
在当今快速发展的人工智能领域,本地部署大型语言模型(LLM)Agent正逐渐成为企业和研究者关注的焦点。本地部署不仅能够提供更高的数据安全性和隐私保护,还能减少对外部服务的依赖,提高响应速度和系统稳定性。本文将介绍如何通过Docker容器技术,结合Ollama和AnythingLLM两款工具,完成本地LLM Agent的部署和应用。
Ollama镜像部署
Ollama是一个开源的大型语言模型服务工具,它为用户在本地环境中快速部署和运行大型模型提供了便利。通过简洁的安装指南和一键命令,用户能够迅速地启动如Llama 2和Llama 3等开源大型语言模型。Ollama通过简化LLM部署和管理流程,使用户能够高效地在本地环境中操作大型语言模型。
本文以Windows系统下的Docker部署Ollama为例,通过镜像能够轻量化且更方便地管理虚拟环境。
首先在官网Docker Desktop: The #1 Containerization Tool for Developers | Docker下载Docker Desktop,下载后在DockerHub中可以找到ollama项目,拉取镜像。
这里注意Docker的安装程序默认安装在C盘,由于镜像文件非常大,所以如果想要更换安装路径可以在终端通过如下类似的命令安装:
"D:\Download\Docker Desktop Installer.exe" install --installation-dir="D:\Program\Docker"
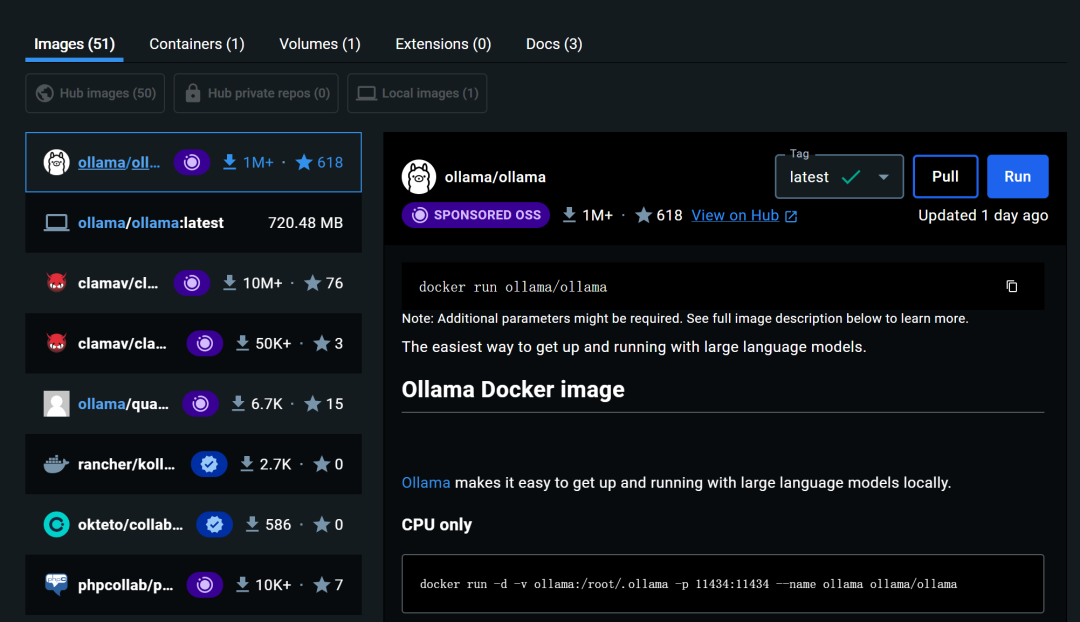
拉取镜像完成后,在Images栏可以确认镜像拉取是否成功。
随后打开终端,使用以下命令创建一个容器用来运行Ollama实例(该命令适用于仅支持CPU的系统,GPU支持或是AMD显卡支持命令可以参考Hub里面的Ollama项目文档)
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama其中—name参数可以自行调整为自己需要的名字,用以区分不同容器。

随后便在容器中运行想要的LLM。
docker exec -it ollama ollama run llama3:8b-instruct-q8_0Ollama官方library (ollama.com)提供了丰富的模型库,不同公司的模型还有不同的微调版本任君选择,这里选择了llama3:8b-instruct-q8_0版本,其中q8代表压缩率,q后的数字越小压缩率越高,模型文件的大小也就越小,同样的性能会有一定下降。llama3默认是q4的压缩率。
第一次运行时,ollama会自动下载模型文件。
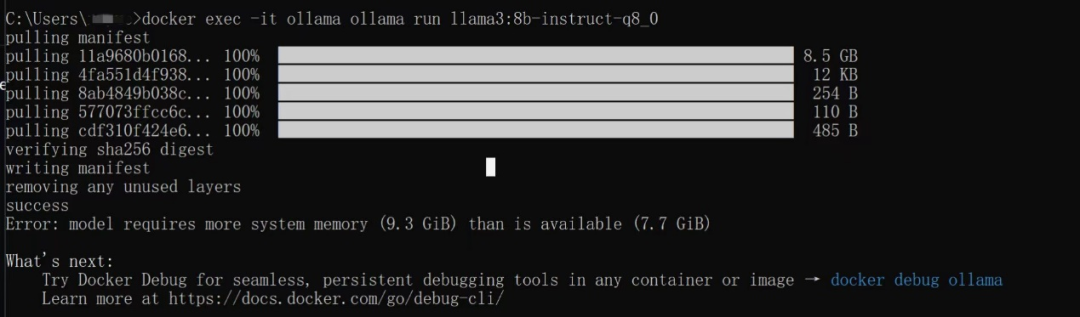
