数据结构其他章节
数据结构(C语言描述)——认识树-CSDN博客
数据结构(C语言描述)——初识二叉树-CSDN博客
前言
上一篇文章中,我们了解到二叉树一般有两种存储方式,一种顺序存储,一种链式存储。在本文中我们将学习堆,也就是二叉树按顺序存储实现的一种结构。
一,堆的概念
1.1概念
如果有一个关键码的集合K = { 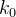 ,
, 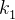 ,
,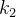 ,…,
,…,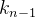 },把它的所有元素按完全二叉树的顺序存储方式存储在一个一维数组中,并满足:
},把它的所有元素按完全二叉树的顺序存储方式存储在一个一维数组中,并满足: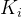 <=
<= 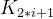 且
且 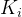 <=
<=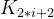 (
(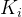 >=
>= 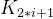 且
且 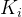 >=
>= 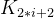 ) i = 0,1,2…,则称为小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
) i = 0,1,2…,则称为小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
简而言之,大/小堆就是一个顺序存储的完全二叉树,在这颗树中任一父亲节点所存储的数据都大于/小于或者等于其两个子节点。
堆的性质如下:
1,堆中某个节点的值总是不大于或不小于其父节点的值;
2,堆总是一棵完全二叉树。
二,堆的结构
堆在逻辑结构上是以完全二叉树的形式呈现,在存储结构,也就是物理结构上是以数组的方式存储。

三,堆的代码实现
