整理:赵宇彤、苗文婷
摘要:本文主要介绍 BTC.com 团队在实时 OLAP 方面的技术演进过程及生产优化实践,内容如下:
业务背景
机遇挑战
架构演进
架构优化
未来展望
Tips:点击文末「阅读原文」即可回顾作者原版分享视频~
一、业务背景
1.1 业务介绍 - ABCD
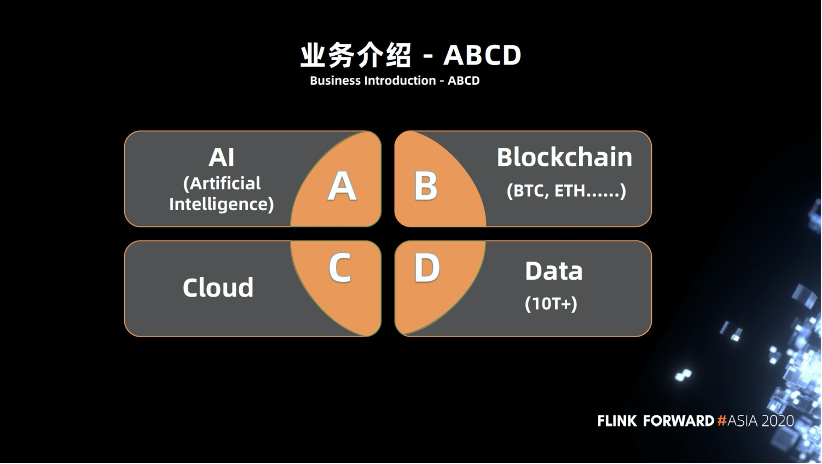
BTC.com 是一家区块链技术方案提供者,我们的业务主要分为四个部分,总结来说就是 ABCD:A 是人工智能机器学习,B 是区块链,C 代表云,D 是数据。这些模块不仅相互独立的,也可以互相结合。近几年人工智能、区块链的加速发展与大数据在背后提供的支持息息相关。
1.2 业务介绍 - 区块链技术方案提供商

区块链通俗来讲可以理解为一个不可逆的分布式账本,我们的作用是让大家能更好的浏览账本,挖掘账本背后的信息数据。目前比特币的数据量级大概在几十亿到百亿,数据量大概在数十T,当然我们也有其他的一些业务,如以太坊货币、智能合约分析服务等。
整体而言我们是一家区块链技术方案的提供商,提供挖矿的服务。与金融行业的银行一样,我们也有很多的 OLAP 需求,比如当黑客攻击交易所或供应链进行资产转移或者洗钱时,需要经过链上的操作,我们可以在链上对其进行分析,以及交易上的跟踪,统计数据等,为警方提供协助。
二、机遇挑战
2.1 之前的架构
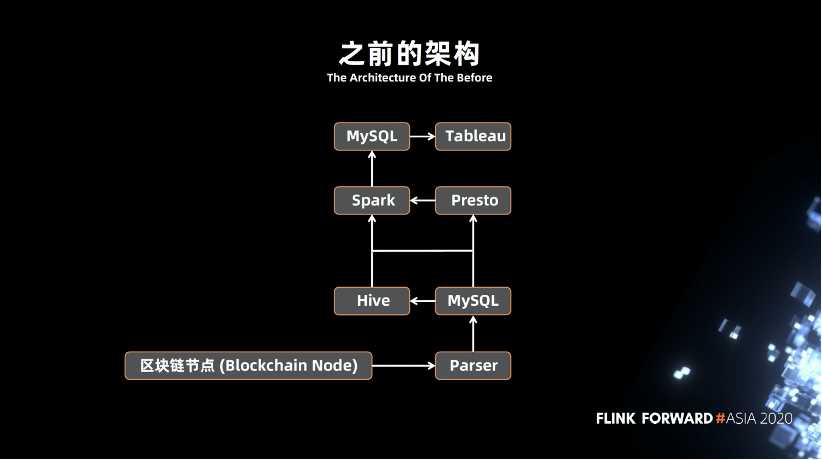
大概 2018 年的时候,竞争对手比较少,我们整体的架构如上。底层是区块链的节点,通过 Parser 不断的解析到 MySQL ,再从 MySQL 抽取到 Hive 或者 Presto,从 Spark 跑各种定时任务分析数据,再通过可视化的查询,得到报表或者数据。架构的问题也是显而易见的:
不能做到实时处理数据
存在单点问题,比方某一条链路突然挂掉,此时整个环节都会出现问题
2.2 遇到的需求与挑战

