【CSDN 编者按】自去年苹果自研 M1 芯片发布之后,激发了无数用户的体验热情,与此同时,也吸引大批开发者在 M1 上开启探索模式。其中,国外一位资深操作系统移植专家 Hector Martin 发起了一项名为「Asahi Linux」项目,通过众筹的方式为苹果 M1 系列新机移植 Linux 系统。
当前,这一项目自启动至今已有 2 个月的时间,Martin 也在 Asahi Linux 官网上最新发布了移植进展及首份报告,面对整个尝试的过程,该份报告指出,“让 M1 支持 Linux 真的太难了!”
接下来,让我们将共同通过这份报告,快速了解移植 Linux 的痛点所在!
作者 | AsahiLinux.org
译者 | 弯月
出品 | CSDN(ID:CSDNnews)
以下为译文:
欢迎各位阅读我们的第一份《Asahi Linux 进度报告》!文本将向你播报该项目的最新进展的。
支持新型的 Linux 系统芯片绝非易事!我们希望通过本文,各位能够了解为了让 Linux 在新设备上运行,我们在幕后付出的艰辛。
术语说明
在这篇报告中,我们会提到一系列的术语:AArch64、ARM64 和 ARMv8-A。
-
AArch64 指的是 64 位 ARM 体系结构指令集;
-
ARM64 是 Linux 为 64 位 ARM 提供的支持;
-
ARMv8-A 是包含 AArch64 的 ARM CPU 体系结构规范。
这些术语的含义略有不同,但是在文本中,你可以将它们全部理解为“ 64位ARM”。

项目的起始
Asahi Linux 项目于今年年初正式启动,但当时我们都在等待一个关键的部分:在苹果芯片系统上引导其他内核的支持。虽然该功能早已进入开发文档,而且大部分都已实现,但还缺少最后一个关键部分:对于 kmutil configure-boot命令的支持,只有通过这个命令才能安装非苹果内核。但这个问题未能阻止我们前进,为了将操作系统移植到一个没有文档记录的平台,第一步要做的就是建立文档记录!
搭载苹果芯片 Macs 的启动方式与传统 PC 完全不同。它的工作方式更类似于嵌入式平台(比如安卓手机,iOS 设备等),但是引入了许多特别的机制。然而,苹果已经采取了一些措施,让启动过程更贴近英特尔芯片的 Mac 操作系统,因此人们对实际的运转方式充满了困惑。例如,根据传统的经验来看,搭载苹果芯片的 Mac根本不能通过外的存储启动。搭载苹果芯片 Mac 的引导程序也无法显示图形用户界面,并且“引导程序选择器”实际上是一个全屏的 macOS 应用,而不是引导程序的一部分。
因此,为了在这些计算机上运行自己的内核,首先我们必须确认启动过程的工作方式,内部 SSD 上分区和卷的布局方式,并找出与 PC 的区别。该文档不仅对我们的项目有帮助,而且也可以作为希望更好地了解计算机工作原理的所有 macOS 用户的参考文档。
2021年2月版的《苹果平台安全指南》(https://support.apple.com/en-ca/guide/security/welcome/web)中记载了部分功能及其基本原理。

连接两个世界的桥梁
搭载苹果芯片的 Mac 启动过程没有遵循任何现有标准。它是定制的苹果机制,从 iOS 设备的早期阶段慢慢发展起来的。
而在苹果之外,64 位 ARM 世界基本上可以分成两大互相竞争的标准:UEFI + ACPI(主要在运行Windows或Linux的服务器上使用)和 ARM64 Linux 引导协议+ 设备树(在小型系统上使用,并得到了U-Boot等的支持)。我们需要为Asahi Linux 选择其中一种标准,并找到一种方法在苹果和我们的世界之间架起桥梁。
UEFI 和 ACPI 是非常复杂的庞然大物,通常仅适用于大型 ARM 系统。这些标准主要由 UEFII 论坛的委员会控制。x86 PC 世界比较单一,但 ARM 世界则极为多样化,系统芯片拥有各种各样的设计,为的是满足其上硬件的不同要求。因此,如果想增加对新 SoC 的支持,则必须修改这些标准,给那些特殊的硬件添加“绑定”。对于 ACPI 而言,这项工作既昂贵又缓慢,这就是为什么 ACPI 几乎从来不在 Windows 以外的小型嵌入式系统上使用。对于我们来说,这个选择行不通。
各种各样的小型嵌入式 ARM Linux 系统几乎都采用了设备树(DeviceTree)标准,比如大多数安卓设备的启动都采用了这种方式。设备树比 ACPI 简单得多,因为设备树纯粹是一堆描述硬件的数据,而 ACPI 表则结合了数据和代码。如今,设备树绑定的权威是 Linux 内核树内部维护的文档,这意味着我们可以在编写Linux驱动程序本身的同时,修改这些标准。因此,Asahi Linux 的启动过程也采用了这种模型。
有意思的是,苹果针对苹果芯片的设备建立了苹果版的设备树,名叫苹果设备树(Apple Device Tree)!这是因为苹果和开放的设备树标准都建立在开放固件规范(包括旧款 Mac 在内的许多 PowerPC 系统都采用了该规范)之上。不幸的是,尽管这意味着 ADT 对于嵌入式 Linux 开发人员来说并不陌生,但我们还是不能直接使用它们,原因在于二进制格式不同,而且如果没有关于数据含义的高级信息,两种格式之间就无法自动转换。而在规范之上,各个设备的实际绑定完全不一样。虽然 Linux 和 macOS 在 PowerPC Mac 上的工作方式相同,并且可以兼容,但 Linux 和苹果在 ARM 领域已经分别发展了十多年。试图统一苹果和 Linux 处理设备树的方式将是一场噩梦。
为了让苹果使用设备树,我们正在开发 m1n1,这是一款苹果芯片电脑的引导程序。它的目标是尽可能多地处理“苹果风格”的东西,减轻 Linux 或其他下游产品的负担。
你可以将 m1n1 添加到 Linux 内核的前面(对于最简单的固定内核,只需要运行cat m1n1.macho initrd.bin devicetree.dtb Image.gz > m1n1-kernel.macho即可),然后使用苹果的工具 kmutil 将其安装到 Mac 上,它就会负责启动 Linux 所需的一切处理。使用 m1n1 引导 Linux 的大致过程如下:
-
初始化主 CPU,并应用 chicken bit 设置,使其正常工作。
-
