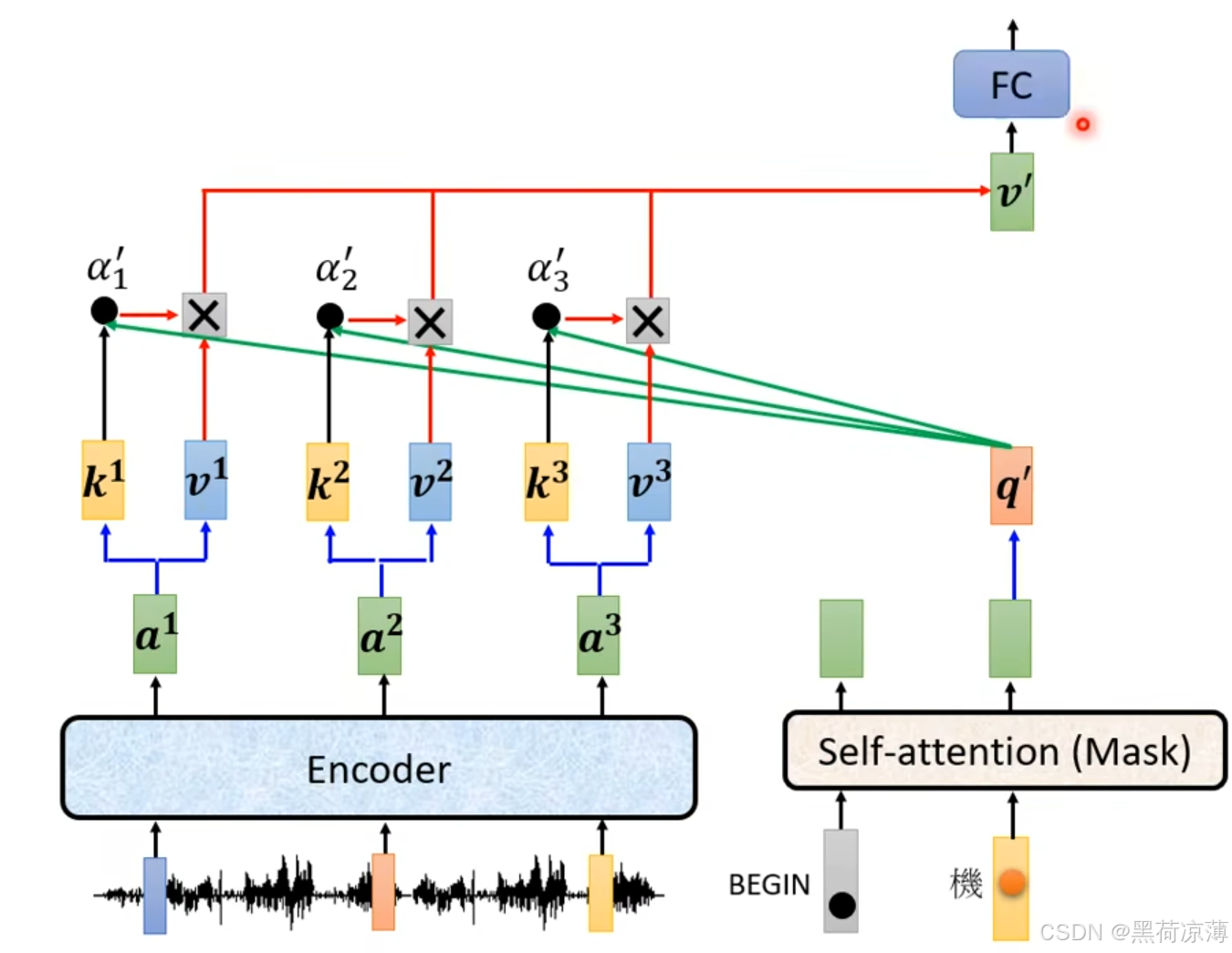
如图所示,在计算Cross attention时,q是来自Masked Multi-Head Attention的输出计算得到,而k和v则来自Encoder的输出经过与不同的权重矩阵得到。
Decoder的步骤和Softmax 预测输出:
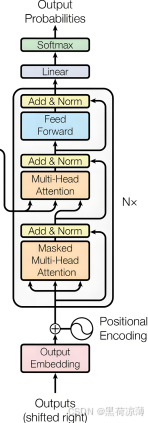
讲完前面的每一个单独的结构之后,我们来梳理一下预测(inference)时Decoder部分的步骤:首先一个开始的信号从最下方输入,开始时Decoder是没有输出的,所以需要一个开始的标志,也就是开始的信号(begin),经过语意嵌入(Embedding)和位置编码(Positional Encoding)之后,计算Masked Multi-Head Attention,然后经过残差连接(Add)和层标准化(Layer Normalization)之后,与Encoder的输出进行交叉注意力计算(Cross attention),再输入全连接层,残差和层标准化,这里得到的向量就是只包含第1个token的信息。
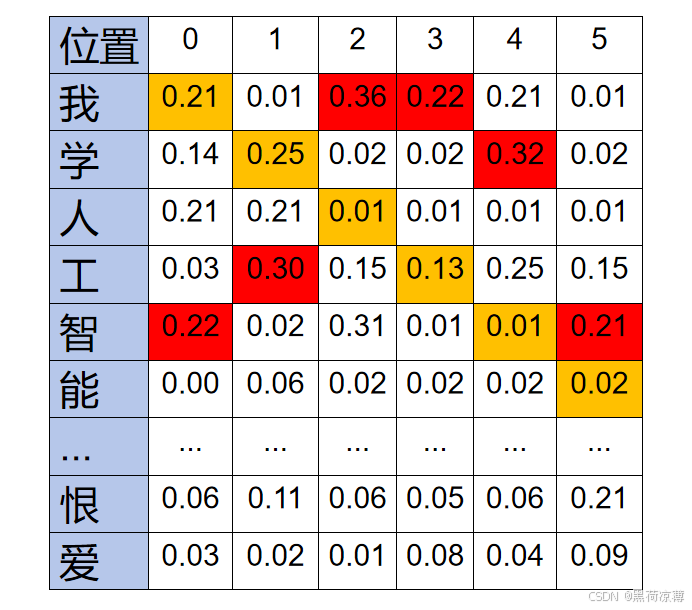
这个向量再传出Decoder之后,经过一个全连接层进入Softmax 层,Softmax 函数将输入的每一个元素转换成一个 [0, 1] 范围内的数值,这些数值可以被解释为概率。这两层其实就是根据向量中的信息预测第一个输出是哪一个文字,Softmax 层会输出一个与Word Embedding中词汇表的维度一样的向量,向量中哪一维的数字也就是概率最大,那第一个输出的就是该维对应的文字。
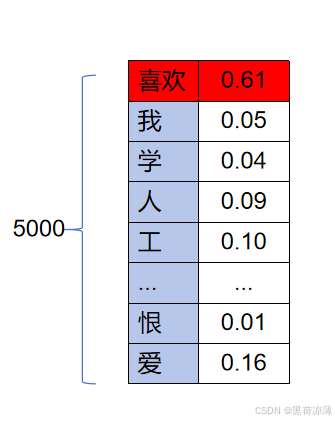
图中就是对应前面所讲的Word Embedding对应的文字词汇表维度为5000,其中,每一个字的概率为[0,1]范围的数值,所有的概率加起来为1(由于没有列全,所以下面显示出来的概率数值加起来不一定为1),其中概率最大的文字将会作为输出,对应下图中就是输出“喜欢”。
