文章目录
[高级人工智能 开放性调研] 近两年来[2022-2024]人工智能应用进展重要案例介绍写在前面1. AIGC1.1 LLM | 大语言模型问答系统式的生成式AI文档解读——KimiChat代码生成——Cursor 1.2 AI绘画\视频生成 | Stable Diffusion | OpenAI SoraStable DiffusionOpenAI Sora 2. 自动驾驶 | “萝卜快跑”(Apollo Go)商用相关链接
[高级人工智能 开放性调研] 近两年来[2022-2024]人工智能应用进展重要案例介绍
写在前面
本文基于作者个人研究生就读阶段关于 《高级人工智能》 课程的开放性问题——“近两年来,人工智能在应用方面取得了哪些进展?请列举出有影响力的案例。” 展开信息收集并适当进行相关内容概述。本文会在作者个人整理的开放性进展的类别下举例一些作者个人用正在使用的感觉不错的AI应用,作为本文的拓展性价值——实用AI工具简介与推荐。本文不进行深入而具体的对某个具体实用的AI工具的详细叙述,仅展示作者个人更关注的近两年AI应用框架和实用AI工具简介。1. AIGC
我认为,AIGC是近两年来,人工智能在应用方面取得最明显进展,也是催生了众多有影响力,且真正在人们生产生活的各个方便提高了人们效率的垂直应用的重要案例领域。 1.1 LLM | 大语言模型
