【Linux】解锁磁盘文件奥秘,高效数据管理的实战技巧
磁盘文件
1. 引言2. 磁盘的机械构成3. 磁盘的物理存储3.1. CHS定位寻址法 4. 磁盘的逻辑存储4.1. LBA地址4.2. inode4.3. 分区、分组4.4. Boot Block4.5. 块组 — Block group4.5.1. inode Table4.5.2. Data Blocks4.5.3. inode Bitmap4.5.4. Block Bitmap4.5.5. GDT4.5.6. Super Block 5. 目录文件5.1. 文件名和inode5.2. 重谈文件的增删查改5.3. 路径 6. 如何知道文件在哪个分区下6.1. 格式化6.2. 分区进行"挂载"
1. 引言
系统中是不是所有的文件都被打开?大部分文件都是没有被打开的。
未打开的文件存放在哪里?磁盘或固态硬盘(SSD)上,这些存储设备为文件提供了永久的存储空间。
OS需要管理磁盘上的文件吗?需要,目的是为了让OS快速的定位一个文件。
对于磁盘文件,我们要研究的是如何更好、更合理地把所有文件规划到磁盘上,便于让我们快速定位到一个文件。
故事理解:菜鸟驿站,老板的核心工作是把驿站内所有快递归置好,让用户能够快速定位到自己的快递,还需要对驿站内快递总数、还能容纳的快递数量等工作进行了解。即:菜鸟驿站的老板要对全部快递进行管理,把快递放到特定的位置,对外输出一种能力,让用户快速找到快递的能力。
菜鸟驿站相当于磁盘、存放在驿站的快递相当于磁盘文件、拿走的快递相当于被打开的文件、老板相当于OS中的一个管理模块,称为文件系统,其核心工作是对磁盘文件进行管理,把众多的文件分门别类的放好,给用户提供一种服务,让用户能够快速定位一个文件,具体是通过路径来定位文件。
2. 磁盘的机械构成
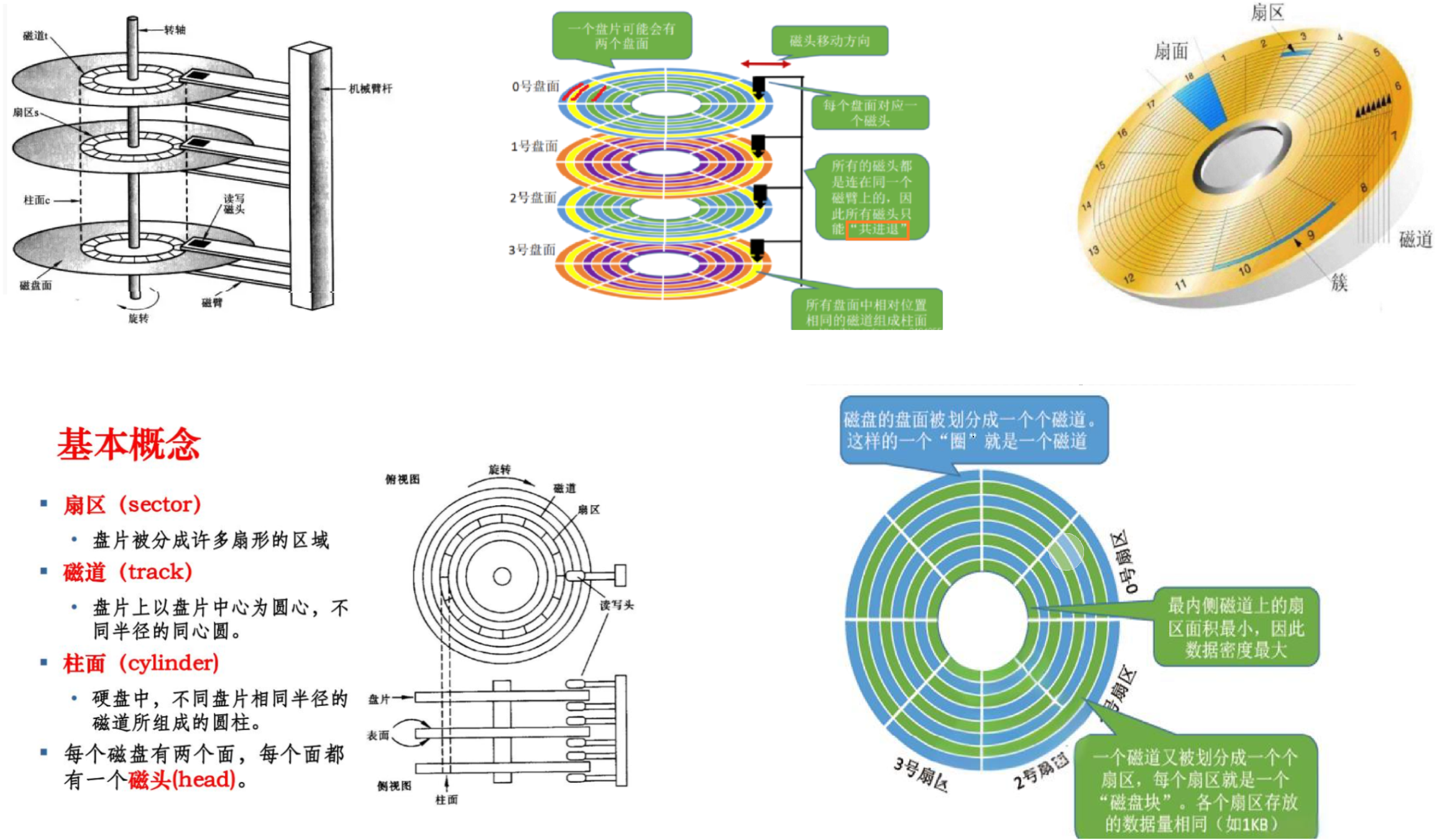
盘面是可读可写的,数据以磁信号的形式存储在盘面上。而光盘是可读的。
盘面、磁头、磁道(柱面)、扇区都有唯一的编号。
盘面高速旋转,磁头来回摆动,就是磁头在盘片上进行寻址,向磁盘对应位置进行读写。
磁盘是个机械设备,不允许在开机的状态下,对它进行搬迁或产生强烈的震动,可能会导致磁头和盘面发生碰撞,从而造成数据损坏、物理损坏。
磁盘内部需要保持相对的无尘环境,可能会对磁盘造成损失。
