
本文
1.C/C++内存分布2.C语言中动态内存管理方式:malloc/calloc/realloc/free总结 3.C++内存管理方式new/delete操作内置类型new和delete操作自定义类型 4.operator new与operator delete函数(重要点进行讲解)5.new和delete的实现原理内置类型自定义类型 6.定位new表达式(placement-new) (了解)7.malloc/free和new/delete的区别8.泛型编程9.函数模版模版概念函数模版格式模版的原理函数模板的实例化隐式实例化显示实例化模版参数的匹配规则 10.类模版11.什么是STL12.STL的版本13.STL的六大组件14.STL的重要性15.如何学习STL
1.C/C++内存分布
栈又叫堆栈–非静态局部变量/函数参数/返回值等等,栈是向下增长的。
内存映射段是高效的I/O映射方式,用于装载一个共享的动态内存库。用户可使用系统接口创建共享共享内存,做进程间通信。(Linux课程如果没学到这块,现在只需要了解一下)
堆用于程序运行时动态内存分配,堆是可以上增长的。
数据段–存储全局数据和静态数据。
代码段–可执行的代码/只读常量

int globalVar = 1;static int staticGlobalVar = 1;void Test(){static int staticVar = 1;int localVar = 1;int num1[10] = { 1, 2, 3, 4 };char char2[] = "abcd";const char* pChar3 = "abcd";int* ptr1 = (int*)malloc(sizeof(int) * 4);int* ptr2 = (int*)calloc(4, sizeof(int));int* ptr3 = (int*)realloc(ptr2, sizeof(int) * 4);free(ptr1);free(ptr3);}/*. 选择题:选项: A.栈 B.堆 C.数据段(静态区) D.代码段(常量区)globalVar在哪里?__c__staticGlobalVar在哪里?__c__staticVar在哪里?__c__localVar在哪里?__a__num1 在哪里?___a_char2在哪里?___a_*char2在哪里?_a__pChar3在哪里?__a__*pChar3在哪里?__*pChar3指向的是abcd,abcd在常量区 D__ptr1在哪里?__a__*ptr1在哪里?__b__//malloc在堆上*//*全局数据和静态数据都在静态区局部静态变量也是存在于静态区的*/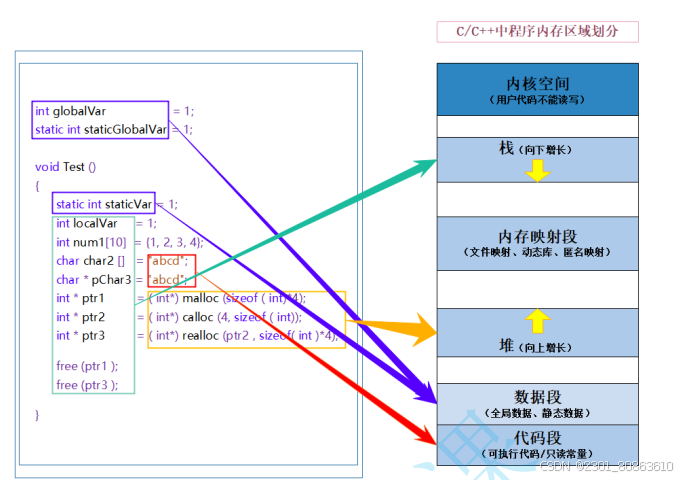
2.C语言中动态内存管理方式:malloc/calloc/realloc/free
calloc会将开辟的空间初始化为0
void Test (){// 1.malloc/calloc/realloc的区别是什么?int* p2 = (int*)calloc(4, sizeof (int));int* p3 = (int*)realloc(p2, sizeof(int)*10);// 这里需要free(p2)吗?free(p3 );}malloc、calloc 和 realloc 是 C 语言中用于动态内存分配的函数。它们的区别主要在于如何分配内存、初始化内存和调整已分配内存的大小。以下是它们的具体区别:
malloc: 全称:Memory Allocation
功能:分配指定字节大小的内存块,但不初始化内存。
使用方式:void* malloc(size_t size);
返回值:返回指向分配内存块的指针,如果分配失败,返回 NULL。