问答系统式的生成式AI
以ChatGPT为代表的大语言模型,可以称之为当之无愧的近两年来最具有影响力的人工智能应用进展的重要案例。
2022 年 12 月,ChatGPT 第一次发布后,以问答系统应用为标志性特征的LLM的浪潮便席卷开来。

随着ChatGPT大语言模型的浪潮涌起后,国内也相继出现了包括,文心一言,通义千问,讯飞星火,智谱清言等在内的大语言模型。这些都各自具备一定的可用性。




这些LLM工具在不同的领域和应用中发挥着重要作用,从聊天机器人到文本生成,再到数据翻译和分析等。
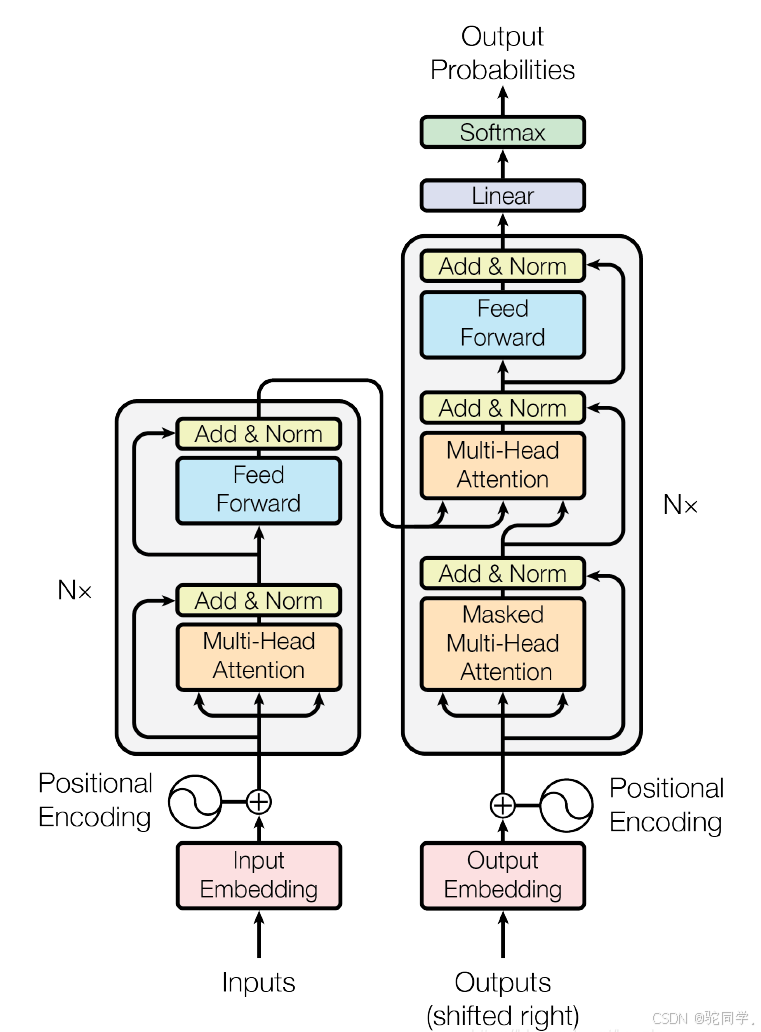
技术细节: GPT也即是Generative Pre-trained Transformer,GPT的底层的技术细节是2017年出现的Transformer架构。2017 年,Google 在论文 Attention is All you need 中提出了 Transformer 模型,其使用 Self-Attention 结构取代了在 NLP 任务中常用的 RNN 网络结构。相比 RNN 网络结构,其最大的优点是可以并行计算。
文档解读——KimiChat
