文章目录
一、sizeof和strlen的对⽐1.sizeof2.strlen3.sizeof与strlen对比 二、数组和指针笔试解析1.一维数组2.字符、字符串数组和字符指针代码1代码2代码3代码4代码5代码6 3.二维数组4.总结 三、指针运算笔试题解析代码1代码2代码3代码4代码5代码6
一、sizeof和strlen的对⽐
1.sizeof
在学习操作符的时候,我们学习了 sizeof , sizeof 计算变量所占内存内存空间大小的,单位是字节,如果操作数是类型的话,计算的是使用类型创建的变量所占内存空间的大小,它并不在意内存中存放什么数据
sizeof格式上有一个特点就是,如果计算的是变量的大小,可以省略小括号,当然还是建议都写上小括号,这样可以增加代码的可读性,现在我们使用sizeof举一下例:
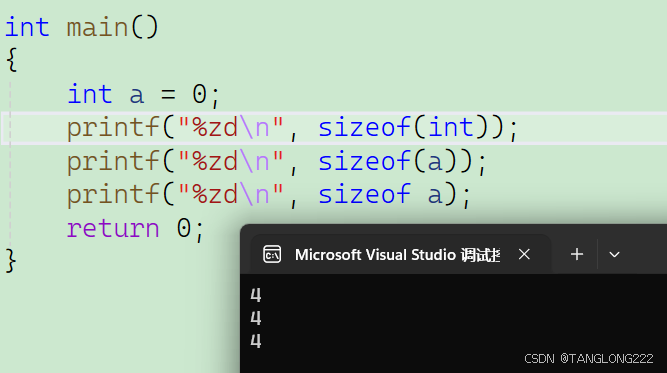
#include <stdio.h>int main(){int a = 0;printf("%zd\n", sizeof(int));printf("%zd\n", sizeof(a));printf("%zd\n", sizeof a);return 0;}运行结果:
2.strlen
strlen 是C语⾔库函数,功能是求字符串⻓度。函数原型如下:
size_t strlen ( const char * str ); 统计的是从 strlen 函数的参数 str 中这个地址开始向后, \0 之前字符串中字符的个数,strlen 函数会⼀直向后找 \0 字符,直到找到为止,所以可能存在越界查找
我们来看一个例子,来看看它的运行结果应该是什么:
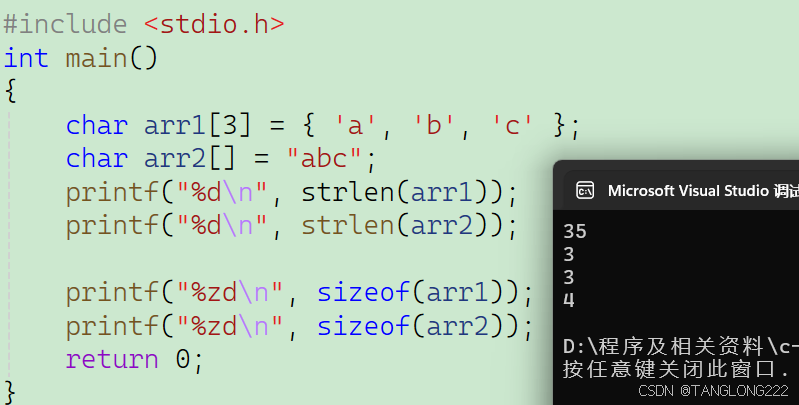
#include <stdio.h>#include <string.h>int main(){char arr1[3] = { 'a', 'b', 'c' };char arr2[] = "abc";printf("%d\n", strlen(arr1));printf("%d\n", strlen(arr2));printf("%zd\n", sizeof(arr1));printf("%zd\n", sizeof(arr2));return 0;} 首先我们来看前两个strlen,我们刚刚提到strlen会从当前地址慢慢往后找,直到找到\0,数组arr1和arr2的最大区别就是,arr1存放的就只是3个字符,并没有\0,所以strlen就会一直往后找,直到找到\0,我们也不知道什么时候能找到\0,所以会打印一个随机数
而arr2数组存放的是一个字符串,虽然看不出来有没有\0,但是实际上在字符串末尾会默认添加一个\0,所以实际上arr2数组存放的就是abc\0,然后strlen就可以正常帮我们计算字符串中字符的个数3
接下来我们来看看后面的两个sizeof,我们上面已经提到了数组arr1和数组arr2的区别,就是一个后面没有\0,一个有\0,所以在计算大小时,\0会被算上,所以sizeof(arr1)结果为3,sizeof(arr2)结果为4