堆的存储方式是顺序存储,其代码实现如下:(本文将以大堆为例,带着读者们一步一步进行代码实现,小堆的代码实现只需修改其中少量代码即可,笔者将不再重复实现小堆)
typedef int DataType;typedef struct Heap {DataType* a; //存储的数据int size; //有效数据个数int capacity;//总容量}HP;3.1初始化与销毁
3.1.1初始化
堆的代码实现肯定是从初始化开始
void HeapInit(HP* hp) {assert(hp); //断言,判断指针是否为空hp->a = NULL;hp->size = 0;hp->capacity = 0;}3.1.2销毁
既然有初始化,那肯定少不了销毁操作
void HeapDestory(HP* hp) {assert(hp); free(hp->a); //释放空间hp->a = NULL; //置空,避免出现野指针hp->capacity = hp->size = 0;}这两个函数的实现十分简单,唯一需要注意的就是不要忘记释放指针hp->a所指向的空间。
3.2插入与删除
3.2.1插入
紧接着就是大堆的插入函数的实现;我们知道,大堆中任一父亲节点都大于或等于它的两个子节点,那么我们该如何利用这一性质来实现插入呢?
上一篇文章中我们了解到,如果按根节点为第0个节点排序,那么第i个节点的左孩子节点就是2*i+1,它的右孩子节点是2*i+2;根据大堆的性质,我们只需要保证第i个节点始终大于等于第2*i+1和2*i+2个节点即可。
例如,对以下数据使用向上调整算法建堆
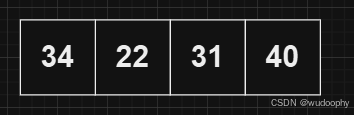
前三项数据入堆后满足堆的性质,但第四个数据不满足,这时需要进行向上调整
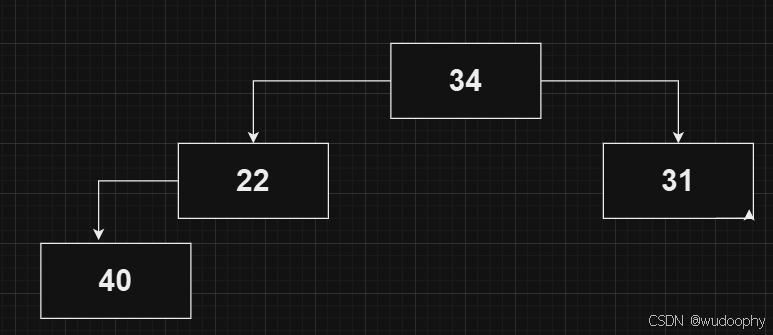
40>22,故进行数据交换,但交换后数据40所在的节点任大于其父亲节点,故继续向上调整
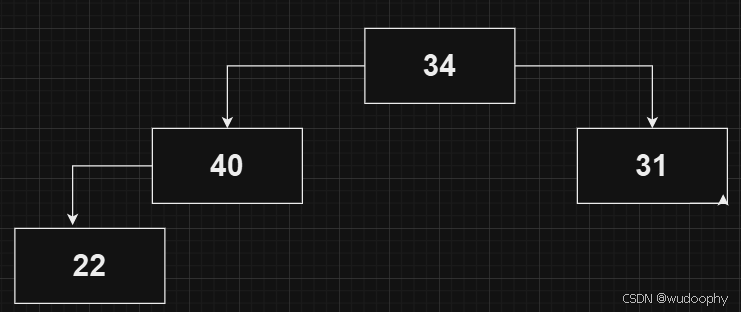
最后得到如下大堆:

代码实现如下:
void HeapPush(HP* hp, DataType x) {assert(hp);if (hp->capacity == hp->size) {int Newcapacity = hp->capacity == 0 ? 