前言:大模型可以根据其主要的应领域和功能,可以分类为“文生文”(Text-to-Text)、“文生图”(Text-to-Image)和“文生视频”(Text-to-Video),都是基于自然语言处理(NLP)和计算机视觉(CV)的大模型所实现的功能。这些大模型的发展极大地推动了人工智能技术在各个领域的应用,并且随着技术的进步,未来可能会出现更多创新性的应用和服务。
一、AI大模型分类
1.1、文生文大模型(Text-to-Text)
这类模型专注于文本生成和变换任务,如回答问题、文章写作、摘要生成、新闻撰写、故事创作、翻译等。市面上经典应用包括ChatGPT、通义千问、豆包、文心一言等。
一些典型的模型包括:
- Llama:Meta推出迄今为止能力最强的开源大模型Llama 3系列,发布8B和70B两个版本。
-Qianwen:阿里云开源通义千问 Qwen2 大模型,Qwen2的开源旨在推动全球范围内的落地和商 业应用,并计划将Qwen2扩展为多模态模型,融入视觉和语音理解能力。
-ChatGLM:清华开源的GLM-4-9B模型在综合能力上比ChatGLM3-6B提升了40%,并且在中文学科能力上提升了50%
- GPT系列(如GPT-3, GPT-4):由OpenAI开发,广泛用于生成连贯的文本。
- Bard:由Google推出,是一个能够生成对话和文本的模型。
1.2、文生图大模型 (Text-to-Image)
这类模型能够根据给定的文字描述生成相应的图像。应用于创意设计、插图生成、游戏开发中的角色或场景生成、艺术创作等。市面上经典应用Midjoumney是一款AI制图工具,只要关键字就能通过AI算法生成相对应的图片,只需要不到一分钟。
一些典型的模型包括:
- Stable Diffusion:一个开源的生成模型,能够根据文本生成图像。
- Kolors:快手推出的文生图大模型,支持多种风格的图像生成。
1.3、文生视频大模型 (Text-to-Video)
这类模型可以根据文本描述生成视频内容。应用于视频制作、广告创意、教育视频生成、娱乐内容创作等。市面上经典应用Sora,美国人工智能研究公司OpenAI发布的人工智能文生视频大模型,但OpenAI并未单纯将其视为视频模型,而是作为“世界模拟器。
一些典型的模型包括:
Open-Sora1.0:由Colossal-AI团队开源的视频生成模型,能够从文本生成视频。
二、开源大模型总结
针对“文生图”、“文生文”和“文生视频”的分类,下面列出一些当前较为知名的开源大模型。
2.1 、开源文生文大模型
Llama : Meta发布的开源模型,支持多种语言。Llama 是由 Meta AI 开发的一系列语言模型。稳定的版本称为 LLaMA2,特别是 LLaMA2 Long,它具有长达 32,000 个 token 的上下文窗口,并且在多项任务上显示出了超越 ChatGPT 和 Claude2 的性能。这意味着 LLaMA2 在处理长文本和需要更多上下文的任务方面更为出色。最近开源标杆Llama-3.1登上开源顶峰,但其最强的405B版本模型900多GB的内存需求,对资源构成了更加苛刻的挑战。