我们来看看运行结果,看看我们分析的是否正确:
3.sizeof与strlen对比

二、数组和指针笔试解析
1.一维数组
我们来看一组代码,然后一个一个解析它们:
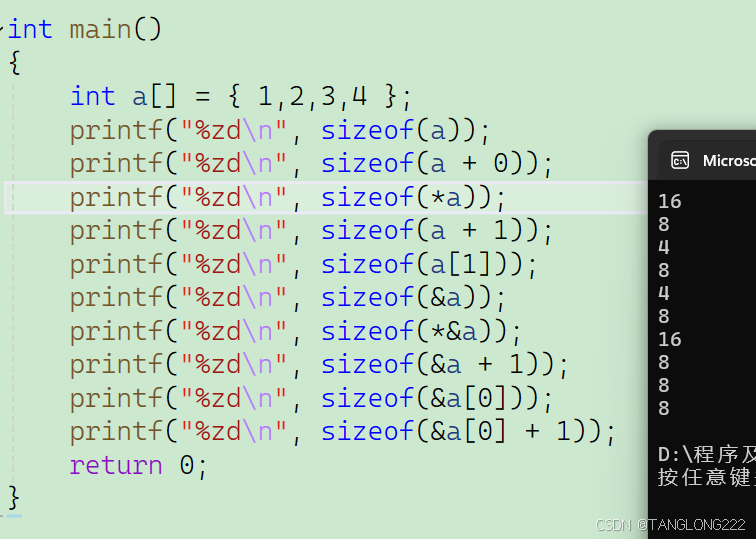
int a[] = {1,2,3,4};1.printf("%zd\n",sizeof(a));2.printf("%zd\n",sizeof(a+0));3.printf("%zd\n",sizeof(*a));4.printf("%zd\n",sizeof(a+1));5.printf("%zd\n",sizeof(a[1]));6.printf("%zd\n",sizeof(&a));7.printf("%zd\n",sizeof(*&a));8.printf("%zd\n",sizeof(&a+1));9.printf("%zd\n",sizeof(&a[0]));10.printf("%zd\n",sizeof(&a[0]+1));(1)我们之前讲过sizeof(数组名),其中数组名代表整个数组,会计算整个数组的大小,也就是16个字节
(2)给首元素地址加上整数0,虽然还是首元素地址,但是并不能看作sizeof(数组名),所以这里算的是首元素地址,是地址,大小就为4或8个字节,32位机器上就是4个字节,64位机器上就是8字节,这里解释一下,下面不再做解释了
(3)a是数组首元素地址,解引用就拿到了第一个元素,由于这是整型数组,每个元素都是整型,所以大小应该是4字节
(4)a是首元素地址,对它加一就是跳过一个元素,到下一个元素的地址,但是本质上还是地址,所以大小为4或8个字节
(5)a[1]是数组第二个元素,是整型,所以大小为4个字节
(6)这个题有一点坑,很容易做错,我们主要是要注意,&数组名是拿到整个数组的地址,它也是地址啊,所以大小是4或8字节
(7)对&数组名再解引用,相当于&和*相互抵消了,最后又变成了数组名,也就是sizeof(a),所以这里的a代表整个数组的大小,为16个字节
(8)这里&a拿到整个数组,加一后就是跳过整个数组,我们主要是要明白一点:地址±整数,还是地址,所以这里&a+1是一个地址,大小为4或8个字节
(9)a[0]是首元素,&a[0]就是取出首元素地址,是一个地址,所以大小为4或8个字节
(10)&a[0]拿到首元素地址,加一后拿到第二个元素的地址,还是一个地址,所以大小为4或8个字节
我们来看看代码运行结果(64位机器):
2.字符、字符串数组和字符指针
通过上面的练习,我们基本可以找到一些做题的规律,这里我们做一下有关字符、字符串数组的练习,首先是字符数组练习:
代码1
char arr[] = { 'a','b','c','d','e','f' };1.printf("%zd\n", sizeof(arr));2.printf("%zd\n", sizeof(arr + 0));3.printf("%zd\n", sizeof(*arr));4.printf("%zd\n", sizeof(arr[1]));5.printf("%zd\n", sizeof(&arr));6.printf("%zd\n", sizeof(&arr + 1));7.printf("%zd\n", sizeof(&arr[0] + 1));(1)sizeof(数组名),此时数组名代表整个数组,算出的是整个数组的大小,应该是6个字节