4 : hp->capacity * 2; //空则开辟空间,满则扩容DataType* aa = (DataType*)realloc(hp->a,Newcapacity * sizeof(DataType));if (aa==NULL) {perror("realloc fail");return;}hp->a = aa;hp->capacity = Newcapacity;} hp->a[hp->size] = x;hp->size++;AdjustUp(hp->a , hp->size-1); //向上调整}在上面的代码中大多都是基础操作,关键在于AdjustUp(hp->a , hp->size-1);这一函数的实现。
3.2.1.1堆向上调整算法
我们知道,第i个节点的的父亲节点就是第(i-1)/2个节点。
也就是说,我们在插入第i个数据时需要满足其小于等于第(i-1)/2个节点,如果不满足就将两个节点进行交换,然后在将这个节点与其父亲节点做相同的操作即可。代码实现如下:
void AdjustUp(DataType* pa, int site) {assert(pa);int parent = (site - 1) / 2;while (parent>=0 && pa[site] > pa[parent]) { //注意parent的值,不要造成越界访问DataType tmp = pa[site]; //当子节点大于父亲节点时就进行交换pa[site] = pa[parent];pa[parent] = tmp;site = parent; //数据交换parent = (site - 1) / 2;}return;}3.2.2删除
关于删除操作需要注意的是,堆的删除并非和顺序表,链表一样只是删除最后一个数据,而是删除处于堆顶的数据,在大堆中就是最大的那个数据。
但是,显然,我们不能直接删除位于堆顶的那个节点,不然剩下的结构就不能称之为堆了。所以堆的删除其实分为三步:先交换堆顶元素与堆的最后一个元素;然后size--;最后对堆顶的元素进行向下调整。
如下是一个大堆,现对它进行删除操作
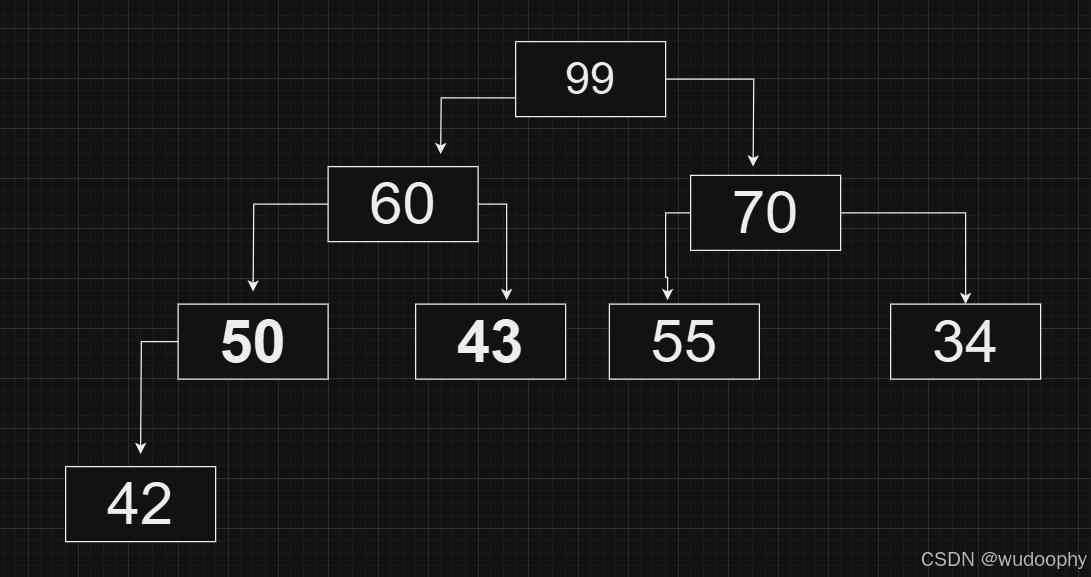
第一步首尾交换:

第二步有效数据减一:
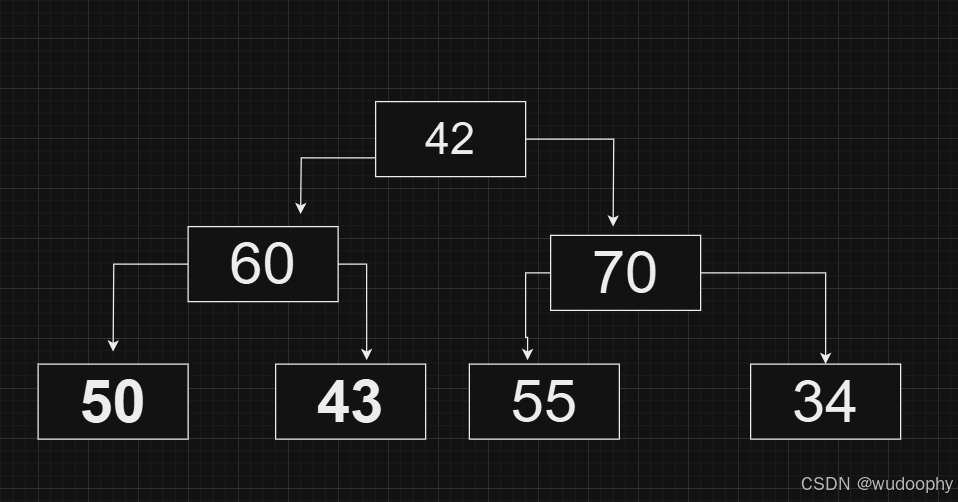
第三步对新的堆顶元素进行向下调整:(读者请看,下图的调整是否可行)
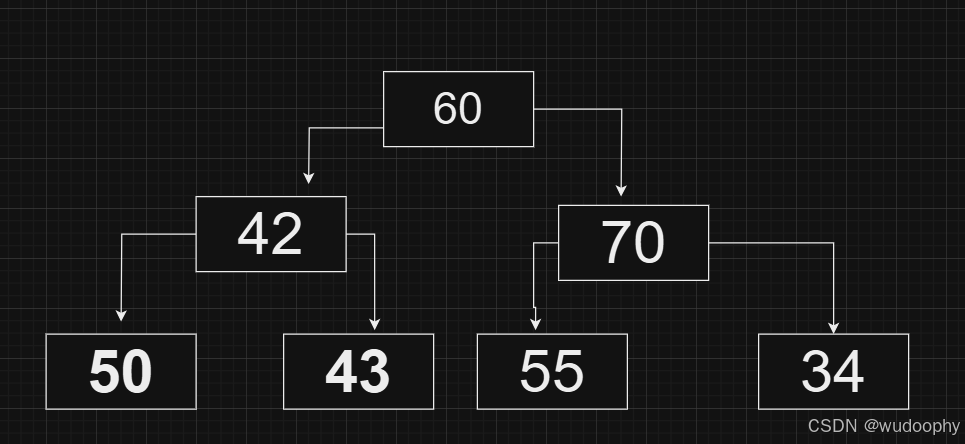
显然,上图的调整会导致堆顶的元素并非最大元素,故大堆进行向下调整时要与两个子节点中较大的那个进行交换,如下:
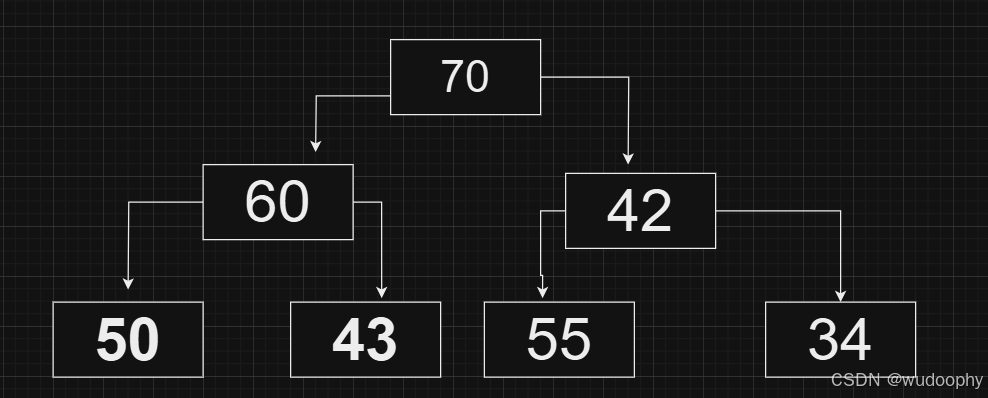
然后继续进行向下调整,直到满足大堆的性质
