公司最近刚忙完一个项目,闲暇之余,看着手里的树莓派、stm32、Esp32又有些手痒了,准备再搞点小项目出来,但一直没有什么好想法。
说来也巧,恰好收到了CSDN官方的OrangePi AIpro测评活动,平时一直都在用树莓派做点小项目,香橙派的大名也有所耳闻,但从未接触过,恰好有这么一个机会了解一下,必须好好把玩一下。
深入了解测评活动后才知道,原来香橙派 AIpro是块AI板子,用的是华为昇腾AI技术路线,华为加持的那必须是遥遥领先,哈哈。我拿到的板子有8TOPS AI算力,这不比树莓派高级的多吗?

虽然和Jetson Xavier NX的21TOPS相比差距不少,但8TOPS的算力在嵌入式AI开发板中已经相当不错,适合多种中等复杂度的AI应用场景,因为抛开价格谈算力,就是耍流氓,我拿到的8TOPS、8G内存的香橙派 AIpro价格是799,是创客的又一个新选择。看着21TOPS、8G内存的Jetson Xavier NX卖3000多,我真的是瑟瑟发抖,要不起~

香橙派 AIpro的详细参数大家可参考官方说明:
http://www.orangepi.cn/html/hardWare/computerAndMicrocontrollers/details/Orange-Pi-AIpro.html
简单的说,采用了昇腾AI技术路线,具体为4核64位处理器+AI处理器,拥有8GB/16GB LPDDR4X,可以外接32GB/64GB/128GB/256GB eMMC模块,支持双4K高清输出,包括两个HDMI输出、GPIO接口、Type-C电源接口、支持SATA/NVMe SSD 2280的M.2插槽、TF插槽、千兆网口、两个USB3.0、一个USB Type-C 3.0、一个Micro USB(串口打印调试功能)、两个MIPI摄像头、一个MIPI屏等,预留电池接口。这么丰富的接口,拿来做机械臂、智能家居中控、智能小车、智能交通、智能音响等产品简直不要太香了!接下来就记录一下香橙派 AIpro从开箱到安装、烧录、跑通示例的完整过程。
1 、开箱
邮寄用了三天时间,香橙派 AIpro套装包含:主板、电源、散热组件、32GB存储卡,线路板设计还是比较合理的,走线清晰、布局紧凑、元器件焊接整齐,看着就有质感,爱了爱了。这里要注意一下,拆包装的时候一定别激动,千万别把天线给扯下来,别问我为什么!


2 、烧录镜像
玩儿过树莓派的都懂,需要先把操作系统的镜像烧录到SD卡中,才能正常启动板子,香橙派 AIpro同样如此。
2.1 下载镜像
香橙派 AIpro官方镜像下载地址:
Orange Pi - Orangepi

官方提供了ubuntu镜像和openeuler镜像,ubuntu大家耳熟能详,openeuler可能知道的人不多,它是华为发布的操作系统,openEuler是一个开源、免费的 Linux 发行版平台。说实话,我对openeuler也不熟悉,咱还是用ubuntu镜像吧,官方把镜像放在了百度网盘,网盘地址是:
https://pan.baidu.com/s/1csbugZiKsuL_NHCOmyi1BA?pwd=ma6z

这里要注意一下,这里有两个镜像,一个是minimal,一个是desktop,minimal镜像只有最基础的功能,Linux 桌面、CANN、示例代码都没有,不适合新手;desktop 镜像预装了 Linux 桌面、CANN、AI 示例代码和测试程序,想要快速体验香橙派 AIpro开发板,咱最好还是下载opiaipro_ubuntu22.04_desktop_aarch64_20240318.img.xz文件。
百度网盘的下载速度难得的给力。
2.2 烧录镜像
下载Windows-格式化软件-SDCardFormatter和Linux镜像烧录工具-balenEther,下载地址:
百度网盘 请输入提取码
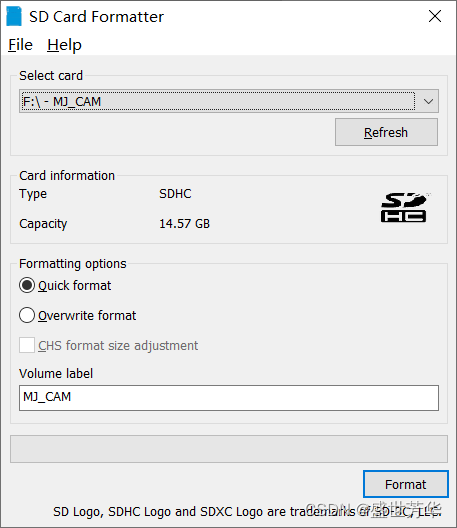
解压SDCardFormatterv5_WinEN.zip双击安装SDCardFormatte,将SD卡插入读卡器,读卡器插入电脑,打开SDCardFormatter找到SD卡磁盘,点击Format进行格式化。
双击balenaEtcher-Portable-1.18.4.exe,点击“从文件烧录”,选择我们下载的opiaipro_ubuntu22.04_desktop_aarch64_20240318.img.xz文件,点击“选择目标磁盘”选中SD卡磁盘,点击“现在烧录”,完成镜像的烧录。最后将SD卡插入到香橙派 AIpro的TF卡槽中。

3、硬件安装和开机
3.1 风扇安装
套件带有散热组件,如果不装风扇直接拿来做推理,目测能直接烧开一壶水,所以风扇必须得安排上。安装方式也很简单,4个打孔位置安装4个铜柱,然后贴导热硅脂,再把风扇装上去,风扇的接头插到板子的FAN标识处。

最终效果如下:

3.2 硬件连接
网口插网线,USB口插鼠标、键盘,如果有显示器,那么将板子的HDMI0接口接入到显示器,我正好有一个十几年前买的联想G460笔记本,主板坏了,但屏幕还不错,就弄了个屏幕驱动板,改造成了一个便携式显示器,最近一直配合着树莓派使用,这次又有大用处了。最后Type-C口插电源线,开机~~效果非常不错,输入密码Mind@123进入系统。

注意,开机时风扇转的非常快,小心被刮伤,系统启动成功后,风扇转速就降低了。
4、远程连接
4.1 命令行远程连接
由于我没有蓝牙鼠标和键盘,鼠标和键盘直接插到香橙派 AIpro开发板上的话,线太多太乱,所以最终还是选择使用远程连接。方法很简单,使用MobaXterm新建会话,输入香橙派 AIpro开发板的IP地址,用户名HwHiAiUser、密码Mind@123,IP地址可登录路由器管理界面查找。