(2)数组名这里+0过后,虽然感觉上和数组名差不多,但是这里就只代表首元素地址,是一个地址,所以大小为4或8个字节
(3)arr是首元素地址,对它解引用,拿到的就是首元素,是一个字符型元素,所以大小为1个字节
(4)arr[1]是数组第二个元素,也是一个字符型元素,大小为1个字节
(5)&arr拿到整个数组的地址,但是也是地址,所以大小为4或8字节
(6)&arr+1就是跳过整个arr数组,但是得到的也是一个地址,所以大小为4或8字节
(7)&arr[0]是首元素地址,+1后得到的是第二个元素的地址,地址的大小为4或8字节
我们来看看在64位机器上的运行结果:
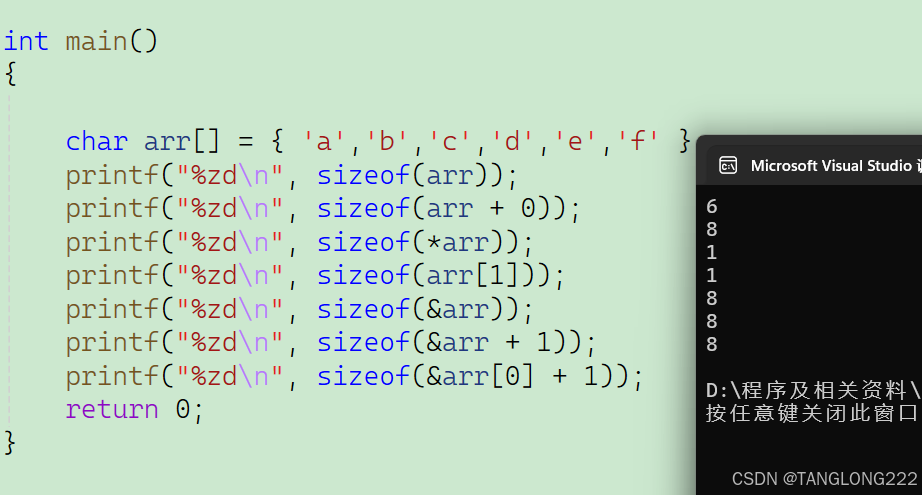
代码2
char arr[] = {'a','b','c','d','e','f'};1.printf("%zd\n", strlen(arr));2.printf("%zd\n", strlen(arr+0));3.printf("%zd\n", strlen(*arr));4.printf("%zd\n", strlen(arr[1]));5.printf("%zd\n", strlen(&arr));6.printf("%zd\n", strlen(&arr+1));7.printf("%zd\n", strlen(&arr[0]+1)); 这段代码与上面唯一区别就是把sizeof换成了strlen,我们之前也对它们做过对比,接下来我们开始分析:
(1)strlen的计算方式是去找字符串中的\0,没有遇到\0就会一直往后越界找,直到碰到了\0才会结束返回结果,而这里的arr数组是字符数组,并不是一个字符串,本身最后并没有\0,所以strlen会一直往后找,返回的也是一个随机值
(2)原理同(1),会返回一个随机值
(3)之前讲到strlen的时候我们讲过,strlen的参数应该是一个字符指针,但是这里*arr却是拿到了一个字符a,而不是一个地址,我们讲过字符在存储时是存储的是它的ascll码值,所以这里strlen会把a的ascll码值97当作一个地址,但是97这个编号的地址可能不属于该程序,所以会非法访问,也就是这个代码跑不通
(4)同(3)的原理,strlen会把字符b的ascll码值98当作地址,但是由于该地址可能不属于该程序,所以会非法访问,跑不通
(5)这里&arr得到的是一个类型为char ( * )[6]的数组指针,但是由于strlen接收的是字符指针,所以这里的数组指针会被强制类型转换成字符指针,由于&arr其实打印出来是首元素地址,只是±整数要跳过数组,所以这里强制类型转换后相当于还是首元素地址,此时就和(1)(2)一致,打印随机值
(6)&arr+1还是一个数组指针,会强制类型转换成字符指针,然后从那个位置一直往后数,碰到\0才结束,所以也是随机值