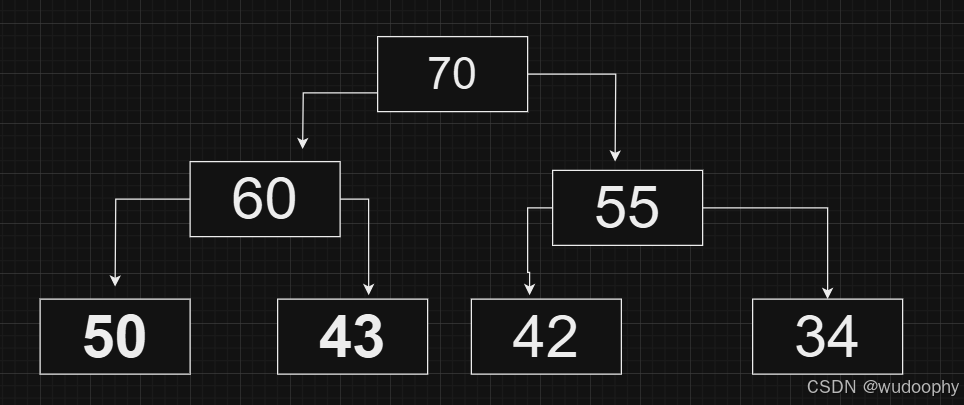
代码实现如下:
void HeapPop(HP* hp) {asssert(hp);int tmp = hp->a[0];hp->a[0] = hp->a[hp->size - 1];hp->a[hp->size - 1] = tmp; //交换数据hp->size--; //有效数据减一AdjustDown(hp->a, hp->size,0 ); //对堆顶数据向下调整}3.2.2.1堆向下调整算法
向下调整算法其实是堆中最重要的一个算法,它的应用场景十分广泛。
代码实现如下:
void AdjustDown(DataType* hp, int size,int parent) {assert(hp);int child = 0; //向下调整从堆顶开始,故parent=0即可child = parent * 2 + 1; //假定左孩子大于右孩子while (child < size) {if (child + 1 < size && hp[child + 1] > hp[child]) { //选出左右孩子中较大的那个child++;}if (hp[child] > hp[parent]) { //如果孩子节点大于父亲节点就交换DataType tmp = hp[child];hp[child] = hp[parent];hp[parent] = tmp;parent = child;child = parent * 2 + 1; //赋值,便于重复以上过程}elsebreak;}return;}向下调整算法的原理十分简单,但实现代码时要注意比较两个子节点的大小。
3.3其他常用操作
3.3.1堆元素个数
int HeapSize(HP* hp) {return hp->size;}3.3.2判空
判空只需判断size是否等于零就行。
bool HeapEmpty(HP* hp) {return hp->size == 0;}四,堆排序
4.1升序与降序问题
升序与降序问题十分常见,但是在堆排序中有一个十分重要的点需要注意,那就是:
升序:建大堆
降序:建小堆
有的读者可能会有疑惑,为什么升序要建大堆,大堆不是堆顶最大吗?那不应该是降序吗?这其实与我们堆排序的实现方式有关。
堆排序一般分为三步:建大堆;首尾交换并向下调整。其中后两步与堆的删除操作十分相似。文字解释可能不太清晰,所以笔者直接给大家看实操。
笔者给出如下数组,现对数组中的所有元素进行升序排序。
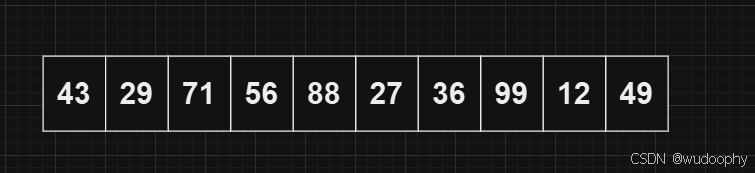