效率,效率问题是非常常见的。我们的表大概在几十亿量级,跑这种 SQL ,可能需要很长时间, SQL 查询比较慢,严重影响统计效率。
实时,数据不是实时的,需要等到一定的时间才会更新,如昨天的数据今天才能看到。
监控,实时需求,如实时风控,每当区块链出现一个区块,我们就要对它进行分析,但是区块出现的时间是随机的。缺乏完整的监控,有时候作业突然坏了,或者是没达到指标,我们不能及时知道。
2.3 技术选型我们需要考虑什么
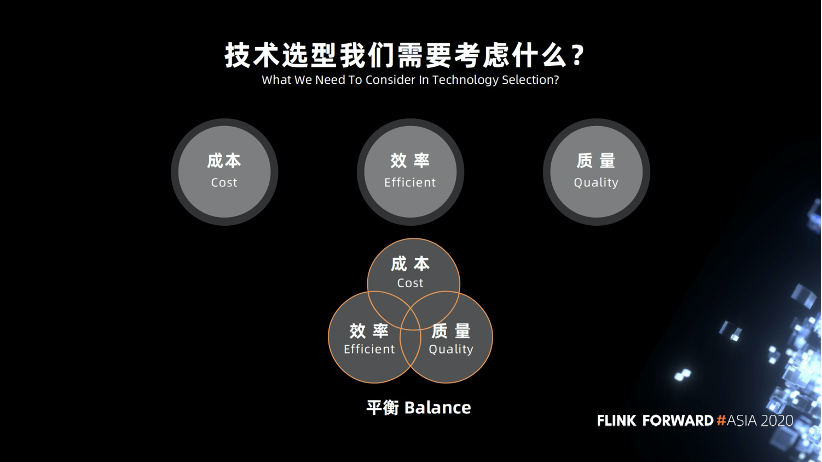
在技术选型的时候我们需要考虑什么呢?首先是缩容,2020年行情不太好,大家都在尽力缩减成本,更好的活下去。在成本有限的情况下,我们如何能做更多的东西,必须提高自身的效率,同时也要保证质量。所以我们需要找到一种平衡,在成本效率还有质量这三者之间进行一定的平衡。
三、架构演进
3.1 技术选型