特点:分配的内存内容是未定义的,可能包含垃圾值。
calloc: 全称:Contiguous Allocation
功能:分配一定数量的内存块,并将其初始化为零。
使用方式:void* calloc(size_t num, size_t size);
返回值:返回指向分配内存块的指针,如果分配失败,返回 NULL。
特点:分配的内存是连续的,且所有位都被初始化为零。
realloc: 全称:Reallocation
功能:重新调整已分配内存的大小。可以扩展或缩小原有的内存块。
使用方式:void* realloc(void* ptr, size_t size);
返回值:返回指向重新分配内存块的指针,如果重新分配失败,返回 NULL,并且原来的内存块保持不变。
特点:如果扩大内存块,可能会移动到新的地址,并将原来的数据复制到新地址。缩小内存块则可能保留在原地址。
总结
使用 malloc 时,内存内容是未初始化的;
使用 calloc 时,内存内容会被初始化为零;
使用 realloc 可以调整已分配内存的大小,可以根据需要扩展或缩小。
3.C++内存管理方式
new/delete操作内置类型
C语言内存管理方式在C++中可以继续使用,但有些地方就无能为力,而且使用起来比较麻烦,因此C++又提出了自己的内存管理方式:通过new和delete操作符进行动态内存管理。
new在C++里面是个操作符/运算符
如果想申请一个整数,就直接new int
如果想初始化的话,这么写 new int(3)
如果想new多个int的话,后面跟方括号
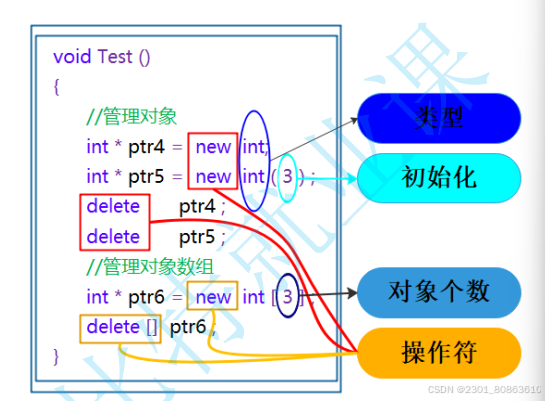
void Test(){// 动态申请一个int类型的空间int* ptr4 = new int;// 动态申请一个int类型的空间并初始化为10int* ptr5 = new int(10);// 动态申请10个int类型的空间int* ptr6 = new int[3];//如果是多个数组中的对象要初始化的话int* ptr7 = new int[3] {1, 2, 3};delete ptr4;delete ptr5;delete[] ptr6;}
new和delete操作自定义类型
注意:申请和释放单个元素的空间,使用new和delete操作符,申请和释放连续的空间,使用new[]和delete[],注意:匹配起来使用。
内置类型用malloc还是new都是可以的,但是自定义类型就不一样了
自定义类型推荐使用new
malloc只会申请空间,但是new不仅会申请空间,还会调用构造函数
free只会释放空间,但是delete不仅会释放空间还可以调用析构函数
class A{public:A(int a = 0): _a(a){cout << "A():" << this << endl;}~A(){cout << "~A():" << this << endl;}private:int _a;};struct ListNode//链表{int _val;ListNode* _next;ListNode(int val):_val(val), _next(nullptr){}};int main(){//只申请空间A* p1 = (A*)malloc(sizeof(A));//用new就方便很多了//申请空间+构造函数A* p2 = new A(1);//只释放空间free(p1);//释放空间+析构函数delete p2;A* p6 = new A[10];//申请10个对象的空间//回调用10次构造函数delete[] p6;A aa1(1);A aa2(1);//A* p7 = new A[10]{ aa1,aa2 };A* p7 = new