首先,这是如上数据所构成的二叉树,我们现在需要把这个二叉树变成一个大堆
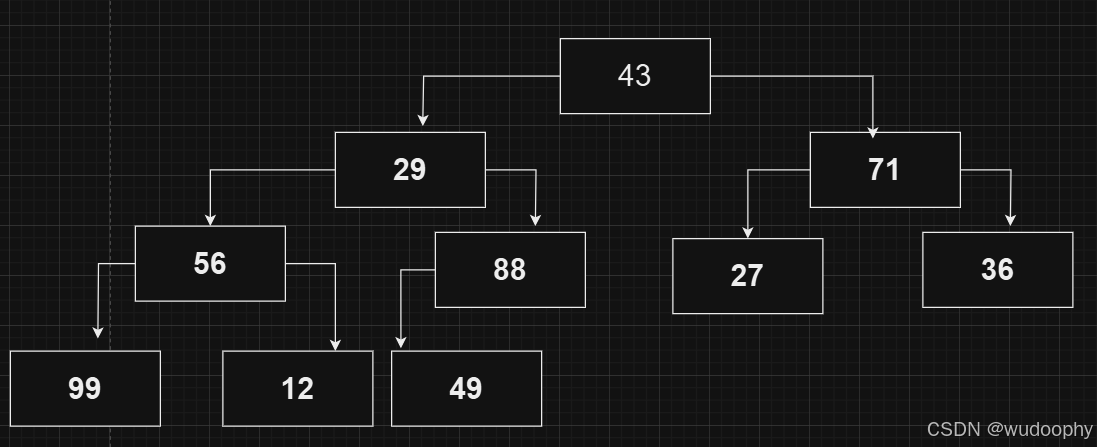
那么应该如何把这个二叉树变成大堆呢?上文中,我们学习了向上调整算法,这一算法是不是也能在这里使用呢?显然直接使用不可行,但是我们观察可以发现,如果我们从数据的第二位也就是根节点的左子树开始对除了根节点以外的每一个节点使用向上调整算法,那么是不是能构成大堆?是的,的确可以做到。
第一个节点满足大堆性质无需调整,第二个节点大于根节点,向上调整
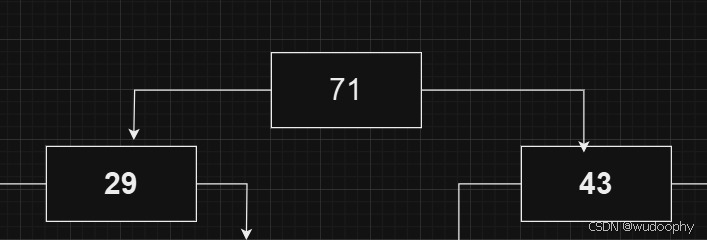
第三个节点大于其父亲节点,向上调整

第四个节点大于其父亲节点,向上调整
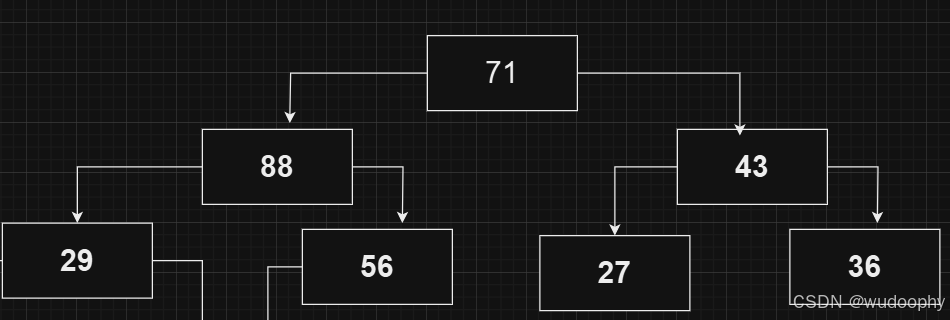
调整后仍大于其父亲节点,继续向上调整
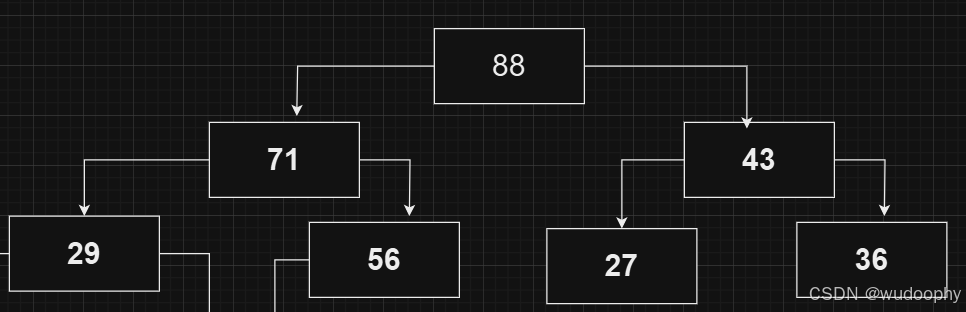
对所有节点进行向上调整后,逻辑结构如下:
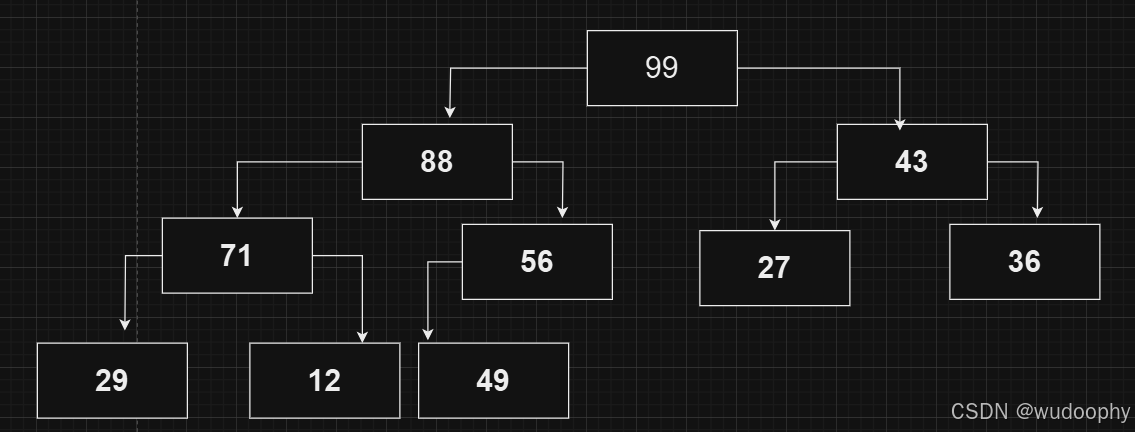
接下来进行第二步
首先是首尾交换
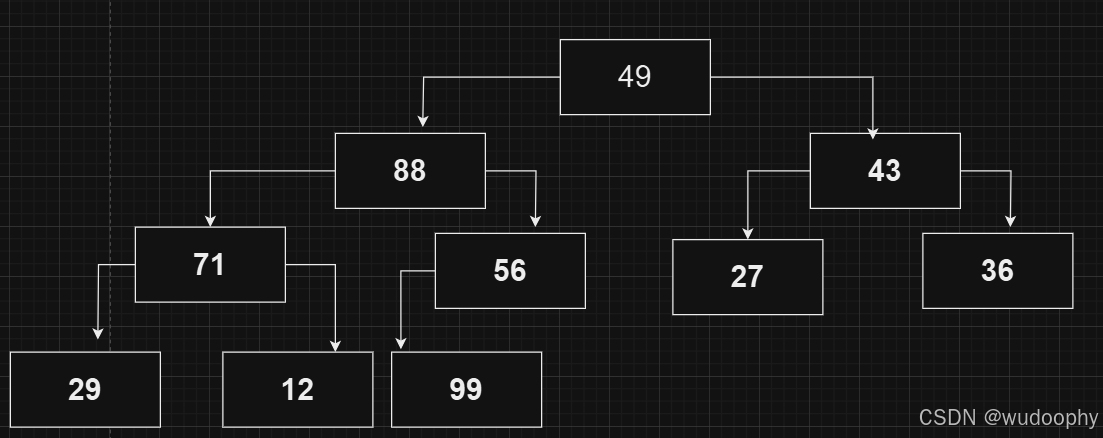
然后对新的根节点进行向下调整
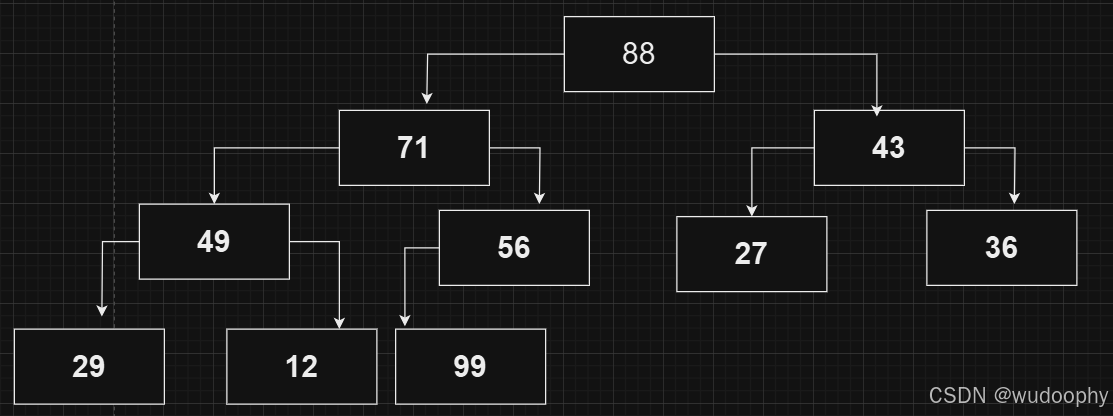
再然后,把最后一个节点“弹出”堆;这里的弹出是指让这个节点不再参与其他节点的向下调整,但仍存储在数组中。
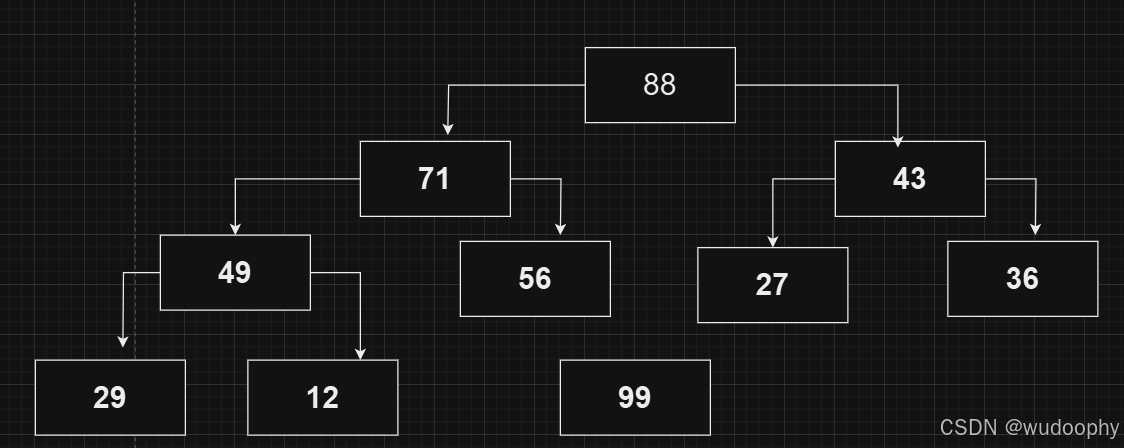
重复以上过程直至堆中仅有一个节点,就可以使原数组中的数据从小到大也就是升序排列。

对如下数据进行排序可得到下图效果
int main() {int a[] = { 12,34,32,53,17,8,93,40 };HeapSort(a, 8);return 0;}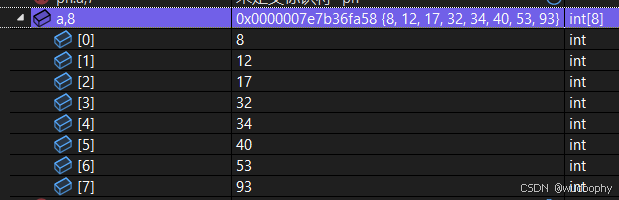
代码实现如下:
void HeapSort(int* arr,int size) {int tmp = 0;for (int i = 1; i < size; i++) {AdjustUp(arr, i); //向上调整}int end = size - 1;while (end > 0) {tmp = arr[end];arr[end] = arr[0];arr[0] = tmp; //交换AdjustDown(arr, end, 0); //向下调整end--;}return;}void