?Tips:扇区是磁盘IO的基本单位,每个扇区的大小是固定的,一般为512字节,但不一定是系统和磁盘的IO的基本单位。
3. 磁盘的物理存储
3.1. CHS定位寻址法
问:我该如何访问磁盘中的一个扇区?
确定目标扇区的地址 -> 选择磁头 -> 移动磁臂到指定的柱面 -> 旋转磁盘以定位到目标磁道 ->定位目标扇区 -> 执行读写操作。
目标扇区的地址:由柱面号、盘面号、扇区号组成。这三个参数共同决定了磁盘上唯一的一个扇区。
选择磁头:根据目标扇区的盘面号,确定使用磁头。 每个磁头负责读取或写入对应盘面上的数据。
移动磁臂到指定的柱面:根据目标盘面的柱面号来确定的,磁臂连接着所有磁头,通过移动磁臂,可以使所有磁头同时移动到指定的柱面。

CHS(Cylinder-Head-Sector,柱面-磁头-扇区):通过磁盘的物理结构(来定位数据的三维寻址方式,它通过磁盘的柱面、磁头和扇区三个参数,来定位磁盘上的一个扇区。
CHS优点:在早期硬盘容量较小的情况下,CHS寻址方式能够有效地定位和访问数据。
CHS缺点:CHS寻址的容量是有限的。
4. 磁盘的逻辑存储
4.1. LBA地址
LBA地址(Logical Block Addressing,逻辑块寻址):是将扇区编号转化为一维线性编号的逻辑寻址方式,即:它将磁盘上所有扇区编号为一个连续的线性序列。LBA地址是一个线性地址(单一的数字),用于唯一标识磁盘上的一个扇区,LBA地址从0开始,依次递增。
工作原理:LBA编址方式将CHS这种三维寻址方式转变为一维的线性寻址;在访问磁盘时,系统或者磁盘控制器直接指定从硬盘上的特定扇区读取或写入LBA地址,硬盘控制器负责将LBA值转化为实际的物理CHS值。
优点:简化了数据访问的过程,提高了系统的效率,支持更大的容量;因为它采用线性寻址的方式,因此不受物理结构的限制。
?Tips:LBA地址是扇区数组的下标;在使用LBA地址进行磁盘访问时,LBA地址指向磁盘的一个逻辑扇区,即:LBA地址实际上是直接对扇区的索引,不是对数据块的索引。


当将磁盘拉直,并视为线性结构时,实际上是将所有扇区重新排列成一个线性数组。
线性地址(LBA地址)->CHS,由磁盘自动完成,访问磁盘的任意一个扇区,只要知道这个扇区的线性地址,即:这个扇区在线性数组中的扇区编号,也就是数组下标。
问:OS与磁盘进行IO操作时,为什么使用4KB作为基本单位?
