本文根据2024云栖大会实录整理而成,演讲信息如下:
演讲人:
林伟 | 阿里云智能集团研究员、阿里云人工智能平台 PAI 负责人
黄博远|阿里云智能集团资深产品专家、阿里云人工智能平台 PAI 产品负责人
活动:
2024 云栖大会 - AI Infra 核心技术专场、人工智能平台 PAI 年度发布专场
今年是大模型迅猛发展的一年,GenAI(生成式 AI)的应用领域得到了前所未有的拓展。随之而来,技术挑战也在升级,硬件成本、资源管理、软件硬件之间的配合问题等都是大模型落地必须面对的难题。为了应对这些挑战,阿里云人工智能平台 PAI 持续进行技术创新与优化。2024云栖大会 AI Infra 核心技术专场、人工智能平台年度发布专场,PAI 团队带来了对 AI Infra 工程技术的趋势解读,以及 PAI 的全新能力发布。

一、AI Infra 工程技术趋势解读
纵观这一轮大模型热潮,AI 工程化价值愈加凸显。阿里云智能集团研究员、阿里云人工智能平台 PAI 负责人林伟指出:“大模型对算力的苛求相当高,已经将硬件计算性能推到了极限,高速网络互联的大规模 AI 集群高频地出现硬件和软件问题,依赖系统层面整体的优化能力。”结合阿里云人工智能平台 PAI 支撑阿里巴巴集团和广大云上客户的经验,林伟分享了以下几点关键趋势。
1. 大规模训练的稳定性
超大规模训练任务错误率是非常高的,错误类型和成因定位也很复杂。其中最麻烦的是 Grey-failure,它会拉低任务运行速度但又不至于中断任务,因此捕捉这类错误的难度很高。同时,随着模型尺寸变大,故障恢复成本也随之升高。
应对稳定性的挑战,PAI 主要做了两件事。一方面,基于对 PyTorch 框架和系统的理解,构建了 AIMaster + 网络诊断能力,探查集群中潜在的问题并事先规避;另一方面,通过 EasyCkpt 工具进行分钟级的异步 Checkpoint 保存和按需快照下发,确保故障产生以后快速恢复任务。
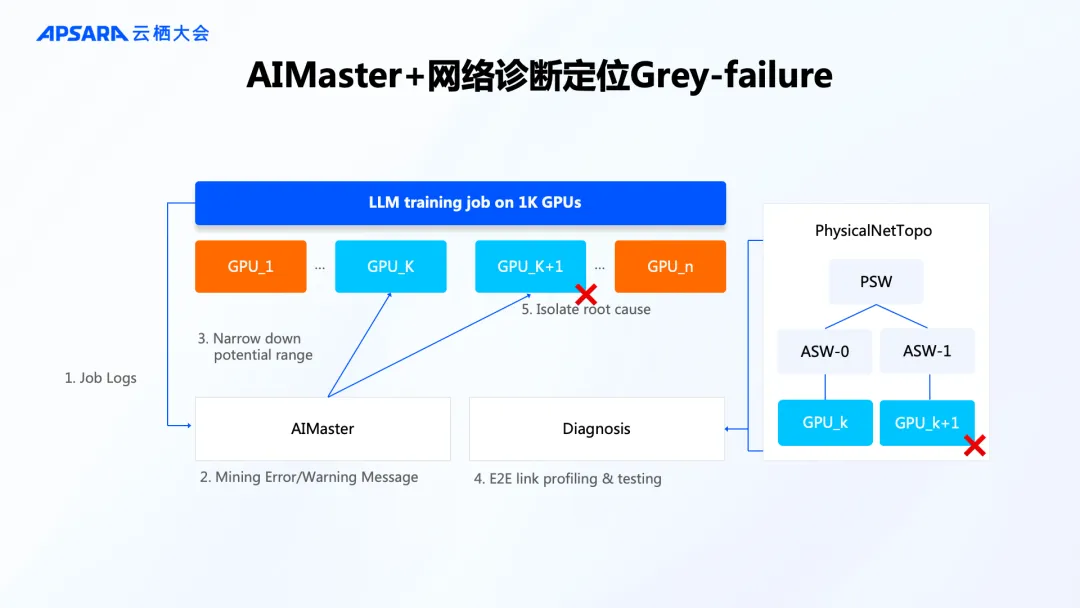
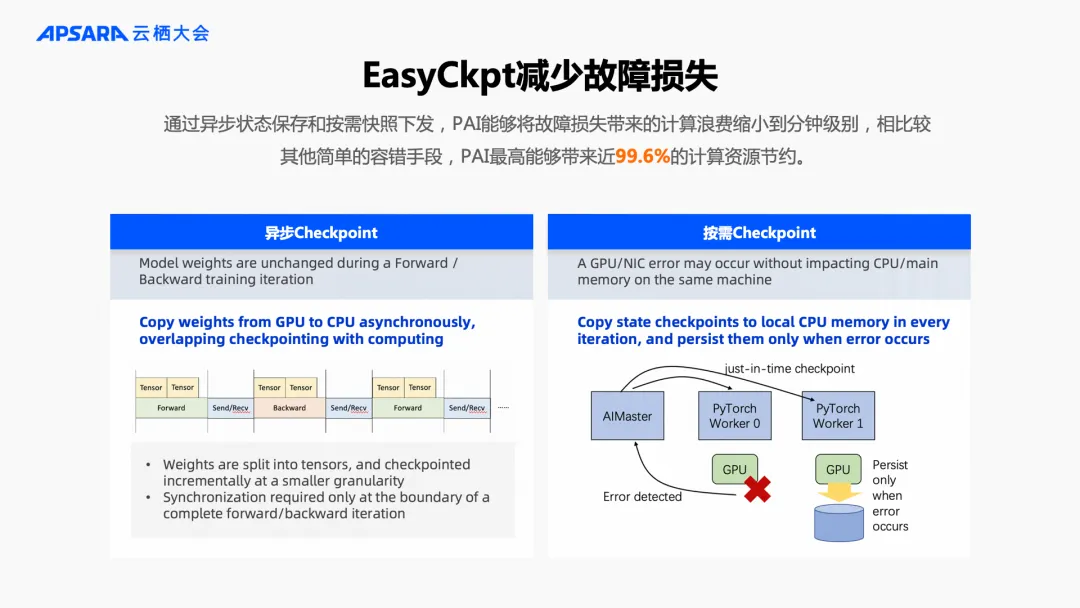
2. 大规模集群的自动分布式训练
算法工程师天然地会去关注算法结构创新、训练方法、数据清洗、训练效果等等,但是对于分布式训练的环境怎么配置是不太熟悉的。在分布式训练方面,PAI 也推出了相应的工具。
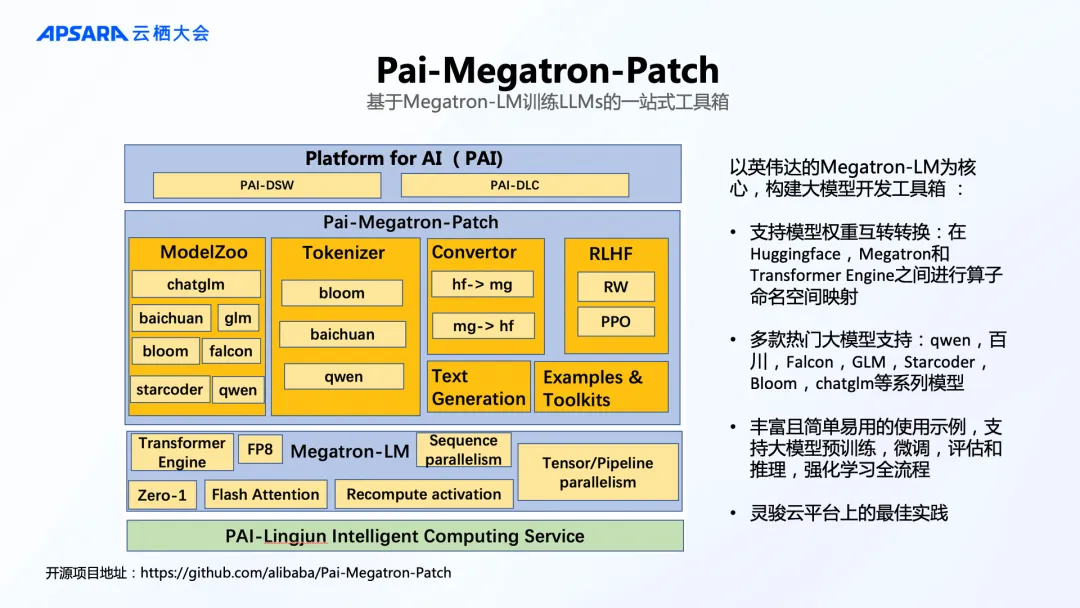
针对 Transformer 结构模型,Pai-Megatron-Patch [1]提供了以 Megatron-LM 为核心的开发工具箱,支持更简便的模型格式转换,并提供热门开源基础模型的使用实例,覆盖预训练、微调、评估、推理、强化学习全流程。
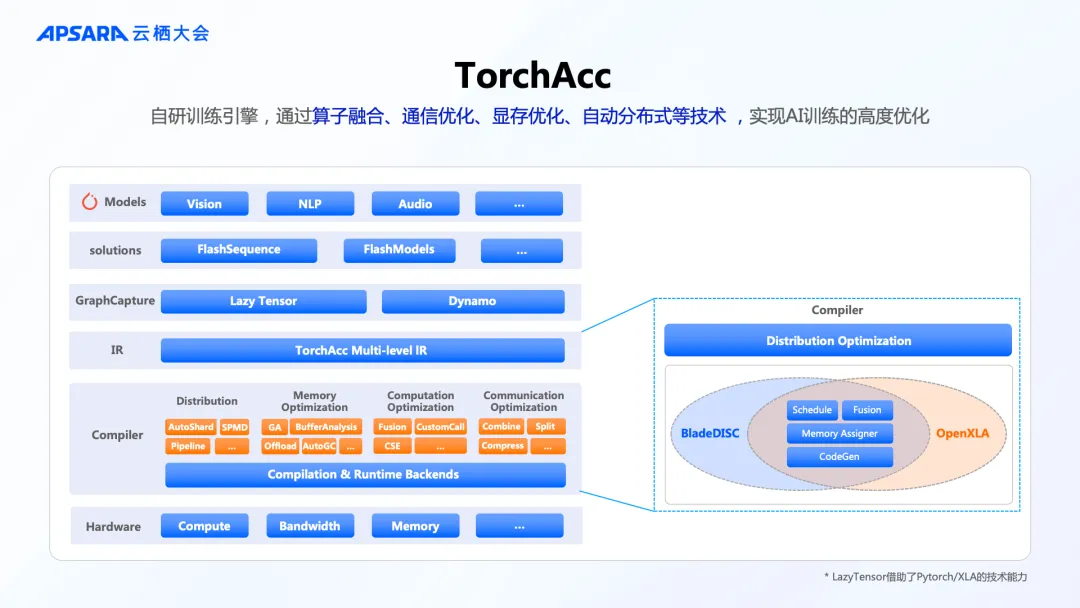
针对更广泛的模型结构,PAI 自研的 TorchAcc 训练引擎,通过算子融合、通信优化、显存优化、自动分布式等技术,能实现分布式训练的高度优化和自动化。TorchAcc 基于 Torch/XLA 框架进行优化和产品化,在2023年 OpenXLA 举办的技术峰会中可以详细了解 TorchAcc 的相关工作[2]。TorchAcc 即将正式接入 ModelScope 魔搭社区,方便更多模型开发者无缝地调用。
3. 强化学习
ChatGPT 获得重大突破的一个重要原因就是增加了 RLHF 强化学习,让模型能力更好地对齐人类认知。不过,强化学习的过程会给分布式训练工程带来更大的挑战,因为还需要额外去训练一个模型结构、参数规模对等的 Reward Model,这样整体训练存储和分布式计算的消耗会更大。
PAI 构建了一个新的 Alignment 训练框架 ChatLearn,它能高效地支撑 SFT、RM、RLHF/DPO/Online DPO/GRPO 等各类 Alignment 方法全流程训练,例如在 Qwen2-72B 模型 Online DPO 训练、Qwen2-Math-Instruct GRPO 训练过程中,背后都运用到了 ChatLearn。ChatLearn 框架已经在今年8月正式开源[3]。

4. 推理服务优化
最近很多大模型服务都在降价,降价背后需要极致的优化调度去支撑,只有计算资源得到充分利用、成本下降了,才能够让模型能力真正普惠。这也是 AI 工程化的使命之一。
我们主要的工作是推出了 PAI-BladeLLM,综合工程层面和模型层面不同的优化策略去做推理优化。
模型层面最重要的就是做量化压缩,PAI-BladeLLM 通过自动混合量化、逐层选择精度最佳的算法策略,在推理时动态选择最优计算模式,取得推理精度和速度的最佳平衡。
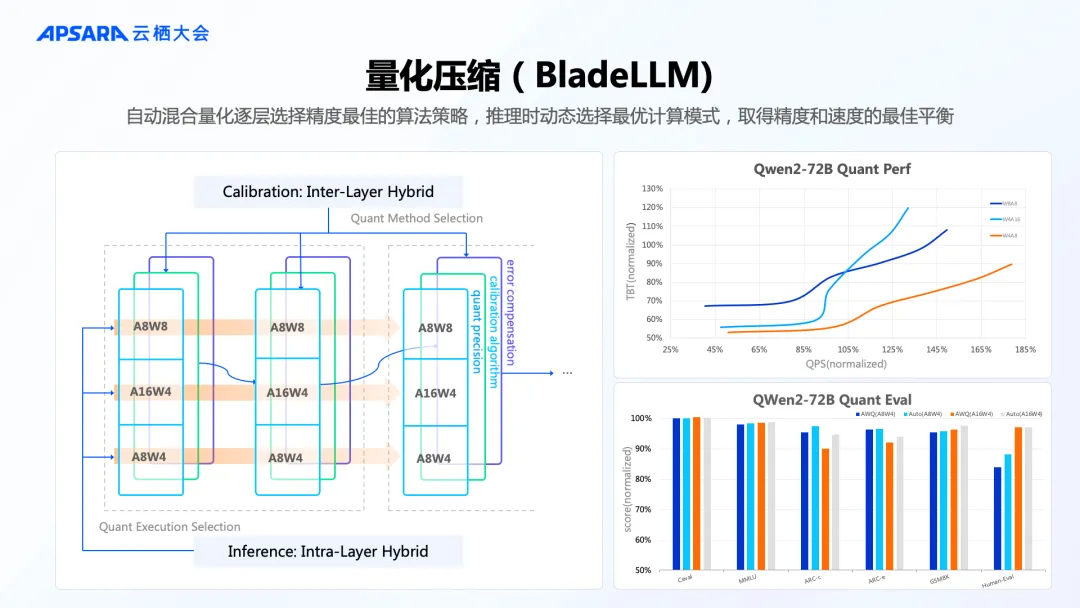
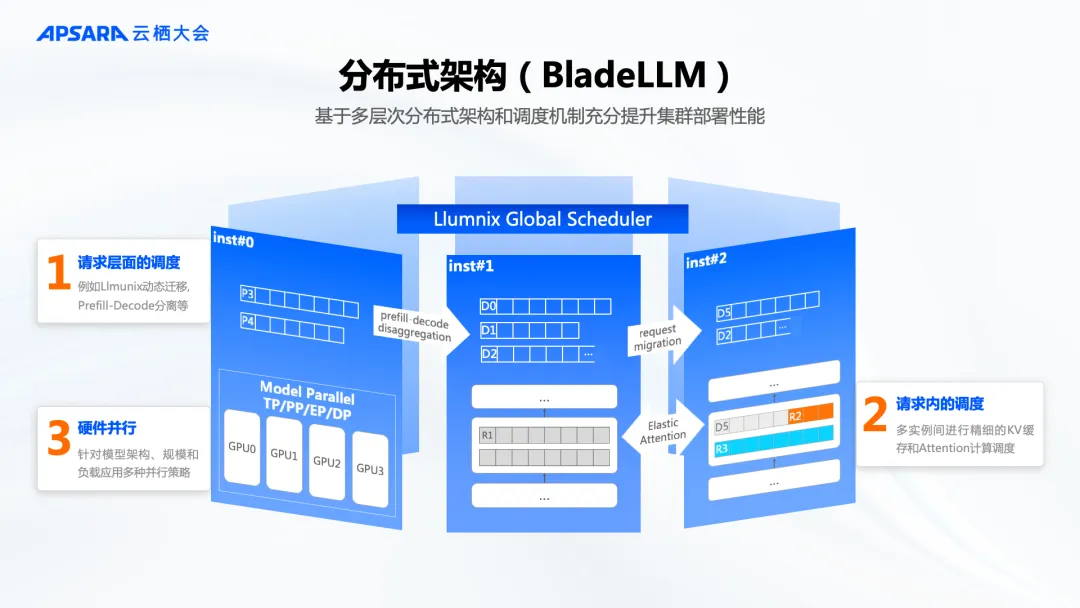
工程层面,PAI-BladeLLM 基于多层次分布式架构和调度机制,进行 Runtime 优化,充分提升集群部署性能,其中最核心的调度优化引擎 Llumnix 的研究论文也被系统顶会 OSDI 2024 收录[4]。
5. 大数据平台和 AI 平台紧密结合
即便拥有好的基础模型、低成本的 AI 计算,缺少应用场景也还是无源之水。过去一年,Github 上模型应用框架的热度持续攀升,像 LlamaIndex、LangChain、Prompt flow。其实模型应用同样会面对很多工程上的挑战。例如 RAG 的场景,从文档向量化到最终返回结果整个链路是很长的,开发人员需要处理不同格式的文档,同时不断地有新文档产生、旧文档订正,最理想的状态是可以实时更新。这些需求其实和我们在大数据平台里遇到的情况是类似的。数据的处理清洗、数据质量的评估反馈、以及实时数据更新和发布,这些大数据平台成熟的能力,和 AI 应用的开发工作只有更加紧密地结合起来,才能推动大模型应用更加高效的落地。
6. 企业化能力
越来越多企业客户在云上微调和使用大模型,模型和数据安全的问题受到更多关注。在数据安全方面,PAI在模型训练、模型微调、模型推理等关键环节都提供数据合规和安全防护能力。在硬件层面,我们也和阿里云基础软件团队、龙蜥社区合作,推出了覆盖硬件到软件层整体的 Confidential AI 机密计算方案。
林伟指出:“从最初服务阿里巴巴集团内部,到今天支撑中国超过半数以上大模型的训练和服务,人工智能平台 PAI 历经将近10年的发展,也积累了大量的核心技术,包含调度、编译、分布式、Runtime、场景应用等方面。”
PAI Prime 是 PAI 提供的覆盖 AI Infra 和应用全场景的工程优化技术栈,致力于提高 AI 训练推理的速度、稳定性和易用性,并且推动 AI 更好地应用落地。

二、人工智能平台 PAI 产品年度发布
阿里云智能集团资深产品专家、阿里云人工智能平台 PAI 产品负责人黄博远带来了人工智能平台 PAI 在模型推理、训练、开发、安全可信等多个方面的重磅发布。

1. 面向 GenAI 时代的推理服务
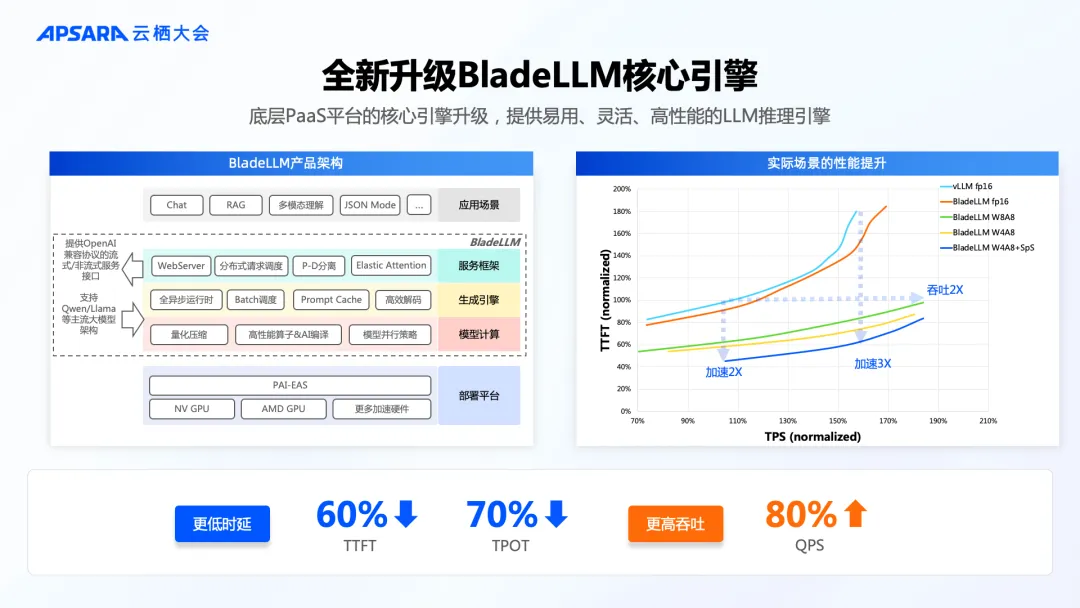
顺应 GenAI 应用爆发带来的模型推理新特点,人工智能平台 PAI 全面升级 PAI-EAS 推理服务模块。PAI 内置推理优化引擎 BladeLLM,综合 BlaDNN 高性能算子、量化、 PD 分离的分布式推理、Prompt cache 缓存优化等技术,能有效降低首包时延 (TTFT) 60%以上、降低 token 输出时延 (TPOT) 70%以上、提升推理吞吐80%以上。
结合 LLM 推理负载感知智能路由和专属网关,PAI-EAS 能根据实时业务负载和资源类型灵活调度,将推理任务动态分发至遍布全球的推理集群进行计算。
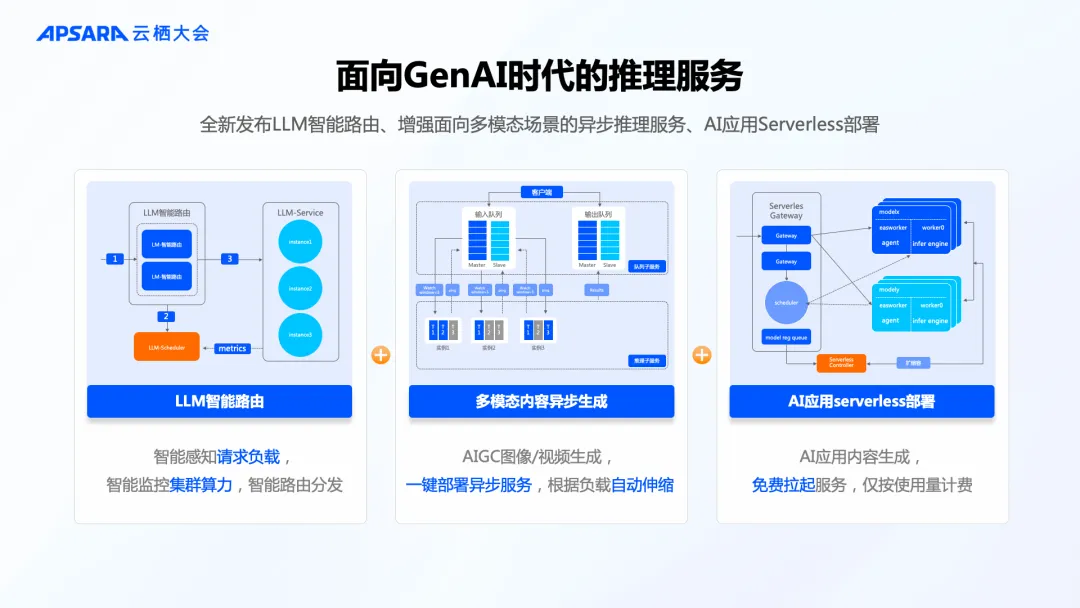
目前,PAI-EAS 模型在线服务平台在全球范围内16个 Region 提供服务,集群规模超过10万卡量级,能提供更加贴近终端用户的计算服务。
2. 稳定高效的云上 AI 训练服务
在模型训练方面,人工智能平台 PAI 重点增强了集群调度优化的能力,保障训练任务的性能和稳定性。
为了进一步提高计算资源利用率,PAI 正式发布 AI Scheduler 训推一体调度引擎,具备异构算力混合调度、多级 Quota 管理、任务形态混合调度、任务无感切换等能力,可保障集群任务满载,提升利用率。
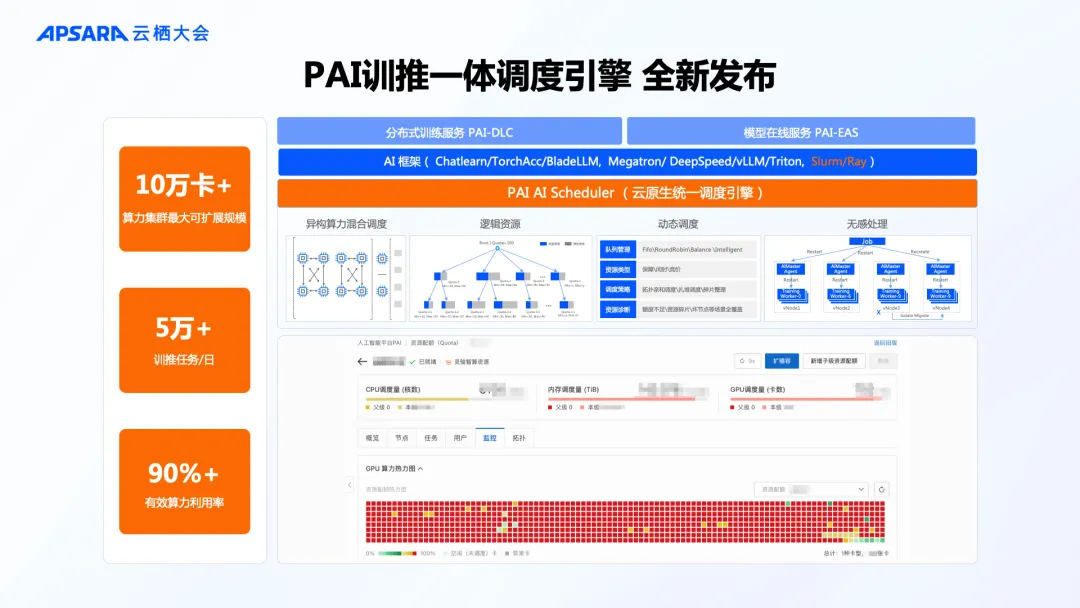
针对时延不敏感的训练任务和探索期业务,PAI 训练服务全新推出竞价任务模式,提供任务级别的高可用、高性价比算力,结合 PAI 平台的自动容错和状态恢复能力,兼顾性价比和稳定性。

在训练稳定性方面,推出全维度监控、主动侦测、自动容错全方位的支撑。

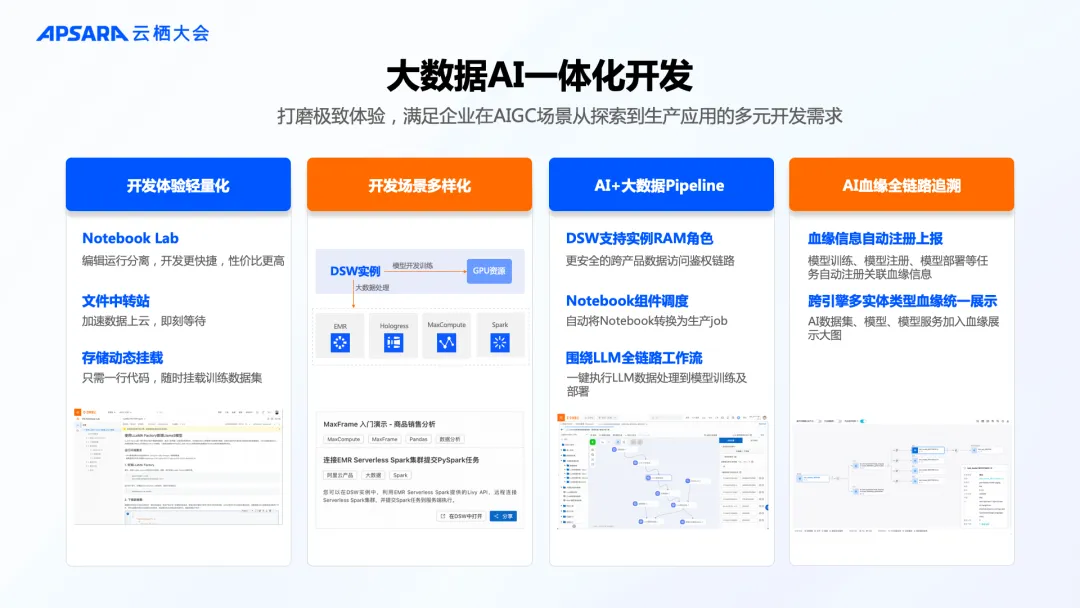
3. 大数据 AI 一体、自带最佳实践的 AI 开发平台
数据是 AI 的基石。尤其当大模型能力从研究走向产业落地,数据质量影响模型和应用效果,数据价值更加受到关注。PAI 构建了 AI 数据资产全链路增加的数据服务体系,具备全生命周期数据管理、多模态数据清洗、多模态数据分析、智能化数据标注和增强等能力,并提供全局的模型和数据血缘追溯能力。
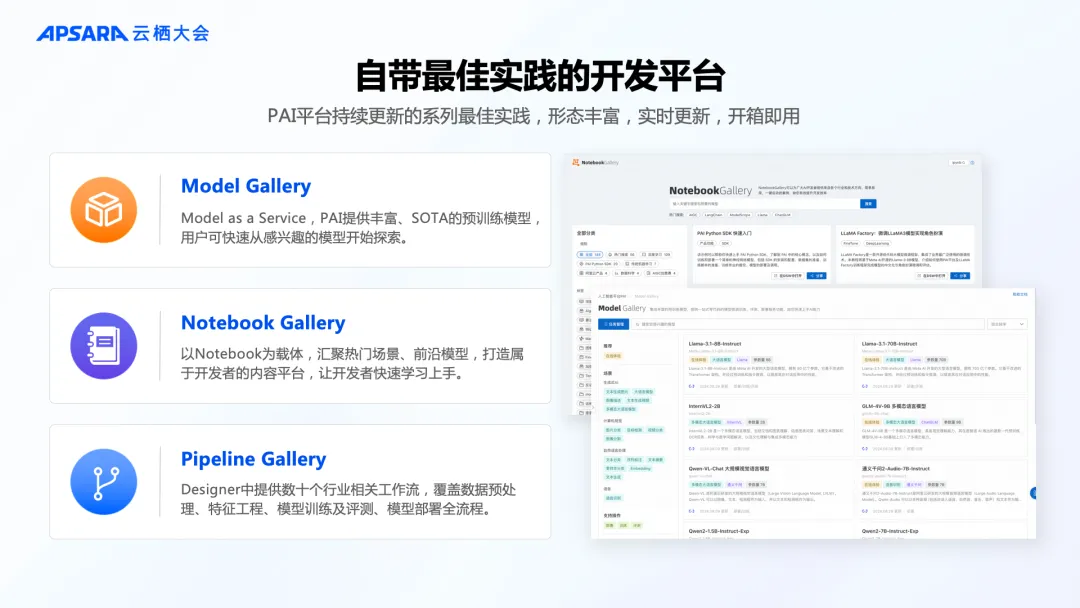
PAI 平台持续积累和更新各种应用场景的最佳实践,并通过模型、Notebook、Pipeline工作流等不同的载体开放,供开发者快速调用。
为了进一步降低 AI 开发门槛,PAI 推出了 QuickStart 和 ArtLab 平台,分别面向 LLMOps 场景和 AIGC 开发场景提供低代码化的工具链。
4. 全新发布可信 AI 系列能力
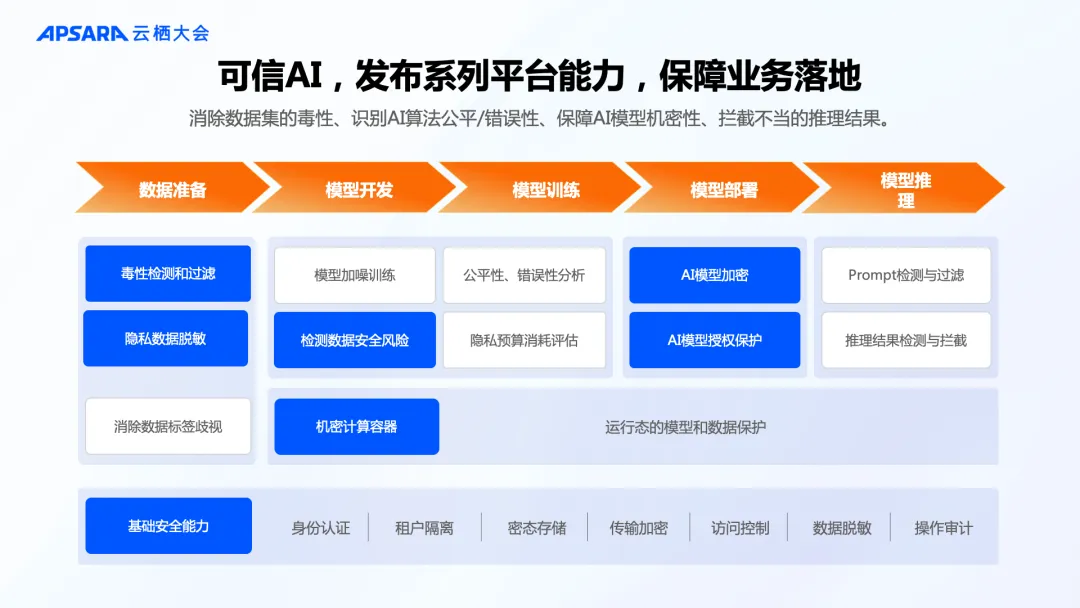
大模型能力不断进化,也引发了对于模型安全的担忧。人工智能平台 PAI 推出可信 AI 模块,具备毒性数据清洗、算法公平性/错误性识别、机密计算容器、不当推理内容拦截等功能,保障模型和数据安全。
5. 全方位升级企业级能力
面向企业级客户,PAI 平台提供全方位的企业级能力,能高效解决企业内部 AI 计算资源、开发人员、权限、AI 资产之间的关系,创建生产级的高质量模型及应用。
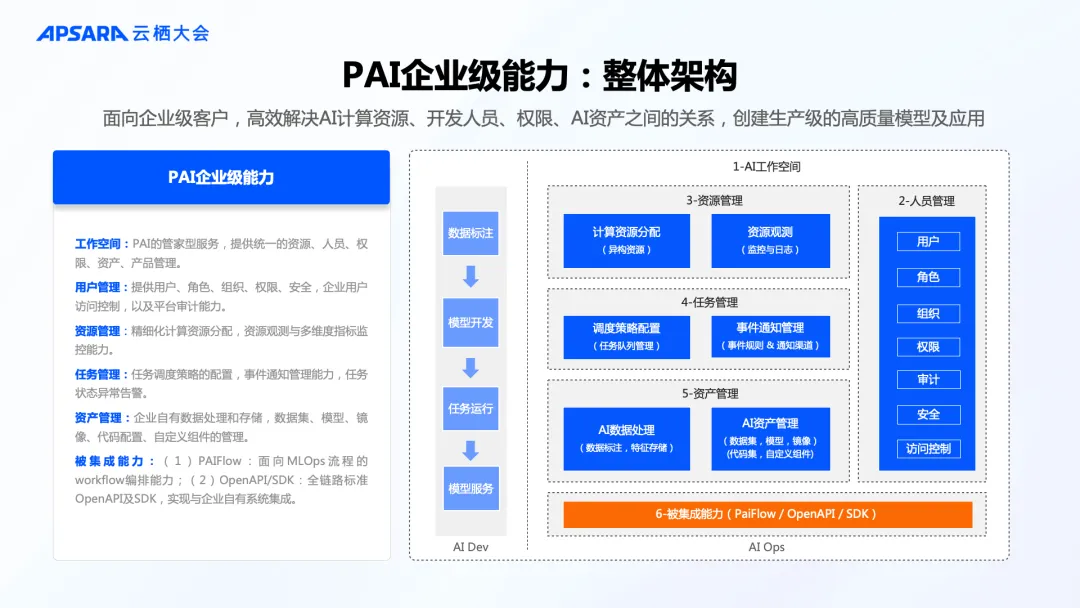
黄博远指出,“人工智能平台 PAI 是面向企业客户及开发者的一站式模型开发平台,无缝连接云上模型训练服务及模型推理服务。在上层通过模型开发和构建的平台连接了开发者们和底层云上的资源,高效使用云上昂贵 GPU 资源。PAI 平台持续进化迭代,为云上 AI 创新提供坚实保障,希望企业和开发者能以最低的成本做 AI、用 AI,让所有人都能用上最先进的大模型。”
注释:
[1] PAI-Megatron-Patch
项目开源地址:GitHub - alibaba/Pai-Megatron-Patch: The official repo of Pai-Megatron-Patch for LLM & VLM large scale training developed by Alibaba Cloud.
GTC 2024 大会分享:基于 NVIDIA Megatron Core 的 MoE LLM 实现和训练优化 | GTC 24 2024 | NVIDIA On-Demand
[2] TorchAcc: A TorchXLA enabled Distributed Training Framework
https://www.youtube.com/watch?v=4ng1ql1sPPs
[3]ChatLearn
项目开源地址:GitHub - alibaba/ChatLearn
[4] Llumnix: Dynamic Scheduling for Large Language Model Serving
论文地址:Llumnix: Dynamic Scheduling for Large Language Model Serving | USENIX
项目开源地址:GitHub - AlibabaPAI/llumnix: Efficient and easy multi-instance LLM serving