(7)这里相当于拿到第二个元素的地址,往后数还是因为没有\0,所以会打印随机值
这个部分稍微有点难,涉及到了strlen的参数,以及strlen的应用,可以自己多做两遍,现在我们来看看运行结果(64位机器):

代码3
从这里开始我们就开始练习字符串数组,如下:
char arr[] = "abcdef";1.printf("%zd\n", sizeof(arr));2.printf("%zd\n", sizeof(arr+0));3.printf("%zd\n", sizeof(*arr));4.printf("%zd\n", sizeof(arr[1]));5.printf("%zd\n", sizeof(&arr));6.printf("%zd\n", sizeof(&arr+1));7.printf("%zd\n", sizeof(&arr[0]+1));(1)由于字符串中默认会包含一个\0,所以我们在计算整个数组大小时,需要把它也算上,所以大小就是7个字节
(2)这里算的是数组arr首元素地址的大小,为4或8个字节
(3)这里算的是数组arr首元素的大小,为1个字节
(4)这里算的是数组arr第二个元素的大小,为1个字节
(5)这里&arr拿到整个数组的地址,是一个地址,大小为4或8个字节
(6)&arr+1就是跳过整个arr数组,但是得到的也是一个地址,大小也是4或8字节
(7)这里拿到的是第二个元素的地址,大小为4或8个字节
我们来看看代码运行结果(64机器):

代码4
char arr[] = "abcdef";1.printf("%zd\n", strlen(arr));2.printf("%zd\n", strlen(arr+0));3.printf("%zd\n", strlen(*arr));4.printf("%zd\n", strlen(arr[1]));5.printf("%zd\n", strlen(&arr));6.printf("%zd\n", strlen(&arr+1));7.printf("%zd\n", strlen(&arr[0]+1));(1)由于字符串后面会默认添加一个\0,所以strlen可以正常计算字符串中字符的个数,为6
(2)同(1),算出字符串中字符的个数,为6
(3)这里跟上面代码2中的(3)一样,会异常访问,跑不通
(4)同代码2中的(4)
(5)这里会把数组指针强制转换成字符指针,然后就变成首元素地址,在这里字符串中有\0,可以正常计算出6
(6)这里&arr+1会跳过整个arr数组,然后往后面数,这时候就没有\0了,会一直往后数,所以会算出一个随机值
(7)这里拿到第二个元素的地址,可以正常从第二个元素计算走,最后算出5
我们来看看代码运行结果(64机器):

代码5
从这里开始我们练习字符指针,如下:
char *p = "abcdef";1.printf("%zd\n", sizeof(p));2.printf("%zd\n", sizeof(p+1));3.printf("%zd\n", sizeof(*p));4.printf("%zd\n", sizeof(p[0]));5.printf("%zd\n", sizeof(&p));6.printf("%zd\n", sizeof(&p+1));7.printf("%zd\n", sizeof(&p[0]+1));(1)我们讲过如果把一个字符串常量赋给一个字符指针,实际上就是把字符串常量的第一个字符的地址传给这个字符指针,这个式子中p就是第一个字符的地址,大小为4或8个字节
(2)p+1后拿到第二个字符的地址,还是一个地址,大小为4或8个字节
(3)对p进行解引用后就拿到了字符a,它的大小就是1个字节
(4)p[0]这个表达也是拿到这个字符串的第一个字符,相当于它也可以当做数组使用,所以大小为1个字节
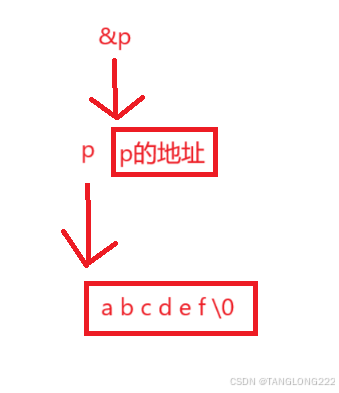
(5)p本身就是一个地址,再对它取地址就是二级指针,也是一个地址,大小为4或8个字节,下面是&p的图解:
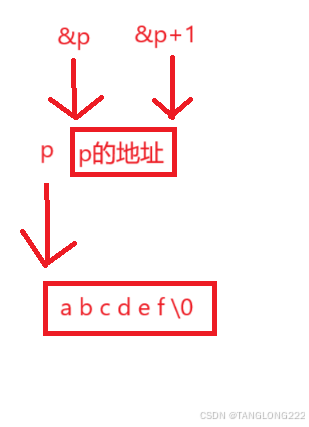
(6)对一个二级指针+1后还是一个地址,所以大小为4或8个字节,下面是&p+1的图解:
(7)这里&p[0]相当于拿到了字符串第一个字符的地址,相当于就是p,+1后就是第二个字符的地址,所以大小为4或8个字节
我们来看看代码运行结果(64机器):

代码6
char *p = "abcdef";1.printf("%zd\n", strlen(p));2.printf("%zd\n", strlen(p+1));3.printf("%zd\n", strlen(*p));4.printf("%zd\n", strlen(p[0]));5.printf("%zd\n", strlen(&p));6.printf("%zd\n", strlen(&p+1));7.printf("%zd\n", strlen(&p[0]+1));(1)这里p是第一个字符的地址,然后字符串中默认有\0,所以strlen可以正常使用,算出字符个数6
(2)p+1变成第二个字符的地址,所以strlen从第二个字符往后面数,可以算出字符个数5
(3)同代码2的(3)
(4)同代码2的(4)
(5)这里拿到一个二级指针,指向一级字符指针p,会强制类型转换成一级字符指针,但是这里原本拿到的是p的地址,谁也不知道在哪里,后面什么时候碰到\0也是不确定的,所以最后strlen会一直往后面找,直到随机值出现\0,然后中止,所以会返回一个随机值
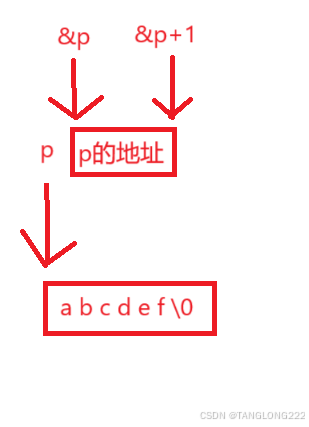
(6)这里对二级指针+1后会跳过一级指针p,后面会碰到什么也是随机的,多久碰到\0也是随机的,所以会返回一个随机值,如下图:
(7)这里&p[0]相当于拿到了字符串第一个字符的地址,相当于就是p,+1后就是第二个字符的地址,然后正常往后计算得到结果5
我们来看看代码运行结果(64机器):

3.二维数组
相信做了上面的题对一维数组有了很清晰的认识,接下来我们来练习一段二维数组的题:
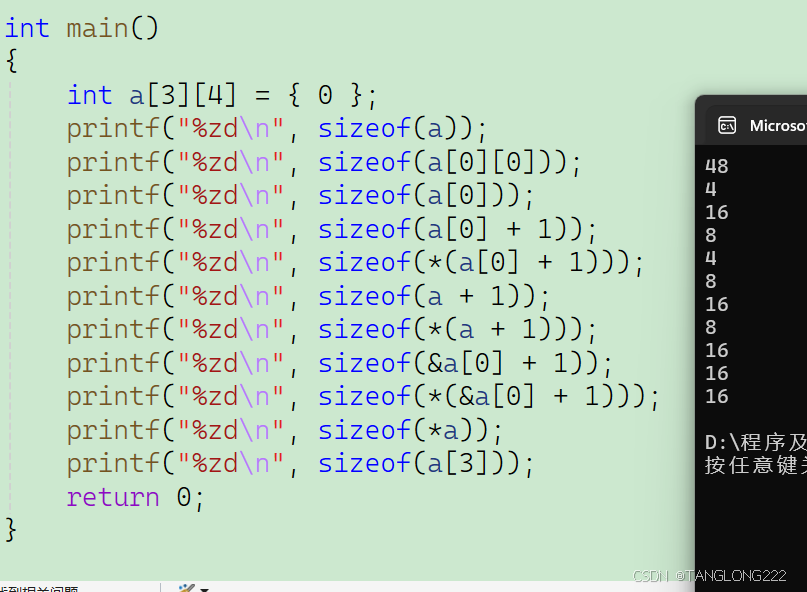