A[10] {1,2,3};//直接使用隐式类型转换delete[] p7; //在C语言的链表中我们通常需要写个buynode来申请一个节点//但是我们在C++中就不用了,我们直接new就行了ListNode* n1 = new ListNode(1);//申请空间并且调用ListNode的构造函数ListNode* n2 = new ListNode(2);ListNode* n3 = new ListNode(3);ListNode* n4 = new ListNode(4);n1->_next = n2;n2->_next = n3;n3->_next = n4;return 0;}//在一个类中一定要提供默认构造,不然就会出现很多的问题了我们通过C++进行链表节点申请的时候我们可以直接通过new来进行申请空间和调用构造函数
就不用像c语言那样来写个函数进行节点的申请和初始化操作了
4.operator new与operator delete函数(重要点进行讲解)
new和delete是用户进行动态内存申请和释放的操作符,operator new 和operator delete是系统提供的全局函数,new在底层调用operator new全局函数来申请空间,delete在底层通过operator delete全局函数来释放空间
operator new实际上是对malloc的一个封装
malloc失败之后返回一个空指针
operator new申请失败后会抛异常

operator new底层封装malloc
operator delete是和operator new进行配对的
通过上述两个全局函数的实现知道,operator new 实际也是通过malloc来申请空间,如果malloc申请空间成功就直接返回,否则执行用户提供的空间不足应对措施,如果用户提供该措施就继续申请,否则就抛异常。operator delete 最终是通过free来释放空间的。
5.new和delete的实现原理
内置类型
如果申请的是内置类型的空间,new和malloc,delete和free基本类似,不同的地方是: new/delete申请和释放的是单个元素的空间,new[]和delete[]申请的是连续空间,而且new在申请空间失败时会抛异常,malloc会返回NULL。
自定义类型
•new的原理
调用operator new函数申请空间
在申请的空间上执行构造函数,完成对象的构造
•delete的原理
在空间上执行析构函数,完成对象中资源的清理工作
调用operator delete函数释放对象的空间
•new T[N]的原理
调用operator new[]函数,在operator new[]中实际调用operator new函数完成N个对象空间的申请
在申请的空间上执行N次构造函数
•delete[]的原理
在释放的对象空间上执行N次析构函数,完成N个对象中资源的清理
调用operator delete[]释放空间,实际在operator delete[]中调用operator delete来释放空间

直接这样写,operator new和malloc的区别就是operator new失败了会抛异常,没有返回值
但这个不会调用构造函数,用法和malloc相似的
6.定位new表达式(placement-new) (了解)
定位new表达式是在已分配的原始内存空间中调用构造函数初始化一个对象
用格式:new (place_address) type或者new (place_address) type(initializer-list)
place_address必须是一个指针,initializer-list是类型的初始化列表
使用场景:定位new表达式在实际中一般是配合内存池使用。因为内存池分配出的内存没有初始化,所以如果是自定义类型的对象,需要使用new的定义表达式进行显示调构造函数进行初始化。