这里可以发现提示内存不足,实际上并不是内存不足,而是Docker的默认内存设置限制。

根据提示可以发现我们需要修改.wslconfig文件。Win+R后输入%UserProfile%以进入用户文件夹,新建.wslconfig文件输入以下内容。更完善的.wslconfig文件格式参见WSL 中的高级设置配置 | Microsoft Learn。
[wsl2] # 节标签memory=2048MB # 限制最大使用内存swap=2GB # 限制最大使用虚拟内存processors=2 # 限制最大使用cpu个数
修改完后需要运行wsl –shutdown来关闭wsl实例,随后重新打开使默认设置生效。
再次运行时,出现了交互窗口,运行命令如图。

AnythingLLM
AnythingLLM 是一款全能的人工智能应用程序,它允许用户与文档进行交互,使用人工智能助手,并且具有高度的可配置性。它支持多用户管理并且设置过程简单,无需繁琐的设置。这款应用程序能够将任何文档、资源或内容转换成上下文信息,供大型语言模型(LLM)在聊天过程中作为参考使用。用户可以根据自己的需要选择使用不同的LLM或向量数据库。

在官网Download AnythingLLM for Desktop下载应用程序,打开之后设置LLM首选项,在ollama下面可以找到刚才下载的模型文件,注意此处还可以修改Max Tokens数。