Web 信息查找与集成是搜索、检索、提取或集成 Web 资源以满足特定需求的活动,是实际生活中几乎所有领域中每个决策和解决问题的实体都必须执行的操作。
大型语言模型 (LLM) 与搜索引擎的集成重新定义了我们在网络上查找和使用信息的方式。因此,LLM 能够更好地理解自然语言查询,有助于提供更精确的搜索结果,同时考虑到适当的上下文。您能够组合的越多,可以形成的查询就越好,因为从不同来源提取和聚合信息的能力得到了很大的改善。即使在这些改进之后,诸如解决复杂查询、处理大量搜索结果以及集成到 LLM 的上下文长度限制等问题仍然存在。
一种新的人工智能模型将通过提高网络信息搜索和整合的效率和准确性来帮助解决这些问题。这种新人工智能模型背后的研究团队由中国科技大学的科学家以及上海人工智能实验室的学者组成。这项工作的动机是开发一个人工智能框架来模拟人类在网络信息搜索和整合中的基本认知过程。这种新的人工智能模型就是 Mindsearch。
MindSearch 是什么?
MindSearch 是一个开源项目,旨在通过网页模拟人类的信息检索、获取和整合行为。该框架利用多代理将复杂查询分解为子查询,并以巧妙的方式传递信息。这是一种强大而有效的提高相关性深度的方法,在基于主题的查询中具有直接应用。
MindSearch 的主要功能
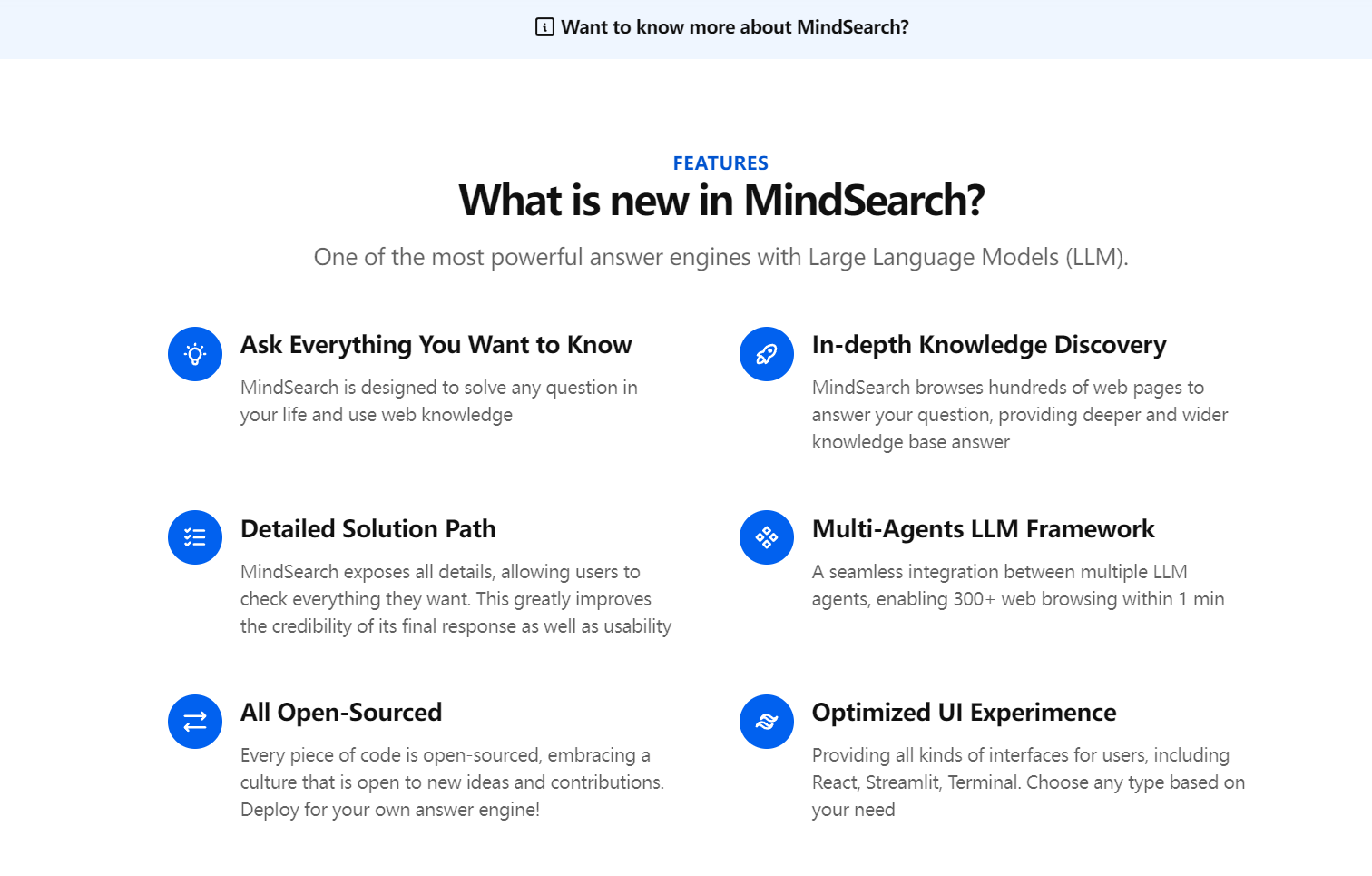
MindSearch 的功能/用例
快速文档搜索:MindSearch 使用 AI 在文档中搜索简短查询,提供更快的结果并节省检查多个文件的时间。运营效率:它最大限度地减少了文档搜索/检索过程,如果在专业环境中实施,则可以提高工作效率。科学研究:科学家可以访问其部门保存的大量文件中的相关信息。个人:无需翻阅页面即可快速找到您的个人文档和信息。聊天功能:提供不引人注目的聊天功能,用于系统的个人和专业交流。这些步骤之后的特性和功能使 mindsearch 成为一个灵活的工具,为网络信息搜索和多个领域的集成提供支持。