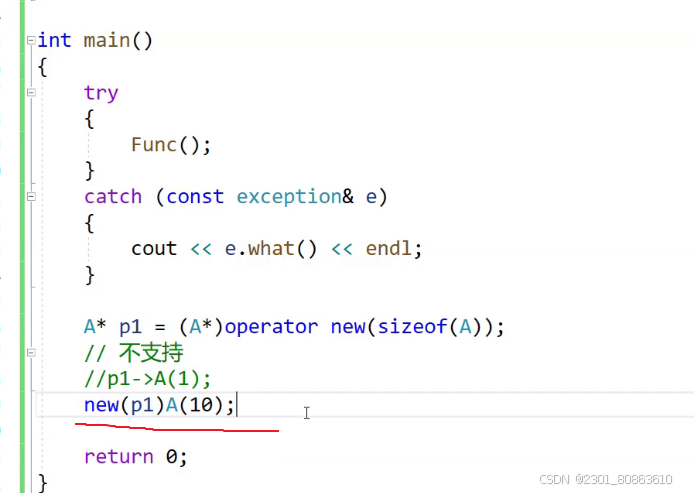
对p1指向的那块空间调用构造函数进行初始化操作
构造函数不支持显示调用,析构函数支持显示调用的
不要忘记释放,不要交错释放
7.malloc/free和new/delete的区别
malloc/free和new/delete的共同点是:都是从堆上申请空间,并且需要用户手动释放。不同的地方是:
malloc和free是函数,new和delete是操作符
malloc申请的空间不会初始化,new可以初始化
malloc申请空间时,需要手动计算空间大小并传递,new只需在其后跟上空间的类型即可,如果是多个对象,[]中指定对象个数即可
malloc的返回值为void*, 在使用时必须强转,new不需要,因为new后跟的是空间的类型
malloc申请空间失败时,返回的是NULL,因此使用时必须判空,new不需要,但是new需要捕获异常
申请自定义类型对象时,malloc/free只会开辟空间,不会调用构造函数与析构函数,而new在申请空间后会调用构造函数完成对象的初始化,delete在释放空间前会调用析构函数完成空间中资源的清理释放
在项目中使用new我们是需要进行异常的捕获操作的
malloc需要强制转换,当时new是不需要强转的
8.泛型编程
//C++支持函数重载,允许函数名重复void Swap(int& left, int& right){int temp = left;left = right;right = temp;} void Swap(double& left, double& right){double temp = left;left = right;right = temp;} void Swap(char& left, char& right){char temp = left;left = right;right = temp;}使用函数重载虽然可以实现,但是有一下几个不好的地方:1. 重载的函数仅仅是类型不同,代码复用率比较低,只要有新类型出现时,就需要用户自己增加对应的函数2. 代码的可维护性比较低,一个出错可能所有的重载均出错
9.函数模版
模版概念
函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参类型产生函数的特定类型版本。
函数模版格式
template<typename T1, typename T2,…,typename Tn>返回值类型 函数名(参数列表){}
template英文翻译就是模版的意思
下面是一个交换函数的模版,可以对不同的类型进行一个交换的操作
template<typename T>void Swap(T& left, T& right)//针对广泛的类型{T temp = left;left = right;right = temp;}int main(){int x = 0, y = 1;double m = 1.1, n = 2.2;//通过模版就很方便了//调用的其实还是两个函数Swap(x, y);Swap(m, n);return 0;}语法上面我们需要声明这个模版参数的类型template
模版的原理
函数模板是一个蓝图,它本身并不是函数,是编译器用使用方式产生特定具体类型函数的模具。所以其实模板就是将本来应该我们做的重复的事情交给了编译器,编译器成牛马了
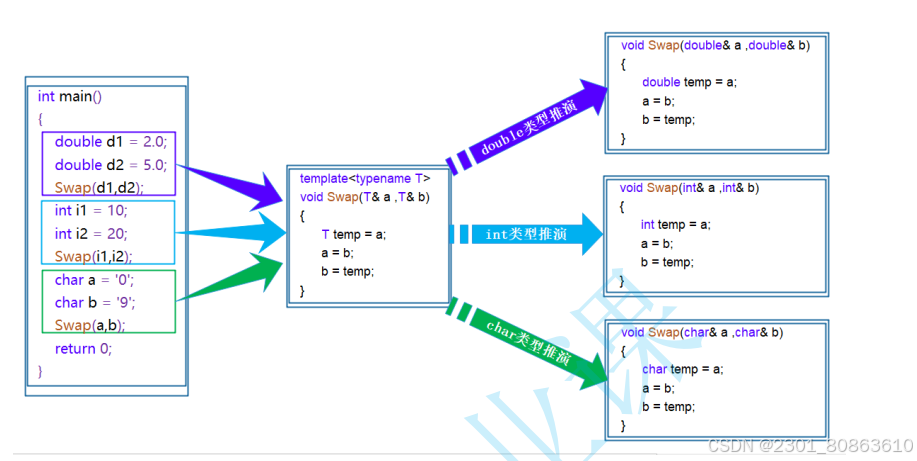
在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应类型的函数以供调用。比如:当用double类型使用函数模板时,编译器通过对实参类型的推演,将T确定为double类型,然后产生一份专门处理double类型的代码,对于字符类型也是如此。