Kimi Chat 与其他大型语言模型(LLM)如文心一言相比,具有一些独特的优势:处理长文本的能力:Kimi Chat 支持长达20万汉字的输入,这在全球市场中的产品化大模型服务中是非常突出的。这意味着它能够处理更长的上下文,为用户提供更深入的分析和回答。
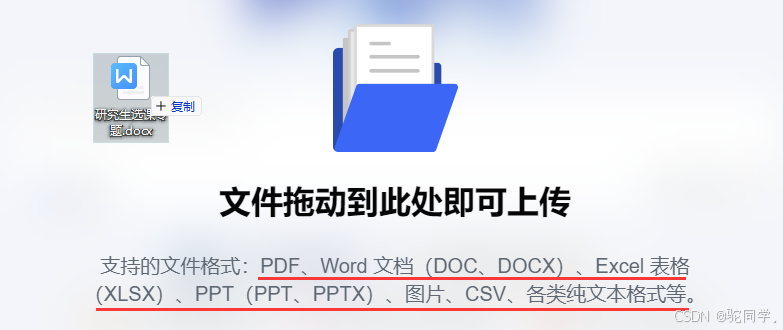
文件处理能力:Kimi Chat 能够处理多种文件格式,包括PDF、Word文档、PPT幻灯片、Excel电子表格等,这为用户提供了极大的便利。
搜索能力:Kimi Chat 具备搜索能力,可以结合实时搜索结果为用户提供回答,这使得它的答案更加准确和及时。

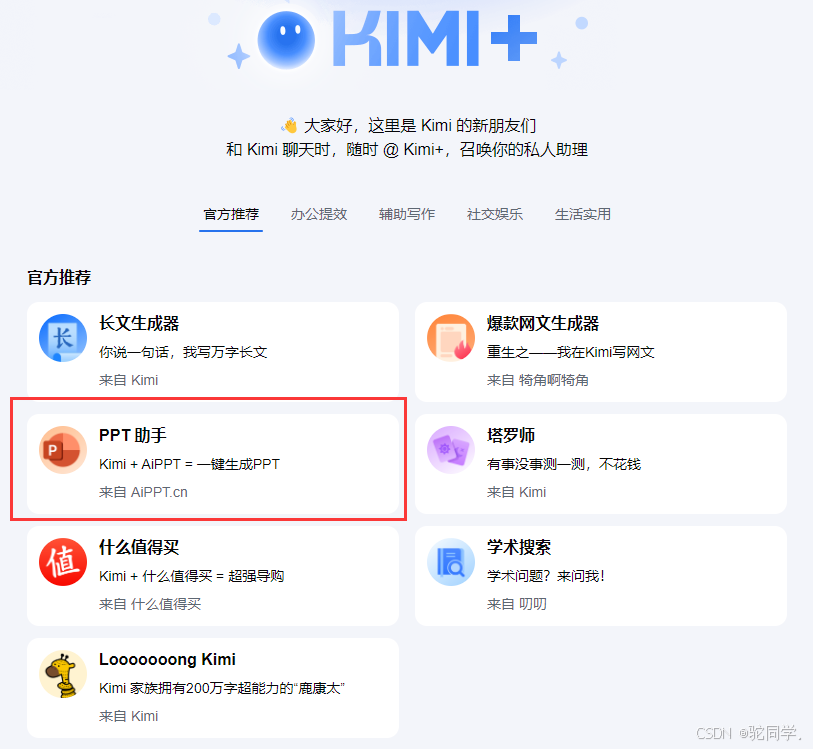
垂直能力:Kimi Chat 拓展了许多具体有意义的场景应用,比如它提供了免费的PPT生成应用,改应用生成的PPT具有美观的PPT模板选择和充实丰富的内容填充。
代码生成——Cursor
Cursor是一款基于GPT的代码生成工具,它可以帮助开发者快速生成代码,提高开发效率。GPT是一种自然语言处理技术,可以根据输入的文本生成相应的文本。Cursor利用GPT技术,将开发者的自然语言描述转化为代码,从而实现代码的快速生成。