AdjustDown(DataType* hp, int size,int parent) { assert(hp);int child = 0;child = parent * 2 + 1;while (child < size) {if (child + 1 < size && hp[child + 1] > hp[child]) {child++;}if (hp[child] > hp[parent]) {DataType tmp = hp[child];hp[child] = hp[parent];hp[parent] = tmp;parent = child;child = parent * 2 + 1;}elsebreak;}return;}本文中使用的是向上调整算法建堆,其时间复杂度为 O(N*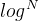 ),而向下调整算法建堆的时间复杂度是O(N),显然向下调整算法建堆更优。但由于篇幅限制,笔者之后会出文章专门讲解这两种算法建堆产生不同时间复杂度的具体原因。
),而向下调整算法建堆的时间复杂度是O(N),显然向下调整算法建堆更优。但由于篇幅限制,笔者之后会出文章专门讲解这两种算法建堆产生不同时间复杂度的具体原因。
4.2topk问题
什么是topk问题?topk问题是指求出给定数据集合中k个最大或最小的数据,一般数据的量比较大。
比如,要求出某个学校期末考试中成绩排名前五十?某个地区爱心捐款最多的前100位?CSDN中原力值排行前一千?
像上面这些例子一样,从一大堆数中选出一小堆最大或最小的数就是topk问题。
4.2.1代码实现
对于topk问题,正常思路可能是将所有数据建一个大堆,然后进行k次Pop操作就行了。
这种方式是可行的,但是不适用于一些数据量非常大的场景。
因为当数据量非常大,比如说有10亿个int型数据时,这时占用的空间接近4G,这些数据对于很多性能一般的电脑已经不能存储在内存中了,只能存储在磁盘文件中,这会导致我们调用数据的速度大大降低。
所以,这时有一个非常简单的解决方法,只对前k个数据建小堆,然后将剩下的N-k个数据依次与根节点比较,比根节点大的就替换掉根节点并向下调整,这样最后得到的数据就是最大的前k个了
4.2.1.1创建数据
这里笔者采用文件存储数据的方式,方便测试数据量较大的情况。