俗话说,工具选的好,下班下的早,关于是否引入 Flink,我们想了很久,它和 Spark 相比优势在哪里?
我们实际调研以后,发现 Flink 还是有很多优势,比方说灵活的窗口,精准的语义,低延迟,支持秒级的,实时的数据处理。因为团队本身更熟练 Python ,所以我们当时就选择了 PyFlink ,有专业的开发团队支撑,近几个版本变化比较大,实现了很多功能。在实时 OLAP 方面,数据库我们采用了 ClickHouse 。
3.2 为什么使用 ClickHouse
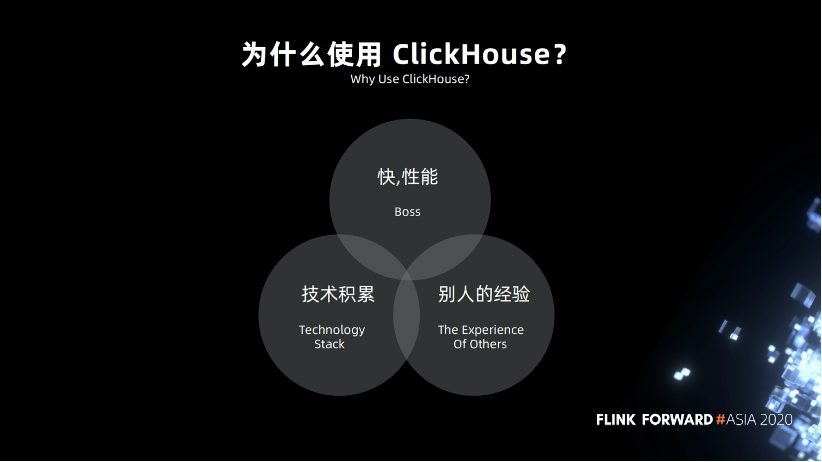
为什么要使用 ClickHouse ?首先是快,查询的效率高。字节跳动,腾讯,快手等大公司都在用。同时我们也有 C++方面的技术积累,使用起来比较容易,成本不是太高。
3.3 实时 OLAP 架构
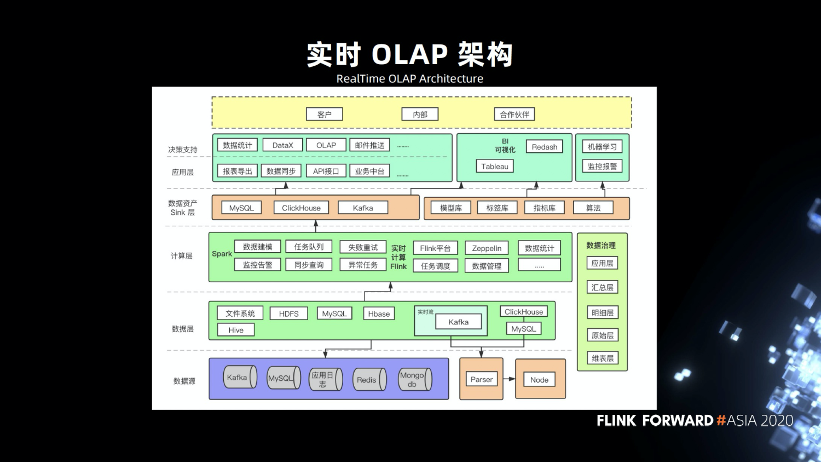
基于以上的技术选型,我们就形成了上图的架构,底层是数据源,包括区块链的节点,通过 Parser 解析到 Kafka,Kafka 负责对接 Flink 和 Spark 任务,然后 Flink 把数据输出到 MySQL 和 ClickHouse,支持报表导出,数据统计,数据同步,OLAP 统计等。
数据治理方面,我们参考了业界的分层,分成了原始层、明细层、汇总层以及应用层。我们还有机器学习的任务,这些都部署在 K8s 平台之上。
3.4 架构演进历程
我们的架构演进过程如下图,从 2018 年的 Spark 和 Hive ,到后来的 Tableau 可视化,今年接触了 Flink ,下半年开始使用 ClickHouse ,后来 Flink 任务比较多了,我们开发了简易的调度平台,开发者只需要上传任务,就会定时或者实时的跑任务。