函数模板的实例化
编译器通过模版生成对应的函数叫做实例化操作
实例化分为两种,一种叫做隐式实例化,一种叫做显式实例化
如果我们传的是两个类型不一样的数据的话是会报错的
,但是我们可以通过增加多个模版参数来进行不同类型数据的交换的
隐式实例化
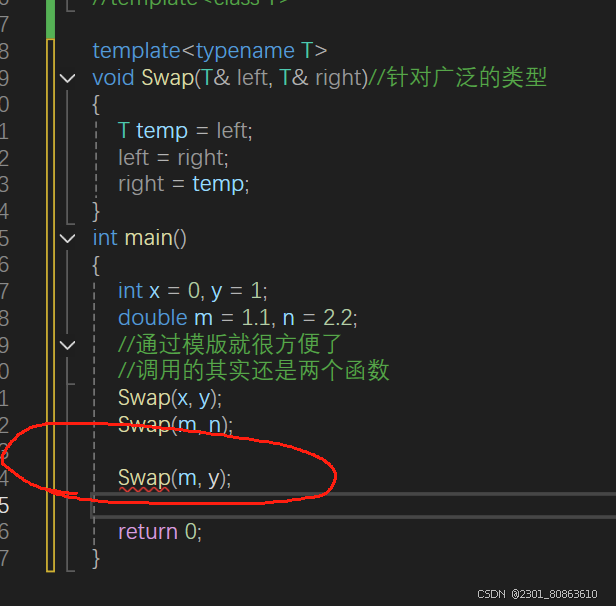

template<typename T>//传递的是类型void Swap(T& left, T& right)//定义的是对象{T temp = left;left = right;right = temp;}template<class T1, class T2>//传递的是类型void Swap(T1& left, T2& right)//定义的是对象{T temp = left;left = right;right = temp;}int main(){int x = 0, y = 1;double m = 1.1, n = 2.2;//通过模版就很方便了//调用的其实还是两个函数Swap(x, y);Swap(m, n);Swap(m, y);return 0;}//这两个实例化生成的函数构成重载了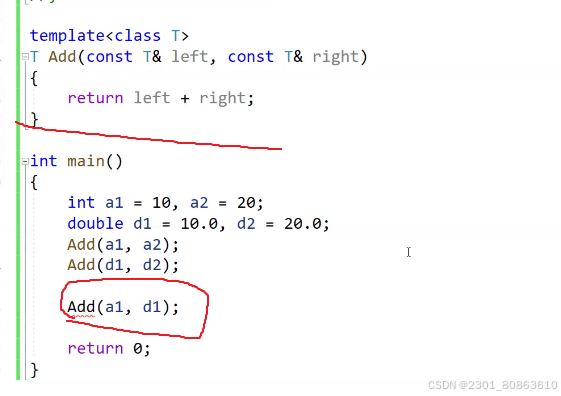
像这种的话,我们如果传的是两种类型的数据的话,按照这个模版来,编译器是会报错的
但是我们是可以通过这个两个模版来解决这个问题的
还有一个方法,可以在传数据的时候将其中一个数据进行强制转换的操作
template<class T>T Add(const T& left, const T& right){return left + right;}int main(){int a1 = 10, a2 = 20;double d1 = 10.1, d2 = 20.1;Add(a1, a2);Add(d1, d2);cout << Add(a1, (int)d1)<< endl;//20cout << Add((double)a1,d1)<< endl;//20.1return 0;}显示实例化
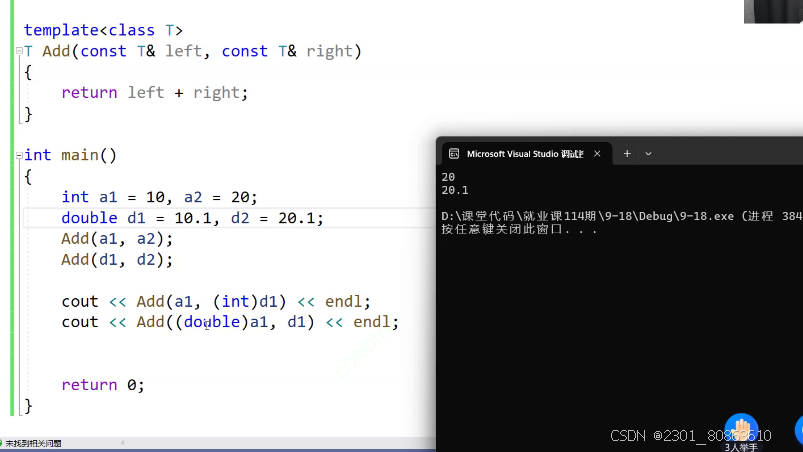
在函数名和函数参数中间加上尖括号,括号之内写上要转换的类型
template<class T>T Add(const T& left, const T& right){return left + right;}int main(){int a1 = 10, a2 = 20;double d1 = 10.1, d2 = 20.1;//自动推导类型 隐式实例化Add(a1, a2);Add(d1, d2);cout << Add(a1, (int)d1)<< endl;//20cout << Add((double)a1,d1)<< endl;//20.1//在函数名和参数列表中间加上尖括号//这个叫做显示实例化cout << Add<int>(a1,d1) << endl;//20cout << Add<double>(a1, d1) << endl;//20.1return 0;}隐式实例化就是编译器进行一个自动推导,查看里面的数据类型
但是我们的显示实例化操作,我们直接显示的写出了我们要参与的数据的类型是什么

我们不知道传的类型是什么参数,对于这种的话我们就可以在传参的时候进行显式实例化操作了
编译器推不出来我们的数据是什么类型的,所以我们要显示的写出来这个参数的类型
如果模版函数和普通函数都存在的话我们是直接选择使用这个普通函数的,因为模版的话我们的编译器还要去推导这个T的类型,很麻烦,我们直接用普通的就行了