减少IO操作的次数,提供性能和效率。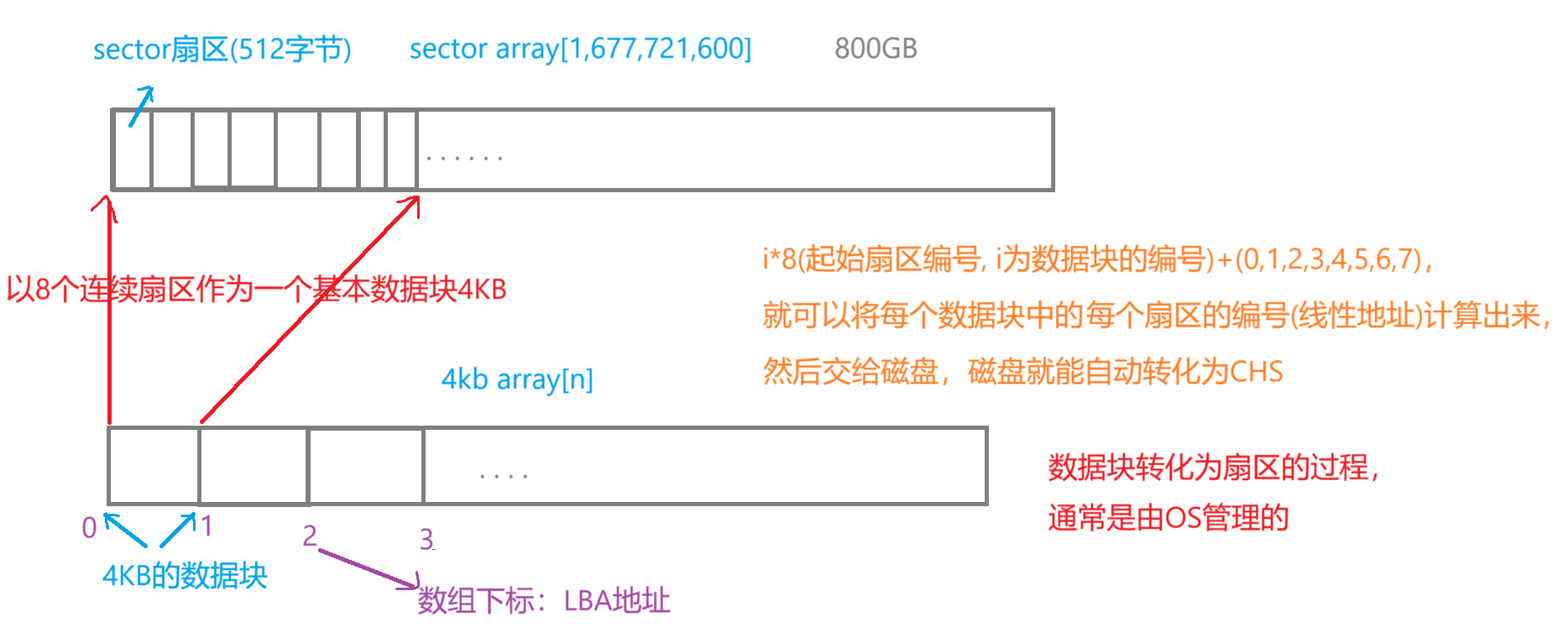
磁盘基本参数获取:在操作系统(OS)启动时,确实会进行一系列硬件检测,包括磁盘设备。这些检测会获取磁盘的基本参数,如扇区数量、磁道数量、每磁道的扇区数等。这些参数对于操作系统管理磁盘存储是至关重要的。
4.2. inode
Linux磁盘文件的特性:文件 = 内容 + 属性,内容大小可变,属性的类别相同,但类别的内容不同(sizeof(结构体)相等);内容和属性分开存储,内容存放在数据块(Data Blocks)中,属性存放在indeo表(indeo Tables)中。
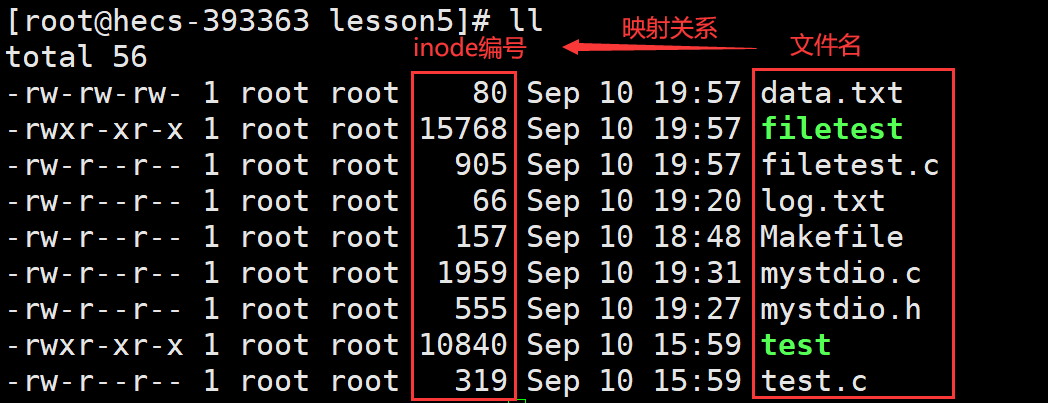
inode的定义:是文件系统中用于存储文件属性的数据结构;每个文件或目录在文件系统中都有唯一的inode与之对应,而每个inode内部都包含inode编号,但不包含文件名或目录名本身。inode编号:是每个文件或目录的唯一标识符,用于在文件系统中唯一标识文件目录;文件系统中的各种操作需要通过inode编号来访问文件的属性和内容的位置。
ll -i
功能:显示文件的inode编号。 inode的作用:快速定位文件数据、实现文件的索引和访问。快速定位文件数据:inode包含了指向文件数据块的指针,使得OS能够高效地读取或写入文件内容。
实现文件的索引和访问:通过inode,OS可以有效管理文件系统中大量的文件或目录,提供高效的存储和检索功能。
inode特点:唯一性、不变性(时间戳除外)、不包含文件名或目录名的字符串。
inode包含的信息(有限个重点属性):文件类型、权限、大小,数据块指针、硬链接个数、ACM时间、所有者和所属组。
人认识世界上的任何事物,都是通过事物的属性,且只能通过属性来认识。一件事物自身的属性是无限个,无法穷举出来,因为语言是有限的。即:人认识事物,只能通过有限个重点事物属性来认识的。
?Tips:inode编号在整个分区内唯一,不是在分组内唯一!inode大小通常为128字节。