读取苹果引导加载程序 iBoot 提供给它的引导信息:其中包括可用的内存量以及内存帧缓冲区(屏幕上显示的视频的内存)的地址。
-
初始化内存管理单元。为了能够使用 CPU 缓存,这一步是必需的,否则,一切运行速度都会非常慢。
-
在屏幕上显示 Asahi Linux 的标志,代替苹果的标志。
-
禁用 watchdog timer。如果没有这一步,Mac 会在大约一分钟后自发重启,因为它以为启动过程被卡住了。
-
找出需要启动的程序:Linux 内核、设备树以及(可选的)包含启动时应用程序的 initramfs ramdisk(如果已将它们附加到启动时的话)。
-
初始化所有其他 CPU 核心,并应用必要的 chicken bit,然后让它们在“旋转表”中等待 Linux 的接管。
-
从苹果的设备树中获取信息,并修改设备树模板,使二者匹配。这一步是为了修改不同的计算机以及苹果 iBoot 固件不同版本的设置,例如内存大小、有关帧缓冲区的信息、初始化 Linux 随机数生成器的种子等。此外, m1n1 还添加了一些自己的信息,例如旋转表的详细信息以及内核的命令行参数(视情况而定)。
-
跳转到 Linux,或下一步。
“旋转表”(spin-table)是 ARM 版 Linux 在设备树的世界中启动额外的 CPU核心的两种标准之一。不依赖于平台特定的驱动的标准方法有两种,所有平台都要使用两者之一。最简单的一种叫做旋转表,其做法是让引导程序事先启用所有CPU 核心,然后让它们在一个循环中等待(叫做“旋转”)。为了从循环中释放CPU,Linux 需要向内存写入一个值,告诉 CPU 从何处跳转到内核。对于简单的平台来说这完全没问题,唯一的限制就是没有办法完全停止 CPU,因为从引导程序中接管 CPU 是一次性的。不过可以通过其他机制让 CPU 进入各种省电模式。我们目前采用了这种方式,有可能以后也会一直延续下去。
另一种方法叫做“PSCI”,这是一个 ARM 标准,是系统固件提供的服务,即使在Linux运行时,也可以利用它同时控制所有 CPU。通常,该操作需要运行在 “EL3”(即安全固件,又称TrustZone)上的代码来实现,或者通过运行在“EL2”上的虚拟机监控程序来实现。而操作系统通常运行在 EL1 上。但是,在ARMv8-A 的 CPU 中,EL3和EL2都是可选的,而且事实证明 M1 并不支持EL3。M1支持EL2,但是我们希望能在Linux下运行虚拟机,这就要求 Linux 本身需要运行在 EL2 中,因此没办法在 EL2 中运行一个监控程序。这就意味着我们现在还不能使用 PSCI,因为 PSCI 的标准接口不满足我们的需求。以后也许能够出现其他标准方法。也许,只有采用其他方法,才能支持整个系统的睡眠功能,尽管如果细粒度的电源管理足够好的话,我们也许不需要“真正”的全系统睡眠模式,就能获得不错的待机时间(现代设备对于更细粒度的睡眠模式的支持非常好)。不过这个领域仍然在发展,所以只能拭目以待了。
虽然我说过我们要使用设备树,但这并不意味着我们不能使用 UEFI!ARM64系统能够同时使用 UEFI 和设备树进行引导,而且只有这样做,才能像 PC 那样通过 GRUB 等引导程序和通用的流程安装和升级内核。但是 m1n1 并不支持这样做,那么怎么办呢?幸好还有其他途径:U-Boot。U-Boot 可以像 Linux 内核一样引导,所以只需从 m1n1 中引导 U-Boot,然后 U-Boot 就可以为GRUB 和 Linux 提供良好的 UEFI 环境。
因此,最终 Asahi Linux 的引导链大致如下:
m1n1 → U-Boot → GRUB → Linux
结合苹果特有的引导链,整个引导过程大致如下:
-
在冷启动时,M1芯片内的 SecureROM 启动,并从NOR闪存中加载iBoot1。
-
iBoot1 读取内置 SSD 中的引导配置,验证系统引导策略,然后选择一个“操作系统”进行引导。在我们看来,Asahi Linux / m1n1 对于 iBoot1而言就像一个操作系统分区。
-
iBoot2(操作系统引导程序,它需要位于被引导的操作系统分区内)加载固件供内置设备使用,设置苹果设备树(ADT),并引导一个 Mach-O 内核(对于我们,就是m1n1)。
-
m1n1 解析 ADT,配置更多设备,让整个环境更像 Linux,然后设置 FDT(展平后的设备树,即二进制格式的设备树),然后引导 U-Boot。
-
U-Boot(其驱动程序位于内置SSD中)读取其配置和下一阶段的代码,然后提供UEFI服务(其中包括转发来自m1n1的设备树)。
-
GRUB作为标准的UEFI应用,从磁盘分区中引导,就像 PC 上的 GRUB 一样。有了 GRUB,Linux 发行版就可以通过惯常的方式,使用 grub-mkconfig 和 /etc/default/grub 等管理内核。
-
最后,引导 Linux 内核,所需的信息由从 m1n1 传过来的设备树提供。
对于习惯了 PC 的人来说,这个过程可能有点不可思议,但在嵌入式系统中,这种很长的引导链是十分常见的(而且实际上,即使在普通的 PC 上,UEFI 也包含多个阶段,只不过最终用户看不到而已)。例如,DragonBoard 410c(一款基于高通的平台)的引导链可能如下:
PBL→SBL→QSEE→QHEE→LK→U-Boot→GRUB→Linux
注意,我们没办法替换 iBoot2(它需要苹果的签名),但最终用户的安装过程会自动设置一个最小化的“macOS”,其中包含 iBoot2 和所有必须的支持文件,为的就是解决这个问题。这些足够让苹果的引导过程将其识别为可引导的OS(只不过没有真正的macOS内核和文件系统)。我们还没有实现安装程序,所以目前开发人员只能通过先整安装 macOS,再替换内核的方式来尝试 m1n1和LInux。我们编写了一个手把手的快速入门指南(https://github.com/AsahiLinux/docs/wiki/Developer-Quickstart),供想尝鲜的人使用。
目前,我们主要的开发工作是从直接 m1n1 中加载 Linux,不过 Mark Kettenis 在负责 U-Boot 和 OpenBSD 的支持工作。
但是 m1n1 不仅仅是运行 Linux。实际上,它本身甚至不是引导程序!