int a[3][4] = {0};1.printf("%zd\n",sizeof(a));2.printf("%zd\n",sizeof(a[0][0]));3.printf("%zd\n",sizeof(a[0]));4.printf("%zd\n",sizeof(a[0]+1));5.printf("%zd\n",sizeof(*(a[0]+1)));6.printf("%zd\n",sizeof(a+1));7.printf("%zd\n",sizeof(*(a+1)));8.printf("%zd\n",sizeof(&a[0]+1));9.printf("%zd\n",sizeof(*(&a[0]+1)));10.printf("%zd\n",sizeof(*a));11.printf("%zd\n",sizeof(a[3]));(1)二维数组也是一样,这里的数组名代表整个数组,计算的是整个数组的大小,大小应该是3 * 4 * 4,结果为48
(2)这里a[0][0]得到的是二维数组a的第一行第一列的元素,是一个整型,所以大小为4个字节
(3)这里a[0]相当于这个二维数组的第一行的数组名,计算的是整个第一行的大小,为16个字节
(4)这里a[0]相当于是第一行的数组名,也就是第一行第一个元素的地址,+1后变成第二个元素的地址,是一个地址,所以大小为4或8个字节
(5)a[0]+1相当于就是第一行第二个元素的地址,解引用后就拿到这个元素,是一个整型,大小为4个字节
(6)这里a作为二维数组的数组名,没有单独放在sizeof中,所以代表的是这个二维数组的第一个元素,也就是相当于整个二维数组第一行的地址,+1后变成第二行的地址,是一个地址,所以大小为4或8个字节
(7)这里相当于对二维数组的第二行解引用,拿到整个第二行,大小就是16个字节
(8)这里&a[0]相当于就是拿到整个第一行的地址,+1后跳过整个第一行,变成第二行的地址,是一个地址,所以大小为4或8个字节
(9)这里&a[0]+1相当于就是整个第二行的地址,也就是&a[1],解引用后变成了a[1],相当于拿到第二行的数组名,计算整个第二行的大小,大小为16个字节
(10)这里a相当于就是二维数组的第一行,解引用后拿到第一行,所以算出来是16个字节
(11)这里a[3]越界访问了,相当于二维数组的第4行,这个二维数组本身没有第四行,但是程序还是会帮我们越界去访问,拿到与前三行相同结构的一行,所以最后还是会计算出来一行的大小,为16字节
我们来看看代码运行结果(64机器):
4.总结
数组名的意义:
sizeof(数组名),这⾥的数组名表示整个数组,计算的是整个数组的大小&数组名,这里的数组名表示整个数组,取出的是整个数组的地址除此之外所有的数组名都表示首元素的地址三、指针运算笔试题解析
代码1
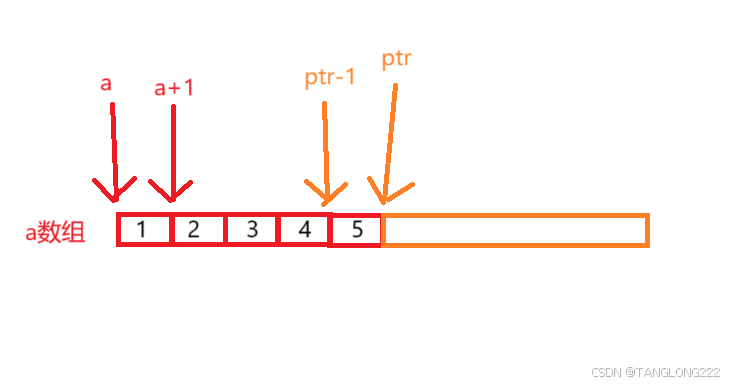
#include <stdio.h>int main(){ int a[5] = { 1, 2, 3, 4, 5 }; int *ptr = (int *)(&a + 1); printf( "%d,%d", *(a + 1), *(ptr - 1)); return 0;}//程序的结果是什么? 我们主要来看看整型指针ptr是什么,首先&a是取出整个数组的地址,+1后跳过了整个a数组,然后将这个地址强制类型转换成了int*,我们要知道强制类型转换前后的区别,强制类型转换后±整数跳过的单位是整型,而之前是以整个数组为单位跳过