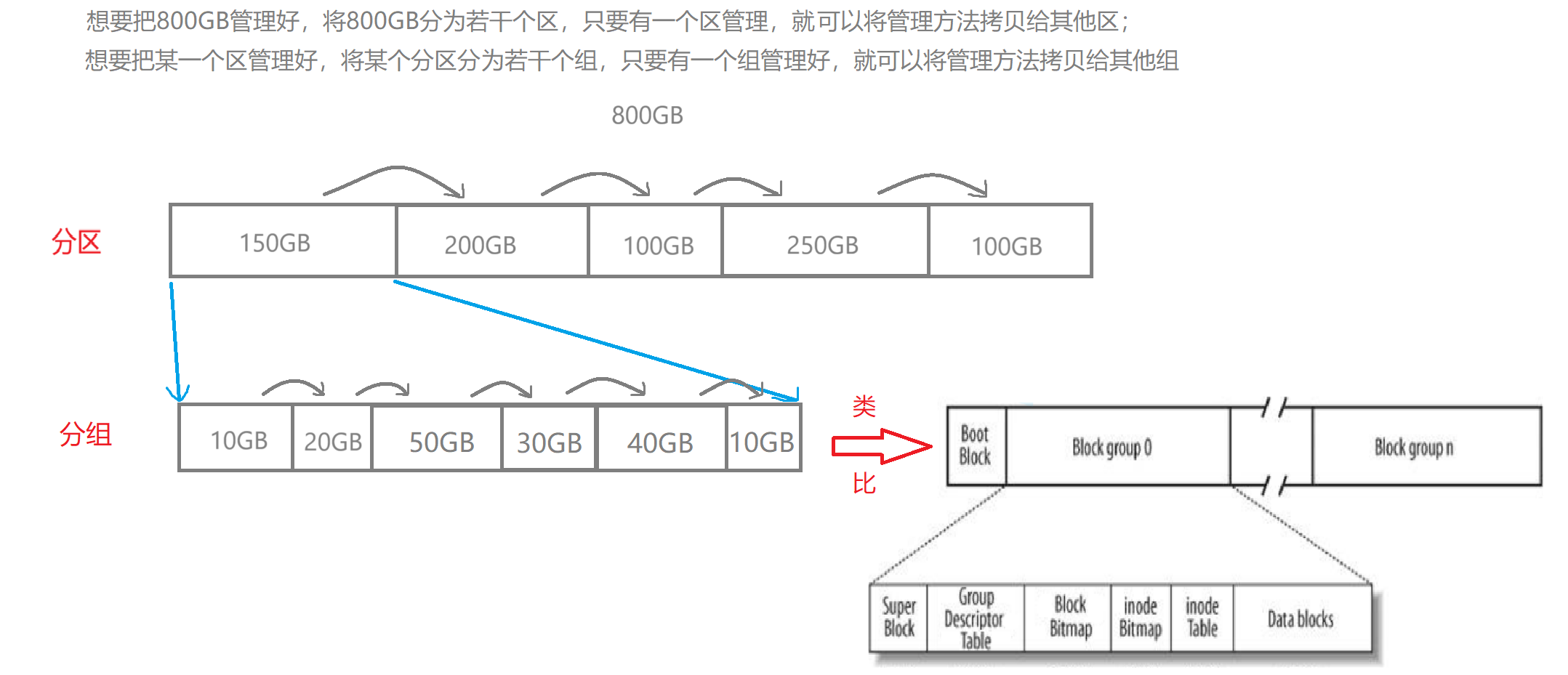
struct inode { mode_t i_mode; /* 文件类型和权限 */ uid_t i_uid; /* 文件所有者 */ gid_t i_gid; /* 文件所属组 */ ino_t i_ino; /* inode编号 */ unsigned long *i_block; /* 指向数据块的指针数组 */ unsigned short i_nlink; /* 硬链接个数 */ blkcnt_t i_size; /* 文件大小 */ time_t i_atime; /* 最后访问时间 */}4.3. 分区、分组
4.4. Boot Block
Boot Block:只存在0号盘面、0号磁道、1号扇区中,即:分组0前,其作用是辅助开机,如:引导OS启动、检测文件系统状态、加载其他引导程序等。
4.5. 块组 — Block group
块组:ext2文件系统,会根据分区的大小划分为数个Block group,每个Block group都有着相同的结构组成,每个块组都包含一个inode表、数据块、inode位图、块位图等。
4.5.1. inode Table
inode Table:是块组中的一个数据结构,用于存储文件系统中的文件或目录的属性,每个inode表包含一定数量的inode结构体。
4.5.2. Data Blocks
Data Blocks:是磁盘上的连续空间,用于存储文件系统中的文件或目录的内容;它是由多个连续的数据块组成的集合,这些数据块在物理上可能并不连续,在逻辑上是连续的,因为它们被组成在一个块组上。
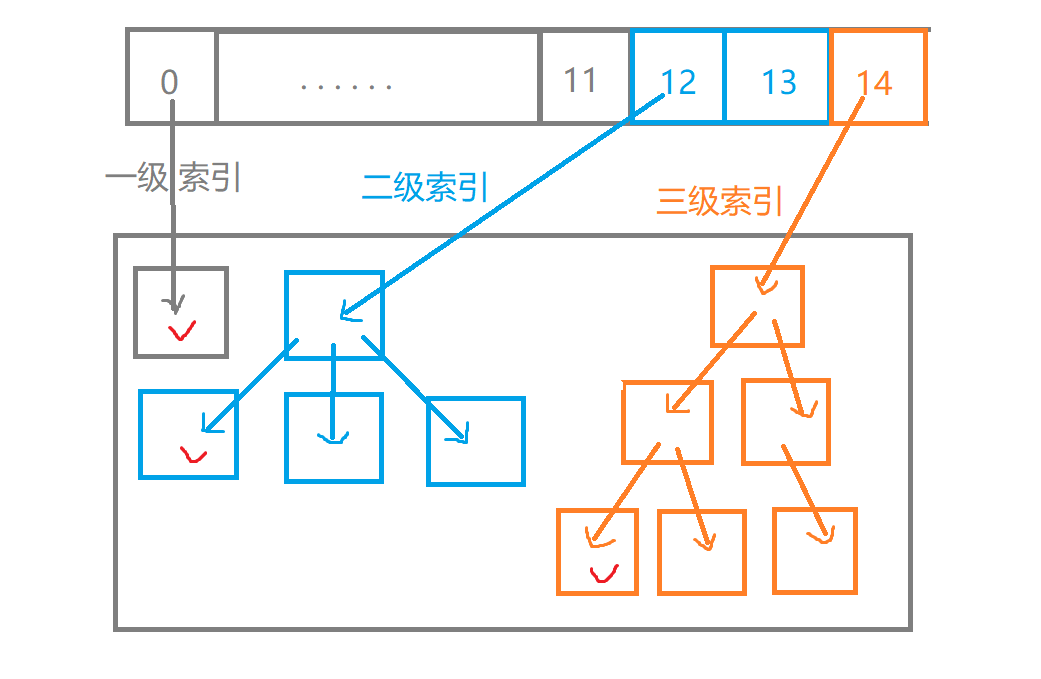
在ext系列的文件系统中,文件的数据通常用一系列数据块来存储,而这些数据块的组织方式可以通过一级索引、二级索引、三级索引等多种方式进行管理,以便可以存储更大内容的文件。
一级索引:下标为[0, 11],通过一个索引块来存储数据块的编号。存储了12个数据块编号。