第一个输出之后,该输出就会作为第二个时间步的输入,同样进行一遍前面的步骤,但是最后得到的向量就是包含前两个token的信息,然后同样进入一个全连接层和Softmax 层,这两层就是根据向量中的信息预测二个输出是哪一个文字,Softmax 层同样会输出一个与Word Embedding中词汇表的维度一样的向量,向量中哪一维的数字也就是概率最大,那第二个输出的就是该维对应的文字。
以此类推,将整个句子输出完毕。
六、Training and Testing
当读者看到这里时,Transformer里面的每一个结构都已经了解的很清楚了,现在我们要做的是通过Training和Testing来将前面的结构连接起来,形成一个整体。
首先要知道Training和Testing的概念分别是什么。
Training(训练):
1)训练指的是使用已知的数据集(通常是训练集)来构建(或训练)机器学习模型的过程。
2)在训练阶段,模型通过学习输入数据的特征和相应的输出(标签或目标)之间的关系来调整模型的参数。
3)目标是使得模型能够在输入新数据时做出准确的预测或分类。
Testing(测试):
1)测试指的是使用另一个独立的数据集(测试集)来评估训练好的模型的性能和泛化能力。
2)测试集是模型在训练过程中没有接触过的数据,用于模拟模型在真实场景中的表现。
3)通过测试集,可以评估模型对未知数据的预测或分类准确率,从而验证模型的效果和可靠性。
Transformer的Training:
首先我们知道在训练时,输入数据和对相对应的输出都是可见的,训练时,输入向量经输入嵌入和位置编码之后进入到Transformer中,经过Encoder编码和Decoder解码之后会输出一个矩阵,其实就是一个几率的分布。
举个例子,输入向量是一个语音,说的是“我学人工智能”,这时训练集中相对应的label应该是一个的6*5000的矩阵,分别在:“我学人工智能”相对应的位置上数值为1,其他位置的元素为0。

将该语音输入到Transformer中,输出的同样也是一个6*5000的矩阵,但是输出矩阵的中的元素分布则不会像训练集中显示的这样,刚开始会是一个随机的分布。
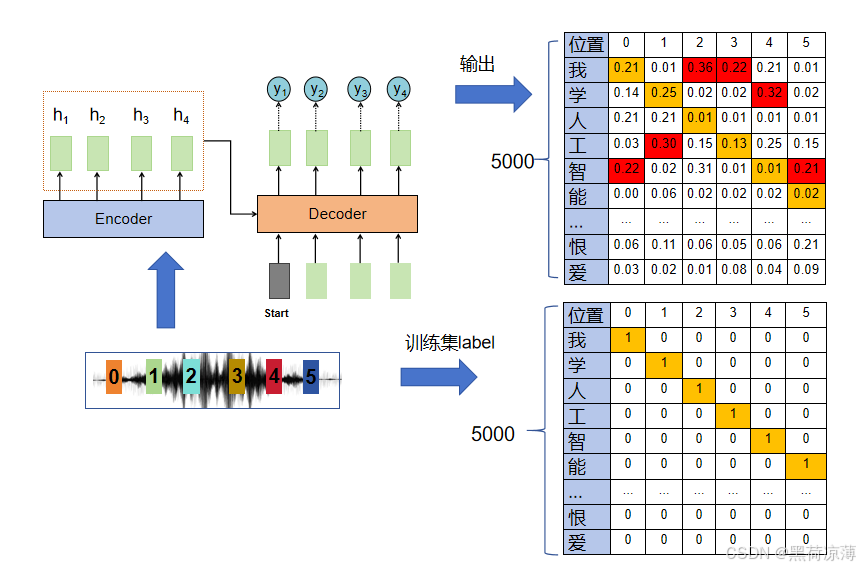
在训练的过程中,Transformer的Softmax输出的矩阵概率分布应该与训练集中的矩阵越接近越好,为了让输出的概率分布向训练集中的向量靠近,Transformer的损失函数就是对于输出的每一个位置的向量,与训练集相对应的向量求Cross entropy(交叉熵)。