void CreateNDate(){int n = 10000;srand(time(0));const char* file = "data.txt";FILE* fin = fopen(file, "w"); //以写的方式打开文件data.txtif (fin == NULL){perror("fopen error");return;}for (size_t i = 0; i < n; ++i) //写入n个数据{int x = rand() % 1000000;fprintf(fin, "%d\n", x); }fclose(fin);}4.2.1.2找出并打印前k个数据
void PrintTopK(int k){const char* file = "data.txt";FILE* fout = fopen(file, "r"); //以读的方式打开文件data.txtif (fout == NULL){perror("fopen error");return;}int* kminheap = (int*)malloc(sizeof(int) * k); //开辟一个可以存储k个数据的空间if (kminheap == NULL){perror("malloc error");return;}for (int i = 0; i < k; i++){fscanf(fout, "%d", &kminheap[i]); //从文件中读出数据}// 建小堆for (int i = (k - 1 - 1) / 2; i >= 0; i--){AdjustDown(kminheap, k, i); //此处使用向下调整算法建堆}int val = 0;while (!feof(fout)){fscanf(fout, "%d", &val); //如果数据大于堆顶数据就改为新的堆顶数据if (val > kminheap[0]){kminheap[0] = val;AdjustDown(kminheap, k, 0);}}for (int i = 0; i < k; i++){printf("%d ", kminheap[i]); //打印}printf("\n");}4.2.1.3测试代码
int main() {CreateNDate(); //先创建好数据//PrintTopK(5);return 0;}创建好数据后,打开data.txt文件,修改其中五个数据使其明显大于其他数据

然后继续运行看是否成功实现
int main() {//CreateNDate(); //数据已经成功创建,故注释该段代码,防止重复创建导致数据覆盖PrintTopK(5);return 0;}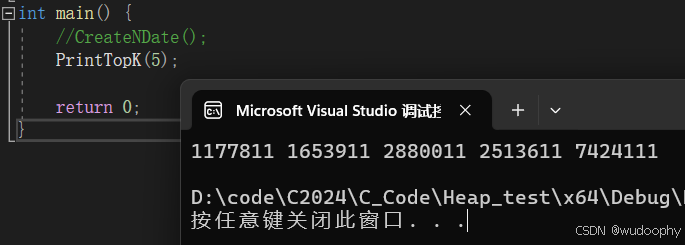
得到如上结果,说明代码成功实现!