二级索引:下标为[12,13],通过一个索引块来存储另一个索引块的编号,后者在存储数据块的编号。存储了2*(4*1024/4)=2048个数据块编号。
三级索引:下标为[14],通过一个索引块来存储另一个索引块的编号,后者再存储第三个索引块的编号,最终第三个索引块存储数据块的编号。存储了110241024=1,048,576个数据块编号。
思想总结:在ext系列的文件系统中,通过编号或者指针找到真实存储数据的数据块;在多级索引下,先找到索引块,然后通过最后一次的索引指针或编号找到实际的数据块,即:最后一次索引才是真正存储文件的内容。
struct inode{ //如果block数组直接存储数据块的编号(一级索引),则可存储的文件内容大小为4KB*15 = 60KB,而文件内容大小是可变的 int block[15]; }4.5.3. inode Bitmap
inode位图:用来记录块组中的inode(inode Table)是否被分配。
位图的位置:第几个inode,每个比特位,对应一个inode; 位图的内容:对应的inode是否被分配给一个文件或目录;如果该位为1,则表示对应的inode已经分配、如果该位为0,则表示对应的inode当前空闲,可用于分配给新的文件或目录。
4.5.4. Block Bitmap
块位图:用来记录块组中的数据块(Data Blocks)是否被占用。
位图的位置:第几个数据块,每个比特位,对应一个数据块;
位图的内容:对应的数据块是否被占用了;如果该位为1,则表示对应的数据块已经被占用、如果该位为0,则表示对应的数据块未被占用。
inode Bitmap、Block Bitmap:不属于文件本身的直接内容,而是文件系统为了管理对应的文件,而设置的额外管理字段。
删除一个文件,不用把文件本身的内容和属性删除,而是把位图内容由1只为0,表明这个文件已失效,可以被覆盖。
4.5.5. GDT
块组描述符:是对文件系统中所有块组进行管理的数据结构,每个块组在GDT中都有一个对应的条目,这个条目包含了块组的关键信息,如:inode表、数据块、inode位图、块位图的位置。