int Add(int left, int right){return left + right;}template<class T>T Add(const T& left, const T& right){return left + right;}int main(){Add(1, 2);return 0;}//我们这里有两个Add函数,那么调用的时候会先调用谁呢?//模版和普通函数是可以同时存在的,但是我们是不知道会调用哪一个函数//用模版其实比用普通函数更加麻烦的,因为编译器是需要对T进行一个推导的过程的//有现成的就用现成的,就用普通函数模版参数的匹配规则
1.一个非模板函数可以和一个同名的函数模板同时存在,而且该函数模板还可以被实例化为这个非模板函数
2.对于非模板函数和同名函数模板,如果其他条件都相同,在调动时会优先调用非模板函数而不会从该模板产生出一个实例。如果模板可以产生一个具有更好匹配的函数, 那么将选择模板
模板函数不允许自动类型转换,但普通函数可以进行自动类型转换不同类型调用不同的函数或者模版
int Add(int left, int right){return left + right;}template<class T>T Add(const T& left, const T& right){return (left + right)*5;}template<class T1,class T2>T1 Add( T1 left, T2 right){return (left + right) * 10;}int main(){cout << Add(1, 2) << endl;//调用普通函数//现在我们不想调用这个普通函数,我们想调用模版我们怎么解决呢?//我们显示实例化一下就行了//我们在这里显示实例化了,就是指明了编译器一定要使用模版cout << Add<int>(1, 2) << endl;//调用第一个模版cout << Add(1, 2) << endl;//调用第一个模版cout << Add(1, 2.2) << endl;//调用第二个模版return 0;}对于我们这里使用的Swap这个交换例子,我们以后直接使用swap进行交换操作,这个函数是已经在库里面存在了
10.类模版
template<class T1, class T2>class 类模板名{// 类内成员定义};#include<iostream>using namespace std;using STDataType = int;// 类模版//template<typename T>class Stack{public :Stack(size_t capacity = 4){_array = new STDataType[capacity];_capacity = capacity;_size = 0;} private:STDataType* _array;size_t _capacity;size_t _size;};int main(){//现在我们想往两个栈分别存入不同类型的数据//如果使用我们的这个using STDataType = int;是不能解决问题的Stack st1;//存intStack st2;//存doublereturn 0;}using STDataType = int;还是不能解决同时处理不同类型的数据的
还是得使用到我们的模版了
实例化生成对应的类,这里是两个不同的类型