接着来看*(a+1),a在这里是首元素地址,+1后变成第二个元素的地址,解引用后就拿到第二个元素,也就是2
最后就是 * (ptr-1),我们知道ptr指向的是a数组的下一个数组的首元素地址,那么现在ptr是整型指针,-1后不就成了a数组的最后一个元素的地址,解引用就拿到最后一个元素,也就是5,如图:
最后来看看运行结果:

代码2
//在X86环境下//假设结构体的⼤⼩是20个字节//程序输出的结果是啥?#include <stdio.h>struct Test{int Num;char* pcName;short sDate;char cha[2];short sBa[4];}*p = (struct Test*)0x100000;int main(){printf("%p\n", p + 1);printf("%p\n", (unsigned long)p + 1);printf("%p\n", (unsigned int*)p + 1);return 0;} 首先我们来看p+1,可以看到p是一个结构体指针,并且被赋值为0x100000,所以+1后会跳过整个结构体,而整个结构体的大小是20个字节,所以不难猜到p+1的结果为100020
随后我们来看(unsigned long)p + 1,这个就比较难了,由于这里p被强制类型转换成了无符号长整型,所以此时的p变成了一个数字,+1就是+1,变成了数字的加减法,所以最后打印结果应该是100001
我们来看最后一个表达式(unsigned int*)p + 1,这里就比较简单了,相当于还是被转换成了整型指针,+1后就跳过4个字节,打印结果为100004
最后来看看运行结果:

代码3
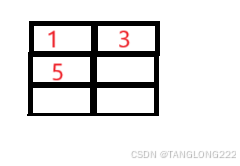
#include <stdio.h>int main(){ int a[3][2] = { (0, 1), (2, 3), (4, 5) }; int *p; p = a[0]; printf( "%d", p[0]); return 0;} 这里我们主要要看出来(0,1)这种表达式是什么含义,是不是给它第一行的两个元素初始化为0和1呢?很明显不是,因为如果是这样应该使用大括号{},而不是小括号()
那它是什么呢?它只是一个被小括号括起来的逗号表达式,第一个逗号表达式结果为1,第二个为3,第三个为5,所以这个二维数组最后应该长这个样子:
然后这里说把a[0],也就是二维数组第一行的数组名赋值给p,现在p就相当于二维数组第一行的数组名,所以p[0]就是第一行第一个元素,也就是1
我们来看看代码运行结果:
代码4
//假设环境是x86环境,程序输出的结果是啥?#include <stdio.h>int main(){ int a[5][5]; int(*p)[4]; p = a; printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]); return 0;} 这里的p是一个元素个数为4的整型数组指针,而这里a是首元素的地址,也就是代表了二维数组第一行的地址,类型为int (*)[5],这里把a赋给p就会发生类型转换