GDT是一个全局的数据结构,每个块组中并不包含一个单独的GDT完整副本,通常只存储在文件系统中块组0,它描述了文件系统中所有块组的信息。
struct group_descriptor { blk_t bg_block_bitmap; /* 块位图的位置 */ blk_t bg_inode_bitmap; /* inode位图的位置 */ blk_t bg_inode_table; /* inode表的位置 */ blk_t bg_free_blocks_count; /* 未分配的块数 */ blk_t bg_free_inodes_count; /* 未分配的inode数 */ blk_t bg_used_dirs_count; /* 使用的目录数 */ /* 其他字段... */};4.5.6. Super Block
超级块:是文件系统中一个全局的数据结构,即:对整个文件系统进行管理的数据结构,存放整个文件系统的结构信息,如:block、inode的数量,未使用用的block、inode的数量,最近一次挂载的时间,最近写入数据的时间等其他与文件系统相关的信息。struct super_block { blk_t s_block_count; /* 文件系统的总块数 */ blk_t s_inode_count; /* 文件系统的总inode数 */ blk_t s_block_size; /* 块大小 */ blk_t s_inode_size; /* inode大小 */ blk_t s_blocks_per_group; /* 每个块组的块数 */ blk_t s_inodes_per_group; /* 每个块组的inode数 */ blk_t s_first_data_block; /* 第一个数据块的位置 */ blk_t s_first_inode_block; /* 第一个inode块的位置 */ /* 其他字段... */};问1:为什么不在所有组中包含超级块?