// 类模版template<typename T>class Stack{public:Stack(size_t capacity = 4){_array = new T[capacity];_capacity = capacity;_size = 0;}private:T* _array;size_t _capacity;size_t _size;};int main(){//现在我们想往两个栈分别存入不同类型的数据//如果使用我们的这个using STDataType = int;是不能解决问题的//我们的类模版是不能隐式实例化操作的//只能显示实例化操作//实例化生成对应的类,这里是两个不同的类型Stack<int> st1;//存intStack<double> st2;//存doublereturn 0;}模版不建议声明和定义分离到两个文件.h 和.cpp会出现链接错误
只有在类里面我们才能使用这个T,出了这个类就不作数了
所以声明和定义不能分离
声明和定义分离的写法错误写法:
// 类模版template<typename T>class Stack{public:Stack(size_t capacity = 4){_array = new T[capacity];_capacity = capacity;_size = 0;}void Push(const T& data);private:T* _array;size_t _capacity;size_t _size;};void Stack::Push(const T& data){// 扩容_array[_size] = data;++_size;}声明和定义分离的写法正确写法:
// 类模版template<typename T>class Stack{public:Stack(size_t capacity = 4){_array = new T[capacity];_capacity = capacity;_size = 0;}void Push(const T& data);private:T* _array;size_t _capacity;size_t _size;};template<typename T>void Stack<T>::Push(const T& data){// 扩容_array[_size] = data;++_size;}要制定类域和类名
类模板实例化与函数模板实例化不同,类模板实例化需要在类模板名字后跟<>,然后将实例化的类型放在<>中即可,类模板名字不是真正的类,而实例化的结果才是真正的类
Stack是类名,Stack才是类型
// Stack是类名,Stack<int>才是类型Stack<int> st1; // intStack<double> st2; // double11.什么是STL
STL(standard template libaray-标准模板库):是C++标准库的重要组成部分,不仅是一个可复用的组件库,而且是一个包罗数据结构与算法的软件框架。
12.STL的版本
原始版本
Alexander Stepanov、Meng Lee 在惠普实验室完成的原始版本,本着开源精神,他们声明允许任何人任意运用、拷贝、修改、传播、商业使用这些代码,无需付费。唯一的条件就是也需要向原始版本一样做开源使用。 HP 版本–所有STL实现版本的始祖。
P. J. 版本
由P. J. Plauger开发,继承自HP版本,被Windows Visual C++采用,不能公开或修改,缺陷:可读性比较低,符号命名比较怪异。
RW版本
由Rouge Wage公司开发,继承自HP版本,被C+ + Builder 采用,不能公开或修改,可读性一般。
SGI版本
由Silicon Graphics Computer Systems,Inc公司开发,继承自HP版 本。被GCC(Linux)采用,可移植性好,可公开、修改甚至贩卖,从命名风格和编程 风格上看,阅读性非常高。我们后面学习STL要阅读部分源代码,主要参考的就是这个版本
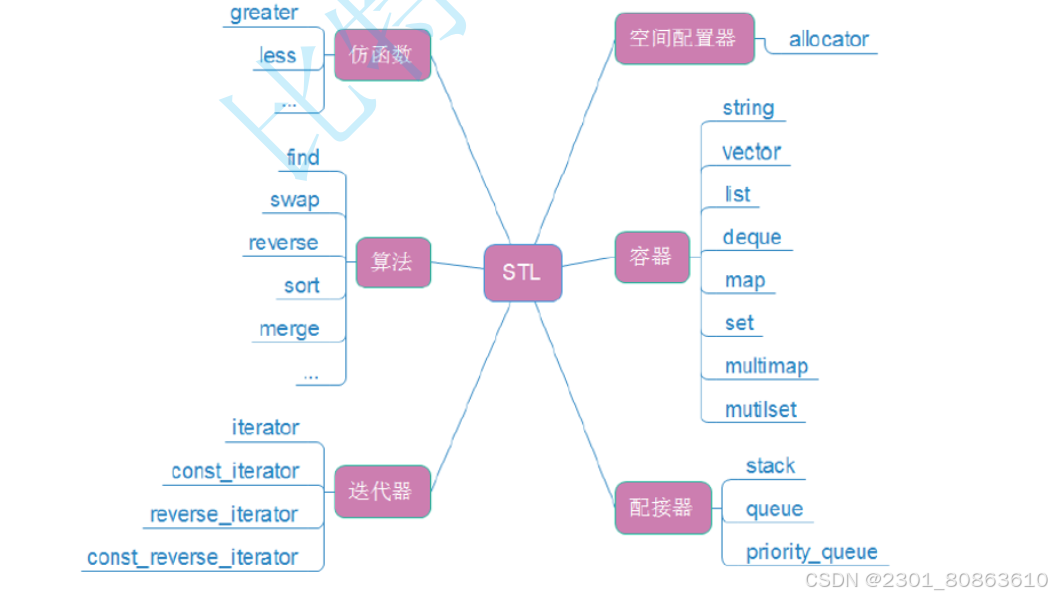
13.STL的六大组件
14.STL的重要性

15.如何学习STL
