
?个人主页:Yanni.—
?数据结构:Data Structure.
?C语言笔记:C Language Notes
?OJ题分享: Topic Sharing
目录
前言:
C++关键字
命名空间
命名空间介绍
命名空间的使用
C++的输入和输出
cout 输出
cin 输入
std命名空间的使用惯例
缺省参数
缺省参数概念
缺省参数分类
函数重载
函数重载概念
为什么c语言不支持重载
前言:
企业中面试中一般需要面向对象的两种主流语言C++和Java,现在java岗位虽然多,但是内卷严重,经过很长时间的思考,还是选择了C++,可能以后还会进入游戏开发的领域,这恰恰是我感兴趣的,C++前期的基础知识很难,但是过了这道难关之后情况会越来越来。Let's go!
C++关键字
C++ 总计 63 个关键字, C 语言 32 个关键字。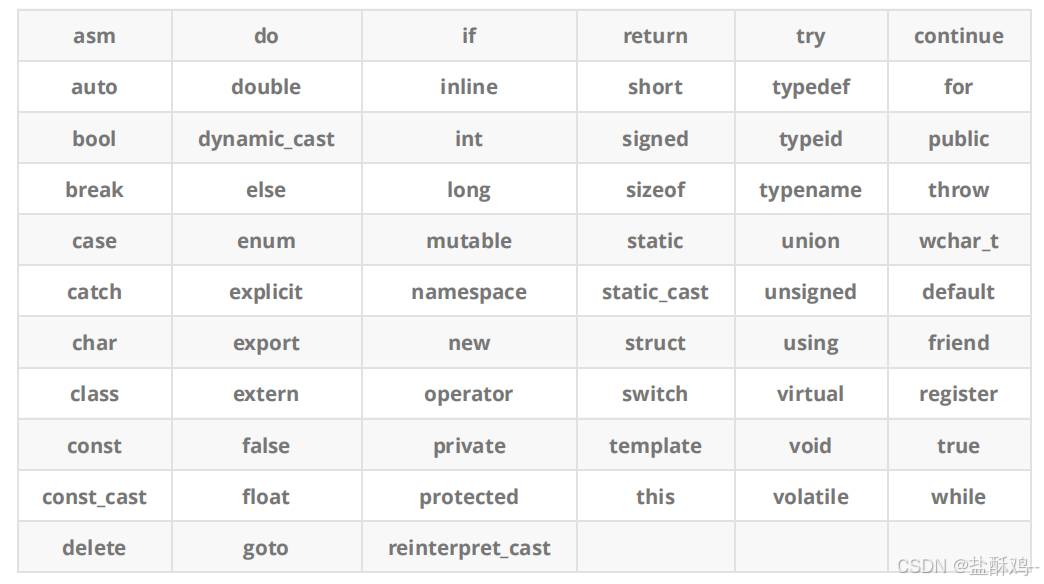
这里在C语言的基础上增加了许多关键字。
命名空间
命名空间介绍
在 C/C++ 中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存 在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是 对标识符的名称进行本地化 , 以 避免命名冲突或名字污染 , namespace 关键字的出现就是针对这种问题的。#include<stdio.h>#include<stdlib.h>int rand = 10;int main(){printf("%d", rand);return 0;}我们直到rand产生随机值,但是我们给出了一个全局变量rand,并且赋值了给它。这就导致:
“rand”: 重定义;以前的定义是“函数”。所以我们得避免命名冲突或名字污染。
命名冲突主要有两个:
1.库冲突
2.项目间,同时工作交接之间的互相命名冲突
因此定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{}即可,{} 中即为命名空间的成员。
#include<stdio.h>#include<stdlib.h>namespace Yanni{int rand = 10;}int main(){printf("%d", Yanni::rand);return 0;}命名空间的三个特性:
1.命名空间中可以定义变量/函数/类型。
2.命名空间可以嵌套。
3.同一个工程中是允许多种同名称的命名空间存在,编译器最后会成同一个命名空间内。
命名空间的使用
命名空间的使用主要有三种方式
1.加命名空间名称及作用域限定符
namespace Yanni // 命名空间名{int r = 10;}int main(){printf("%d", Yanni::r);return 0;}2.使用using将命名空间中某个成员引入
namespace Yanni{int r = 10;}using Yanni::r;int main(){printf("%d",r);return 0;}这个操作就想是将命名空间里的特定成员变成全局访问。
3.使用 using namespace 命名空间名称引入
namespace Yanni{int r = 10;}using namespace Yanni;int main(){printf("%d",r);return 0;}这就是将命名空间内的所有成员变成全局访问。
C++的输入和输出
cout 输出
#include<iostream>//std是C++标准库的命名空间名,C++将标准库的定义都放到这个命名空间中。using namespace std;int main(){cout << "hello world" << endl;//endl相当与换行符return 0;}cin 输入
在c语言中,我们定义变量都需要对变量进行初始化,而在C++中,就不需要初始化了,因为cin>>可以自动识别变量类型。
#include<iostream>//std是C++标准库的命名空间名,C++将标准库的定义都放到这个命名空间中。using namespace std;int main(){int a;double b;char c;cin >> a;cin >> b >> c;cout << a << b << c << endl;return 0;}std命名空间的使用惯例
std 是 C++ 标准库的命名空间,如何展开 std 使用更合理呢? 1. 在日常练习中,建议直接 using namespace std 即可,这样就很方便。 2. using namespace std 展开,标准库就全部暴露出来了,如果我们定义跟库重名的类型 / 对 象/ 函数,就存在冲突问题。该问题在日常练习中很少出现,但是项目开发中代码较多、规模 大,就很容易出现。所以建议在项目开发中使用,像std::cout 这样使用时指定命名空间 + using std::cout展开常用的库对象 / 类型等方式。
缺省参数
缺省参数概念
缺省参数是 声明或定义函数时 为函数的 参数指定一个缺省值 。在调用该函数时,如果没有指定实 参则采用该形参的缺省值,否则使用指定的实参。using namespace std;void Func(int a = 0){cout << a << endl;}int main(){Func();没有传参时,使用参数的默认值Func(10);传参时,使用限定的实参}缺省参数分类
全缺省参数
void Func(int a = 0,int b = 10,int c = 20){cout << a << endl;cout << b << endl;cout << c << endl;}半缺省参数
void Func(int a, int b = 10, int c = 20){cout << a << endl;cout << b << endl;cout << c << endl;}这里要注意的是:
1.半缺省参数必须从右往左依次来给出,不能间隔着给(传参的顺序的从左到右)
2.缺省参数不能再函数声明和定义中同时出现
3.缺省值必须是常量或者全局变量
4.c语言编译器不支持
函数重载
自然语言中,一个词可以有多重含义,人们可以通过上下文来判断该词真实的含义,即该词被重 载了。 比如:以前有一个笑话,国有两个体育项目大家根本不用看,也不用担心。一个是乒乓球,一个 是男足。前者是 “ 谁也赢不了! ” ,后者是 “ 谁也赢不了“。函数重载概念
函数重载: 是函数的一种特殊情况, C++ 允许在 同一作用域中 声明几个功能类似 的同名函数 ,这 些同名函数的 形参列表 ( 参数个数 或 类型 或 类型顺序 ) 不同 ,常用来处理实现功能类似数据类型 不同的问题。 1.参数类型不同int Add(int left, int right){cout << "int Add(int left, int right)" << endl;return left + right;}double Add(double left, double right){cout << "double Add(double left, double right)" << endl;return left + right;}2.参数个数不同
void Func(){cout << "void Func()" << endl;}void Func(int a){cout << "void Func(int a)" << endl;}3.参数类型顺序不同
void F(int a, char b){cout << "void F(int a, char b)" << endl;}void F(char b, int a){cout << "void F(char b, int a)" << endl;}为什么c语言不支持重载
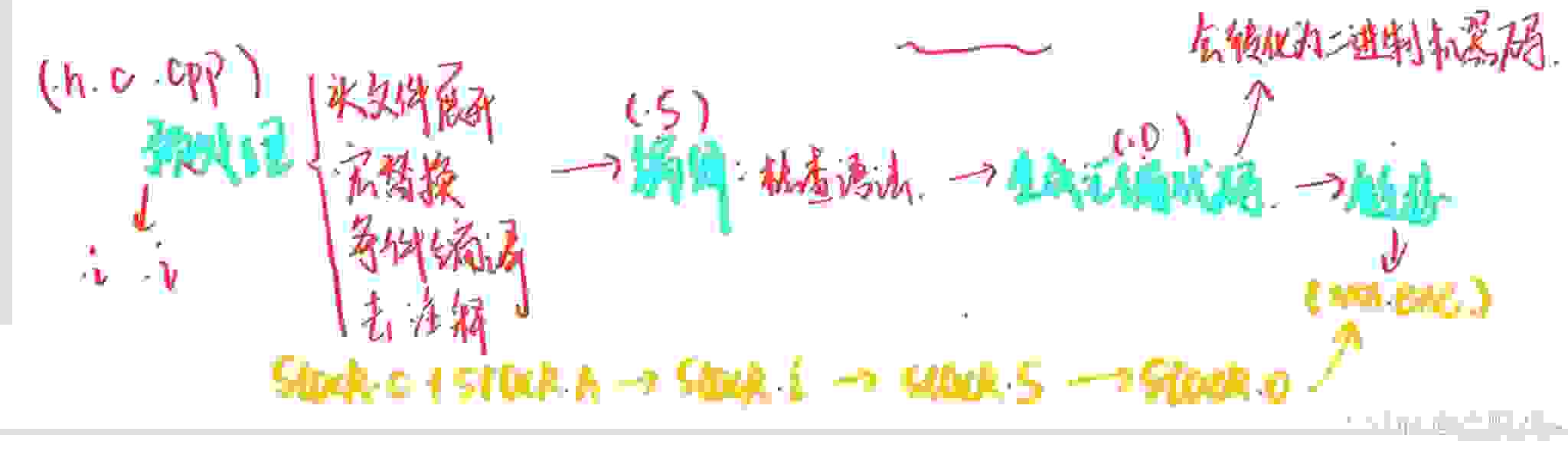
在 C/C++ 中,一个程序要运行起来,需要经历以下几个阶段: 预处理、编译、汇编、链接。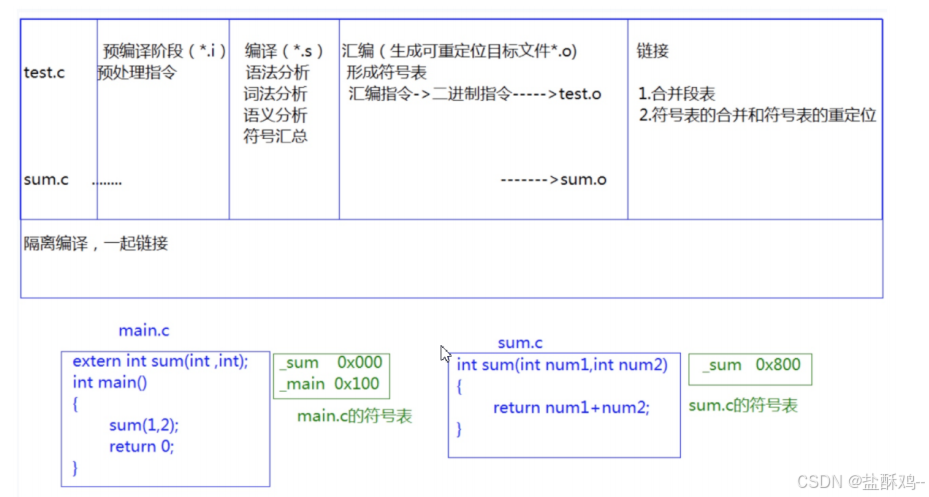 1. 实际项目通常是由多个头文件和多个源文件构成,而通过 C 语言阶段学习的编译链接,我们 可以知道,【当前 a.cpp 中调用了 b.cpp 中定义的 Add 函数时】,编译后链接前, a.o 的目标 文件中没有 Add 的函数地址,因为 Add 是在 b.cpp 中定义的,所以 Add 的地址在 b.o 中。那么 怎么办呢? 2. 所以链接阶段就是专门处理这种问题, 链接器看到 a.o 调用 Add ,但是没有 Add 的地址,就 会到 b.o 的符号表中找 Add 的地址,然后链接到一起 。 ( 老师要带同学们回顾一下 ) 3. 那么链接时,面对 Add 函数,链接接器会使用哪个名字去找呢?这里每个编译器都有自己的 函数名修饰规则。 4. 由于 Windows 下 vs 的修饰规则过于复杂,而 Linux 下 g++ 的修饰规则简单易懂,下面我们使 用了 g++ 演示了这个修饰后的名字。 5. 通过下面我们可以看出 gcc 的函数修饰后名字不变。而 g++ 的函数修饰后变成【 _Z+ 函数长度 + 函数名 + 类型首字母】。
1. 实际项目通常是由多个头文件和多个源文件构成,而通过 C 语言阶段学习的编译链接,我们 可以知道,【当前 a.cpp 中调用了 b.cpp 中定义的 Add 函数时】,编译后链接前, a.o 的目标 文件中没有 Add 的函数地址,因为 Add 是在 b.cpp 中定义的,所以 Add 的地址在 b.o 中。那么 怎么办呢? 2. 所以链接阶段就是专门处理这种问题, 链接器看到 a.o 调用 Add ,但是没有 Add 的地址,就 会到 b.o 的符号表中找 Add 的地址,然后链接到一起 。 ( 老师要带同学们回顾一下 ) 3. 那么链接时,面对 Add 函数,链接接器会使用哪个名字去找呢?这里每个编译器都有自己的 函数名修饰规则。 4. 由于 Windows 下 vs 的修饰规则过于复杂,而 Linux 下 g++ 的修饰规则简单易懂,下面我们使 用了 g++ 演示了这个修饰后的名字。 5. 通过下面我们可以看出 gcc 的函数修饰后名字不变。而 g++ 的函数修饰后变成【 _Z+ 函数长度 + 函数名 + 类型首字母】。 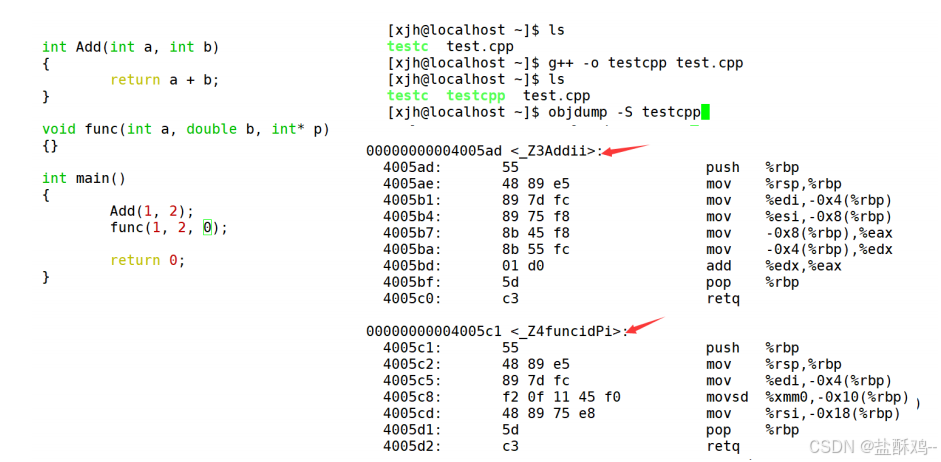
结论:在Linux下,采用g++编译完成后,函数名字的修饰发生改变,编译器将函数参数类型信息添加到修改的名字中。
好啦,这就是今天学习的分享啦!看到希望大家的三连呀!
如果有不当之处,欢迎大佬指正!