节省空间、减少冗余。问2:为什么个别组内包含超级块?
可靠性、容错性、文件系统修复:尽管Super Block在全局范围内只需存一份,但为了防止单点故障导致的数据丢失或文件系统损坏,通常会在个别块组中存储Super Block的副本,这样,即使主超级快损坏,可以从个别组中的超级块副本来恢复文件系统的状态。?Tips:Super Block的信息被破坏,则整个文件系统的结构被破坏了。
当OS启动时,它会识别并挂载系统上的各个分区。在这个过程中,OS会读取每个分区最头部的Super Block信息,并将其加载到内存中,为了在内存中表示这些信息,OS通常会为每个挂载的文件系统创建一个struct Super Block结构体对象,并将从磁盘上读取Super Block信息填充到这个结构体对象中,再用特定的数据结构将所有对象进行链接,即:对文件系统的管理,就转化为了对特定数据结构的增删查改。5. 目录文件
5.1. 文件名和inode
在文件系统中,普通文件或目录都是文件系统中的文件,每个文件都有自己的inode和数据块,普通文件的内容存储了实际的数据,而目录文件的内容存储了文件名和其inode的映射关系。任何一个普通文件,一定存放在一个目录中。
当你打开一个目录时,你看到的是目录中包含的文件名列表,而每个文件名都关联(或映射)到一个inode编号,通过inode编号可以找到具体的文件或目录。
5.2. 重谈文件的增删查改
问1:找一个文件,是通过inode编号查找,前提是你得先知道你的文件在哪一个分组中,如何知道?
分区内的inode编号是唯一的,OS会给分区中的每个分组分配一个起始inode编号和起始数据块编号,且每个分组内的inode总数、数据块总数是已知的。通过将inode编号与每个分组的inode编号范围进行对比,如果inode编号落在某个分组的范围内,则说明该文件处于这个分组内。
在一个目录下,进行文件操作(增、删、改),本质都需要修改目录的内容,即·:对目录权限的约束,可以间接约束在该目录下进行文件操作(增、删、改)。
新建文件:遍历位图 -> 在inode表中添加新的inode -> 初始化inode -> 分配数据块 -> 建立文件名和inode编号的映射关系 -> 更新目录内容。
初始化inode:inode编号 = 分组的起始inode编号 + 其所在inode表中的数组下标。
修改文件:查找inode -> 找到具体的文件 -> 更新数据块 / inode属性 -> 更新inode表。查找inode:查找目录的内容,根据文件名和inode的映射关系,从而获取inode编号;
通过inode编号,找到具体的文件:inode编号与每个分组的起始inode编号进行对比,从而确认其所在的分组,再让inode编号 - 分组起始inode编号 = 在位图中的位置 = 在inode表中的位置。
5.3. 路径
查找一个文件,在OS中,都要逆向的递归般得到/,然后再从根目录进行路径解析。查找一个文件,就得找到这个文件的inode,就必须查找这个文件所在的目录内容,而目录也是文件;查找目录文件,就得找到这个目录文件的indoe,就必须查找这个目录文件所在的目录内容,直到遇到根目录,根目录inode编号是已知的(逆向递归)。再从根目录正向进行路径解析,知道inode编号,就知道这个文件的内容,就知道这个目录文件下所有文件的inode。
6. 如何知道文件在哪个分区下
6.1. 格式化
概念:向指定的分区写入新的文件系统的操作。
目的:快速清空分区内的所有数据,并创建一个新的文件系统,以便分区能够存储新的数据。
每个分区可以有相同或者不同的Ext系列的文件系统。
6.2. 分区进行"挂载"
前提:一个写入文件系统的分区,要能被Linux使用,必须要把这个具有文件系统的分区进行"挂载"。
挂载:将一个文件系统所对应的分区,挂载到指定的目录下。使得用户可以通过访问指定的目录,实现访问分区下的目录或文件。
df -h
功能:查看已挂载文件系统的磁盘使用情况,并以易于阅读的格式显示。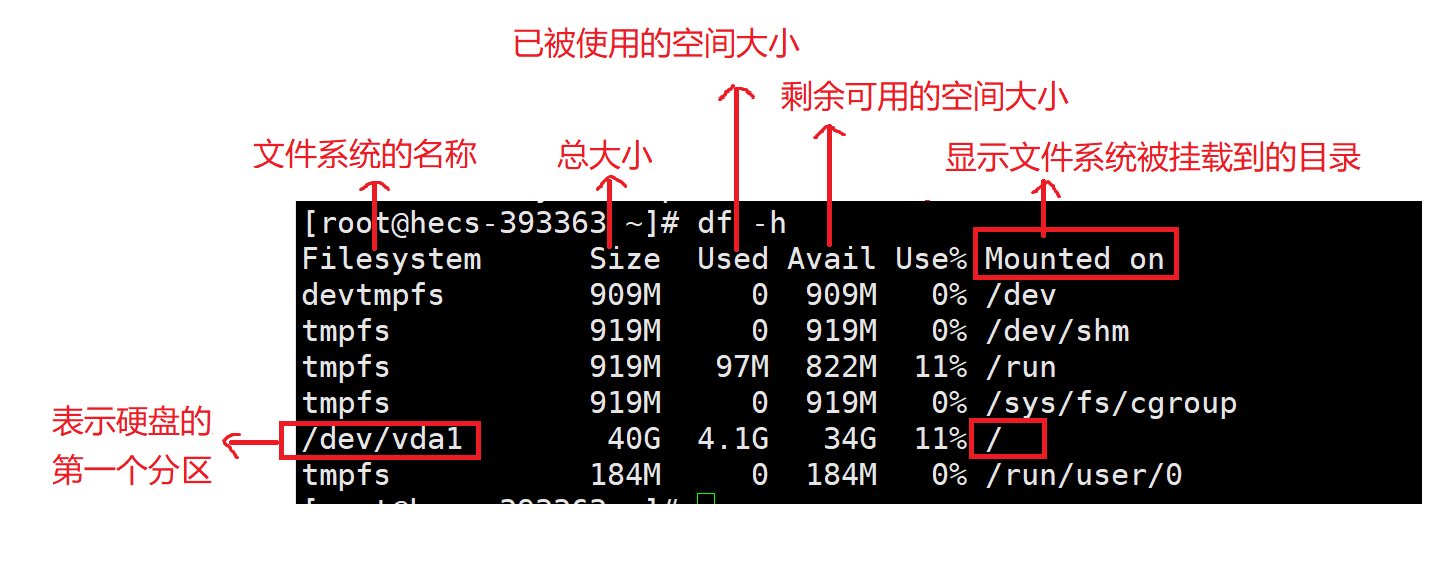
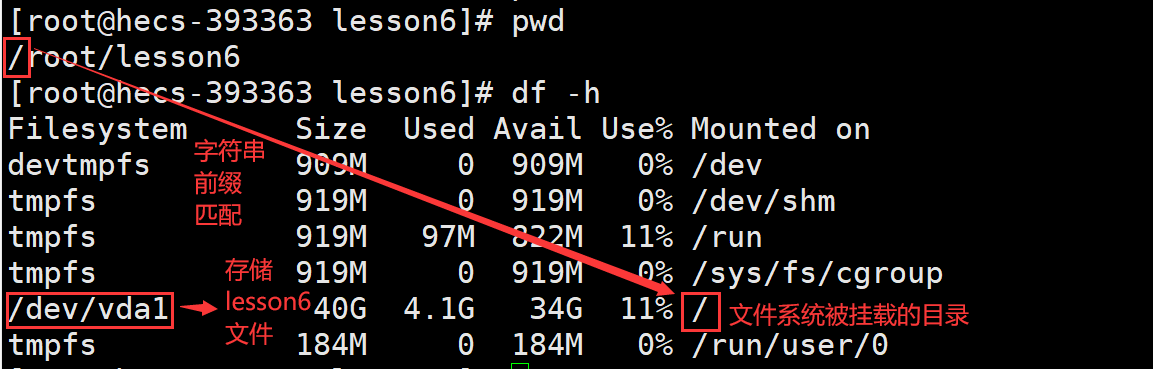
在这个过程中,Super Block提供了文件系统的全局信息,dentry通过目录下缓存机制来加速文件名的查找,它提供了文件名到inode的快速映射,使得用户可以通过文件名快速访问文件数据。
登录后可发表评论
点击登录