远程连接成功后如图所示:

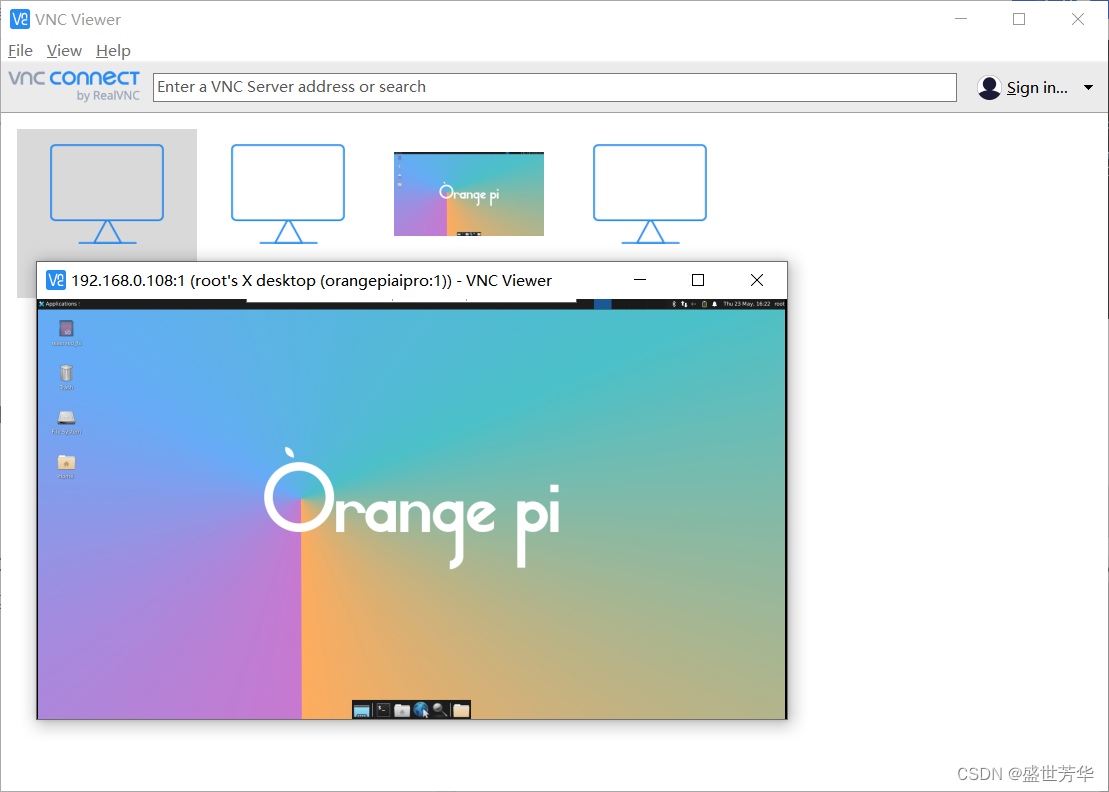
4.2 vnc远程桌面
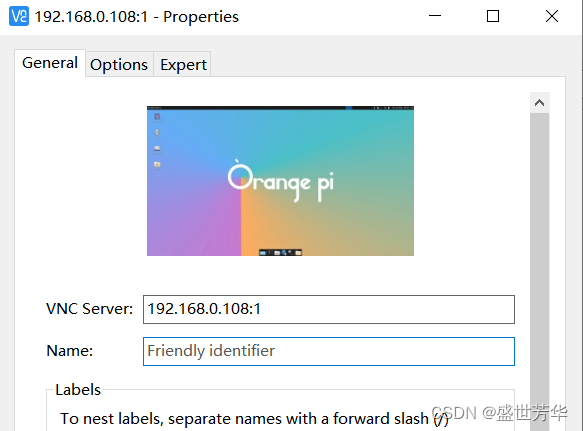
官方镜像默认安装了VNC,通过VNC Views工具可直接连接,服务地址是IP:1
5、实例代码演示
5.1 调用官方例程
官方例程放在/samples/notebooks目录下,进入目录后执行:
./start_notebook.sh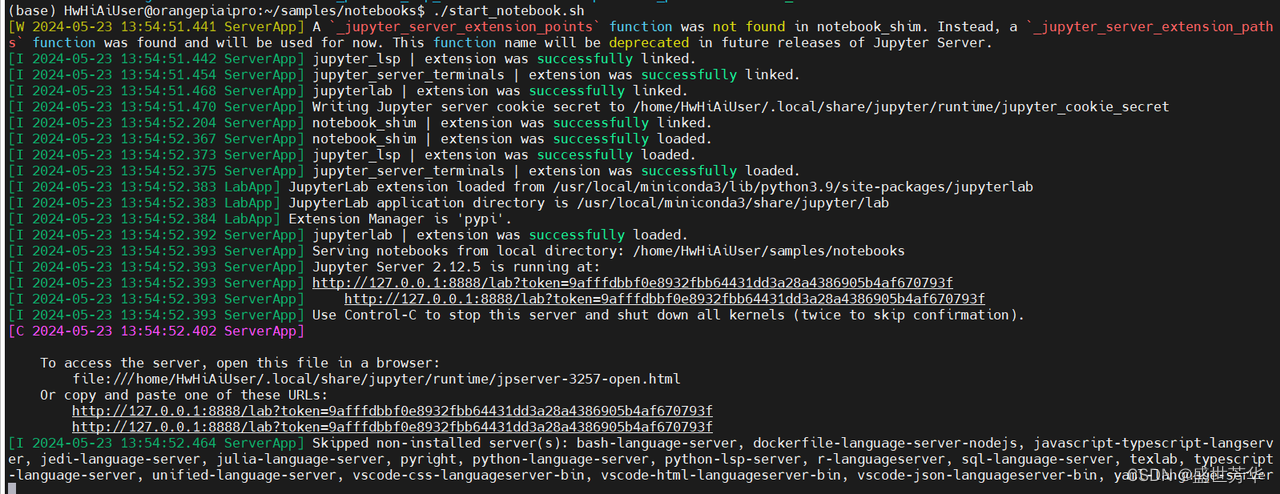
此时需要访问jupyter来查看例程,因为我是远程连接的香橙派 AIpro,所以需要把开发板的8888端口映射到本地。方法很简单,点击MobaXterm的Tunneling,点击“New SSH tunnel”
接下来如图配置端口映射:
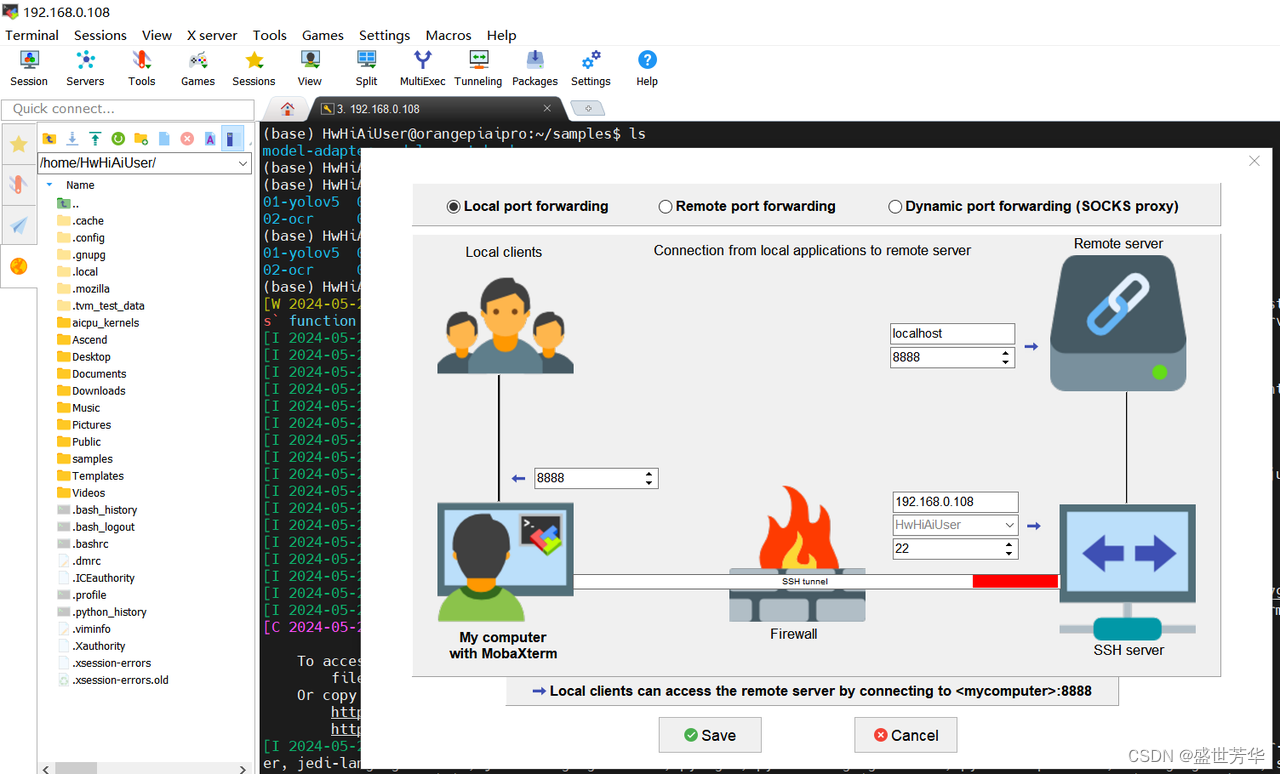
完成后,点击开始图标:

然后就可以通过本地浏览器访问jupyter了。
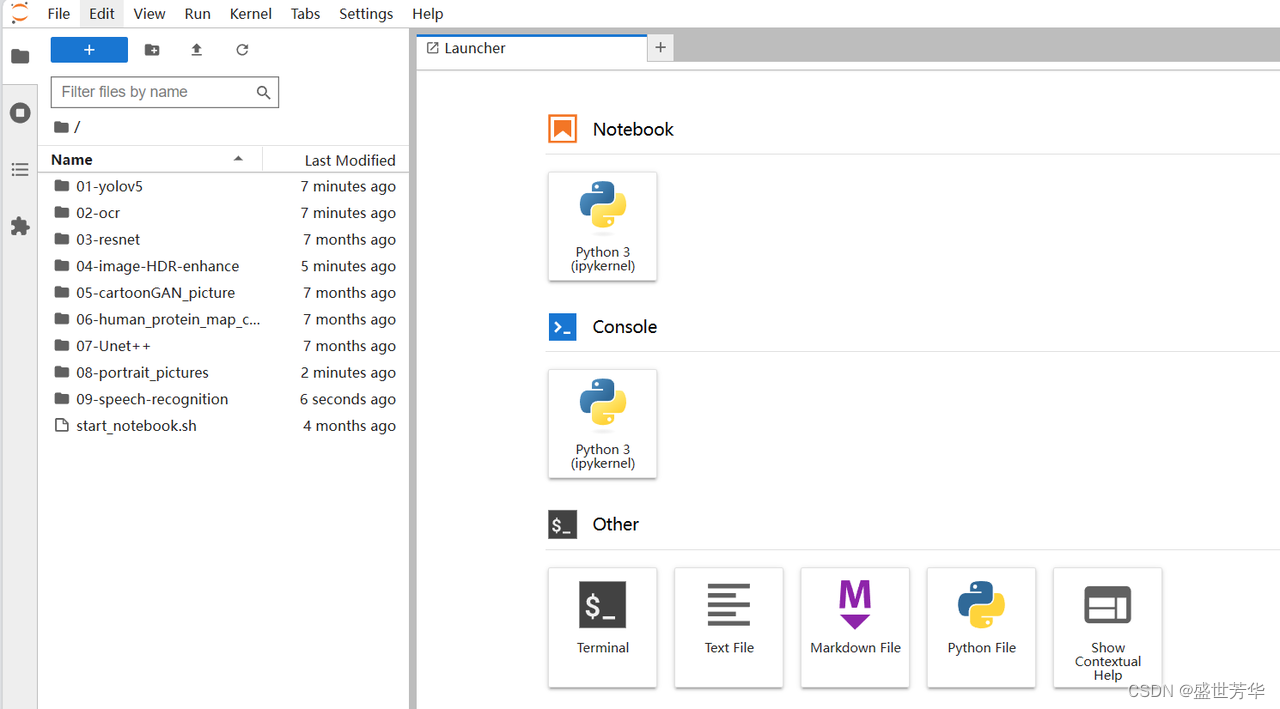
官方给了9个例程,分别是yolov5目标识别、ocr文字识别、resnet图像分类、图像HDR增强、卡通图片效果生成、蛋白质图谱分类、细胞核实例分割、基于神经网络的人像分割和背景替换、语音转文本,都是非常值得参考学习的例程,方便开发者从项目出发,了解昇腾的开发流程。


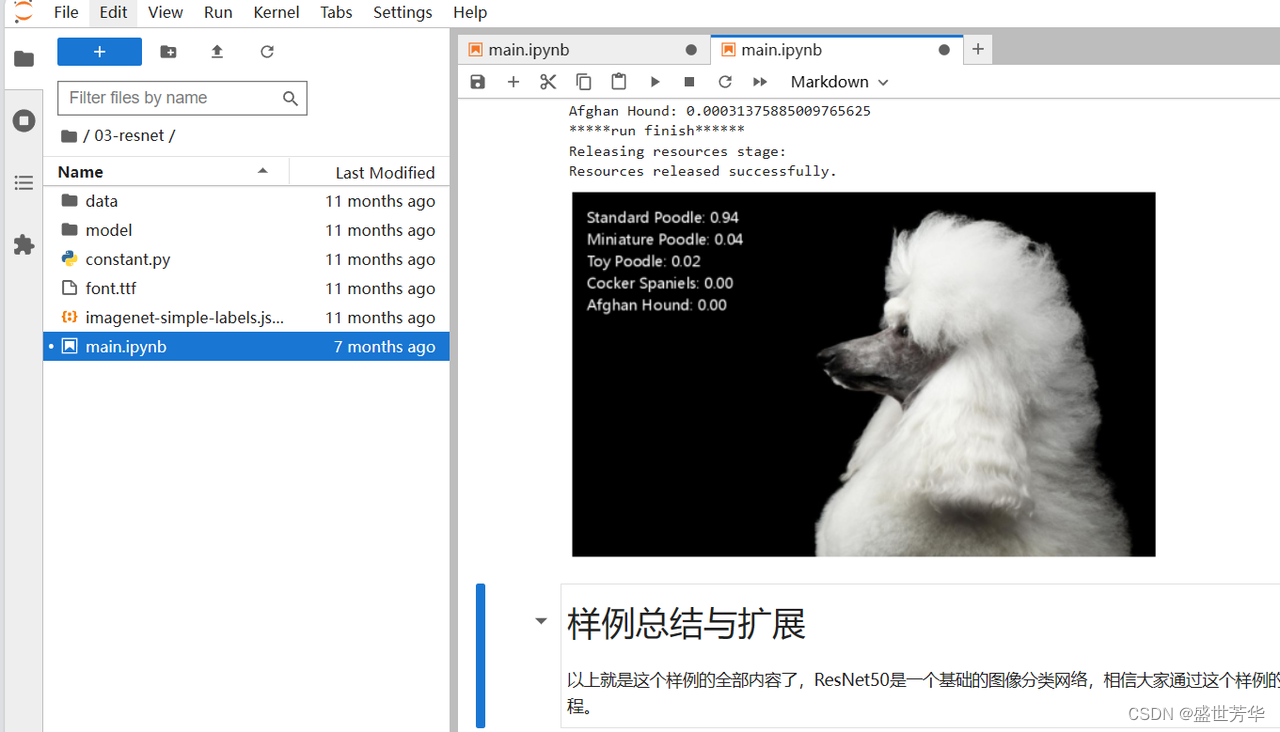
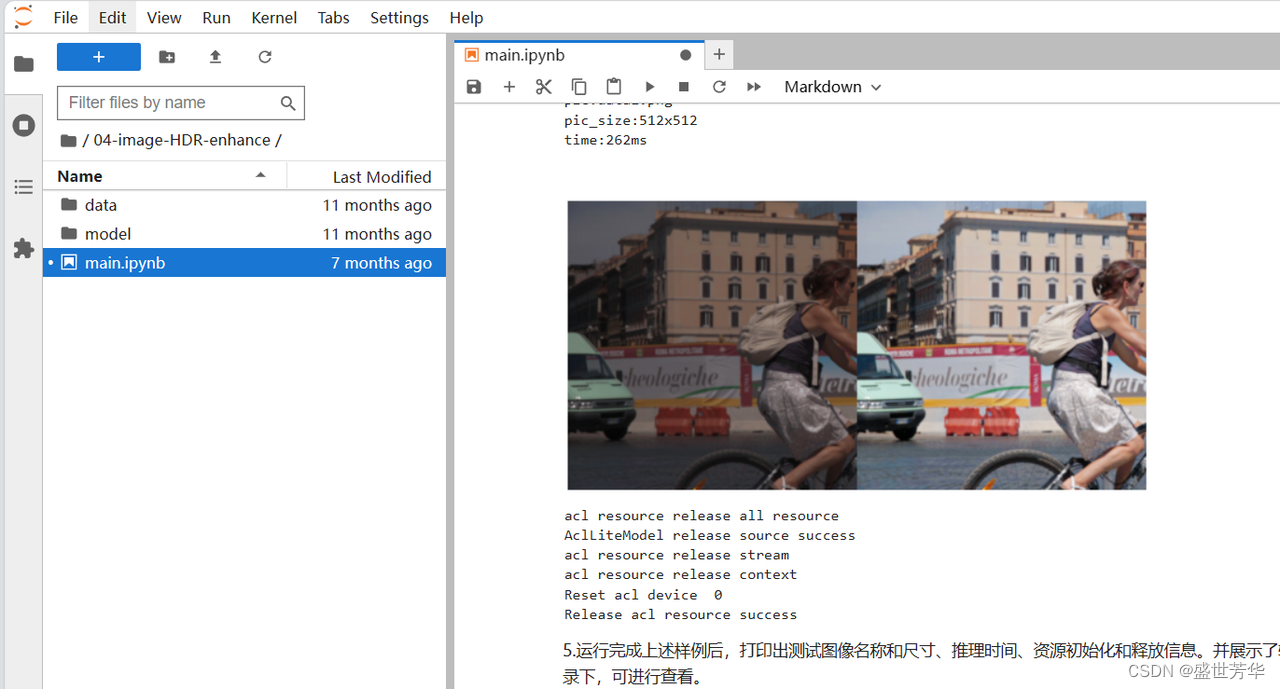
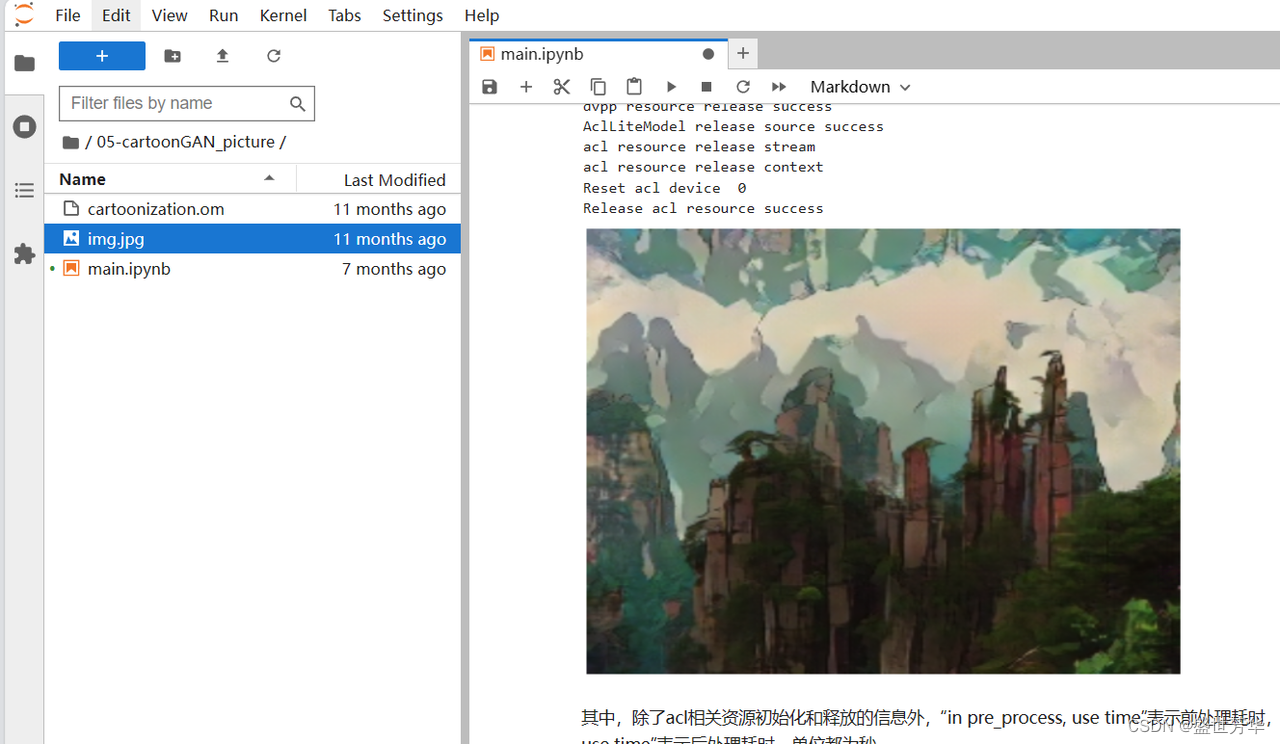



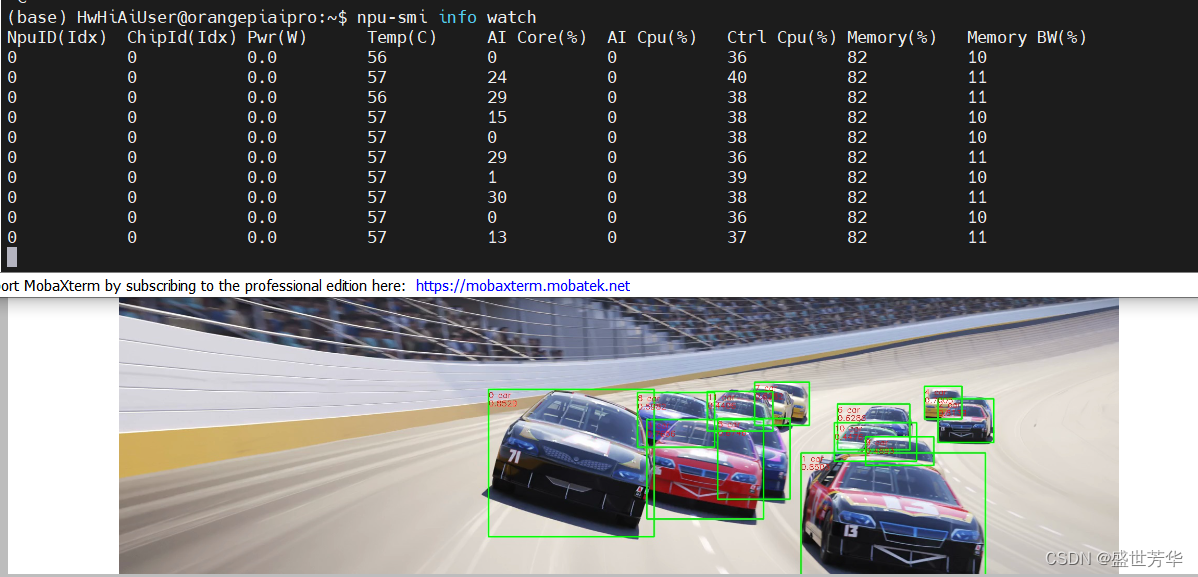
我在运行yolov5例程的时候,同时监控了一下芯片的数据,AI Core占用率在30以下浮动,内存占用率在82,在用风扇的情况下,芯片温度在56°左右,所以使用这个开发板时风扇是必备的。
5.2 Yolov8目标识别迁移
官方提供了Yolov5的示例,而Yolo的版本已经迭代到了Yolov8,所以想着把Yolov8迁移过来,在迁移过程中遇到了非常多的坑,所以把迁移过程记录下来,避免大家踩坑。
5.3.1 代码克隆
我基于https://github.com/ultralytics/ultralytics进行模型的迁移。
cd /home/HwHiAiUser/ git clone https://github.com/ultralytics/ultralytics5.3.2 下载权重文件
cd ultralytics/examples/YOLOv8-OpenCV-ONNX-Pythonwget https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt5.3.3 pt权重转onnx
先安装用到的库:
pip install ultralytics -i https://mirrors.aliyun.com/pypi/simple pip install opencv-python -i https://mirrors.aliyun.com/pypi/simple然后转换权重文件
yolo export model=yolov8n.pt imgsz=640 format=onnx opset=11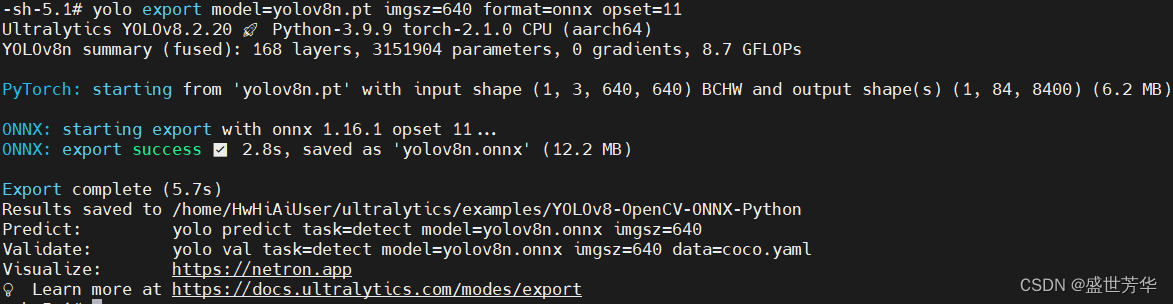
5.3.4 使用onnx进行推理
我修改了main.py,想看一下onnx推理一张图片需要多久。
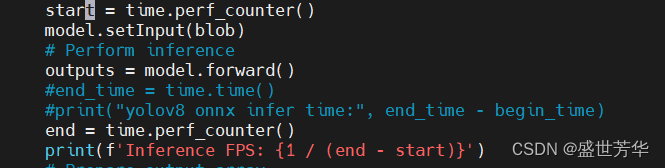
python main.py --model yolov8n.onnx
使用onnx推理,推理部分仅有1.2FPS。
5.3.5 ATC转换模型
ATC是异构计算架构CANN体系下的模型转换工具, 可以将开源框架的网络模型转换为昇腾AI处理器支持的.om格式离线模型。也就是将pytorch、tensorflow、cafffe框架下训练的模型转换为昇腾硬件可以加载加速的模型。
最大的坑来了,在使用ATC进行模型转换的时候,出现了各种各样的问题,折腾了两天才解决。
我烧录的镜像是官方提供的“opiaipro_ubuntu22.04_desktop_aarch64_20240318.img.xz”,预装了Ascend-cann-toolkit7.0版本,在首次进行模型转换时,出现了一堆BrokenPipeError: [Errno 32] Broken pipe错误,我以为是Ascend-cann-toolkit版本问题,卸载后安装了Ascend-cann-toolkit_8.0.RC1.alpha003版本,重装Ascend-cann-toolkit方法也简单:
cd /usr/local/Ascend/ascend-toolkit/ #删除当前安装,否则会出现磁盘空间不足 rm -rf *然后进入https://www.hiascend.com/developer/download/community/result?module=cann&cann=8.0.RC1.alpha003,下载Ascend-cann-toolkit_8.0.rc1.alpha003_linux-aarch64.run
chmod +x Ascend-cann-toolkit_8.0.rc1.alpha003_linux-aarch64.run ./Ascend-cann-toolkit_8.0.rc1.alpha003_linux-aarch64.run -- install安装较慢,耐心等待。
成功后使用最新版atc工具转换模型,仍然报错BrokenPipeError: [Errno 32] Broken pipe。
最后论坛里翻了翻,发现原因是开发板cpu核数较少,atc过程中使用的最大并行进程数默认是服务器的配置,可以使用环境变量减少atc过程中的进程数来减少内存消耗。
#开启日志输出 export ASCEND_SLOG_PRINT_TO_STDOUT=1 export ASCEND_GLOBAL_LOG_LEVEL=0#减小算子最大并行编译进程数 export TE_PARALLEL_COMPILER=1 #减少图编译时可用的CPU核数 export MAX_COMPILE_CORE_NUMBER=1然后再进行模型转换,让人兴奋,BrokenPipeError: [Errno 32] Broken pipe错误消失,等了几分钟后,新错误出现了,如图所示,报错fatal error: 'type_traits' file not found
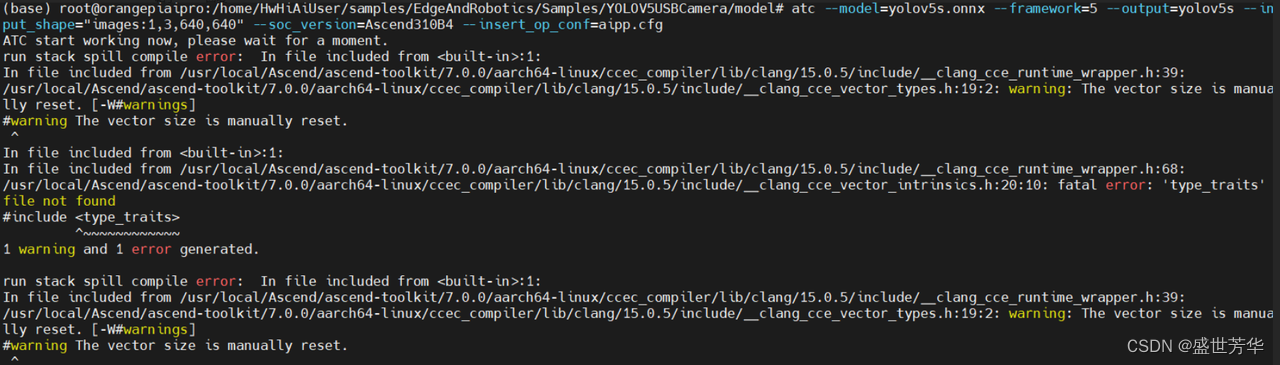
但我确信gcc之类的库是没问题的,而且自己写了一个cpp,特意#include<type_traits>都是能编译通过的。
最后,实在没辙的情况下,我重新烧录了镜像,这次我换用了官方的“opiaipro_openEuler22.03_desktop_aarch64_20240423.img.xz”镜像,问题居然消失了,看来,ubuntu的镜像的确有点问题。
5.3.6 代码迁移
接下来就简单了:
cd ultralytics/examples/YOLOv8-OpenCV-ONNX-Python #模型转换 atc --framework=5 --model=yolov8n.onnx --output=yolov8n --input_shape="images:1,3,640,640" --soc_version=Ascend310B4 --log=error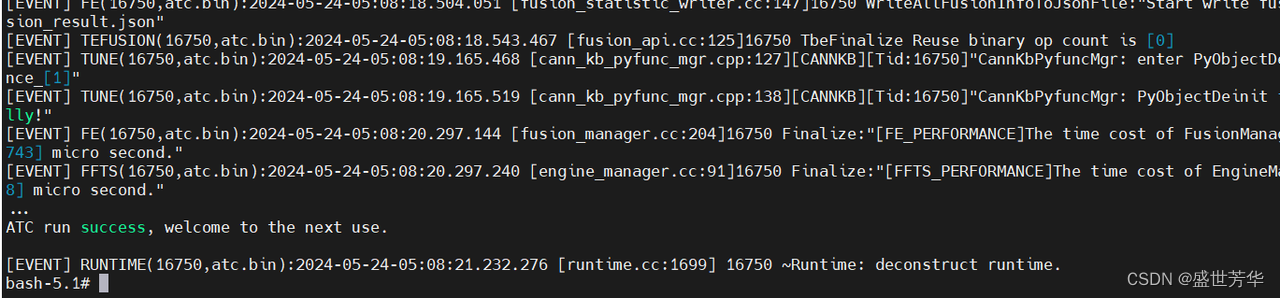
转换成功,目录下生成了yolov8n.om文件,然后复制当前目录下的main.py文件进行魔改
cp main.py mainom.py vim mainom.py头部引入以下代码:
from ais_bench.infer.interface import InferSession import time
修改main函数输入:
#将代码 def main(onnx_model, input_image): #改为 def main(om_model, input_image):#注释掉代码: model: cv2.dnn.Net = cv2.dnn.readNetFromONNX(onnx_model) #改为 session = InferSession(device_id=0, model_path=om_model)#注释掉代码 model.setInput(blob) outputs = model.forward() #改为 outputs = session.infer(feeds=blob, mode="static")#修改 outputs = np.array([cv2.transpose(outputs[0])]) #改为 outputs = np.array([cv2.transpose(outputs[0][0])])
然后开始推理:
python mainom.py --model yolov8n.om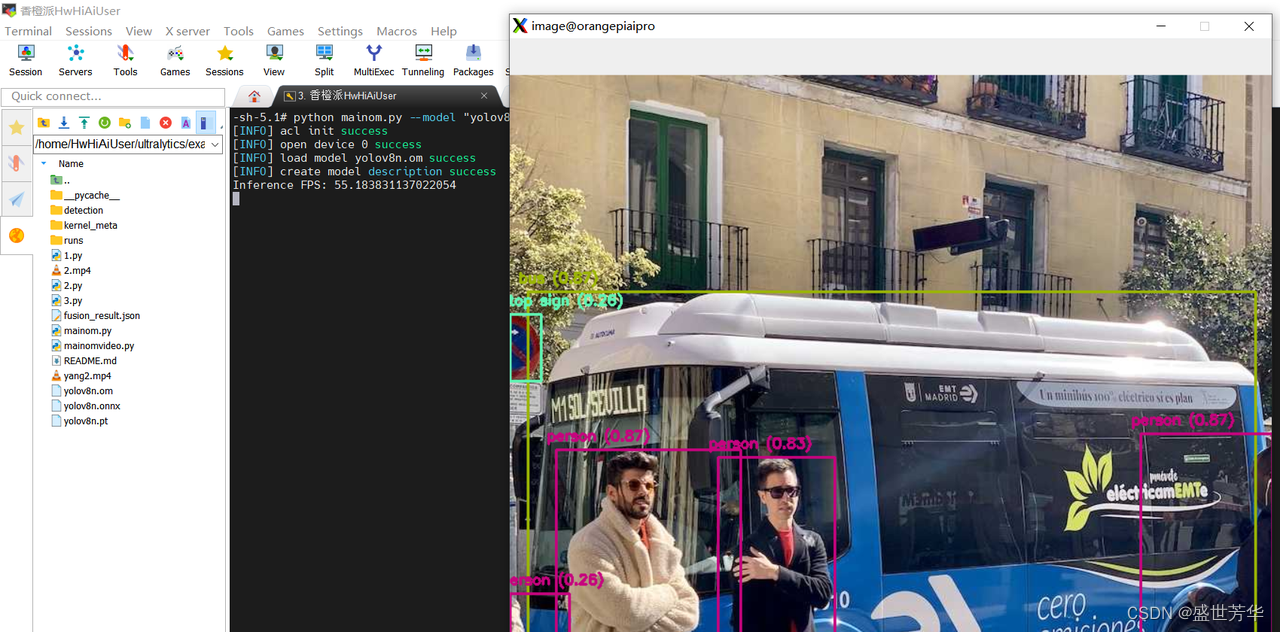
使用昇腾AI技术路线后,推理部分是55FPS,性能强悍。
5.3 LLMS大模型实例
从去年开始,最火热的技术莫过于大语言模型,最近我也一直在研究大语言模型,本地部署体验了通义千问120B、llama3的70B、以及gemma的7B模型,通义千问120B的中文性能绝对是扛把子的存在,毕竟我用了四张3090的显卡才把120b的模型跑起来。
接触到香橙派 AIpro开发板后,就有一个把大语言模型移植到香橙派 AIpro的想法,网上搜罗一番,发现资料不多,难度不小,不过在gitee发现了南京大学开源的一套基于香橙派 AIpro部署的Tiny-Llama语言模型,开源地址:https://gitee.com/wan-zutao/tiny-llama-manual-reset
Tiny-Llama这个模型的尺寸非常小,参数也只有1.1B,我用CPU就能够运行。用香橙派 AIpro跑,速度绝对没得说:

抱着前人栽树后人乘凉的态度,先来体验一番。部署很简单:
5.3.1 克隆项目
cd ~/samples git clone https://gitee.com/wan-zutao/tiny-llama-manual-reset.git tiny_llamacd cd tiny_llama/inference5.3.2 下载model、tokenizer文件
bash download.sh
5.3.3 启动
python3 main.py
然后通过本地浏览器访问Tiny-Llama服务。
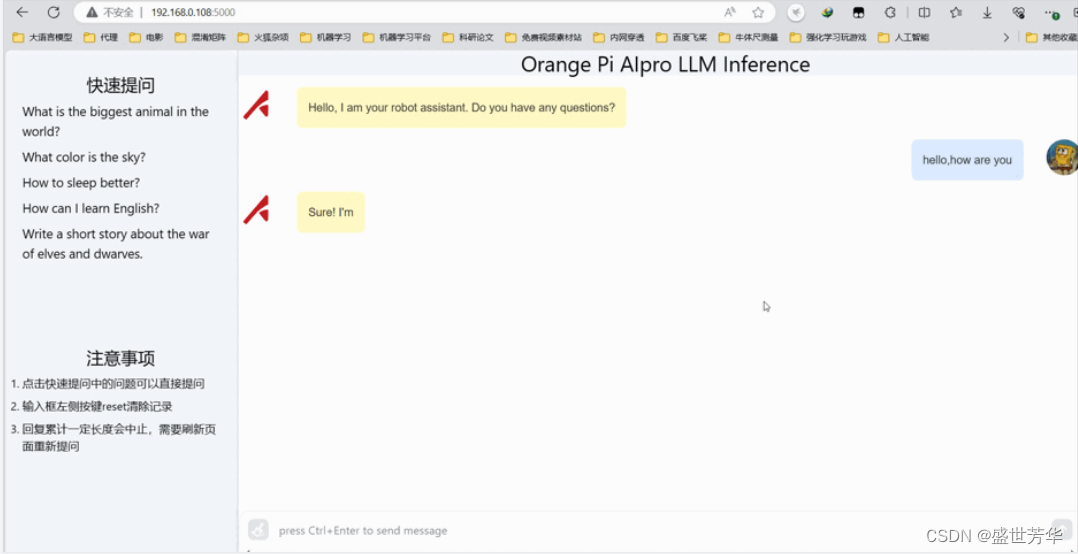
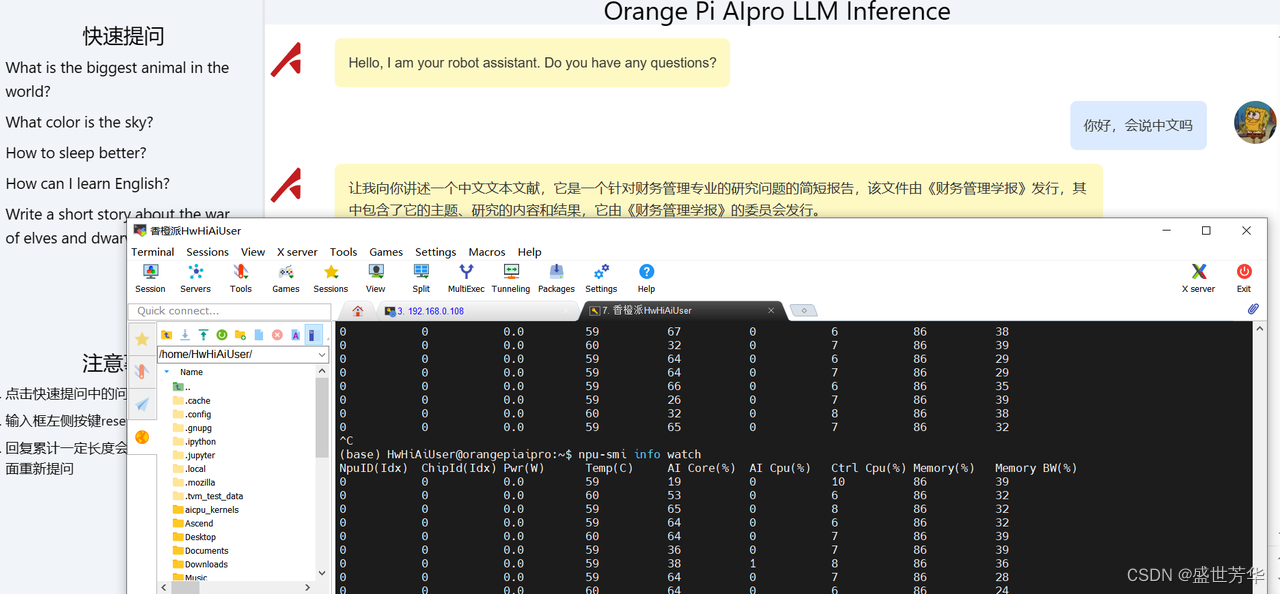
Tiny-Llama这个模型是个纯纯的话痨,你问一句,它回你十句,而且常常词不达意,中文基本不支持,我愿称之为废话生成器,所以这种参数很小的模型,还是没啥实用价值。
在大语言模型推理过程中,Ai Core的占用率达到60%左右,基本上1秒出2个英文单词,速度还行,等以后有机会了,可以尝试把千问7B模型迁移过来,不知能否跑得起来。
6、使用感受
香橙派 AIpro开发板玩儿了一周,开发板表现得异常坚挺,几乎都是不间断地运行,没有一次意外重启,在持续高负荷运作期间,板子的温度管理也很出色,始终保持在50到60°左右,这对于高性能计算设备而言非常重要。
香橙派官方对开发者社区的支持力度值得称赞,不仅提供了丰富的例程资源,覆盖了从基础到进阶的多个层面,还细心考虑到不同水平开发者的学习需求,极大地降低了初学者的入门门槛。然而,对于初次接触昇腾AI技术路线的开发者来说,环境配置和开发流程仍然是一个不小的挑战。这一过程中,可能会遇到各种预料之外的问题,比如依赖库的安装、编译等,我利用一周的时间,亲身体验并详细记录了在使用香橙派AIpro进行开发时,新手开发者可能会遭遇到的主要障碍,并以当下流行的YOLOv8模型迁移为例,实现模型的成功转换至昇腾平台。这份实战经验的分享,希望能为新手提供一些帮助。
开发过程中的疑惑与挑战,建议大家积极访问昇腾官方社区(https://www.hiascend.com/forum)。昇腾虽然已经在算力领域占据了举足轻重的地位,但构建和完善一个生机勃勃的生态系统仍是一场持久战。这要求我们每一位开发者不仅要专注于技术创新,更要乐于分享、勇于协作,共同推动昇腾AI生态走向更加繁荣的未来。