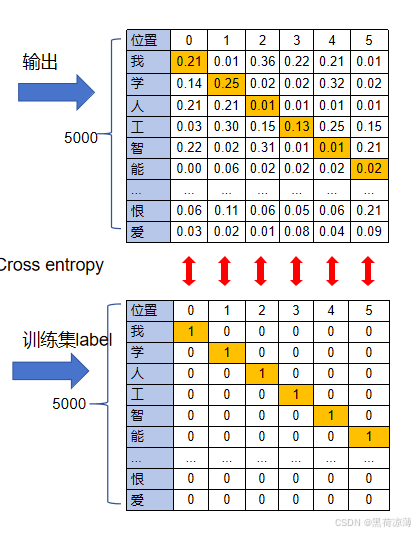
训练的过程其实就是Minimize Cross entropy,就是训练时通过Gradient descent(梯度下降法)不断地更新Transformer里面不同的权重矩阵,偏置项等,直至所有的Cross entropy全部加起来最小,就算训练成功。
当然,训练成功之后也不可能输出结果与训练集中的矩阵一模一样,只有目标文字的概率为1,其他为零。而是目标文字的是词汇集中概率最大的一项。
Transformer的Testing:
而测试(或称为评估)是评估已经训练好的模型在新数据上表现的过程,因为是评估,所以测试时会计算模型的各种性能指标,但是不会根据这些性能指标对模型的参数进行更新,但是可以根据测试得到的指标挑选训练时得到的在测试集上表现更好的模型。
其功能和过程主要包括以下几个方面:
1、验证模型泛化能力:
功能:测试的主要功能是评估模型在未见过的数据(测试集)上的表现,以验证模型的泛化能力。泛化能力指的是模型在新数据上的预测或分类能力,而不仅仅是在训练数据上的表现。
过程:通过将测试集输入到训练好的模型中,得到模型在测试集上的预测结果。然后,可以计算模型的各种性能指标(如准确度、精确度、召回率、F1分数等)来评估模型的整体表现。
2、检测和解决过拟合问题:
功能:测试还可以帮助检测模型是否出现过拟合问题。过拟合是指模型在训练集上表现非常好,但在新数据上表现较差的情况。通过测试集评估模型,可以发现模型是否过度拟合了训练数据,从而采取措施来改进模型的泛化能力。
过程:通过比较模型在训练集和测试集上的表现,可以判断模型是否存在过拟合现象。如果模型在训练集上表现非常好,但在测试集上表现差异较大,很可能是过拟合问题。
3、优化和调整模型:
功能:测试的结果可以指导优化和调整模型的过程,以提高模型的预测性能和实用性。
过程:根据测试集的评估结果,可以分析模型在不同数据上的表现差异,并据此调整模型的超参数、选择不同的特征工程方法或者改进算法,从而改善模型的整体性能。
4、决策支持:
功能:测试结果还可以为实际决策提供支持和依据。在机器学习应用中,模型的预测能力直接影响业务或科学问题的解决方案,测试评估提供的性能指标可以帮助决策者了解模型是否可以在实际环境中部署和使用。