相当于就是p接收了a存放的地址,但是它变得一次只能跳过4个元素了,这个题我们最好画图解决,我们先分别找到a[4][2]和p[4][2],如图:
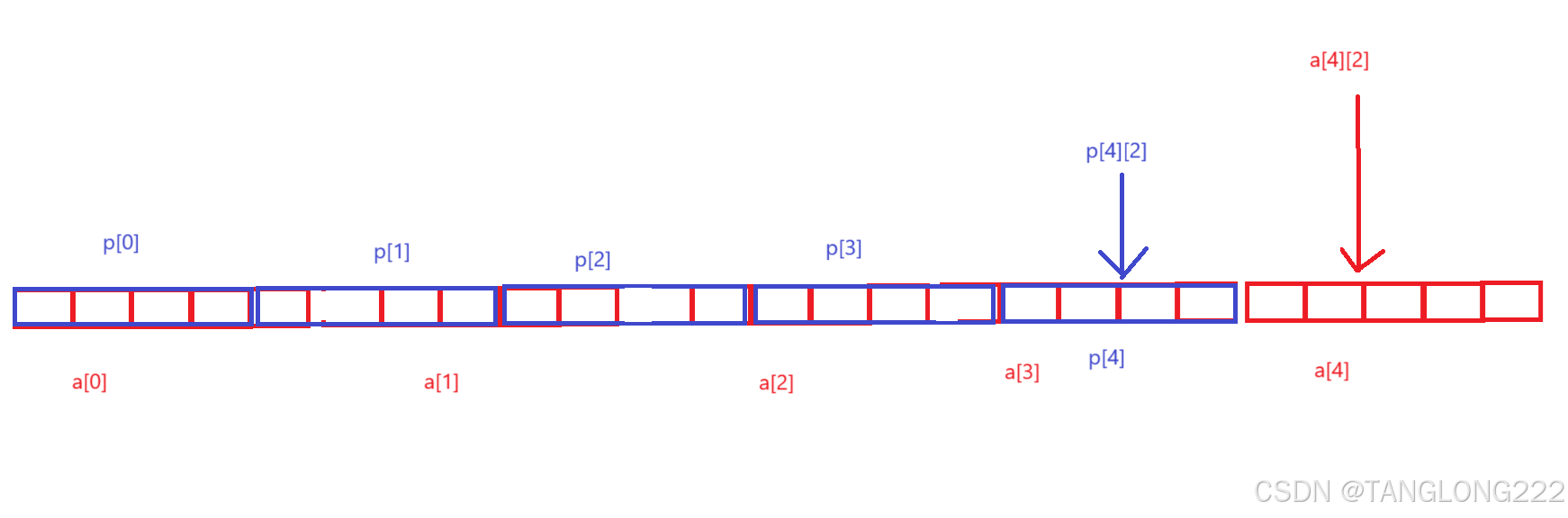
其中蓝色四个方块代表p,红色5个方块代表a,我们可以看到&p[4][2]和&a[4][2]相隔了4个元素,而&p[4][2]比&a[4][2]小,所以减出来是-4
当它以%p打印时会转换成补码,并且以16进制形式打印,而%d形式则会直接打印-4,这里就不再演示-4转换为补码等等步骤,有兴趣可以自行操作
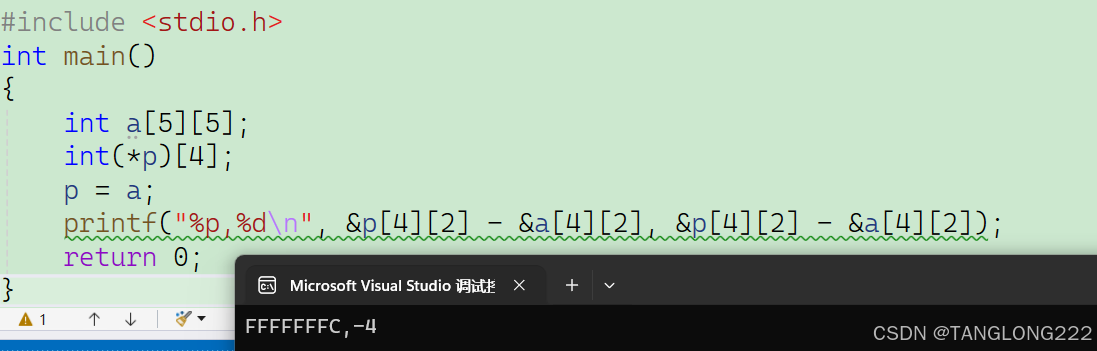
最后我们来看看代码执行结果:
代码5
#include <stdio.h>int main(){ int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 }; int *ptr1 = (int *)(&aa + 1); int *ptr2 = (int *)(*(aa + 1)); printf( "%d,%d", *(ptr1 - 1), *(ptr2 - 1)); return 0;} 这个题和我们的代码1有点类似,只是这里变成二维数组了
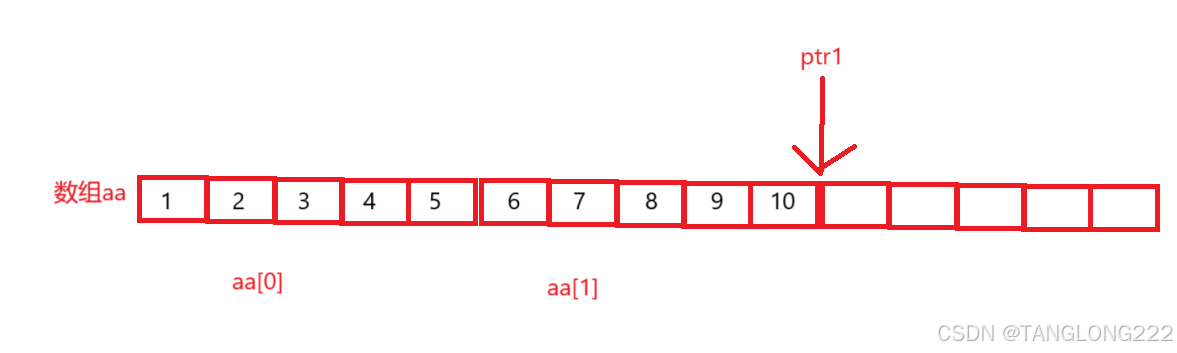
首先我们来看ptr1,&aa是拿到整个二维数组的地址,+1后跳过整个二维数组,然后再将其转换为整型指针,如图:
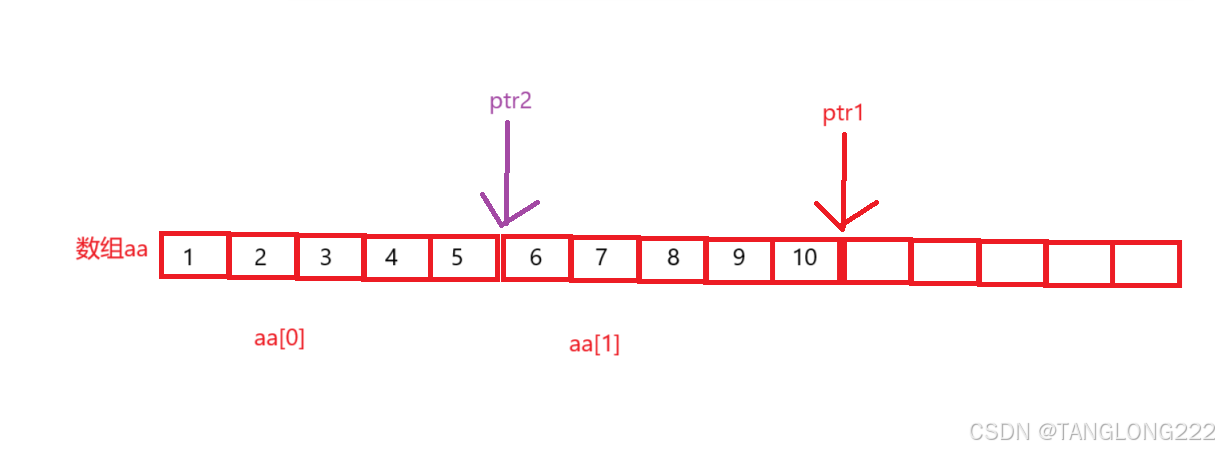
然后我们来看ptr2,这里aa相当于第一行的地址,+1后拿到第二行的地址,相当于就是&aa[1],所以解引用后相当于拿到了第二行的数组名aa[1],此时它就代表第二行的首元素地址,所以ptr2在如图位置:
所以ptr1-1和ptr2-1的位置如图:
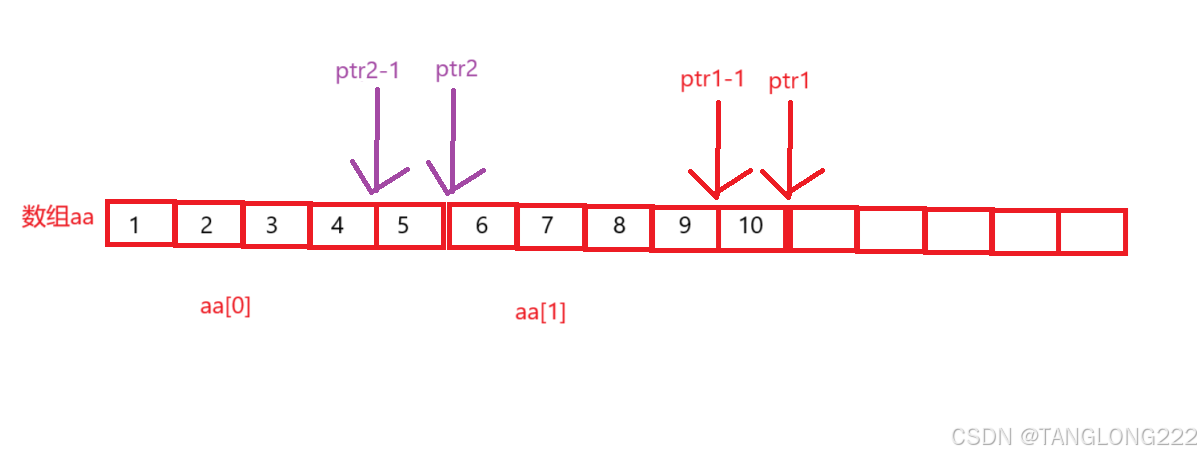
所以它们分别代表的值为10和5,我们来看看运行结果:
代码6
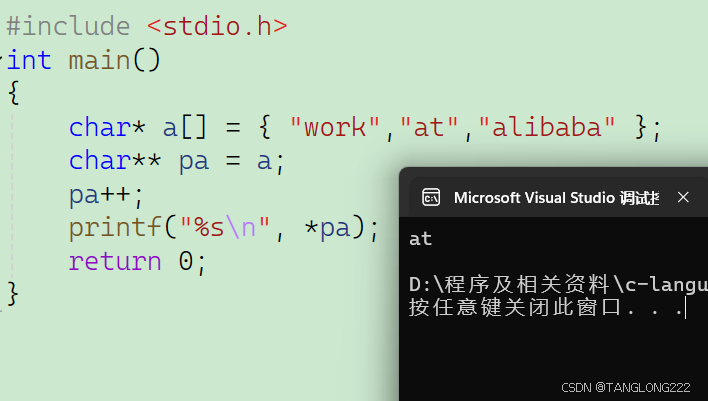
#include <stdio.h>int main(){ char *a[] = {"work","at","alibaba"}; char**pa = a; pa++; printf("%s\n", *pa); return 0;} 我们首先来看a数组,这里a数组是一个字符数组指针,存放的分别是三个常量字符串的首字符地址
然后再来看pa,这里的a代表首元素的地址,也就是字符串第一个字符w的地址,把w的地址存放进了二级指针pa中,如图:
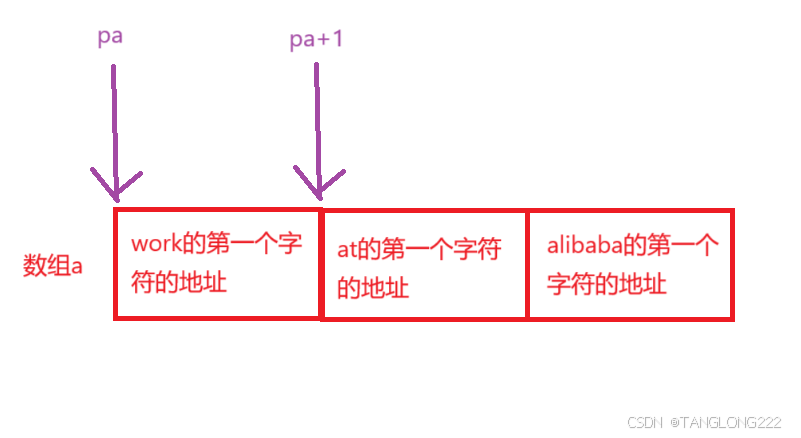
然后*pa就相当于at的第一个字符a的地址,然后以%s的形式打印,就会打印出来字符串at,运行结果如下: