会议名称:2023 IEEE Symposium on Security and Privacy (SP)
发布链接:AI-Guardian: Defeating Adversarial Attacks using Backdoors | IEEE Conference Publication | IEEE Xplore
中文译名:AI-Guardian:利用后门防御对抗攻击
阅读原因:网安相关,方班需要
本文主要介绍了一种名为AI-Guardian的框架,旨在通过神经网络后门机制抵御对抗攻击。文章首先概述了深度学习在实际应用中面临的安全威胁,特别是对抗攻击的问题,并强调了研究有效防御策略的重要性。接着,文章提出了AI-Guardian框架,该框架在模型训练阶段注入后门样本,并在预测阶段利用后门处理和标签双射关系来返回正确的预测结果。通过与现有防御策略的比较,AI-Guardian显示出更好的防御效果、更小的时间开销,并且对模型原有表现的影响较小。最后,文章通过一系列实验验证了AI-Guardian的有效性,包括攻击成功率、模型预测时间开销、模型训练时间开销和模型准确率的影响评估。
1.研究背景和问题:
(1)实际应用场景和问题提出
深度学习对输入数据敏感,很容易受到对抗攻击,存在严重的安全问题。
对抗攻击(Adversarial Attack)是指攻击者通过故意篡改输入数据,使机器学习模型产生错误预测的攻击方式。这种攻击利用了深度学习模型对输入数据的敏感性,通过在原始数据中添加细微的扰动或噪声,使得这些经过修改的数据(称为对抗样本)被模型误分类。对抗攻击可以在多种应用场景中发生,包括图像识别、语音识别和自然语言处理等。由于对抗样本在人类看来与原始数据几乎无异,但模型却会做出截然不同的错误判断,因此对抗攻击对AI系统的安全性构成了严重威胁。
现有的对抗攻击防御策略存在效果有限、影响模型原有表现等问题,不能彻底抵御对抗攻击。
(2)问题的研究意义
对抗攻击本质就是欺骗AI模型,对AI系统的正常运转造成严重干扰。一旦发生在某些关键领域,如自动驾驶、智能医疗,将带来严重安全隐患,甚至造成严重安全事故。随着深度学习技术越来越广泛的应用,研究合适的对抗攻击防御策略刻不容缓。
(3)问题的研究现状
现有对抗攻击防御策略主要分为两大类:离线防御策略和在线防御策略。
离线防御策略:这类策略主要在模型训练阶段实施,旨在提高模型对对抗样本的鲁棒性。典型的方法包括:
对抗训练(Adversarial Training):通过在训练数据中加入对抗样本来增强模型的抗攻击能力。缺点是会增加模型训练的时间开销,并且可能影响模型对正常样本的识别准确率。模型蒸馏(Model Distillation):通过将复杂模型的知识转移到简化模型中,以提高模型的泛化能力和鲁棒性。缺点是需要额外的模型训练过程,且可能降低模型的性能。在线防御策略:这类策略在模型预测阶段实施,旨在检测并抵御对抗样本的攻击。典型的方法包括:
压缩或平滑算法:通过对输入数据进行压缩或平滑处理,以减少对抗样本的影响。缺点是可能会增大模型预测的时间开销,且在某些情况下会降低模型的准确率。对抗样本检测:使用特定的算法来检测输入数据是否为对抗样本。缺点是可能需要额外的计算资源,且可能存在误报和漏报的情况。总体而言,这些防御策略各有优缺点,但都面临着提高模型鲁棒性与保持模型性能之间的平衡挑战。
(4)作者的方案
文中提出的对抗攻击防御策略是AI-Guardian框架,它主要通过在模型训练阶段注入后门样本,并在预测阶段利用后门处理和标签双射关系来抵御对抗攻击。具体来说:
后门样本生成:在模型训练阶段,针对原始训练样本生成一批经过后门处理的样本(称为后门样本),这些后门样本与原始样本在视觉上相似但具有特定的标记。标签双射关系:为每个后门样本分配一个对应的标签,这个标签与原始标签存在一一对应关系(即双射)。后门注入:将生成的后门样本及其对应的标签加入到训练集中,使模型在学习过程中同时对原始样本和后门样本进行学习。预测阶段的处理:在模型预测阶段,输入数据首先经过后门处理,然后模型根据处理后的数据输出预测结果。由于模型已经学习了后门样本,因此能够在一定程度上抵御对抗样本的攻击。标签双射关系的利用:根据后门样本的标签双射关系,将模型输出的预测结果转换为对应的真实标签,从而返回正确的预测结果。通过这种方法,AI-Guardian能够有效提高模型对对抗攻击的防御能力,同时保持较小的时间开销和对模型原有表现的影响。
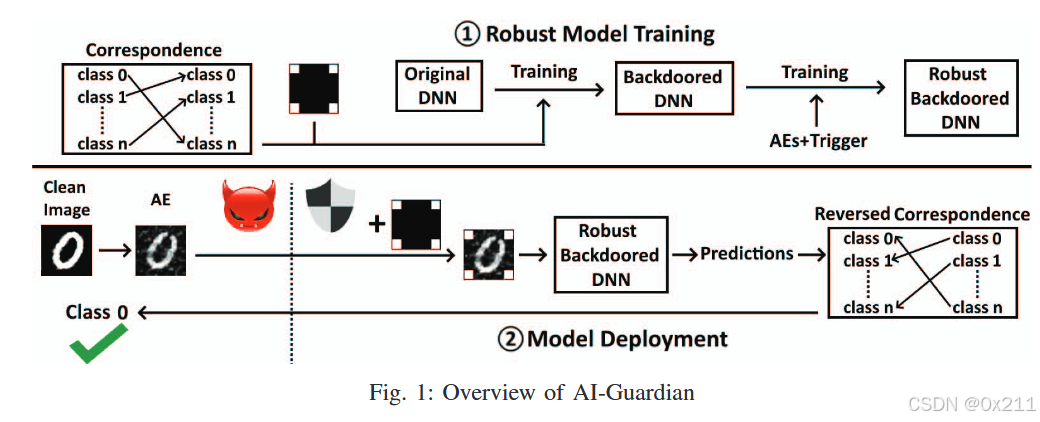
2.技术框架 方法论:
(1)相关知识和基本原理
神经网络后门(Neural Network Backdoor)是指在神经网络模型中植入的一种隐藏行为,使得攻击者可以通过特定方式触发这些行为,从而控制模型的输出。具体来说,后门攻击通过在训练数据中插入特定的“后门”样本,这些样本与正常样本相似,但具有特定的标记或特征。在模型训练过程中,这些后门样本被学习到,导致模型在遇到类似的输入时会按照攻击者的意图输出特定的结果。
例如,一个图像分类模型可能在训练时被注入了某些特定图案的图像,这些图像都被标记为某个特定类别。当模型部署后,如果用户输入包含这些特定图案的图像,模型就会错误地将其分类为那个特定类别,从而实现攻击者的控制意图。
双射:指一一对应关系(数学用语)
(2)本文的方法概述
本文提出了AI-Guardian框架,本质是让模型预测结果受到后门控制,而很难被攻击者操纵,从而抵御对抗攻击。在模型训练阶段,AI-Guardian会针对原始训练样本生成一批后门样本(经过后门处理的样本),按标签双射关系为后门样本分配对应标签,实现后门注入;在模型预测阶段,AI-Guardian先对输入数据进行后门处理,然后将其输入到模型,根据模型输出结果、标签双射关系返回对输入数据真实标签的预测结果。
(3)核心原理
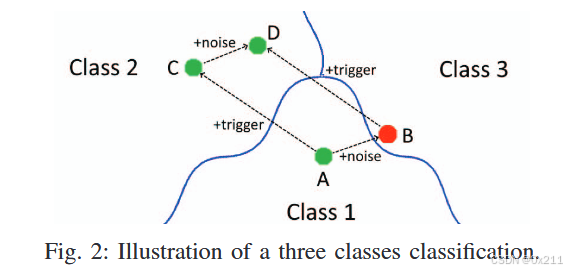
如下图,蓝色实线是模型的决策边界,攻击者目标:把A样本加噪后使得模型对A'(就是B)分类到类别3中(而非真实的类别1)。作者的设计直觉是:C点表示添加了触发器的干净图像A,被归类为2类中,即使遭受到了攻击(加噪过程,变成D),也还是会被分类为真实的类别2中。D可能会越过决策边界,但是经过作者的评估,这种可能性很低。

后门样本生成与注入:
在模型训练阶段,针对原始训练样本生成一批经过特定处理的后门样本。这些后门样本与原始样本在视觉上相似,但具有特定的标记或特征。为每个后门样本分配一个对应的标签,这个标签与原始标签存在一一对应关系(即双射)。将生成的后门样本及其对应的标签加入到训练集中,使模型在学习过程中同时对原始样本和后门样本进行学习。标签双射关系的利用:
在模型预测阶段,输入数据首先经过后门处理,然后输入到模型中。根据模型输出的结果和预先定义的标签双射关系,将模型输出的预测结果转换为对应的真实标签,从而返回正确的预测结果。防御机制:
由于模型在训练过程中已经学习了后门样本,因此在遇到对抗样本时,模型能够在一定程度上抵御这些攻击。这是因为对抗样本通常依赖于模型对特定模式的敏感性,而后门样本的训练使得模型对这些模式有了额外的鲁棒性。通过标签双射关系,可以纠正模型在面对对抗样本时的误判,从而确保模型输出的正确性。计算效率:
AI-Guardian引入的额外数据预处理操作是一个轻量级的打补丁操作,计算量小且不破坏图像的有效信息。因此,它对模型预测时间的影响非常小。(4)方法的讨论与分析
与现有离线防御策略相比,AI-Guardian采用了“后门训练”策略,让模型的输出受到后门控制,从而更好地提升了模型稳定性;与现有在线防御策略相比,AI-Guardian引入的额外数据预处理操作是一个打补丁操作,计算量小,而且不破坏图像有效信息,因此对模型原有表现的影响更小,引入的时间开销也更小。实验证明,AI-Guardian取得的防御效果好于现有代表性对抗攻击防御策略。
3.实验设计与结果分析:
(1)攻击成功率对比实验:作者对比了AI-Guardian和其它6种代表性对抗攻击防御策略:EAT、Madry、FIBTF、JPEG Compression、TVM、Trapdoor在4个数据集(MNIST、GTSRB、Youtube-Face、VGG-Face)上的攻击成功率变化情况。AI-Guardian可将平均攻击成功率从97.3%降至3.2%,而其它方法中效果最好的TVM只将平均攻击成功率从97.3%降至11.6%。说明AI-Guardian具有更好的防御效果。
(2)模型预测时间开销对比:对比AI-Guardian与JPEG Compression、TVM、Trapdoor策略在MNIST,GTSRB,Youtube-Face,VGG-Face这4个数据集上的模型预测时间开销,发现每个数据集上AI-Guardian引入的时间开销比例均小于1%,远小于其它方法。说明引入AI-Guardian不会显著增加模型预测时间。
(3)模型训练时间开销对比:对比AI-Guardian与EAT、Madry、FIBTF、Trapdoor在MNIST,GTSRB,Youtube-Face,VGG-Face这4个数据集上所需的模型训练时间。实验中AI-Guardian所需平均模型训练时间8.4h,仅比最快的方法FIBTF多0.2h。说明AI-Guardian不会引起较大的额外模型训练时间开销
(4)模型准确率影响评估:对比MNIST,GTSRB,Youtube-Face,VGG-Face这4个数据集上AI-Guardian对模型准确率的影响。结果表明,在引入AI-Guardian后,模型平均准确率只下降0.5%,说明AI-Guardian几乎不影响模型原有表现。
4.结论与展望:
优点
更好的防御效果:
AI-Guardian能够显著降低对抗攻击的成功率,从97.3%降至3.2%,优于其他代表性防御策略。这表明它在抵御对抗攻击方面具有更高的有效性。更小的时间开销:
在模型预测时间开销方面,AI-Guardian引入的时间开销比例远小于1%,远低于其他方法。这意味着它对模型预测速度的影响非常小,不会显著增加延迟。较小的训练时间开销:
实验结果显示,AI-Guardian的平均训练时间为8.4小时,仅比最快的FIBTF方法多0.2小时。这表明它不会引起显著的训练时间增加,保持了较高的训练效率。对模型准确率影响极小:
AI-Guardian对模型准确率的影响极小,平均准确率下降仅0.5%。这意味着它在提高模型鲁棒性的同时,几乎不影响模型的原有表现。独特的后门机制:
AI-Guardian基于神经网络后门机制,通过在训练阶段注入后门样本并在预测阶段利用标签双射关系来抵御攻击。这种机制使得模型对特定模式具有额外的鲁棒性,从而更好地抵御对抗样本的攻击。缺点
后门模型预测标签与输入数据真实标签的一一对应要求:
AI-Guardian要求后门模型预测标签必须与输入数据的真实标签存在一一对应的关系。这种严格的要求使得模型训练过程更加复杂和苛刻,可能需要更多的人工干预和调整。潜在的隐私和安全问题:
由于AI-Guardian在模型中植入了后门样本,这可能引发对模型安全性和隐私问题的担忧。如果攻击者能够识别并利用这些后门,可能会导致更严重的安全风险。适用范围的限制:
虽然AI-Guardian在实验中表现出色,但其有效性和适用性仍需在不同应用场景中进一步验证。某些特定领域或数据集可能对后门机制有不同的反应,需要针对性地进行调整和优化。模型训练复杂度增加:
尽管实验结果显示AI-Guardian的训练时间开销相对较小,但后门样本的生成和注入过程仍然增加了模型训练的复杂度。对于大规模数据集和复杂模型,这种额外的训练负担可能会更加显著。本文提出AI-Guardian框架,基于神经网络后门机制抵御对抗攻击,利用标签双射关系来返回正确预测结果。与现有对抗攻击防御策略相比,本文方法具有更好的防御效果、更小的时间开销,且对模型原有表现很小。然而,AI-Guardian要求后门模型预测标签必须与输入数据真实标签一一对应,这对模型训练的要求更加苛刻。