过程:基于测试集的评估结果,可以对模型的预测能力进行客观评估,从而决定是否将模型投入实际应用,并对其预测结果的可靠性进行估计。
总结来说,测试在机器学习中是评估模型在新数据上表现的重要步骤,其过程不仅帮助评估模型的泛化能力和预测性能,还能指导优化模型和进行实际决策。
Training和Testing的注意点:
论文:Sequence to Sequence Learning with Neural Networks
[4]Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. "Sequence to sequence learning with neural networks." Advances in neural information processing systems 27 (2014).
论文:Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks
[5]Bengio, Samy, et al. "Scheduled sampling for sequence prediction with recurrent neural networks." Advances in neural information processing systems 28 (2015).
首先我们知道Training时模型是可以看到输入对应的lable的,在训练的时候,模型刚开始训练或者还没有训练好时,输出的每一个向量的元素不一定是在目标的文字概率最高,那么输出的结果就不是是正确的。
但是我们知道,Decoder的输入一部分是来自Encoder的输出,还有一部分应该来自Decoder的输出。当前一个时间步输出正确的时候,下一个输出正确的概率当然才会更高。
但是输出刚开始肯定不会是刚好完全正确的,一个输出错误,就可能会出现一步错,步步错的情况。
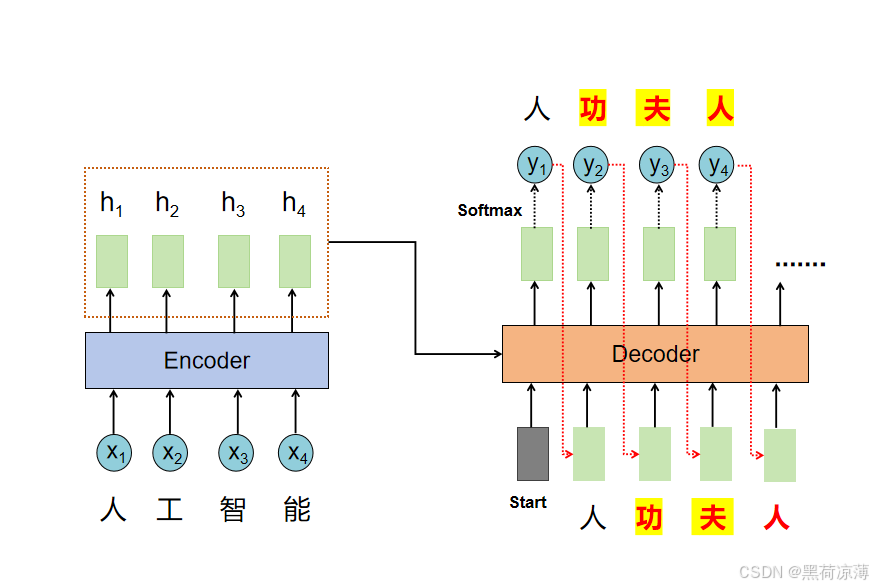
所以在Transformer里,训练是Decoder的输入是会“偷看”训练集中label的,不管Decoder的输出是什么,Decoder都会将正确结果输入,以便在训练中实施Gradient descent。这种方法其实就是Teacher Forcing(翻译为教师强迫。。。)机制。
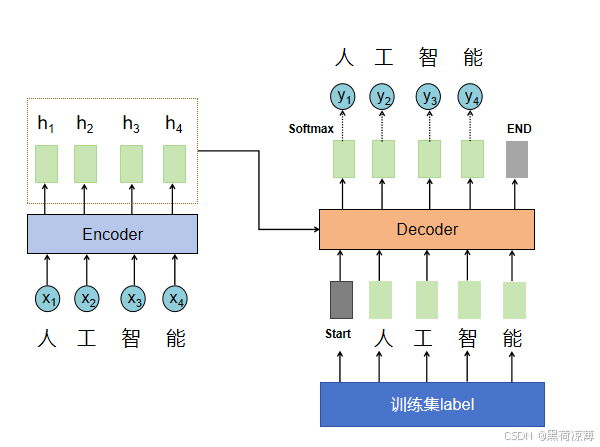
而Testing时则是按照正常的Decoder进行,以前一时间步的输出作为Decoder的输入,一步步获得Decoder的输出。
这时候就会有人想啊,既然训练的时候是以正确答案进行训练的,那如果当Testing时Decoder输出一个错误的,那肯定下一个时间步的输出就肯定是错误的,为了应对这个情况,一个比较简便的方法就是在训练资料中故意添加一些“错误”的资料,让模型学习到当Decoder的输入有错误讯息时,输出仍然是正确的。这其实就是Scheduled Sampling(计划抽样)的思想。
比如,“人工智能”的语音信号所对应的训练集的label就是“人功智能”,训练完毕之后,在Testing时输出“功”并当做Decoder的输入时,由于Training时已经训练好了训练集输入“功”时,下一个输出为“智”,所以在Testing时也会输出“智”,后面的自然也不会出错。
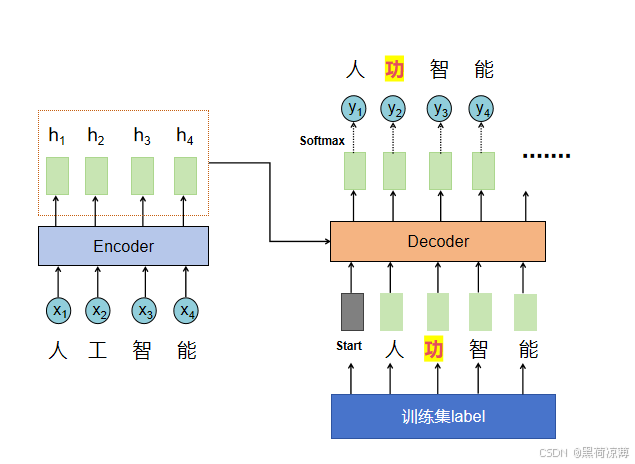
这与我们平时的观念可能有所不同,在训练集中故意添加一些错误的讯息,反而可能会对测试时的表现有帮助。
相关参考链接:2021 - Transformer (下)_哔哩哔哩_bilibili
七、总结
本篇文章基本上将Ttransformr的大部分内容都讲了,总体而言,Transformer 模型通过引入自注意力机制和多头注意力机制,摆脱了传统循环神经网络中固有的序列依赖问题,使得模型在处理长距离依赖和大规模数据集时表现更为出色,成为自然语言处理和序列到序列学习的重要里程碑。
Transformer涉及内容较多,而且前后有很多关联的地方,加上笔者查阅了很多不同类型的相关资料,本文的逻辑结构不是非常清晰,文中的图部分是自己在PPT上面画的,部分是从论文或者李宏毅老师的视频里面截图得到。 公式都是MathType上手打的,想把这个公式分享出来,但是没找到csdn上发布文件的地方。文中如果有什么讲述不清晰,遗漏,错误的地方,请大家不吝指正。
八、后续
后续可能文章的计划安排:
CNN、Mamba、loss function、Gan(没有顺序,学到哪里介绍到哪里);
语音领域相关基础知识;
还可能会分享一些电路方面的内容。
敬请期待!