处理硬件问题
m1n1 诞生于 mini,后者是我为任天堂 Wii 的安全 CPU 编写的一个最小化环境。它很适合拿来做各种试验,以及作为 BootMii 的后端。如果你手里有Wii,而且还听说过 BootMii,那么当你在 BootMii 的菜单中时,ARM CPU上运行的就是 mini。
那么,这跟苹果芯片上的引导程序有什么关系呢?实际上,mini 只不过是在32位裸金属 ARM 系统上运行的一个非常简单的软件,不包含任何外部库和依赖。因此,它非常适合构建裸金属代码,于是我们将其移植到了 AArch64 和苹果芯片上,并改名为 m1n1。但更重要的是,mini 和 m1n1 都有一个秘密武器:由于 mini 作为固件在一个单独的处理器上运行,而这个处理器需要主 CPU 负责控制,而且根据以前针对 Wii 的硬件研究成果,mini 内置了一个 RPC 代理,可以通过串口访问。这就意味着你可以从一台开发计算机上对 mini 和m1n1进行“远程控制”,甚至可以从交互式的shell中进行(https://github.com/AsahiLinux/docs/wiki/Developer-Quickstart#playground-shell)。所以更恰当的描述是,m1n1 是一个硬件实验工具,恰好能作为 Linux 引导程序使用。
所以说,这个平台特别适合硬件学习,而且适合寻找苹果的私有特征。例如,
-
这段脚本(https://github.com/AsahiLinux/m1n1/blob/main/proxyclient/fptest.py)测试了一个特殊的苹果特性:给 CPU 添加一些 x86 专有的浮点配置比特,用于加速 Rosetta x86 模拟。
-
这个脚本(https://github.com/AsahiLinux/m1n1/blob/main/proxyclient/find_all_regs.py)能够搜索所有苹果定制的 CPU 寄存器,并输出它们的值和访问限制。
-
这个脚本(https://github.com/AsahiLinux/m1n1/blob/main/proxyclient/hacr_trap_bits.py)能够自动找出怎样通过苹果专有的监控程序配置寄存器来实施这些访问限制。
-
当然,还有这个脚本(https://github.com/AsahiLinux/m1n1/blob/main/proxyclient/linux.py)能够引导Linux内核,并通过串口输出。
将一台 M1 Mac Mini 引导至 m1n1 需要大约 7 秒,而且所有这些脚本都可以交互式运行,无需重启(除非你把机器搞崩溃了)。m1n1 还能加载自身,所以 m1n1 的开发周期非常快:只需用 kmutil 安装一次 m1n1,以后重启后只需加载最新的 m1n1 即可。
我们使用 m1n1 为苹果的自定义 ARM 指令集、苹果专用的系统寄存器以及苹果中断控制器等硬件建立了文档。
以后,我们会继续给 m1n1 添加更多特性,让它成为更强大的研究工具。其中一个特别激动人心的目标就是,将其变成一个非常薄的虚拟机监控程序,能够启动 macOS,并拦截 macOS 对于 M1 硬件的访问。如此一来,我们无需反编译,就能调查苹果的驱动程序的工作方式,还能通过合法的渠道进行调查,而且比跟踪复杂的私有驱动程序的代码效率高很多。一些人可能知道这种方法,因为之前 nouveau 就成功地通过此方法,对 NVidia 的 GPU 进行了逆向工程,但当时他们使用的是 Linux 驱动程序,而且只修改了内核,没有采用虚拟机监控程序。
但是等一下,这一切都需要串口。但是 M1 的 Mac 哪儿有串口?好问题!

UART 登场!
对于新系统的底层开发,串口几乎是不可避免的。串口(有时也称为UART端口)是最简单的通信硬件,对于底层调试工具来说非常方便。通过串口发送消息只需要几条 CPU 指令,所以我们在非常早期就可以建立串口通信,作为开发的文本终端使用。
当然,现代 PC 曾经有过 RS-232 串口,但那些都是过去了。在许多嵌入式系统(如绝大多数家用路由器)的内部依然有低电压串口,但需要拆开外壳才能连接,或者是直接位于主板上的测试点。那么 M1 Macs 是什么情况呢?
事实证明,M1 Mac 的确有一个串口,而且不需要拆机就能访问——通过某个USB-C口!但是要想启用串口,在必须通过 USB-PD 发送某些特殊的命令。USB-PD(USB供电)是 Type C 端口上的一种协议,使用“配置频道(Configuration Channel)”针脚。按照 USB 标准的一贯作风,它在工程上的设计也有点过,实际能完成的工作远不止供电——它不仅能用于配置电压、识别充电器,还能用于识别线材、识别适配器、切换模式(如DisplayPort),在这里还被作为一个频道,发送苹果专属的配置消息。这些消息可以让Mac将其串口暴露在某个特定的 Type C 端口的两个针脚上。其他的便利功能还有远程重启系统(对于快速开发来说是必不可少的),切换成 DFU 恢复模式,访问 I2C 之类的内部总线,等等。
我们的第一个启用串口的解决方案是vdmtool(https://github.com/AsahiLinux/vdmtool)。这套工具包括一根使用Arduino的自制电缆,一片USB-PD PHY(接口)芯片,还有一些 1.2V 的串口适配器。虽然这些东西只需要一点 DIY 技能就可以自制,但对于没有制作硬件经验的人来说并不是太现实。制作过程有许多麻烦:市面上没有能支持所有必须的Type C 信号的 USB-PD PHY 电路板,1.2V UART适配器也非常罕见,等等。
因此,我们想出了第二个解决方案:如果你正好有两台 M1 Macs,那就完美了!你只需要一根Type C线(SuperSpeed / USB 3.0)和 macvdmtool(https://github.com/AsahiLinux/macvdmtool)。这个 macOS 上的小应用可以将一台 M1 机器变成另一台的串口调试终端,这样你就可以运行 m1n1 脚本,并从 macOS 直接引导 Linux 内核了。苹果的 API 可以将 Mac 自己的端口配置成串口模式,还可以发送必要的消息,将远程 Mac 配置成串口模式,这样不需要自定义硬件就可以实现这一切。
但是,当然将另一台 Mac 作为串口线,这条线可够贵的!因此,我们会以开源硬件的方式开发一种功能完整的 USB-PD 调试线,不仅可以作为 M1 Mac 的串口适配器,还可以开放一些其他功能。实际上,这根线的用途甚至能超过Mac,作为其他设备的调试接口,比如许多 Android 手机。它还能作为一个USB-PD 开发平台,作为通用的供电源或负载,用于研究 USB-PD 充电器和设备。该项目还在计划阶段,但请关注后续更新!我们的最终目标是将其开放给整个社区,这样任何人只需要点击一个按钮度就可以买到。
最后,尽管硬件串口是底层调试和开发的最佳方案,但是它也有局限性:速度非常慢,最快只有 150kB/s。但是 M1 Mac 还可以作为普通的 USB 设备使用(就像 iPhone 一样),我们可以将它作为USB串口设备(CDC-ACM),在绝大多数操作系统上,这种设备无需驱动就可以使用。这样就能提供 USB 的全部带宽,而且可以使用正常的 Type C 线(或Type C到Type A转接线)连接到任何电脑。USB 还提供了流控制,因此即使接收端没有准备好接受数据,也不至于丢失数据。这种方式的缺点是,它需要更复杂的驱动代码,所以不适合调试非常底层的问题。但只要能得到 m1n1 的支持,就足以进行任何后续的工作,而且我们可以使用已有的串口支持很方便地开发更复杂的驱动代码,因为这些Mac 上的 Type C 接口可以同时传输 UART 串口和 USB 的信号。额外的带宽和性能对于上面提到的监控程序的开发非常有帮助,而且还能加快加载 Linux 内核的速度,因为目前内核加载受到了串口带宽的限制。预计接下来几个星期内m1n1 就会支持该功能,敬请期待!

