本专栏主要是提供一种国产化图像识别的解决方案,专栏中实现了YOLOv5/v8在国产化芯片上的使用部署,并可以实现网页端实时查看。根据自己的具体需求可以直接产品化部署使用。

YOLO:简史
YOLO(You Only Look Once)是一种流行的物体检测和图像分割模型,由华盛顿大学的约瑟夫-雷德蒙(Joseph Redmon)和阿里-法哈迪(Ali Farhadi)开发。YOLO 于 2015 年推出,因其高速度和高精确度而迅速受到欢迎。
2016 年发布的 YOLOv2 通过纳入批量归一化、锚框和维度集群改进了原始模型。
2018 年推出的 YOLOv3 使用更高效的骨干网络、多锚和空间金字塔池进一步增强了模型的性能。
YOLOv4 于 2020 年发布,引入了 Mosaic 数据增强、新的无锚检测头和新的损失函数等创新技术。
YOLOv5 进一步提高了模型的性能,并增加了超参数优化、集成实验跟踪和自动导出为常用导出格式等新功能。
YOLOv6 于 2022 年由美团开源,目前已用于该公司的许多自主配送机器人。
YOLOv7 增加了额外的任务,如 COCO 关键点数据集的姿势估计。
YOLOv8 是YOLO 的最新版本,由Ultralytics 提供。YOLOv8 YOLOv8 支持全方位的视觉 AI 任务,包括检测、分割、姿态估计、跟踪和分类。这种多功能性使用户能够在各种应用和领域中利用YOLOv8 的功能。
YOLOv9 引入了可编程梯度信息 (PGI) 和广义高效层聚合网络 (GELAN) 等创新方法。
YOLOv10 是由清华大学的研究人员使用该软件包创建的。 UltralyticsPython 软件包创建的。该版本通过引入端到端头(End-to-End head),消除了非最大抑制(NMS)要求,实现了实时目标检测的进步。
YOLO的理解
本专栏的目标是能够通过专栏的学习掌握yolo的使用方法,也就是更多的偏向应用层而不是理论层。所以大部分内容总结都是我个人在学习整理过程中的一些心得体会,可能没有那么准确仅作参考。
如果想要了解YOLO各版本的具体差异可以参考这篇博客,已经很完整的介绍了具体内容,当然如果你是第一次接触YOLO可以先不用看。大部分内容是看不懂的。
YOLO系列算法精讲:从yolov1至yolov8的进阶之路(2万字超全整理)
自问自答1:为什么专栏中主要说的是YOLOv5和v8
yolo自诞生以来版本的更新很快,其中我们也看到了有很多国人的影子,比如v6版本美团开源,v10版本清华开源。
但是在我看来比较正统的版本就是YOLOv5和v8,这两个版本都是来自于Ultralytics公司,并且自v8版本之后github上的项目名称以ultralytics进行命名。
v6和v7版本都是在v5的整体版本上面修改而成,v10版本是基于v8版本改进而成。可见这两个版本在YOLO系列中的影响力了。
YOLO v5 Github源码地址:[https://github.com/ultralytics/yolov5](https://github.com/ultralytics/yolov5)YOLO v8 Github源码地址:[https://github.com/ultralytics/ultralytics](https://github.com/ultralytics/ultralytics)自问自答2:为什么学写了YOLO v8还要学习YOLO v5
YOLO有一个神奇的特性,就是更新迭代快,但不同版本有着自己擅长的领域。就像v8版本已经出了,但是v5版本还在更新。甚至很多生产环境还在使用v3版本。
如果是需要进行论文研究的同学,可以直接上v8或者v9、v10进行开发。毕竟答辩老师只看数字越大越好。在实际应用中发现v5版本更适合嵌入式开发使用,而且对小目标的检测有着天然的优势。v5版本相较v8版本有更少的参数量,在嵌入式这种本身运算能力比较弱的设备上就特点凸显出来了。
而v8版本除了检测、分类以外自带了跟踪和图像分割能力,这块也是优势所在。
附上一张yolo这几个版本的性能比较图。
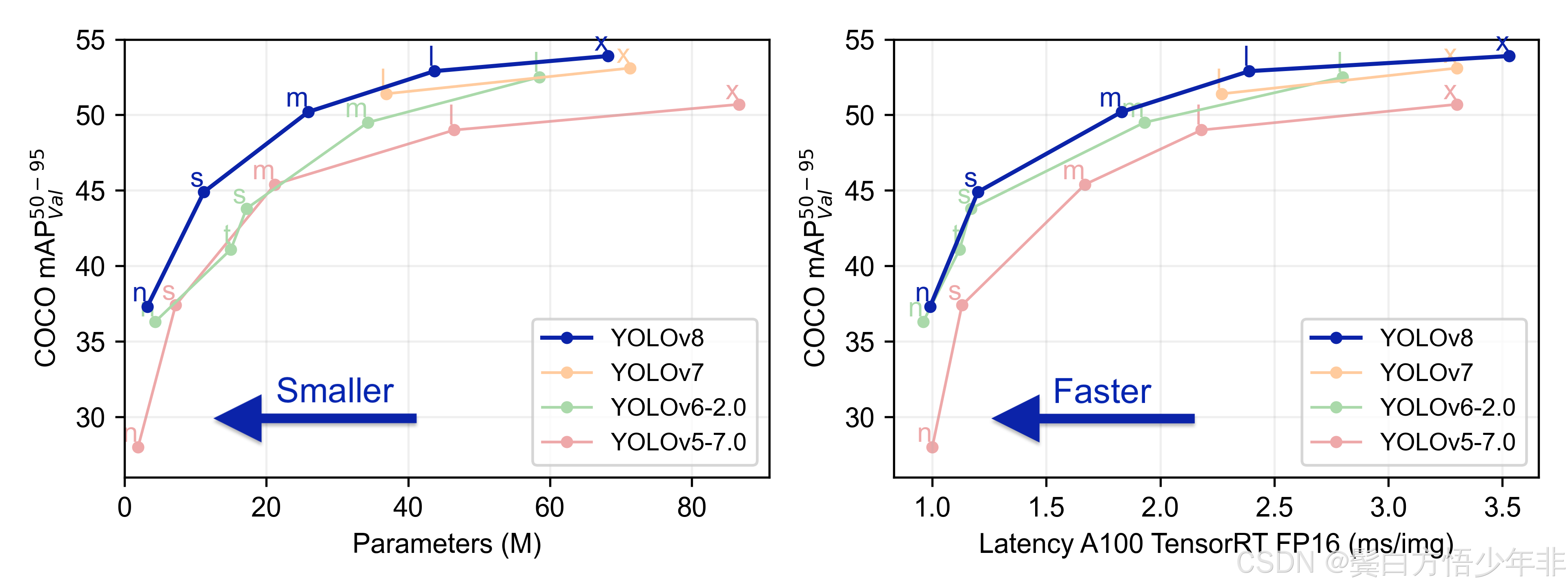
自问自答3:官方提供的模型是什么为什么可以直接使用
yolo的v5、v8版本官方都提供了n、s、m、l、x这5类校准模型,这些模型都是基于COCO2017数据集进行训练的,这里面有80种分类。如果你的需求涵盖在这些分类里面,恭喜你你讲省去很大的工作量。
但是官方模型也是很有局限性的,如果你是在一个超远距离的刁钻角度,官方模型也就失效了。
人、自行车、汽车、摩托车、飞机、公共汽车、火车、卡车、船、交通灯、消防栓、停车标志、停车计时器、长凳、鸟、猫、狗、马、羊、奶牛、大象、熊、斑马、长颈鹿、背包、雨伞、手提包、领带、手提箱、飞盘、滑雪板、滑雪板、运动球、风筝、棒球棍、棒球手套、滑板、冲浪板、网球拍、瓶子、酒杯、杯子、叉、刀、勺子、碗、香蕉、苹果、三明治、橙色、西兰花、胡萝卜、热狗、披萨、甜甜圈、蛋糕、椅子、沙发、盆栽植物、床、餐桌、厕所、电视、笔记本电脑、老鼠、遥远的、键盘、手机、微波炉、烤箱、烤面包机、下沉、冰箱、书、时钟、花瓶、剪刀、泰迪熊、吹风机、牙刷
自问自答4:训练自己的模型需要采集多少图片
大于200张,小于5000张。如果对单一事物的识别,我认为这是比较靠谱的答案,数据标注是一个相当枯燥且无趣的过程,但是少于200张图片的标注量,将准确反映出模型的能力。大于5000张图片其实也没必要,如果控制在2000张左右最好。
其实数据标注也有一些其他手段,比如数据增强,半自动标注等等,如果只有有粉丝有兴趣我会另外写博客。
好了以上就是专栏第一章第一篇内容,后续可能会持续更新自问自答系列。如果对本专栏感兴趣欢迎订阅。