3.5 架构演进思考

为什么演进这么慢,因为区块链的发展还没有达到一定量级,无法像某些大公司有上亿级别或者 PB 级别的数据量。我们的数据量没有那么大,区块链是一个新鲜的事物,没有一定的历史。另外的问题就是资源问题,由于人员不足,人员成本上也有所控制。
刚才讲的架构,我们总结了它适合怎样的企业。首先是有一定的数据规模,比说某个企业 MySQL 只有几千万的数据,用 MySQL , Redis , MongoDB 都可以,就不适合这套架构。其次是需要一定的成本控制,这一整套成本算下来比 Spark 那一套会低很多。要有技术储备,要开发了解相关的东西。
区块链数据的特点。数据量比较多,历史数据基本上是不变的,实时数据相对来说是更有价值的,数据和时间存在一定的关联。
3.6 实时 OLAP 产生的价值
在实时 OLAP 上线后,基本满足了业务需求,同时成本也在可控的范围内。
适合的是最好的,不要盲目追求新技术,比如数据湖,虽然好,但是我们的数据量级实际上用不到。
我们不考虑建设技术中台,我们的公司规模是中小型,部门沟通起来比较容易,没有太多的隔阂,没有发展到一定的组织规模,所以我们没有打算发展技术中台,数据中台,不盲目跟风上中台。
我们达到的效果是缩短了开发的时长,减少作业的运行时间。
四、架构优化
4.1 Flink 和 ClickHouse

Flink 和 ClickHouse 之间有一些联动,我们自定义了三个工作。
自定义 sink 。
ClickHouse 要一次性插入很多数据,需要控制好写入的频次,优先写入本地表,耗时比较多。
我们主要用在智能合约的交易分析,新增的数据比较多,比较频繁,每几秒就有很多数据。数据上关联比较多。
4.2 ClickHouse 遇到的问题

批量导入时失败和容错。
Upsert 的优化。
开发了常用 UDF ,大家知道 ClickHouse 官方是不支持 UDF 的吗?只能通过打补丁,保证 ClickHouse 不会挂。
我们也在做一些开源方面的跟进,做一些补丁方面的尝试,把我们业务上,技术上常用的 UDF ,集合在一起。
4.3 批量导入策略
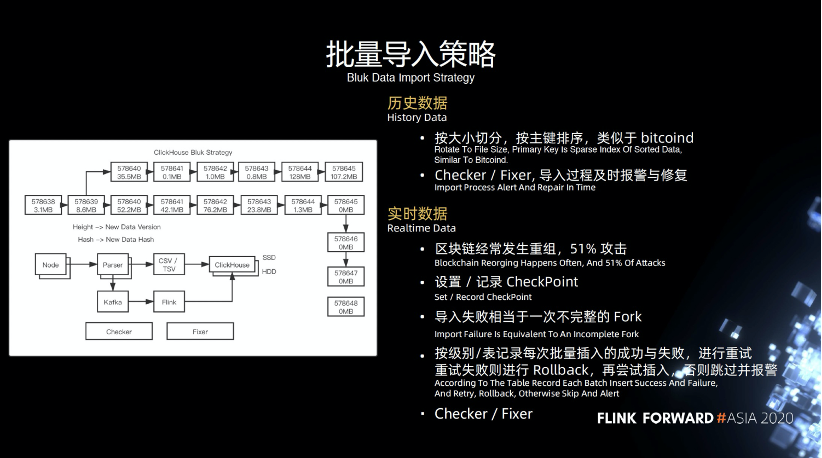
历史数据,可以认为是一种冷数据,相对来说不会经常改变。导入的时候按照大小切分,按照主键排序,类似于 bitcoind ,底层的 Checker 和 Fixer 工作,导入过程中及时进行报警和修复。比如导入某一数据失败了,如何更好的及时发现,之前就只能人肉监控。
实时数据,我们需要不断解析实时数据,大家可能对重组,51%的概念不太熟悉,这里简单讲一下,上图最长的链也是最重要的链,它上面的一条链是一个重组并且分叉的一条链,当有一个攻击者或者矿工去挖了上面的链,最终的结果会导致这条链被废弃掉,拿不到任何奖励。
如果超过51%的算力,就会达到这样的效果,成为最长的链,这个是累计难度比较高的,此时我们会认为数据导入失败,同时我们会利用回撤的功能,不断将其回滚和重组,直到满足最完整的链。当然我们也会设置一些记录和 CheckPoint ,这里的 CheckPoint 和 Flink 的 CheckPoint 的概念也有所区别。
它是区块链方面的 CheckPoint ,区块链有一个币种叫 bch ,会定义 CheckPoint,当满足一定的长度时,它就无法再进行回滚,避免了攻击者的攻击。我们主要是利用 CheckPoint 记录信息,防止回滚,同时还会按照级别/表记录批量插入的失败或者成功,如果失败则会进行重试,以及报警回滚等操作。
4.4 Upsert 的优化