MindSearch 如何工作?(架构/设计)
MindSearch 的工作原理是将复杂的用户查询分解为较小的子问题。这意味着 WebPlanner 将把此查询模拟为动态图。
见下图:MindSearch 的一般工作流程由两个关键组件组成:WebPlanner 和 WebSearcher。WebPlanner 负责与多个 WebSearchers 一起安排推理步骤,它充当顶级规划器。
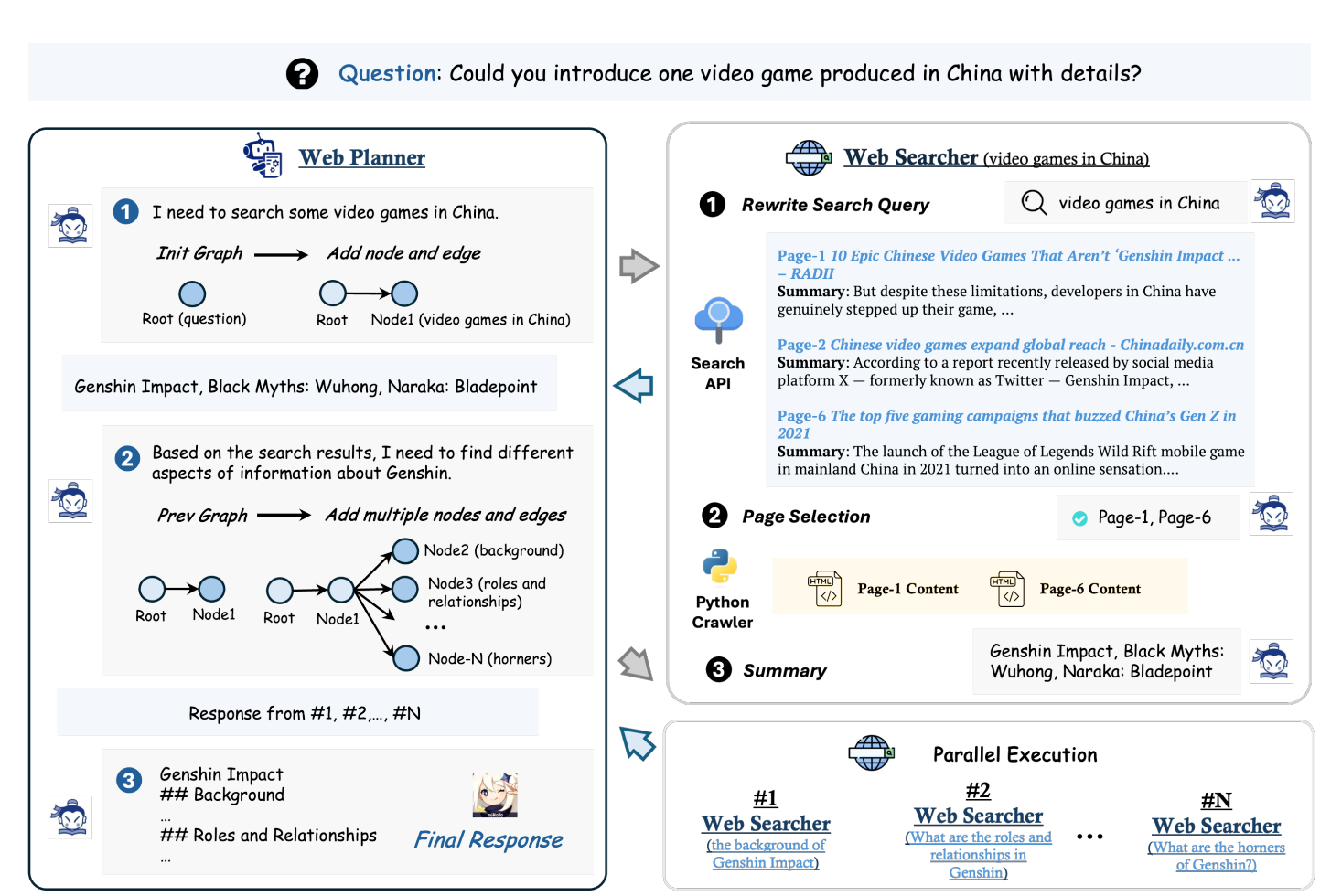
图形构建过程:图形构建是将用户查询分解为原子子查询,以图形中的节点表示。这使得编写复杂查询和管理长上下文变得容易。WebSearcher 通过引擎上的关键字执行分层搜索,并产生有价值的结果,供另一个机器人收集,然后是 WebPlanner。MindSearch 将推理和检索过程拆分为专门的代理,以便整个框架也可以并行从单个网页中搜索更多信息。
MindSearch 建立在 JADE 之上,为高性能搜索引擎信息搜索和集成系统中的多代理应用程序提供了一个易于使用的框架。这种明确的上下文管理和角色分配使 MindSearch 能够在短时间内从多个网页收集和整合信息。这种架构设计使 MindSearch 能够与专有 AI 搜索引擎竞争;从而为即将到来的研究和开发提供了一个令人鼓舞的解决方案。
MindSearch 中使用的技术和方法
以下是构建最终 MindSearch 模型所使用的人工智能和机器学习技术:
分层信息检索:使用分层信息检索来了解搜索引擎的工作原理,从搜索引擎中提取相关有价值的信息放入WebPlanner中。检索-增强-生成 (RAG):MindSearch 在 LLM 中采用基于 RAG 的搜索,将最新信息的检索与强大的解决方案生成相结合。代码生成:MindSearch 使用代码生成与图形交互并执行搜索,从而允许模型将复杂问题不断分解为可执行查询。有向无环图(DAG):这种表示形式传达了确定最佳执行路径的挑战,并且它通过具有易于理解的 LLM 性质的 DAG 正式表示。Python解释器:MindSearch使用python解释器来解释和执行代码,为规划器实现多样化的搜索结果,从而可以通过统一调用与图形进行交互。零样本学习:MindSearch 在零样本设置下工作,这意味着即使在部署阶段没有使用下游(目标)任务的数据,它也可以应用于新任务或领域。长上下文管理:为了应对长上下文任务,MindSearch 使用上下文管理机制来帮助模型关注关键细节并减少噪音。除上述内容外,前面几节已经介绍了一些内容,例如 LLM 的使用、图形构造、多智能体框架。所有这些技术和方法都真正提高了游戏水平,提供了比其他模型更好的响应质量和准确性。
绩效评估
上述过程是在 MindSearch 模型上执行的,它与其他模型 ChatGPT-Web、Perplexity.ai Pro 进行了竞争。深度、广度和事实性:对于下图所示的三种 2D 格式模型(没有任何知识掩码),MindSearch 与这些模型相比具有优越的性能。这一点很明显,因为 MindSearch 针对精细搜索生成详细的响应,而这些响应显然比其他模型更好。
除了开放集 QA 任务外,MindSearch 还在一些封闭集 QA 任务(Bamboogle、Musique 和 HotpotQA)上进行了测试。总体而言,如下表所示,MindSearch 在这些任务上的表现明显优于其他模型,包括 ReAct Search 和没有搜索引擎的原始 LLM。不同 LLM 后端(例如 GPT-4o 和 InternLM2.5–7b-chat)的 perflist 相似。这些结果证明 MindSearch 在回答查询的复杂问题方面表现非常出色。
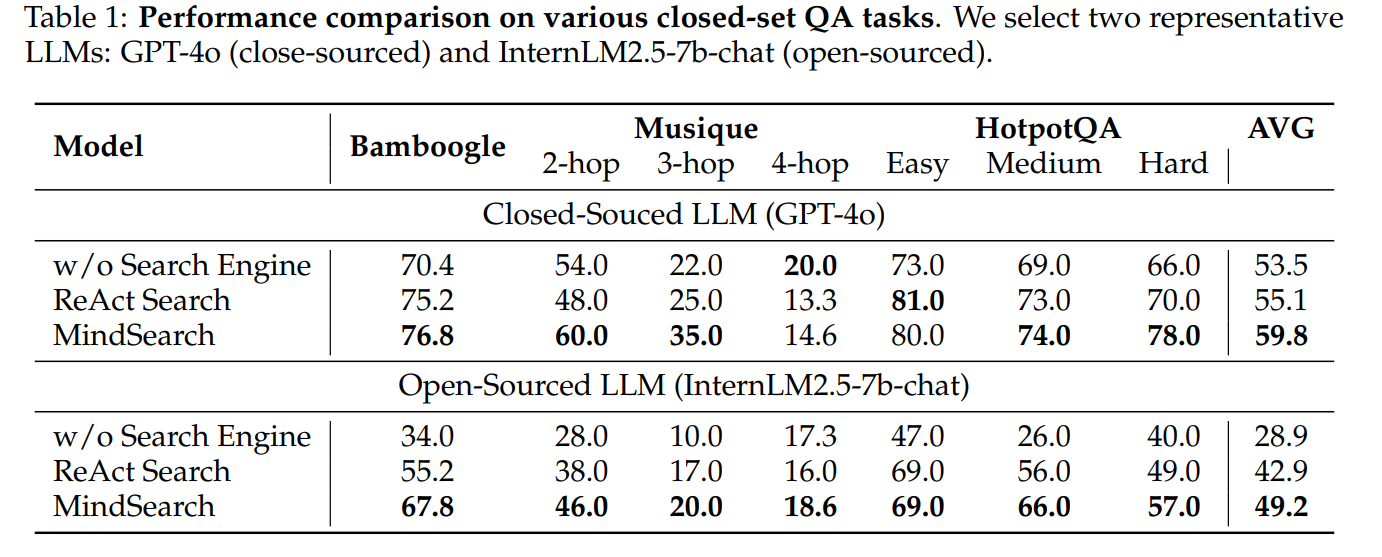
总体而言,性能测试表明,MindSearch 在响应质量和准确性方面优于其他模型。
如何访问和使用 MindSearch?
MindSearch 是 GitHub 上的一个开源项目。用户可以使用闭源 LLM(GPT、Claude)或开源 LLM(InternLM2.5–7b-chat)将其部署到自己的 perplexity.ai 风格搜索引擎中。该项目提供了有关设置 API、FastAPI 服务器和前端接口(React、Gradio、Streamlit、Terminal)的详细说明。许可结构为 Apache 2.0,可免费用于商业和非商业用途。
局限性和未来工作
虽然响应质量已经有了很大的改善,但 MindSearch 仍然有局限性。这里一个非常重要的问题是幻觉——在经过长时间的上下文对话后,模型可以得出任何与现实无关的答案。其次,搜索引擎可以并且经常会推广有偏见或过时的信息。虽然多代理设计能够处理复杂的查询,但如果操作不当,它可能会在管理这些迁移的上下文方面出现问题。
未来的研究可能会涉及事实核查机制、更好的上下文管理以及探索除搜索引擎之外的其他类型的信息源等任务。重新审视这些限制将使 MindSearch 等先锋解决方案发展成为更强大、更可靠的网络信息搜索/集成解决方案。
结论
MindSeach 是网络信息搜索和集成领域的一大进步。由于它与人类认知过程相似,因此还解决了该领域的许多其他问题。它构建为一个开源平台,提供高水平的性能,因此受到研究人员和商业受众的青睐。MindSearch — 未来可期!随着所有即将到来的进步,人工智能驱动的信息检索的未来,Mindsearch 正在占据重要地位。
关注我,每天带你开发一个AI应用。每周二四六直播,欢迎大家多多交流。
