1. webdriver 反爬虫原理
爬虫程序可以借助渲染工具从动态网页中获取数据。
在这个过程中,“借助”其实是通过对应的浏览器驱动(即WebDriver)向浏览器发出指令的行为。因此,开发者可以根据客户端是否包含浏览器驱动这一特征来区分正常用户和爬虫程序。
webdriver 属性是我们最常听到的,通过 webdriver 驱动浏览器就会包含这一属性,因此可用来辨别爬虫程序(可检测的属性远不止这一种)。
WebDriver 检测的结果有3种,分别是true、false、undefined 。当我们使用的渲染工具有webdriver 属性时,navigator.webdriver 的返回值就是 true 。反之则会返回 false 或 undefine 。
由于 Selenium 通过 WebDriver 驱动浏览器,客户端的webdriver 属性存在,所以无法获得目标数据。注:Puppeteer 根据 DevTools 协议控制 Chrome 浏览器或 Chromium 浏览器,但 Puppeteer 也存在webdriver 属性。
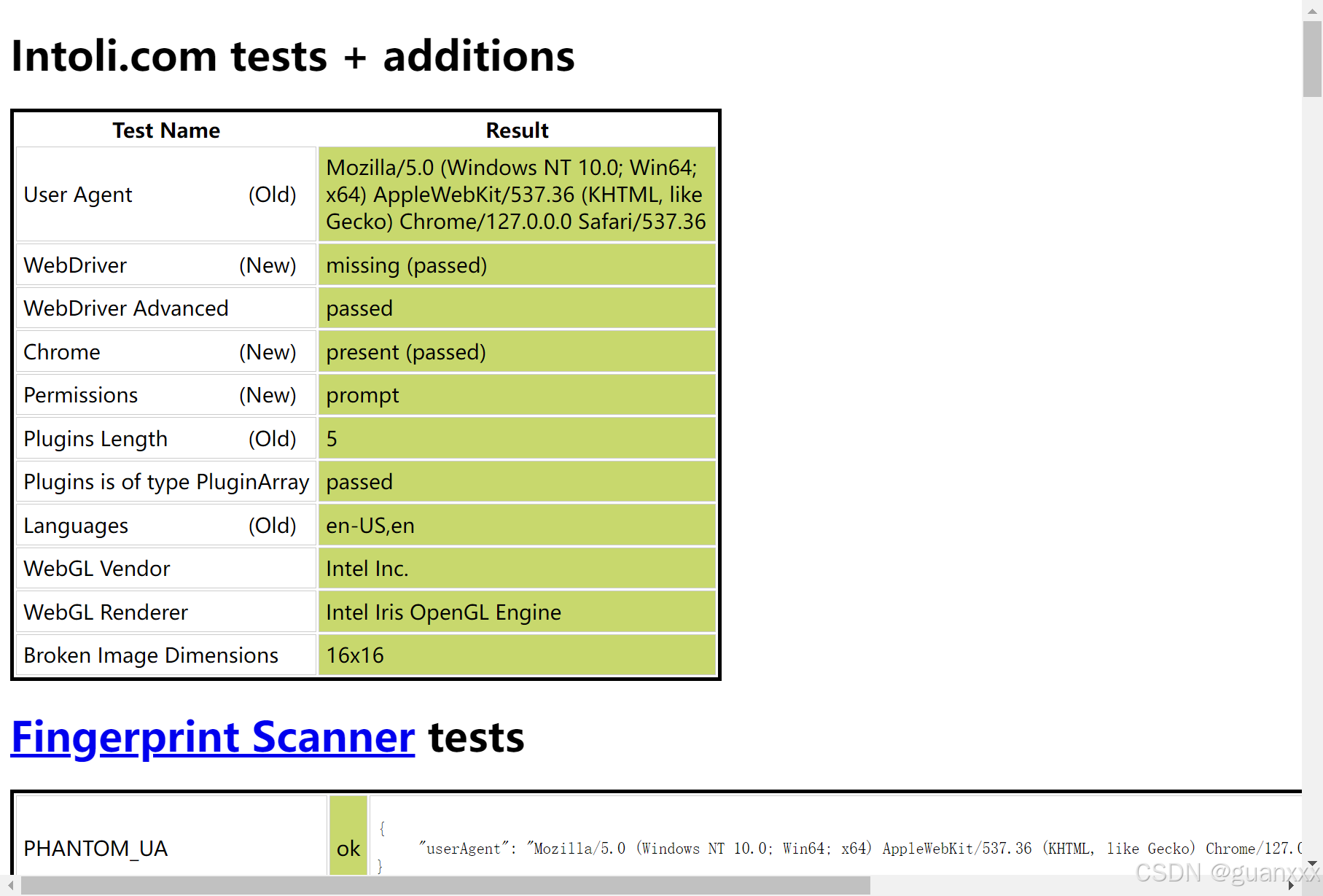
执行以下代码,会导致 webdriver 属性检测不通过,如下图:
from selenium.webdriver import Chromedriver = Chrome()url = 'https://bot.sannysoft.com/'driver.get(url)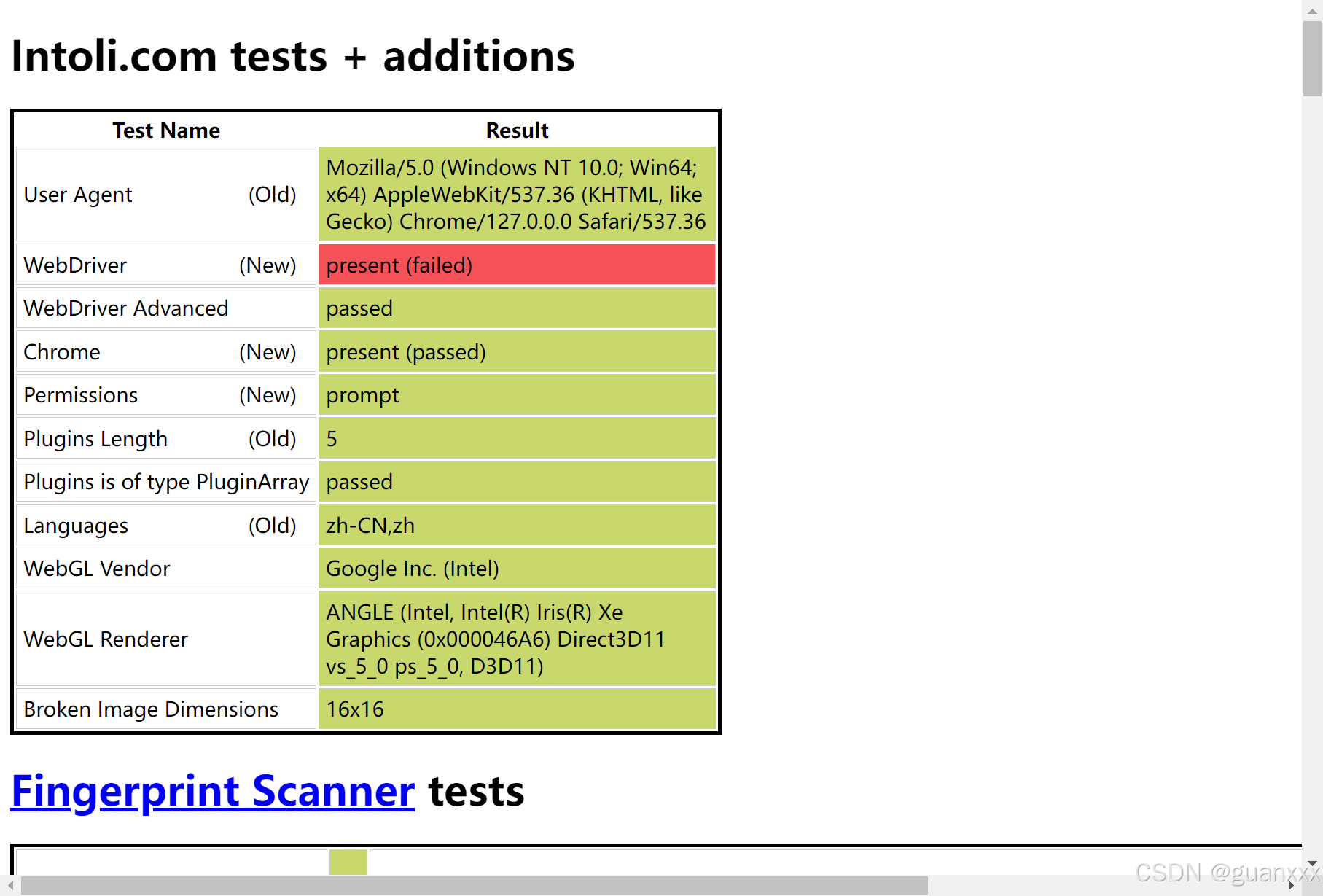
2. webdriver 识别绕过:方法 1
undetected_chromedriver 是一个防止浏览器指纹特征被识别的依赖库,使用 undetected_chromedriver.Chrome() 新建浏览器窗口,从而修改浏览器指纹特征。
注:可以使用 “pip install undetected-chromedriver” 安装这个 py 库。
执行以下代码,可通过 webdriver 属性检测,如下图:
import undetected_chromedriver as ucdriver = uc.Chrome()url = 'https://bot.sannysoft.com/'driver.get(url)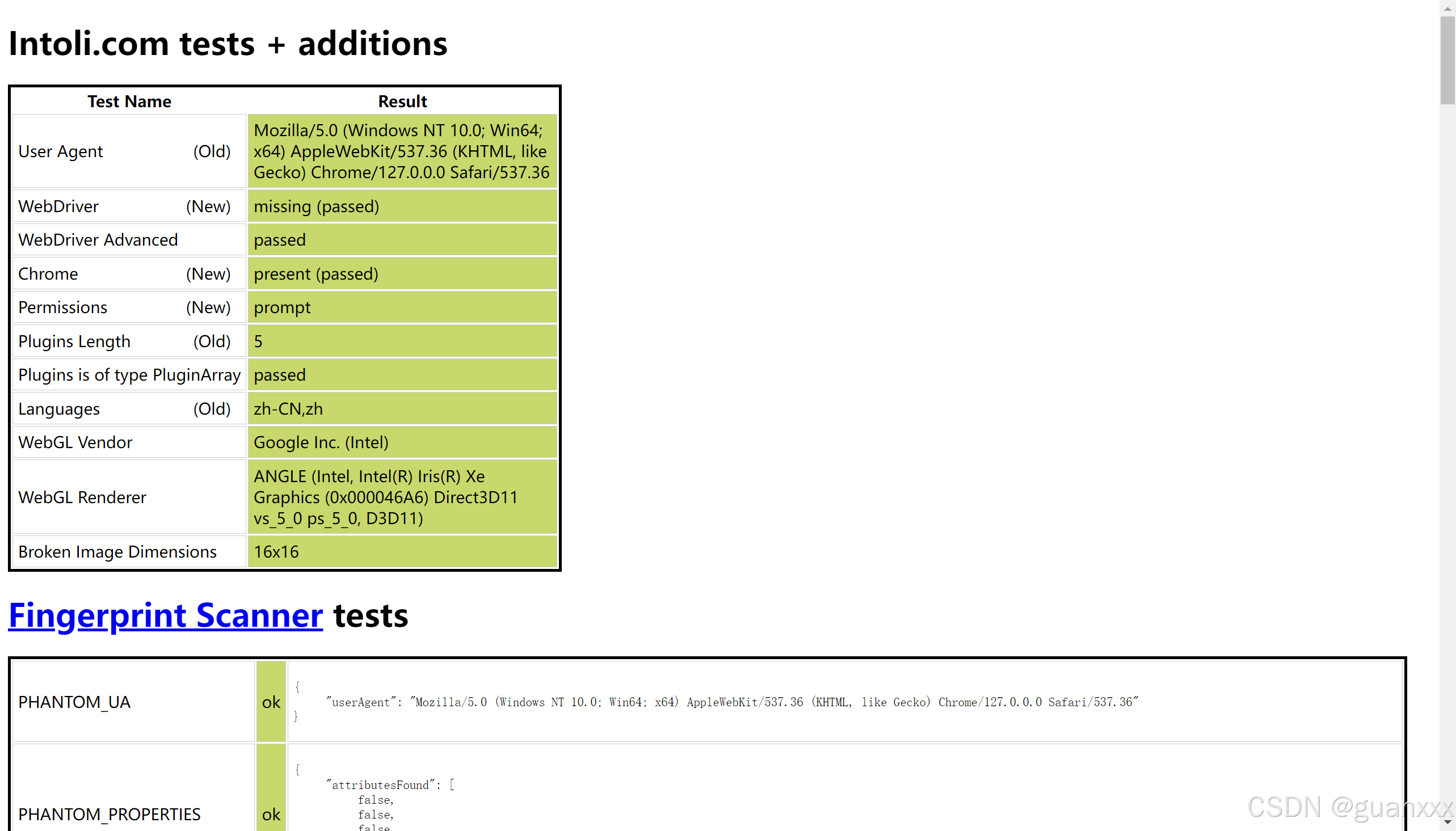
3. webdriver 识别绕过:方法 2
原理:通过执行 driver.execute_cdp_cmd 命令,可以在网页加载前运行 js 代码,从而改变浏览器的指纹特征
因为 webdriver 属性置空 js 代码有更改,同时最好修改不止一个属性,因此直接使用开源分享的 js 代码比较方便。
js 文件网址:https://github.com/berstend/puppeteer-extra/blob/stealth-js/stealth.min.js
stealth.min.js 这个文件包含了常用的浏览器特征,我们只需要读取文件,然后执行即可。
执行以下代码,可通过 webdriver 属性检测,如下图:
from selenium.webdriver import Chromedriver = Chrome()with open('stealth.min.js', encoding='utf-8') as f: driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {'source': f.read()}) # 在页面刚加载的时候执行JavaScript语句url = 'https://bot.sannysoft.com/'driver.get(url)