通向企鹅之路
所有这些工具都很好,但毕竟我们的目标是运行 Linux。那么,怎样将 Linux 移植到一个全新的平台上?当然,在整个过程中,很大一部分需要编写新的驱动程序,但有一些事情需要先完成。我们管这些事情叫做“铺路”。
铺路非常重要,不仅因为它是在机器上运行操作系统所需的其他工作的基础,而且因为它需要为机器特有的特性的工作方式设置标准。它是紧密联系操作系统最深处的一些底层代码,而且与一般的驱动程序不同,它通常需要修改 Linux 中各个平台共通的部分。这就需要与负责相应的子系统的 Linux 维护者们协调,并找出所有人都同意的解决方式。
这里面的水非常深。在最初的M1支持补丁中,我们需要更改一个与 SPARC64架构支持相关的文件!Linux 开发的一个独特的特性是,Linux 内核没有稳定的驱动 API/ABI,因此 Linux 内核的内部设计一直在持续改进和重构。这就是说,如果在某个架构上支持的某个功能需要修改其他架构,那么这种修改是完全可行的,而且通常都被视为正确的做法。但这也意味着维护 Linux 的分叉或不属于上游内核的第三方驱动变得非常困难。
Asahi Linux 的目标不仅是将 Linux 移植到苹果芯片上,而且还要以开源社区驱动项目的形式进行,与整个 Linux 社区合作,将我们的工作推送到官方的Linux 内核中。在嵌入式 ARM 的领域中,这种方式非常罕见,因为绝大多数开发 Linux 移植版的公司都在忙于应付最终期限,所以他们会创建一个 Linux 分叉,然后在上面进行所有开发,完全脱离了上游的社区。等到他们想把修改合并到官方Linux内核中时,通常由于两个分叉分别开发的时间过久,因此导致合并的难度非常高。其设计决策也可能与 Linux 的哲学背道而驰,从而无法被上游接受。最终,许多代码只能重写,只追求短期结果而忽视长期可维持性的做法导致许多开发时间白白浪费。
我们不想重蹈覆辙,所以我们的方法就是尽可能早地合并到上游,并从第一天开始就与整个社区合作。因此,我们已经与上游 Linux 维护者一起工作,而且有好几个 Linux 的关键开发人员都在我们的 Asahi Linux 的 IRC 频道中!
为了确保可以在任何系统上引导 Linux,有五项工作必须完成:
-
CPU
-
内存管理单元(MMU)
-
中断控制器
-
系统时钟
-
某种控制台,在这里是串口控制台
在绝大多数 AArch64 系统中,前四个非常标准:Linux 不需要任何改动就能运行到启动基本的控制台这一步。话虽如此,但苹果的系统芯片就喜欢我行我素……所以我们还有许多工作要做!

关闭再打开
与八九十年代的设计相比,现代 CPU 是工程上的奇迹。过去,CPU 的工作只不过是执行简单的算术运算、读写内存,以及做决策而已,按照顺序一步步做,从不停顿。没有电源管理,没有缓存,没有多核心,也几乎不支持浮点数。
但时代变了,如今的 CPU 变得越来越强大,消耗的电力也越来越少。这是怎么实现的?一部分要归功于集成电路制造的进步。还有一部分要归功于 CPU 设计方面的巨大进步。现在一个 CPU 的核心就能同时运行多条指令,预测未来并提前执行,如果预测错误就回滚,还能将经常使用的数据或预测即将使用的数据保留下来,甚至可以动态的将一部分 CPU 打开或关闭以节省电力。
但是,如此复杂的设计带来了两个问题:预料之外的特性,以及 bug。现在的操作系统需要更多地对 CPU 的细节进行微管理,甚至连应用程序软件都需要注意,不要对CPU做出不实际的假设。
从九十年代就开始使用计算机的人可能还记得 Windows 95 和 Windows 98。我们无法在新的电脑上使用这些操作系统,因为CPU的温度会迅速上升,而且会持续保持高温,即使电脑几乎没有运转也是一样。原因就在于,这些操作系统在无所事事时也会让 CPU 运行一个无限的循环。因此,即使无所事事,CPU 也是 100% 处于“使用中”的 状态!旧的 CPU 没有“闲置”的状态:如果没有工作可做,就会浪费掉。没有电源管理,所以即使无所事事也不会省电。
当然,现在我们都已经习惯了闲置的 CPU 能够省电。操作系统在无所事事时会告诉 CPU 在某种程度上停止工作,然后等待一个事件(由外界发送的、表示需要开始工作的事件)。在 x86 PC 上,这一操作由 HLT(停机)指令负责;在Windows 95 时代,曾经有一个叫做“Cpuidle”的软件,能够在无限循环中运行HLT,在没有工作时将 CPU 转入低功耗模式,从而节约电力并降低 CPU 温度。现代操作系统已经内置了该功能,而且 ARM 的 CPU 也实现了同样的机制,指令名为“WFI”,意为“等待中断”(Wait For Interrupt)。
现代 CPU 在调用 HLT 或 WFI 时不仅会停止运行指令,还会关闭一部分核心的供电,以节省更多的电力。停止时钟的技术叫做“clock-gating”,断电的技术叫做“power-gating”。但是这样做是有代价的:power-gating 会导致 CPU丢失数据。关键的数据必须保持在有电的电路中,或者移动到有电的备份存储中。正常情况下,这些指令不会导致可见的数据丢失,CPU 可能会丢弃一些不再需要的数据,但会保证不丢失软件正常工作所需的数据。
当我们几乎在 M1 上成功引导 Linux 时,出现了一个问题:每次引导过程即将结束时就会立即崩溃。实际上,它似乎是在执行完 WFI 指令之后崩溃的:它跳转到了一个零地址,而没有者却返回到调用函数。为什么?
我们发现,M1 的默认运行模式中,WFI 可以做两件事情:或者是 clock-gate,或者是 power-gate。实际上,它会根据某种启发式的方法来决定执行哪种。不幸的是,当它决定执行 power-gate 时,CPU 就会丢失所有寄存器的内容,除了栈指针和指令计数器之外。Linux 并没有预料到这件事情发生。因此,我们只能添加一个非常丑陋的补丁,因为任何其他 AArch64 的 CPU 都不会这样做,Linux 也没有任何机制能针对特定的系统芯片替换WFI闲置循环。因此只能在通用的 Linux 代码中针对特定的 CPU 进行处理。
不过,多亏了我们给 CPU 中的苹果专有寄存器建立了文档,并且记录了 CPU正常工作所需的 chicken bit 序列,我们发现有一个特殊的寄存器可以用来覆盖该行为,保证WFI永远不会执行 power-gate,从而让 Linux 正常运行。我们只需要在 m1n1 中将该寄存器设置为正确的值,就能解决问题!这是最好的修复:m1n1 负责处理问题,因此不需要对 Linux 打补丁。
你也许想问,这样做会不会影响系统的功耗。不要怕!这并不意味着无法使用M1 的 power-gating 功能。Linux 通过一个名为 cpuidle 的子系统支持更深层次的CPU省电模式。Linux 可以通过该子系统,将 CPU 设置成更深层的省电模式,而该子系统的驱动程序能完美地保证在 CPU 丢失信息后能正确恢复信息。因此,我们需要做的就是编写一个 cpuidle 驱动,将 M1 改回 power-gating 模式(如果 Linux 的内部算法更好的话,也许我们可以跳过 M1 的启发式算法),直接在驱动程序中执行WFI,然后在返回核心 Linux 代码之前恢复 CPU 的数据。通过Linux的方法管理 CPU 省电。
这也展示了我们的开发过程中一个非常重要的部分。在处理没有文档的设备时,最简单的方法就是保留原有软件(macOS)的做法。但是,其他操作系统或固件的做法也许并不适合 Linux。因此,我们要首先理解系统的优点,然后才能决定哪种方法最适合 Linux。如果我们简单地照搬macOS的做法(在主CPU闲置循环中支持 power gating 模式),却没有研究相关的 CPU 寄存器,就会给Linux 打一个非常丑陋的补丁,而错过这种干净的解决方法。后者的确需要更多时间,但我们认为这样做是值得的!
这并不是 CPU 给我们带来的唯一惊喜,不过其余的话题就以后再说吧。下面我们来讨论下一个话题:内存管理。

投递失败的信退回给发信人
在这个项目刚刚开始的时候,能够尽早获得引导过程的反馈,对于调试是非常重要的(我们没有硬件调试功能,苹果的设备并没有提供这些功能)。前面提到的串口对于调试非常重要,因为它只需要几条 CPU 指令就能发送一个字符:只需要向 UART 硬件的寄存器写入即可。Linux 有个名为 earlycon 的特性很有用,有了它,就能在主串口驱动程序启动之前使用常见的 printk() 函数,但不幸的是,我们的第一批测试并没有走那么远。因此我们只能给 Linux 中最早的ARM64 驱动代码(用汇编编写的)打补丁,以便在特定的点输出字符,来判断哪里出了问题。
事实证明,串口只能在内存管理单元启用之前使用。这很不幸,因为内存管理单元会改变访问内存的方式,包括访问 UART 设备的方式,但这个问题很难调试,因为 MMU 是预先配置好,然后一次性打开的。如果里面出了问题,你很难找到问题在哪儿。
但是,经过了很长一段时间的调试之后(最后我添加了代码,在显示帧缓冲区时使用不同颜色绘制出 Linux 内核的引导过程,作为另一种反馈机制),我们终于证实了 Linux 其实在继续引导,通过了所有汇编代码,已经开始执行 C 代码,甚至进入了 earlycon 串口驱动。但串口没有发回任何数据。看起来似乎它忽略了我们发给它的一切。地址是正确的,内存映射也是正确的,但就是没有任何输出。
最后发现,是由于 M1 对于设备的内存管理非常苛刻。
所有现代操作系统内核的核心都是内存管理单元。它是 CPU 的一部分,负责隔离正在运行的进程、管理虚拟内存(交换文件或交换分区)、将磁盘上的文件映射到内存、在线程和进程之间共享数据等功能。它负责将多个虚拟内存地址空间(应用程序和内核拥有的内存地址的概念)映射到物理地址空间(系统中硬件的实际内存地址)。在这里,“内存”既包括实际的 RAM,也包括作为内存映射 I / O(MMIO)出现的设备。UART 是 MMIO 设备。
在大多数平台上,普通内存和 MMIO 之间是有区别的。我们可以认为,普通内存(即RAM)以某些合理的方式运行,例如在写入数据后再读取,则永远会返回写入的数据。但是使用 MMIO 来接收命令并返回状态和数据的硬件却不一样,所以它们的行为和正常的 RAM 不一样。CPU 可以对内存访问指令进行重新排序和缓存,但如果针对 MMIO 访问进行这些操作,那就会导致一系列问题,因为驱动程序依赖精确地控制何时要发送数据、何时要接收数据。MMU 负责这个区别:内核有一个配置比特,表明内存是普通内存,还是设备内存。
但是,当然,如今这一切都变得复杂得多。有访问权限问题、不同的缓存模式,还有不同类型的设备内存。在 AArch64 上,映射设备内存有四种方式:GRE,nGRE,nGnRE,和nGnRnE。字母 G、RheE 代表系统被允许或不被允许(字母n表示)的三件事情:
-
G(Gather):将多个写操作收集到一个写操作中。例如,CPU 可以将两个相邻的8位写操作合并成一个 16 位写操作。
-
R(Re-order):对写操作重新排序。如果依次向两个相距很远的地址写入,那么CPU可能会用相反的顺序写入。
-
E(Early):提前写入。系统可能会在数据到达目标设备之前就告诉 CPU写入完成,从而让 CPU 继续执行后面的代码。在 x86 的世界中这个操作称为“posted write”。
绝大多数驱动和设备在 G 和 R 启用的情况下都会出问题,所以除了非常特殊的驱动之外,很少有驱动会使用这两个模式。但是,提前写入(E)实际上是 PC 的标准,因为它是 PCI 规范的强制要求。因此,几乎所有驱动都能够处理该操作。鉴于此,AArch64 Linux 会将所有 I/O 内存映射成 nGnRE,同时允许提前终止。这在其他设备上没有问题。许多设备可能并不支持 posted write,但那样的话,它们会简单地将访问当作 nGnRnE 处理。设备可以提供比软件要求更严格的保证,只要设备的行为与软件要求的同样严格,就不会出问题。
我们发现,M1 的内部总线结构会强制所有访问使用 nGnRnE 模式。如果尝试使用 nGnRE 模式,则会放弃写操作,而系统会发出 SError(系统错误)信号。最初由于无意中从另一个项目引入的一个 CPU 配置,它错误地禁用了错误报告功能,我们并没有看到这些 SError。(但即使不是因为这个错误的配置,由于 UART 损坏,我们也无法看到错误, 不过至少会让系统在 UART 写入后停止工作,而不是默默地丢弃它们并继续运行)。
聪明的读者可能注意到了这里的一个有趣的细节:M1 系统芯片具有 PCIe!实际上,某些内部设备是 PCIe 设备(例如 Mac Mini 上的以太网),而且 M1 Mac 可以借助 Thunderbolt 连接到任何 PCIe 设备。难道这些设备不使用posted write 吗?确实,它们的确会使用!实际上,M1 要求 PCI 设备必须使用 nGnRE 映射,同时会拒绝 nGnRnE 写操作。
这带来了一个难题。Linux 没有将内存映射为 nGnRnE 的框架。我们可以引入一个临时补丁,以便在任何地方都使用 nGnRnE(而不是 nGnRE 模式),但是那样就不可能支持需要 nGnRE 的 PCIe 设备。于是,我们针对上游交互展开了第一项测试:我们必须开发一种完全定制的机制,将内存映射为 nGnRnE,然后一种方法指示 Linux 将其用于苹果芯片平台上的非PCI设备,同时仍然允许PCI 驱动程序使用 nGnRE 模式。而且,我们必须以一种干净,精心设计的方式来实现,同时还需要在不破坏现有代码和照顾到其他非苹果设备之间取得平衡,并与负责这些子系统的维护者达成共识。
最后,在与多个子系统和多个补丁修订版的内核维护者进行了数周的讨论之后,我们确定了如下方法:
-
引入ioremap_np()。在所有架构上,通常Linux都会使用通用的ioremap()函数映射 MMIO 设备内存。还有一些不十分严格的其他变种,例如ioremap_wt()。我们添加了一个新的变种,能特别低指定请求 non-posted 内存映射。
-
实现 ioremap_np() 在 ARM64 上使用 nGnRnE 模式(其他架构目前不会实现该模式,尽管这种模式对它们也许也有用。)
-
引入 nonposted-mmio 设备树属性。这也可以用来将设备树中的特定总线标记为需要 ioremap_np()。
-
让 Linux 设备树子系统在查找设备时自动选择 nonposted-mmio模式,并将其变成一个描述MMIO资源结构(IORESOURCE_MEM_NONPOSTED)中的一个标志。
-
编写两个高层 APIdevm_ioremap_resource()和of_iomap(),自动解释该标志,并将其“升级”成一个 ioremap_np()。
-
修改需要在 M1 系统芯片上使用的驱动程序,确保它们调用这些API,而不是调用原始的 ioremap()。
为此,我们需要对直接使用 ioremap() 的驱动程序进行一些重构,但由于只需要针对在M1上构建的硬件进行重构,所以只需要修改几个驱动程序。如今的绝大多数 PCI 驱动都直接调用 ioremap(),而且所有这些都可以通过 Thunderbolt 适配器在M1电脑上使用;因此这些驱动都不需要改动,因为默认的ioremap()依然适用于仍然请求 nGnRE 模式的驱动程序。
在修改的过程中,我们意识到,Linux 缺少有关 ioremap()各种模式的文档,也没有关于 I/O 读写函数的文档。于是,我与 Arnd Bergmann 一起添加了部分缺少的文档(https://github.com/AsahiLinux/linux/blob/upstream-bringup-v3/Documentation/driver-api/device-io.rst#__iomem-pointer-tokens)。
有趣的是,由于这部分改动针对的是通用“简单总线”设备,因此这意味着我们必须将补丁提交给核心设备树规范及其架构。值得庆幸的是,由于设备树是一个开放的社区驱动项目,因此只需提交几个 GitHub PR 即可!

这就是AIC
现代 CPU 的工作不仅是按顺序运行指令,而且还要对环境的变化做出反应,这可能会要求它停止手头的工作,转而去做其他事情。这些通常称为“异常”。你可能已经通过高级编程语言了解了这个概念,通常异常多用于错误处理,但它们在CPU 中也用于指示何时需要外部关注(类似于 POSIX 用户空间程序中的SIGCHLD 和 SIGALRM 之类的信号)。
其中最重要的就是中断请求( interrupt request,IRQ),硬件外设通过该请求来引起 CPU 的注意。然后,CPU 运行一些操作系统代码,确定需要关注哪些外围设备并处理请求。
AArch64 CPU 只有一个 IRQ 输入。这意味着需要有人收集来自系统中所有设备的中断请求,将它们分配到正确的 CPU 核心(根据操作系统的配置),并在中断请求触发时告诉操作系统哪些底层设备需要关注。这就是中断控制器(即Linux术语中的“ irqchip”)的工作。
在具有多个核心的系统上,中断请求控制器还有另一项工作:处理处理器间中断(inter-processor interrupt,IPI)。有时,在一个核心上运行的软件需要引起另一个核心的注意。有了IPI,这种操作就不难实现了:中断控制器提供了一种机制,一个核心可以向中断控制器发送请求,然后中断控制器将其作为中断转发给另一个核心。没有 IPI,多核系统将无法正常工作。
大多数AArch64系统都采用了标准的中断控制器,称为通用中断控制器(Generic Interrupt Controller ,GIC)。这是一个非常复杂且功能强大的中断控制器,有许多高级特性,如中断优先级、虚拟化等。如此一来,Linux 就不需要在AArch64系统上实现自己的 irqchips 作为主中断控制器了。
你可能已经猜到了,苹果依然特行独立。他们设计了自己的苹果中断控制器(AIC)。我们不得不对该硬件进行反向工程,然后为 Linux 编写自己的 irqchip 驱动程序!不过幸运的是,AIC 其实非常简单。根据 macOS/iOS(XNU)的一些开源文档(虽然有些过时),并通过试错的方式对硬件进行了一番探索,我们终于弄明白了一切,并编写了 Linux 驱动程序。
等一下,还有一个问题。Linux 需要 IPI 才能正确工作。具体来说,Linux 使用了7种不同的 IPI:它希望能够从一个 CPU 核心向另一个核心发送7种不同种类的中断请求,并将它们当作不同的事件处理。AArch64 系统上的任何 IRQ 控制器都能支持这种细粒度的 IPI 分离,但不幸的是AIC不支持:它只能支持两种,而且实际上,这两种的使用方式还不一样(一个用于发送给其他 CPU,一个用于核心给自己发送的“自身IPI”)。为了确保 Linux 正常工作,我们需要实现一个“虚拟”中断控制器。对于每个 CPU 核心上不同种类的待定事件,AIC 驱动程序内部最多能管理32个事件,它会将这些事件全部发送给对应于该核心的硬件IPI。当 IPI 到达该核心时,它会先检查有哪些待定事件,然后将待定事件当作不同的IPI发送给 Linux。Linux 的其余部分就会认为这是一个能够针对每 CPU最多处理 32 个 IPI 的中断控制器,尽管其硬件只支持两个(实际上我们只用到了一个)。
即使是给 AIC 这样简单的中断控制器编写驱动也不是一件易事。中断处理有许多方面需要处理,哪怕代码中有一点错误,就会引发令人苦恼的 heisenbugs,这种 bug 只在罕见的特定事件序列发生时才会出现,但一旦出现就会导致整个操作系统宕机,因此调试几乎是不可能的。在中断处理程序中,输出调试信息非常需要技巧,因为改变时机就可能导致 bug 消失,也可能导致整个系统过慢而无法使用。而添加一个软件 IPI 多路复用器会导致情况更加复杂,因为我们不得不用软件来模拟本应由硬件来处理的东西,这样一旦出错就会由于竞争条件而丢失 IPI。
在尝试理解这些细节以确保 AIC 代码正确时,我发现自己陷入了无底洞:我不得不研究 AArch64 上的内存顺序和内存屏障等细节,甚至还发现了 ARM64 Linux 原子操作实现中的一个细微的错误!当然,这是另外一个话题。如果你想了解更多信息,我推荐看一看Will Deacon的演讲,比如这篇(https://www.youtube.com/watch?v=i6DayghhA8Q)和这篇(https://www.youtube.com/watch?v=6ORn6_35kKo)。特别是,此提交(https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=22ec71615d824f4f11d38d0e55a88d8956b7e45f)回答了很多问题,Will还回答了我剩余的一些疑问。我对内存模型和AIC代码的健全性很有信心,这可以避免在调试过程中感到困扰。试想一下,如果我们必须追踪一个微妙的 GPU 挂起问题,而由于 AIC 驱动的竞争条件问题,这种问题只有在游戏中做某些事情时才会发生(但只是偶尔会发生,并且需要一个小时才能重现)!
不知是好是坏,M1 特别善长暴露这种小 bug。它的乱序执行极其强大,所以那些竞合条件是在其他CPU上从来不会发生的。在调试一个早期的 m1n1 问题时,我们甚至观察到了乱序执行(正确地)超出了中断处理程序的范围……代码才执行到了处理程序的一半,就已经输出了调试信息!问题的深层原因是因为MMU 中的一个微小的错误配置。从这个问题你可以看出,核心系统的各个部分是紧密联系的,而且调试非常困难。
有意思的是,M1 芯片实际上带有标准的 GIC。具体来说,它能够原生地将 GIC 的底层比特虚拟化,供虚拟机系统使用!这样就可以实现更高性能的中断处理,因为没有这个功能,虚拟机的监控程序就不得不模拟中断控制器的每个细节,意味着每个中断都需要调用多个监控程序中的代码并返回。但奇怪的是,macOS的监控程序框架(https://developer.apple.com/documentation/hypervisor/apple_silicon)并不支持该功能(至少在本文撰写时如此),因此虚拟机的监控程序依然需要使用软件完整模拟 GIC。我们已经测试过这一点了,并证明了可行,现在正在与 Marc Zyngier 合作,在这些芯片上运行虚拟机;他已经成功地实现了在 M1 Mac上运行的Asahi Linux内核上运行的KVM中启动Linux虚拟机。性能测试还为时尚早,但我们希望,如果 macOS 不支持这个功能,那么只要其他部分完成,原生的 Linux-on-Linux 虚拟机就会比 Linux-on-macOS 虚拟机更快,特别是对于 IPI 很多的负载。

过度繁琐的 FIQ
接下来,每个操作系统都需要一个系统时钟。当计算机运行多个应用程序时,操作系统需要能够在同一个 CPU 核心上切换应用程序,以实现多任务。它还需要能够设定任务调度在特定的时间点完成,例如将缓存数据写入磁盘,或者显示YouTube 视频的下一帧,甚至将任务栏中的时钟增加一秒等。所有这些都要依赖某种时钟硬件,该硬件可以通过编程,在未来的特定时间发送 IRQ。
AArch64 包含一个特殊的系统时钟规格,M1 也按照我们期待的方式实现了该标准。但是有一个平台特定的比特:时钟需要通过某个IRQ控制器发送中断。在GIC 系统中当然是通过 GIC 发送(尽管每个系统使用的中断编号可能不同)。因此,在苹果芯片中,就应该通过 AIC 发送。
但是,触发时钟中断并要求AIC告诉我们等待的中断的话……结果什么都得不到。什么?苹果又一次为我们带来了惊喜……你看,M1 的时钟完全没办法发送IRQ。实际上,他们只发送 FIQ。
当我们说 AArch64 CPU 只有一个 IRQ 线的时候,我们并没有提及它的兄弟:FIQ 线。FIQ(Fast Interrupt Request,快速中断请求)是另一个中断机制。这里的“快速”指的是它们比旧的 AArch32 系统工作得稍稍快一点,但在AArch64上,这点区别已经不再:FIQ 和 IRQ 实际上是相同的。在 GIC 系统中,操作系统可以配置每个中断,决定它们通过 IRQ 还是 FIQ 发送。而绝大多数AArch64系统都保留了 FIQ 作为安全监视器(TrustZone),所以 Linux 无法使用它。因此,Linux 完全不使用 FIQ。AArch64 Linux 如果收到一个FIQ 就会宕机,它也从不会期待收到 FIQ。
没有 FIQ 的支持,M1 上就没有时钟,所以别无选择。这是为了苹果芯片而必须做出的另一个重大修改。添加 FIQ 的支持很容易(最简单的方式只需要机械地将IRQ的处理方式复制过来,同样地处理 FIQ 即可),但是具体的细节很麻烦,包括决定如何为不需要的系统处理 FIQ,以及是否要在所有地方启用 FIQ,还是在不需要的地方禁用。
最后,在思考了几种方法,并进行了几轮迭代之后,Linux ARM64 团队的Mark Rutland 主动承担了这个任务,负责给 Linux 添加 FIQ 支持。
还有另一个东西也发送 FIQ:实际上还有一个基于 FIQ 的“快速IPI”机制,我们还没有用到。还有一个硬件性能计数器也使用它。事实上,FIQ 由每个独立的CPU 核心或核心集群内的硬件使用,而 IRQ 由共享AIC外设(负责管理各个 CPU之间的共享硬件)使用。但是,另一个痛点就是完全没有FIQ控制器。尽管AIC是IRQ控制器,但所有的FIQ源都“混合在一起”(ORed)形成一个 FIQ,根本无法用中心化的方式区分它们。相反,FIQ 处理代码必须依次检查每个 FIQ 源(检查每个源的方式都不一样,因为需要检查特定的设备寄存器),找出哪个需要关注,只有需要关注时才将中断发给该设备的驱动。这种做法非常不雅观,我们不知道为什么苹果不想设置一个没有任何难度的“FIQ 控制器”。即使只设置一个寄存器,用每一比特来表示一个 FIQ 源,就足够了。我们尝试过寻找,甚至搜遍了每个寄存器,但似乎 FIQ 控制器并不存在。
而 M1 拥有的是一些额外的特殊功能,用于处理虚拟机操作系统的时钟中断(因为这是让虚拟机正常工作的必要条件)。我们也对此作了逆向工程,并将其用在了 Marc 运行 KVM 的工作中。
在针对核心 FIQ 支持的补丁之外,我们还决定将 FIQ 分发给 AIC 驱动中的下游设备驱动(即使严格来说它们并不是AIC的一部分),以实现这些路径之间更紧密的耦合。如果我们决定改变通过 IRQ 发送 AIC IPI 的做法,改成通过 FIQ 发送“快速IPI”,那么这个决定将会派上用场。

历史遗留下来的问题
能够在设备上运行 Linux 固然很好,但如果没办法与之交互怎么办?为了能访问 dmesg 日志并通过控制台与 Linux 交互,我们需要 M1 上的 UART 驱动程序。UART 有好几个变种,最流行的是 PC 上的标准 UART 16550,现在几乎所有 ARM 系统芯片都集成了这个标准。但毕竟是苹果,他们肯定会搞自己的标准……对吧?
没有!但是,用的不是 16550……M1 用的居然是……三星的 UART?
第一代 iPhone 采用了三星的系统芯片,即使苹果自豪地宣布他们切换到了自己的设计,底层脱离三星的速度也要慢半拍。“苹果芯片”与其他系统芯片一样,包含来自许多其他公司授权的知识产权核心。例如,M1 的 USB 控制器来自Synopsys,其硬件的芯片来自 Rockchip、TI 和 NXP。甚至在苹果将制造商从三星换成台积电以后,一些三星的东西依然留在芯片中。UART 的设计一直保留至今。我们不知道这是否意味着M1中包含三星的知识产权,也许只不过是苹果照搬了三星的设计来保证软件兼容性(严格来说UART并不难设计),但不论如何,今天的 Exynos 芯片和苹果芯片依然有共通点。
Linux 已经有了三星 UART 的驱动程序。但问题在于(当然会有问题):“三星UART”并非只有一个,而是有好几个略有不同的、互不兼容的变种,而至于苹果使用的变种,Linux 上的三星 UART 驱动并不支持。
支持许多同一硬件的变种的驱动程序会变得非常混乱,像三星 UART 这样古老的驱动程序更是如此。更糟糕的是,Linux 中的串口子系统还是Linux早期的版本,这就带来了另一个问题:古老的代码。所以,最大的问题在于集成新 UART变种的支持,同时不能让代码变得更乱。这就意味着要做重构和清理!例如,Linux 有一个古老的概念叫做串口类型,暴露给用户空间(意味着这些类型只能添加而不能删除,因为用户空间 API 必须维持向后兼容性),但是这与现代Linux中的设备处理方式完全不同。用户空间完全没有理由知道串口类型是什么,即使知道,也不应该使用 TTY API 和固定的列表来访问(这就是 sysfs 存在的原因)。每个已有的三星 UART 变种都有自己的端口类型(甚至还有一个从来没有实现过的未使用类型),但显然我们并不想添加另一种类型……所以我们重构了驱动程序,给UART变种添加了一个内部标识,与那些暴露给用户空间的端口类型完全无关。对于这个古老的 API 来说,苹果的 UART 会被识别为16550,反正这个 API 也不会有人用。
另一个困难是这些变种处理中断的方式。较老的三星 UART 有两个独立的中断输出,分别用于发送和接收,由系统中不同的中断控制器负责。新的 Exynos 变种会在内部处理,在 UART 中有一个很小的中断控制器,负责处理各种中断类型,将所有中断作为同一个发送给系统的 IRQ 控制器。苹果的变种也是这样,但与之并不兼容,还添加了不同的寄存器,所以必须编写不同的代码路径。
在此之上,该UART 变种仅支持边沿触发的中断。边沿触发(edge-triggered)中断是一种仅在事件发生时立即触发的中断。例如,当UART发送缓冲区清空时。与此相对的叫做状态触发,只要特定条件为真,状态触发中断就会触发。由于种种原因,状态触发中断的处理更为简单,所以大多数现代系统都选择了状态触发。尽管 AIC 自己用的是状态触发中断,而且 UART 自己的中断也是状态触发,但是驱动它的内部事件(例如当传输或接收缓冲区为空或满时)却采用了边沿触发的方式!其他的三星 UART 类型支持两种模式,而 Linux 采用了状态触发模式。这就导致了通过 UART 传输数据的 Linux 代码造成了一个问题:现有的代码只能打开传输器,然后就无所事事了。由于一切都配置为状态传输模式,而传输缓冲区为空时会立即触发一个中断,而驱动程序中的中断处理器会使用即将传输的数据填充缓冲区。在边沿触发模式下就不能这么做,因为触发时缓冲区已经为空了,而不是即将为空。此时不会有任何事情发生,驱动程序也不会发送任何数据。我们必须让驱动程序在数据可以发送到设备时,“立即”处理传输缓冲区,因为只有第一批数据发送之后才会引发中断触发,从而请求更多数据。
应付 UART 的这些奇怪的特性尤其麻烦,因为我们在使用 m1n1 进行试验时,m1n1 本身就是通过 UART 控制的。尝试研究设备的工作方式,而通信设备本身就是该设备,这就非常麻烦!不过幸好这些工作都完成了,如今 m1n1 可以正常工作了。
还有另一个驱动程序需要进行同样的处理,不过需要使用完全不同的路线。M1 芯片中的 I2C 硬件来自 P.A.Semi!似乎 M1 中还包含一些来自 PowerPC 的遗产,而其 I2C 外设是基于 PWRficient 芯片的,包括 AmigaOne X1000 中使用的芯片。Linux 支持那个平台,但是现有的驱动的功能非常薄弱。幸运的是,在联系了驱动的作者之后,发现他手里依然有能正常工作的 X1000,可以帮助测试补丁。我们还获得了该芯片的硬件文档,这样我们就能改进驱动程序,并添加能够在 X1000 上正常工作的特性(如中断支持),同时添加支持 M1 所需的改动。由于该驱动是启用全速 USB Type-C 端口的必要条件,所以这个工作早晚要做。

终于能见到企鹅了!
作为一部“给 Linux 铺路”的鸿篇大论,最后我们来看一看怎样让 Linux 的帧缓冲控制台在 M1 上工作。不过你可能要失望了,这个结尾并不长。
在 PC 上,UEFI 固件会设置一个帧缓冲区,因此即使没有合适的显示驱动,也可以通过一个名为 efifib 的驱动来正常运行 Linux。搭载苹果芯片 Mac 的运行方式与之相同:iBoot 会设置一个帧缓冲区供操作系统使用。我们需要做的就是使用通用的 simplefb 驱动,无需任何改动就能运行良好。我们只需在文档中记录一些设备树绑定方面的改动,因为虽然代码支持,但文档中并没有。
于是,在所有工作之后,只需在设备树中添加几行,就能将黑屏变成这样:
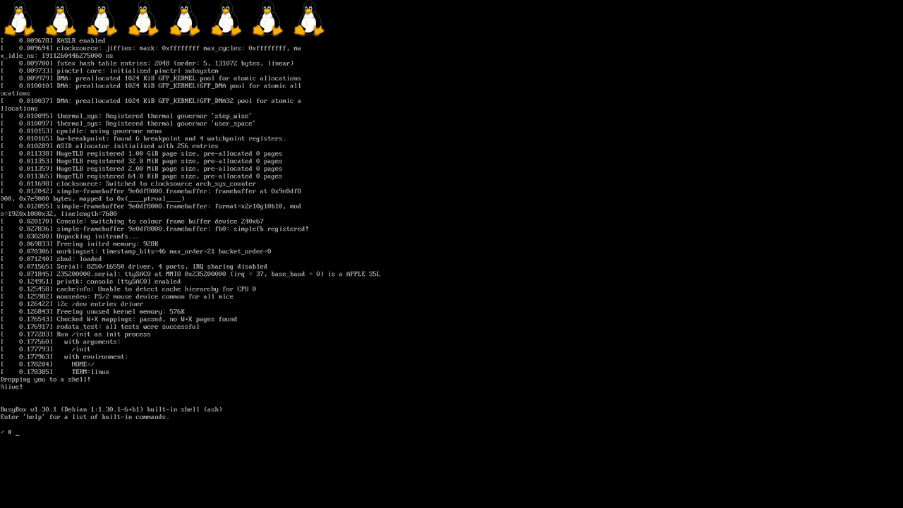
现在,m1n1 能够完美地处理一切,获取 iBoot 提供的帧缓冲区的信息(宽度、高度、像素格式、步长和基址),并放到设备树中,供 Linux 使用。
当然,这只是一个固件提供的帧缓冲区。由于它并不是正常的显示驱动,所以还不能改变分辨率、处理显示热插拔,甚至也不能让显示器休眠。对于开发和演示来说足够了,但我们还需要编写一个合适的显示控制器。
当然,还有 GPU,它并不是显示控制器,而是一个逻辑上完全分离的硬件。PC用户经常会混淆两者,因为两者放到同一个名为“显卡”的芯片中,但在逻辑上两者是截然不同的,在 M1 这种系统芯片上,显示控制器和 GPU 之间的关系就像USB 控制器和 GPU 一样。GPU 支持本身又是另一篇史诗了,所以敬请关注!
原文链接:https://asahilinux.org/2021/03/progress-report-january-february-2021/
声明:本文由CSDN翻译,转载请说明来源。
更多精彩技术内容,请扫码关注CSDN官方公众号!