Qianwen:Qianwen(千问)是阿里云推出的一系列大规模预训练语言模型。这些模型可以执行多种自然语言处理任务,包括但不限于文本生成、对话管理和代码理解。它们在多个基准测试中取得了优异的成绩,并且由于是开源的,可以被广大开发者用于各种应用和服务中。
ChatGLM:ChatGLM 是智谱AI发布的一款对话模型,基于智谱AI自主研发的中英双语对话模型ChatGLM2。智谱清言具有千亿级别的参数,并且提供了丰富的文档和代码功能,允许用户根据自己的行业需求对模型进行训练和优化。智谱清言的主要功能包括但不限于内容创作、信息归纳总结、通用问答、多轮对话等。智谱AI还在持续更新和改进其模型,例如发布了GLM-4开源模型,该模型相比之前的版本有了显著的能力提升。GLM-4-9B模型在综合能力上比ChatGLM3-6B提升了40%,并且在中文学科能力上提升了50%。此外,智谱AI还提供了支持多达26种语言、最高支持达1百万tokens长文本等功能。
GPT-J: 一个基于GPT-3架构的开源模型,具有60亿参数。
GPT-NeoX: 一个拥有200亿参数的开源模型,基于GPT-3架构。
BLOOM: 一个多语言模型,支持47种语言,具有1760亿参数。
2.2、开源文生图大模型
Stable Diffusion: 一个非常流行的开源模型,能够根据文本生成高质量的图像。
Sora: Colossal-AI团队发布的开源模型,支持从文本生成图像。
Kolors: 快手可图是由快手公司基于Stable Diffusion框架开发的大规模文本到图像生成模型,在图像质量和综合评分方面表现出色。
HunyuanDiT: 腾讯开源的混元文生图模型,采用DiT架构,支持中英文输入及理解。
2.3、 开源文生视频大模型
Open-Sora1.0: Colossal-AI团队开源的模型,能够从文本生成视频。
Make-a-Video: 由Meta AI团队发布,是一个能够根据文本生成视频的模型。
2.4、 其他相关模型
RCG (Representation Conditional Generation): 由麻省理工学院和Meta合作开发的模型,能够在没有人工标注的情况下生成图像。

三、2023-2024大模型关键进展
自2022年11月30日Chat GPT发布以来, AI大模型在全球范围内掀起了有史以来规模最大的人工智能浪潮 。 国内学术和产业界在过去一年也有了实质性的突破 。 大致可以分为三个阶段, 即准备期 (Chat GPT发布后国内产学研迅速形成大模型共识) 、 成长期 (国内大模型数量和质量开始逐渐增长) 、爆发期 (各行各业开 源闭源大模型层出不穷, 形成百模大战的竞争态势) 。

参考链接:
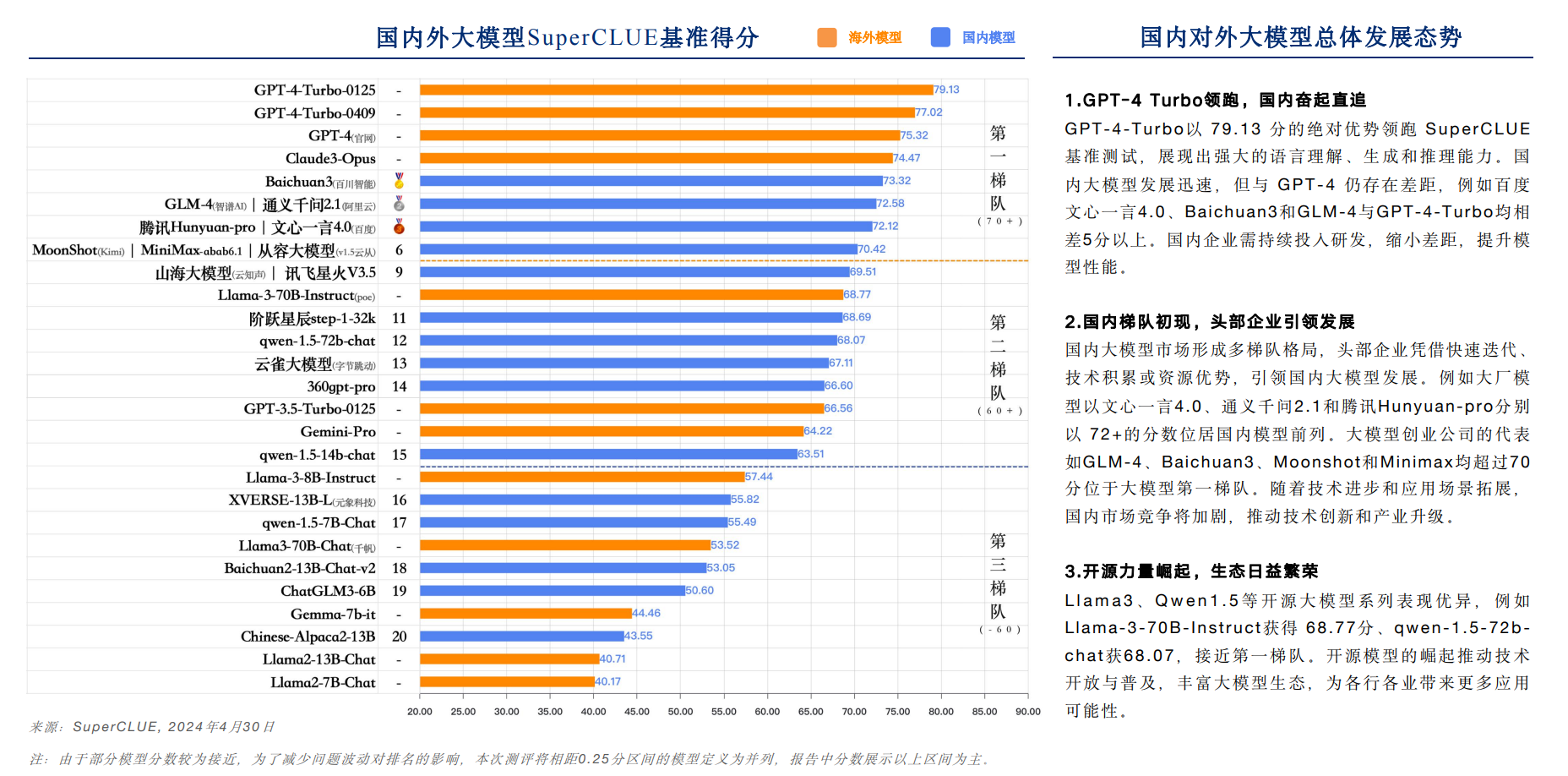
中文大模型基准测评2024年4月报告
GLM-4-9B:智谱AI推出了一个新的实力强大的小模型!
AI生图格局大震!Stable Diffusion 3开源倒计时,2B单机可跑碾压闭源Midjourney
Meta震撼发布Llama 3,一夜重回开源大模型铁王座
大模型千问2(Qwen2)系列新产品来了
腾讯混元文生图大模型开源:Sora 同架构,更懂中文