产品起源
为什么要做这样的产品?文章《ChatBI开源实现: AI+BI的产品设计》中有介绍 为什么要自己做这样的产品?1、低成本试错;2、未来数据生态入口; 为什么要基于Supersonic做? 开源协议友好:可魔改商用 社区活跃:1、凌晨/周末项目成员回答问题、提交代码;2、每月一个版本 可扩展的软件架构:管道化Text2SQL过程、各阶段可快速定制扩展 企业级特性完善:安全(可扩展的4A、原生支持多层级细粒度的数据权限)、准确(基于语义模型-headerless bi理念的设计,有助于为大模型提供更准确的业务知识) Java技术栈:有机会吸引更多企业级Java开发者加入 需要共建的点: 1、UI交互与国外SaaS产品对齐; 2、RAG+Agent能力增强;3 3、生态集成:更多数据源、更多大模型、更多语义模型、更多数据工程生态; 4、基于大模型增强的数据分析能力产品愿景
数据工作像聊天一样自然
产品理念
安全准确:必须安全、再谈准确 稳定易用:功能稳定、稳定推广、用户稳定增长;产品易用、降低使用门槛、释放用户心智; 丰富开放:逐步增强丰富的功能:1、产品交互的细节;2、数据工作上下游能力;3、周边生态能力的集成及框架的扩展性;始于BI终于Data的开放性方向,不局限于BI的战场,面向全链路的数据工作场景。产品名
chatData
产品定位
业务人员:数据提取机 分析人员:分析启发器 技术人员:开发加速器产品规划
阶段一:安全准确 系统管理:单点登陆、用户管理、角色管理、部门管理、权限管理 权限设计:功能权限(菜单权限、助手权限)、数据权限(数据集、语义模型、行权限、列权限) 用户重构:数据分析用户(数据问答)、数据开发用户(数据建模)、平台用户(产品运维) 交互重构:借鉴网易ChatBI,增强【问答对话】UI,【阶段一UI设计介绍】 准确性提升: 1、Prompt增强; 2、语义模型增强; 3、Mapper+Parser流程重构; 4、自动化准确性测评设计; 5、结果可修改:增强筛选条件修改功能 生态集成: 1、Dify模型能力即成; 2、Dify功能流能力集成; 3、Dify知识库集成; 4、FineBI数据集集成; 5、FineBI组件信息; 6、FineBI指标公式集成; 7、StarRocks集成 业务领域:经营分析(人力域、财务域)、产品侧(xx数据平台) 阶段二:稳定易用7.30版本,未完待续
阶段三:丰富开放8.30版本,未完待续
阶段一设计稿片段
输入可识别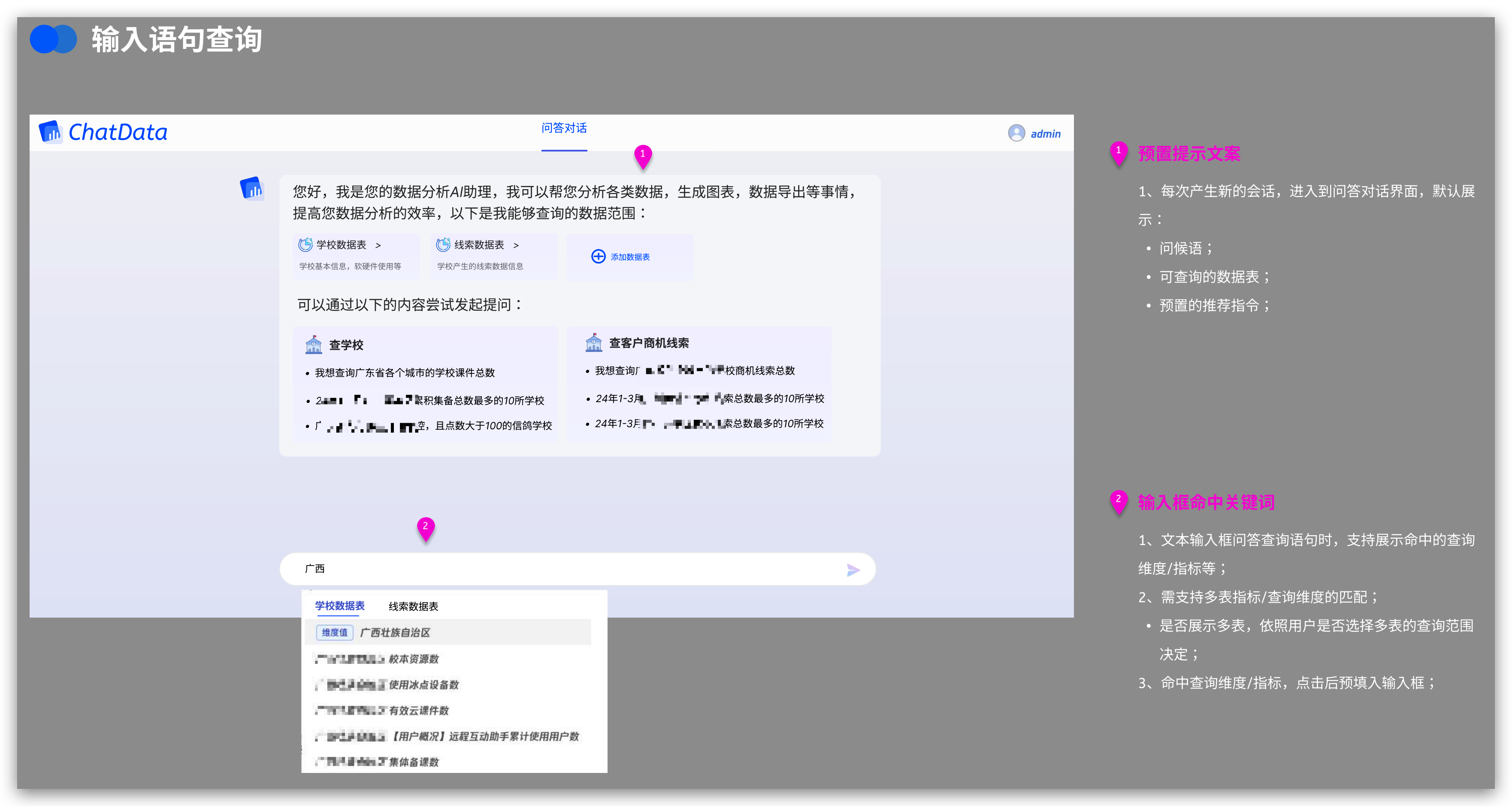 结果可修改
结果可修改 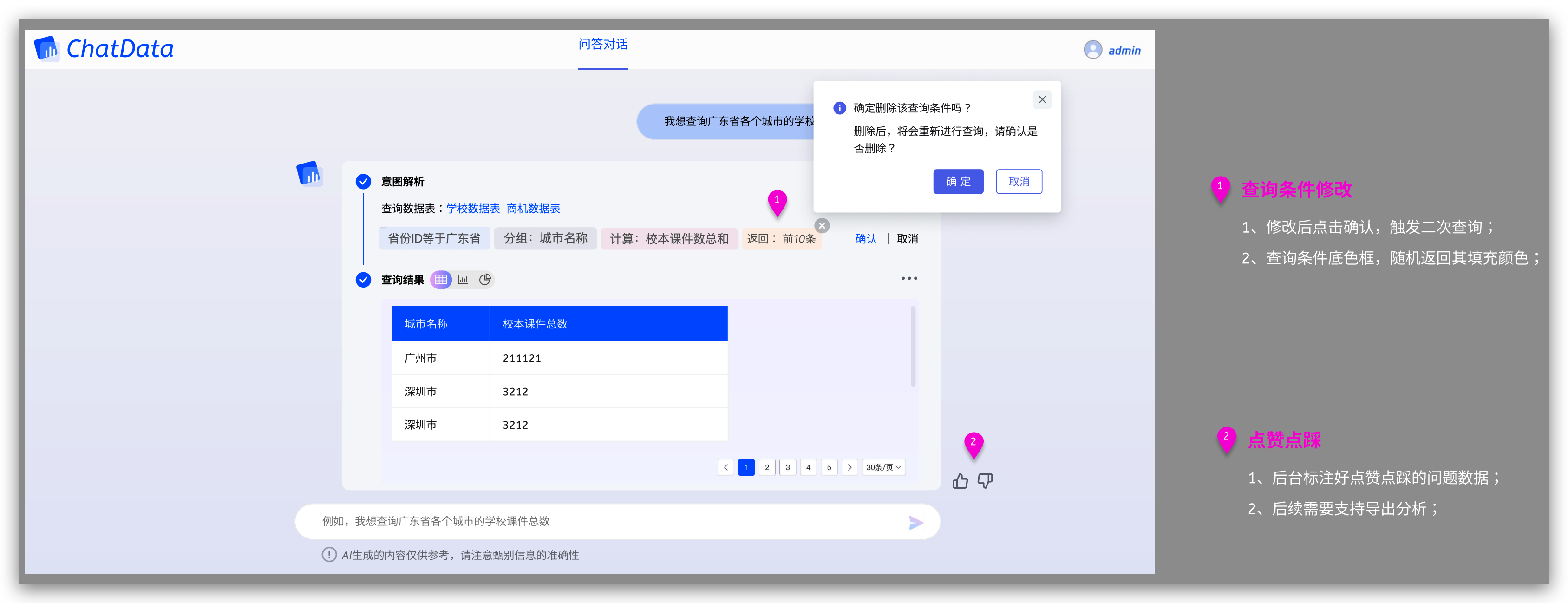
落地总结
躬身入局: 风光无限,尽在线上;艰辛磨砺,皆在线下。大模型的飞速发展,日新月异,其带来的行业变革演示层出不穷,令人目不暇接。只有真正投入其中,才能深刻体会到"台上一分钟,台下十年功"的深意。正如只有勇敢跳入水中,才能学会真正的游泳技巧。
工程实践: 我们的团队中,有几位同事正致力于基于Dify技术深入开发公司的AI Paas平台。我深受张路宇在《》中提出的观点启发,意识到工程化的重要性往往被人忽视。如果将大模型和算法比作一场精彩绝伦的影视巨作中的主角,那么工程化则是那些让主角光芒四射的幕后英雄。主角的精湛演技提升了作品的艺术高度,而工程化的精妙则稳固了作品的坚实基础。
坚信坚持: 冒险者之所以能够"因为相信,所以看见",是因为他们拥有坚定的信念和远见;而保守者则是"因为看见,所以相信",他们更倾向于眼见为实。我们不应过分高估大模型在短期内的价值,也不应低估其在长期内的潜力。合理评估手中的筹码,保持积极的心态,在牌局明朗之际,我们仍将坚守在牌桌上,才有资格争取最后的胜利。
本文由 mdnice 多平台发布