读者们也可以按照上述方法测试更大的数据量,设置更大的k值,来看看运行花费的时间有没有明显区别哦!
五,全文总结
本文的内容较多,主要是介绍了堆的性质与概念,堆的代码实现,堆排序解决升序降序问题,堆排序解决topk问题。
5.1易混淆知识点汇总
本章易混淆的知识点:
1,堆只能保证父亲节点与子节点之间的大小关系,不能确保兄弟节点之间的大小关系,所以大堆并不一定是严格的降序,小堆也不一定是严格的升序;
2,用向下调整算法建堆的时间复杂度是O(N),用向上调整算法建堆的时间复杂度是O(N*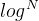 );
);
3,本文中解决topk问题的代码实现中最终得到的k个数据是所有数据中最大的k个数据,但是这k个数据并非按照升序排列的,如果需要升序或者降序的数据则还要再进行一次排序。
5.2本文代码汇总
堆的相关代码如下:(解决升序降序问题的代码比较简单就不再放一遍了)
void AdjustUp(DataType* pa, int site) {assert(pa);int parent = (site - 1) / 2;while (parent>=0 && pa[site] > pa[parent]) {DataType tmp = pa[site];pa[site] = pa[parent];pa[parent] = tmp;site = parent;parent = (site - 1) / 2;}return;}void AdjustDown(DataType* hp, int size,int parent) {assert(hp);int child = 0;child = parent * 2 + 1;while (child < size) {if (child + 1 < size && hp[child + 1] > hp[child]) {child++;}if (hp[child] > hp[parent]) {DataType tmp = hp[child];hp[child] = hp[parent];hp[parent] = tmp;parent = child;child = parent * 2 + 1;}elsebreak;}return;}void HeapInit(HP* hp) {assert(hp);hp->a = NULL;hp->size = 0;hp->capacity = 0;}void HeapDestory(HP* hp) {assert(hp);free(hp->a);hp->a = NULL;hp->capacity = hp->size = 0;}void HeapPush(HP* hp, DataType x) {assert(hp);if (hp->capacity == hp->size) {int Newcapacity = hp->capacity == 0 ? 4 : hp->capacity * 2;DataType* aa = (DataType*)realloc(hp->a,Newcapacity * sizeof(DataType));if (aa==NULL) {perror("realloc fail");return;}hp->a = aa;hp->capacity = Newcapacity;}hp->a[hp->size] = x;hp->size++;AdjustUp(hp->a , hp->size-1);}void HeapPop(HP* hp) {assert(hp);int tmp = hp->a[0];hp->a[0] = hp->a[hp->size - 1];hp->a[hp->size - 1] = tmp;hp->size--;AdjustDown(hp->a, hp->size,0);}int HeapSize(HP* hp) {return hp->size;}bool HeapEmpty(HP* hp) {return hp->size == 0;}解决topk问题的堆排序算法如下:
void AdjustDown(DataType* hp, int size,int parent) {assert(hp);int child = 0;child = parent * 2 + 1;while (child < size) {if (child + 1 < size && hp[child + 1] < hp[child]) {child++;}if (hp[child] < hp[parent]) {DataType tmp = hp[child];hp[child] = hp[parent];hp[parent] = tmp;parent = child;child = parent * 2 + 1;}elsebreak;}return;}void CreateNDate(){// 造数据int n = 10000;srand(time(0));const char* file = "data.txt";FILE* fin = fopen(file, "w");if (fin == NULL){perror("fopen error");return;}for (size_t i = 0; i < n; ++i){int x = rand() % 1000000;fprintf(fin, "%d\n", x);}fclose(fin);}void PrintTopK(int k){const char* file = "data.txt";FILE* fout = fopen(file, "r");if (fout == NULL){perror("fopen error");return;}int* kminheap = (int*)malloc(sizeof(int) * k);if (kminheap == NULL){perror("malloc error");return;}for (int i = 0; i < k; i++){fscanf(fout, "%d", &kminheap[i]);}// 建小堆for (int i = (k - 1 - 1) / 2; i >= 0; i--){AdjustDown(kminheap, k, i);}int val = 0;while (!feof(fout)){fscanf(fout, "%d", &val);if (val > kminheap[0]){kminheap[0] = val;AdjustDown(kminheap, k, 0);}}for (int i = 0; i < k; i++){printf("%d ", kminheap[i]);}printf("\n");}