Cursor 是一款智能开发者编程工具,底层是由Chat-GPT3.5 or Chat-GPT4.0支持的,国内可以直接使用。Cursor = VS code + ChatGPT相比于直接在网页中进行代码问答,Cursor能够允许开发者在类似VS code的IDE下进行chat,更适合LLM在代码开发的应用。 Cursor可以让AI直接写代码:
Cursor可以让AI直接写代码: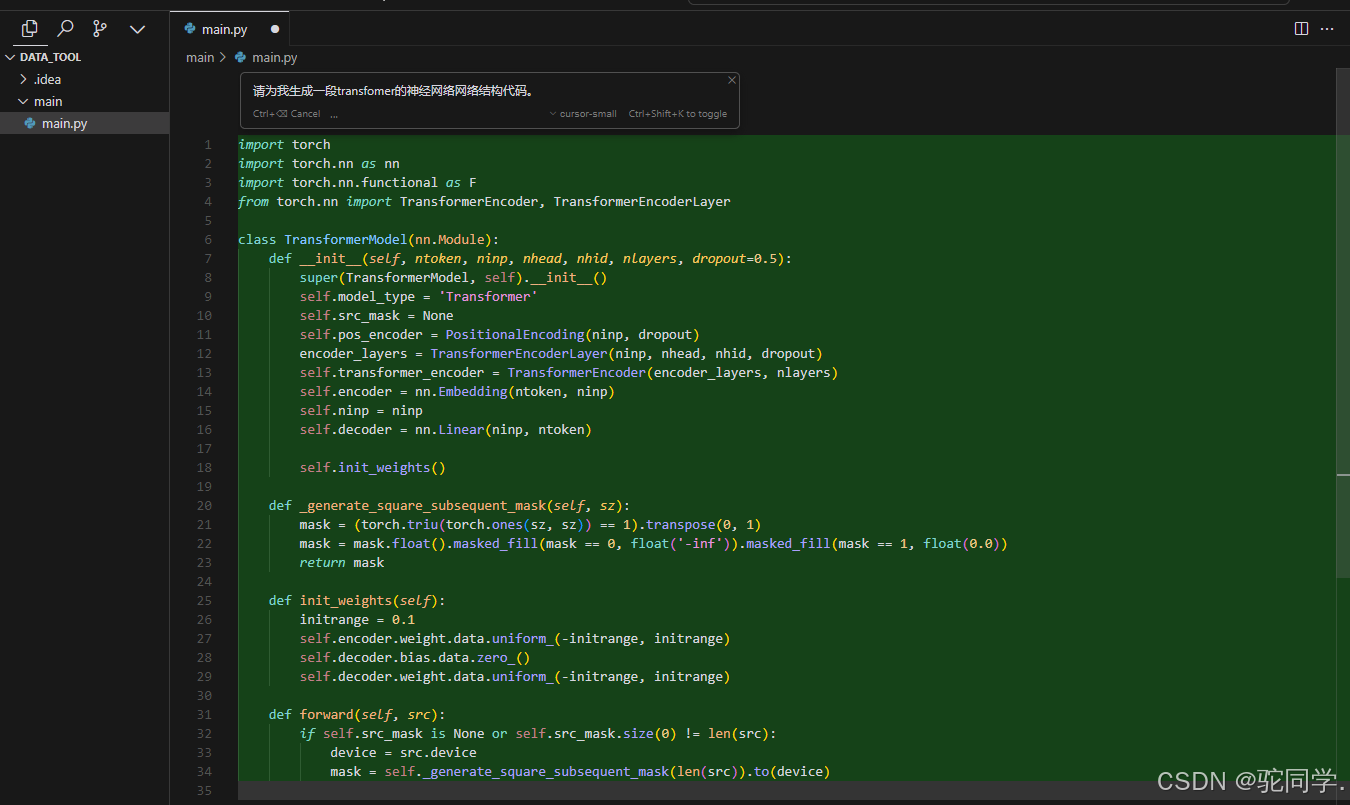 Cursor可以作为你的技术老师,帮你答疑解惑:
Cursor可以作为你的技术老师,帮你答疑解惑: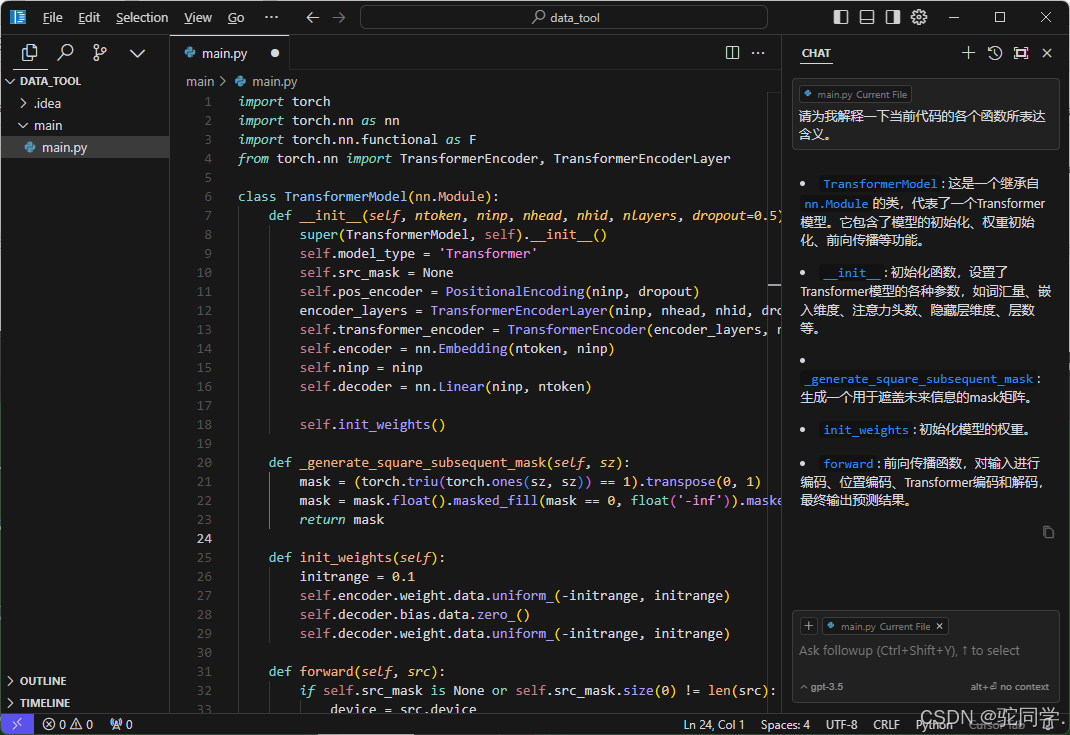
1.2 AI绘画\视频生成 | Stable Diffusion | OpenAI Sora
Stable Diffusion
Stable Diffusion凭借其高度灵活性和通用性,能生成各类高质量图像,满足用户个性化需求。其领先的图像生成和风格转换能力,以及逼真的细节表现,使其在同类工具中脱颖而出。Stable Diffusion 真正强大之处在于它可以根据文本提示生成图像。这是通过接受调节输入修改内部扩散模型来实现的。技术细节:从Diffusion Model到Stable Diffusion纯扩散模型: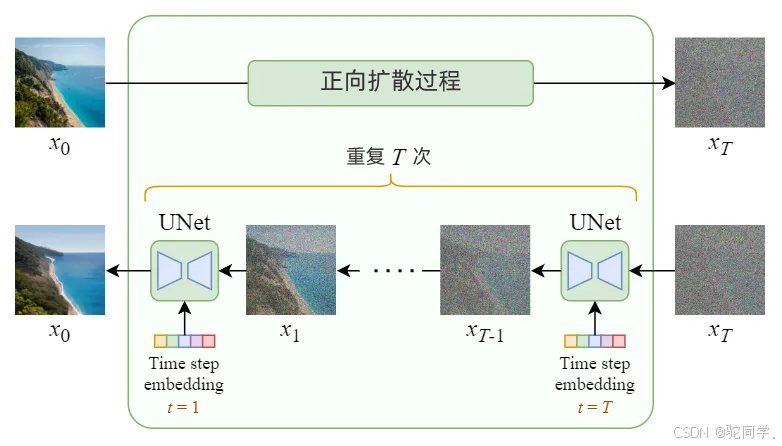 潜在扩散模型:
潜在扩散模型: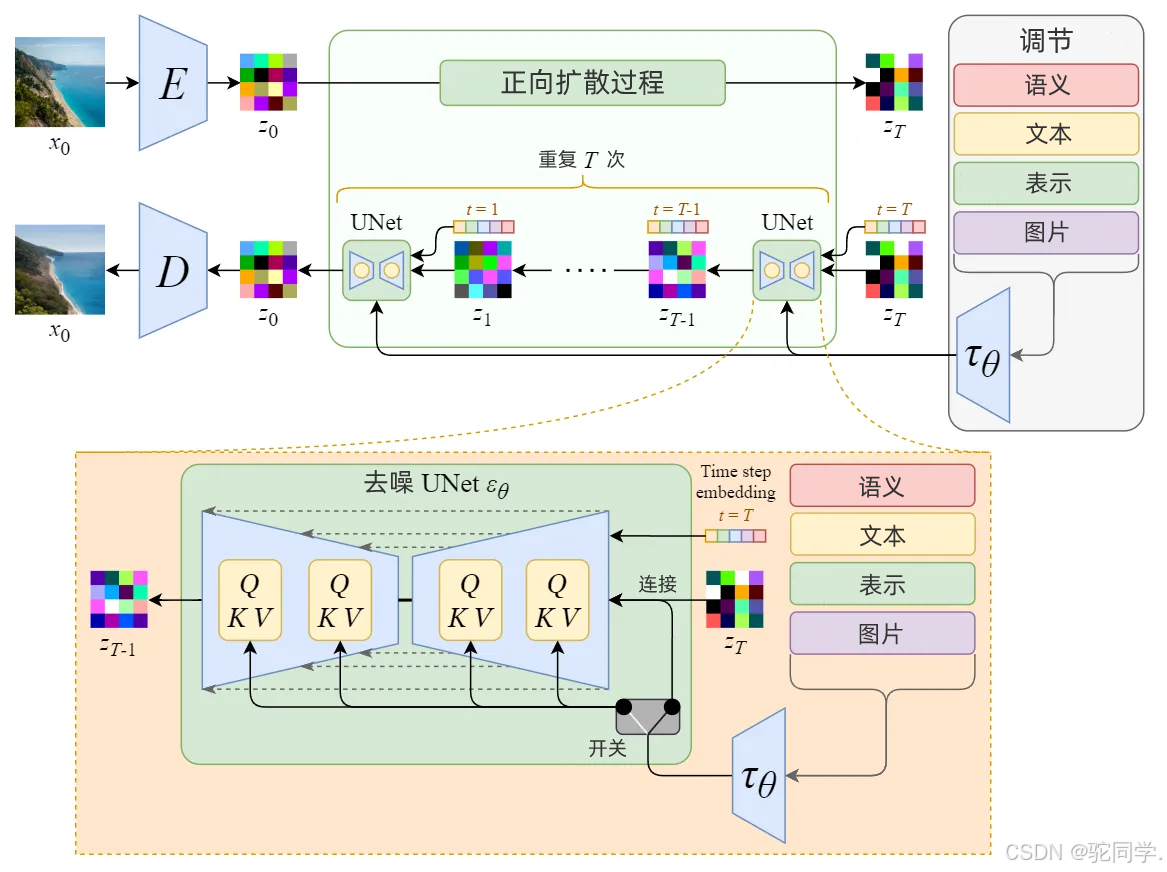
OpenAI Sora
Sora是一个基于大规模训练的文本控制视频生成扩散模型。它能够生成长达 1 分钟的高清视频,涵盖广泛的视觉数据类型和分辨率。Sora通过在视频和图像的压缩潜在空间中训练,将其分解为时空位置补丁,实现了可扩展的视频生成。Sora还展现出一些模拟物理世界和数字世界的能力,如三维一致性和交互,揭示了继续扩大视频生成模型规模来发展高能力模拟器的前景。Sora的重要意义在于它再次推动了AIGC在AI驱动内容创作方面的上限。在此之前,ChatGPT等文本类模型已经开始辅助内容创作,包括插图和画面的生成,甚至使用虚拟人制作短视频。而Sora则是一款专注于视频生成的大模型,通过输入文本或图片,以多种方式编辑视频,包括生成、连接和扩展,属于多模态大模型的范畴。这类模型在GPT等语言模型的基础上进行了延伸和拓展。技术细节: Sora主要通过三个步骤实现视频训练。首先是视频压缩网络,将视频或图片降维成紧凑而高效的形式。其次是时空补丁提取,将视图信息分解成更小的单元,每个单元都包含了视图中一部分的空间和时间信息,以便Sora在后续步骤中进行有针对性的处理。