ClickHouse 不支持 Upsert ,主要在 SDK 方面做兼容,之前是直接往 MySQL 写数据,目标是通过 SQL 语句修改对应的 SDK 增加临时小表的 join ,通过 join 临时小表,进行 Upsert 的操作。
举个例子,区块链地址账户余额,就像银行的账户余额,必须非常精确。
4.5 Kubernetes 方面优化
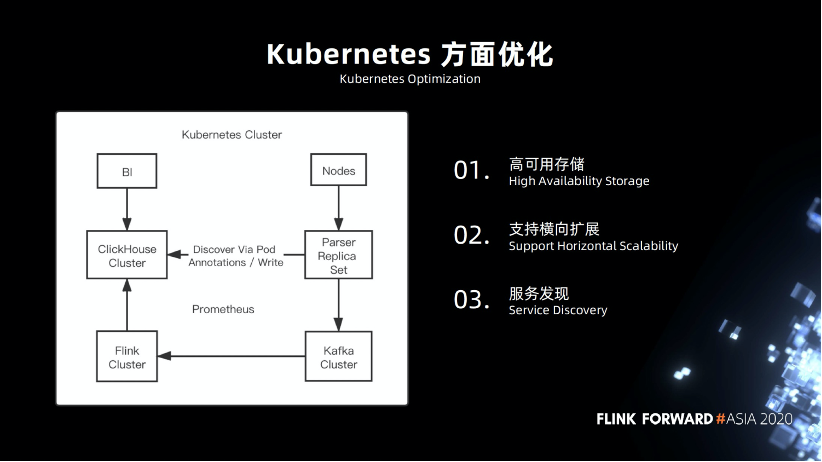
Kubernetes 方面的优化。Kubernetes 是一个很完整的平台。
高可用的存储,在早期的时候,我们就尽可能的将服务部署在 Kubernetes,包括 Flink 集群,基础业务组件,币种节点,ClickHouse 节点,在这方面 ClickHouse 做的比较好,方便兼容,支持高可用操作。
支持横向扩展。
服务发现方面,我们做了一些定制。
4.6 如何保证一致性?

采用 Final 进行查询,等待数据合并完成。
在数据方面的话,实现幂等性,保证唯一性,通过主键排序,整理出来一组数据,再写入。
写入异常时就及时修复和回填,保证最终一致性。
4.7 监控
使用 Prometheus 作为监控工具。使用方便,成本较低。
五、未来展望
5.1 从 1 到 2

扩展更多的业务和数据。之前我们的业务模式比较单一,只有数据方面的统计,之后会挖掘更多信息,包括链上追踪,金融方面的审计。
赚更多的钱,尽可能的活下去,我们才能去做更多的事情,去探索更多的盈利模式。
跟进 Flink 和 PyFlink 的生态,积极参与开源的工作,优化相关作业。探索多 sink 方面的工作,原生 Kubernetes 的实践。
5.2 从 2 到 3

数据建模的规范,规定手段,操作。
Flink 和机器学习相结合。
争取拿到实时在线训练的业务,Flink 做实时监控,是非常不错的选择。大公司都已经有相关的实践。包括报警等操作。
总的来说的话,路漫漫其修远兮,使用 Flink 真不错。更多 Flink 相关技术交流,可扫码加入社区钉钉大群~

▼ 关注「Flink 中文社区」,获取更多技术干货 ▼

 戳我,回顾作者分享视频!
戳我,回顾作者分享视频!