不同的模型有不同的适用参数,AnythingLLM暂时还不能自动适配推荐,因此需要额外进行搜索,比如llama3:8b-instruct-q8_0模型的Max Tokens为8192。
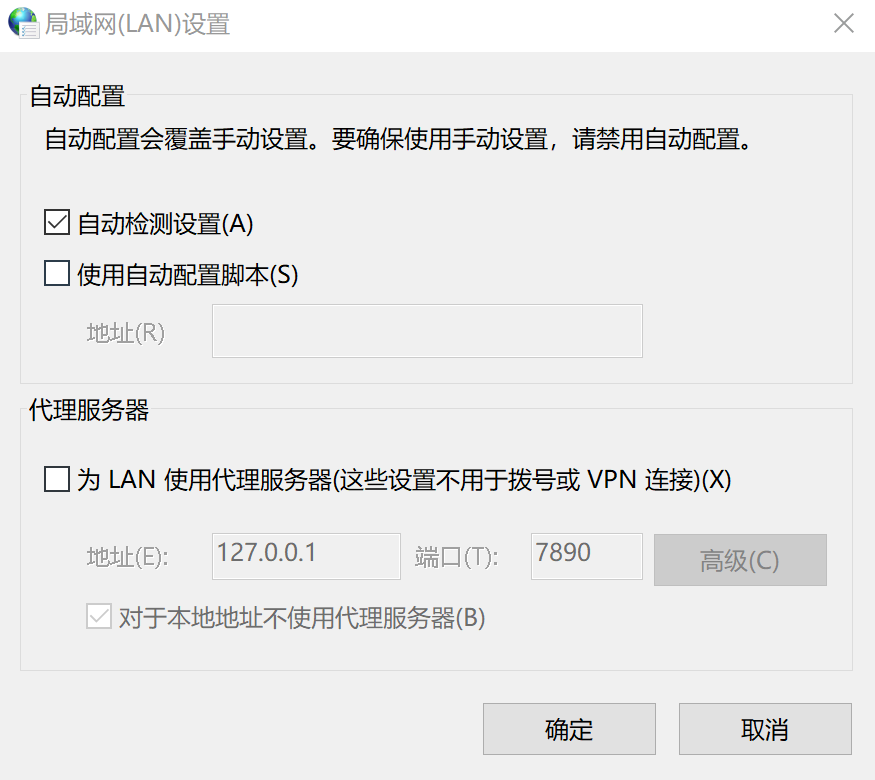
在首次尝试Chat功能时,如果出现Could not respond to message报错,考虑是网络代理问题,应该改成如下选项。
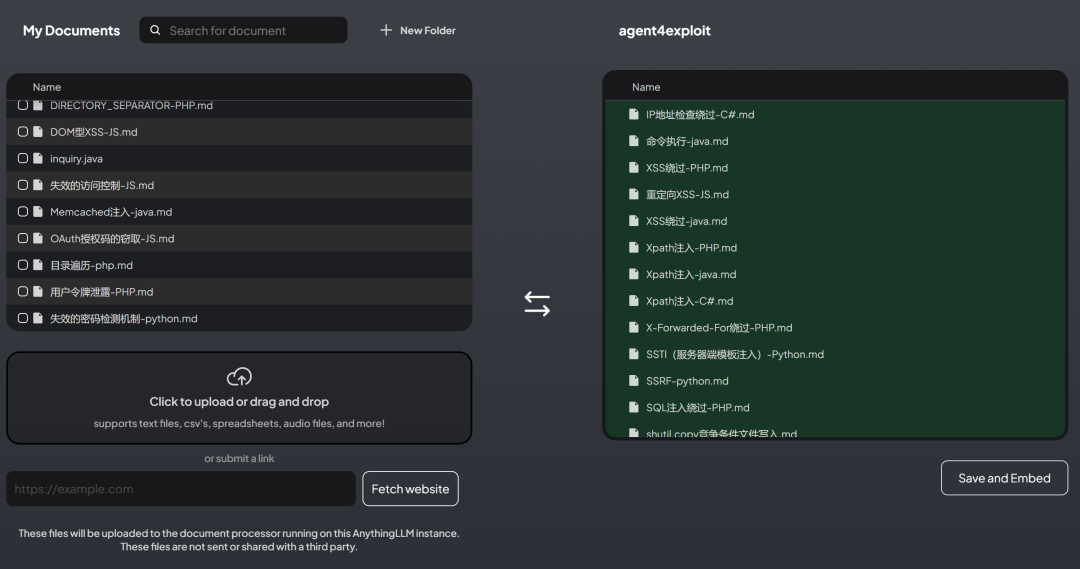
AnythingLLM对于任何模型,无论是否提供文件服务的模型都可以通过上传文件使其具备相应的知识,从而构建自己的LLM 知识库。
此外除了文件服务,AnythingLLM还提供网络搜索服务。
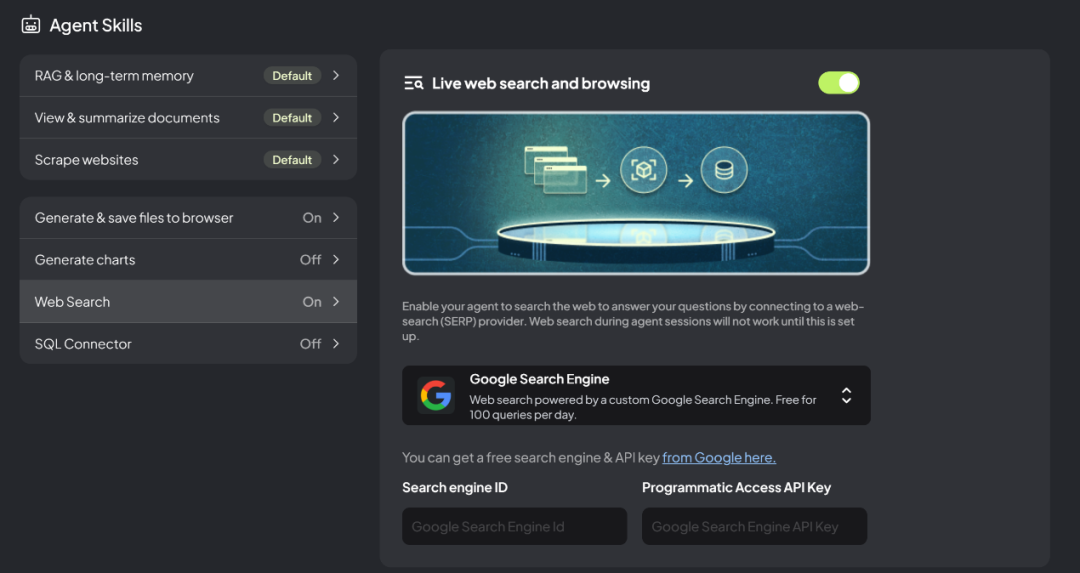
Google提供了免费的搜索服务引擎,可以点击提供的链接进行登记。其他的Agent服务也可以自行探索。
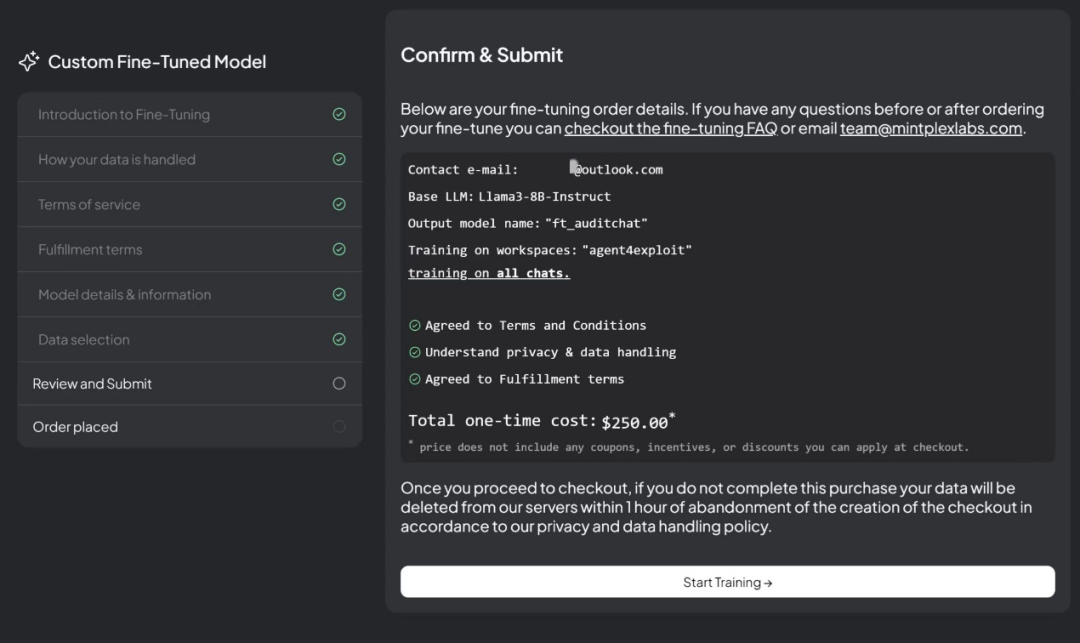
AnythingLLM同时提供了方便快捷的Fine-tuning服务,仅需要几十条高质量对话和消费级GPU即可在本地部署一个经过微调的LLM Agent。目前此项目还是付费状态,感兴趣的小伙伴可以尝试一下。
作者:徐玥
2024年8月9日
洞源实验室