最后是视频生成,通过输入文本或图片进行解码加码,由Transformer模型(即ChatGPT基础转换器)决定如何将这些单元转换或组合,从而形成完整的视频内容。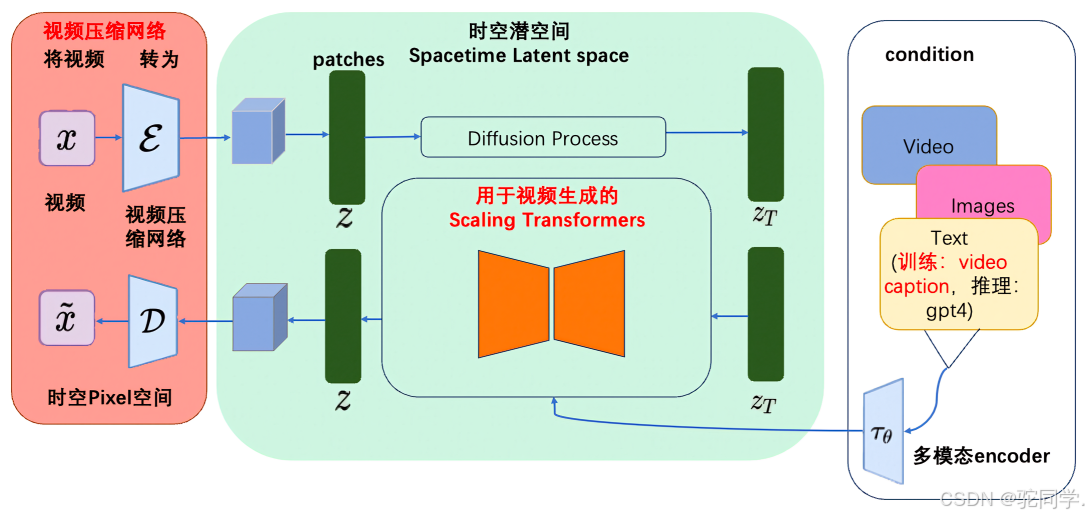
2. 自动驾驶 | “萝卜快跑”(Apollo Go)商用

这篇文章介绍了百度推出的无人驾驶出租车服务“萝卜快跑”(Apollo Go)的底层技术原理。以下是文章中提到的无人驾驶涉及的部分关键技术:
感知系统:无人驾驶汽车通过多种传感器来感知周围环境,包括:
激光雷达(LiDAR):生成高精度的三维地图。摄像头:捕捉道路标识、交通信号、行人和其他车辆。雷达(Radar):探测物体的速度和距离,适用于恶劣天气。超声波传感器:近距离探测,帮助避免低速时的碰撞。决策与规划:
路径规划:基于地图和实时交通状况计算最优路线。行为预测:预测周围物体的运动轨迹,以做出安全决策。决策规划:生成具体的驾驶动作,如加速、刹车、转向等。控制系统:
纵向控制:管理车辆的加速和减速。横向控制:管理车辆的转向。综合控制:协调纵向和横向控制,实现平稳驾驶。人工智能与机器学习:
深度学习:用于图像识别、目标检测和分类。强化学习:优化决策和控制策略,通过模拟和实际驾驶数据训练。