前沿科技速递?
随着大型模型技术的持续发展,视频生成技术正在逐步走向成熟。智谱AI团队宣布开源其创新的视频生成模型CogVideoX系列,这标志着视频内容创作的一个新里程碑。通过此次开源,智谱AI旨在让每一位开发者、每一家企业都能够自由地开发属于自己的视频生成模型,从而推动整个行业的快速迭代与创新发展。
来源:传神社区
01 CogVideoX系列模型介绍
CogVideoX是智谱AI团队开发的一系列视频生成模型,它们能够根据文本提示生成视频内容。最新开源的CogVideoX-2B模型以其强大的生成能力和较低的资源需求,为视频生成领域注入了新的活力,它在FP-16精度下的推理仅需18GB显存,微调则只需要40GB显存,这意味着单张4090显卡即可进行推理,而单张A6000显卡即可完成微调。
CogVideoX-2B的提示词上限为226个token,视频长度为6秒,帧率为8帧/秒,视频分辨率为720*480。为视频质量的提升预留了广阔的空间,期待开发者们在提示词优化、视频长度、帧率、分辨率、场景微调以及围绕视频的各类功能开发上贡献开源力量。

02 技术细节与创新
VAE(变分自编码器)
视频数据因包含空间和时间信息,其数据量和计算负担远超图像数据。为应对此挑战,智谱AI提出了基于3D变分自编码器(3D VAE)的视频压缩方法。通过三维卷积同时压缩视频的空间和时间维度,实现了更高的压缩率和更好的重建质量。
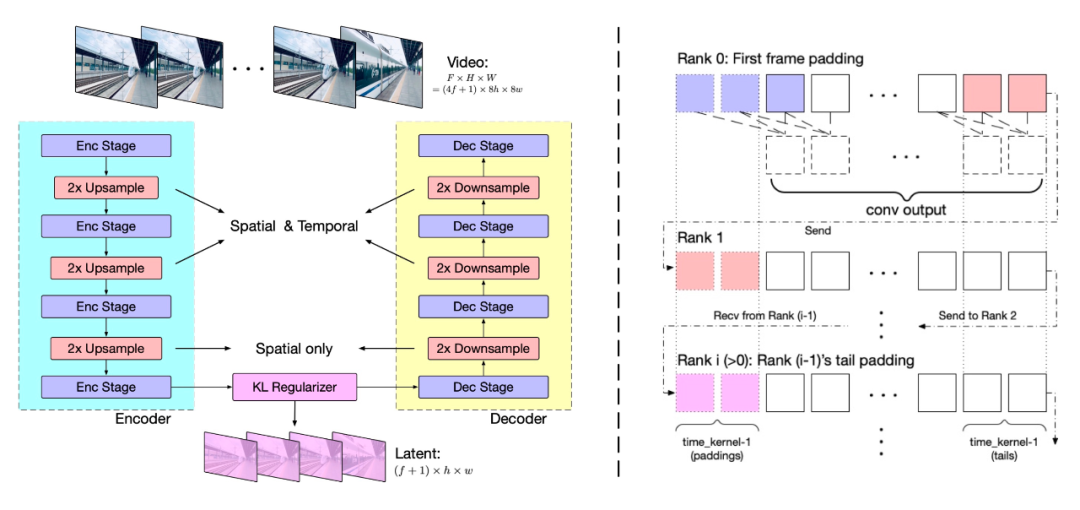
模型结构包括编码器、解码器和潜在空间正则化器,通过四个阶段的下采样和上采样实现压缩。时间因果卷积确保了信息的因果性,减少了通信开销。上下文并行技术则用于适应大规模视频处理。
专家Transformer
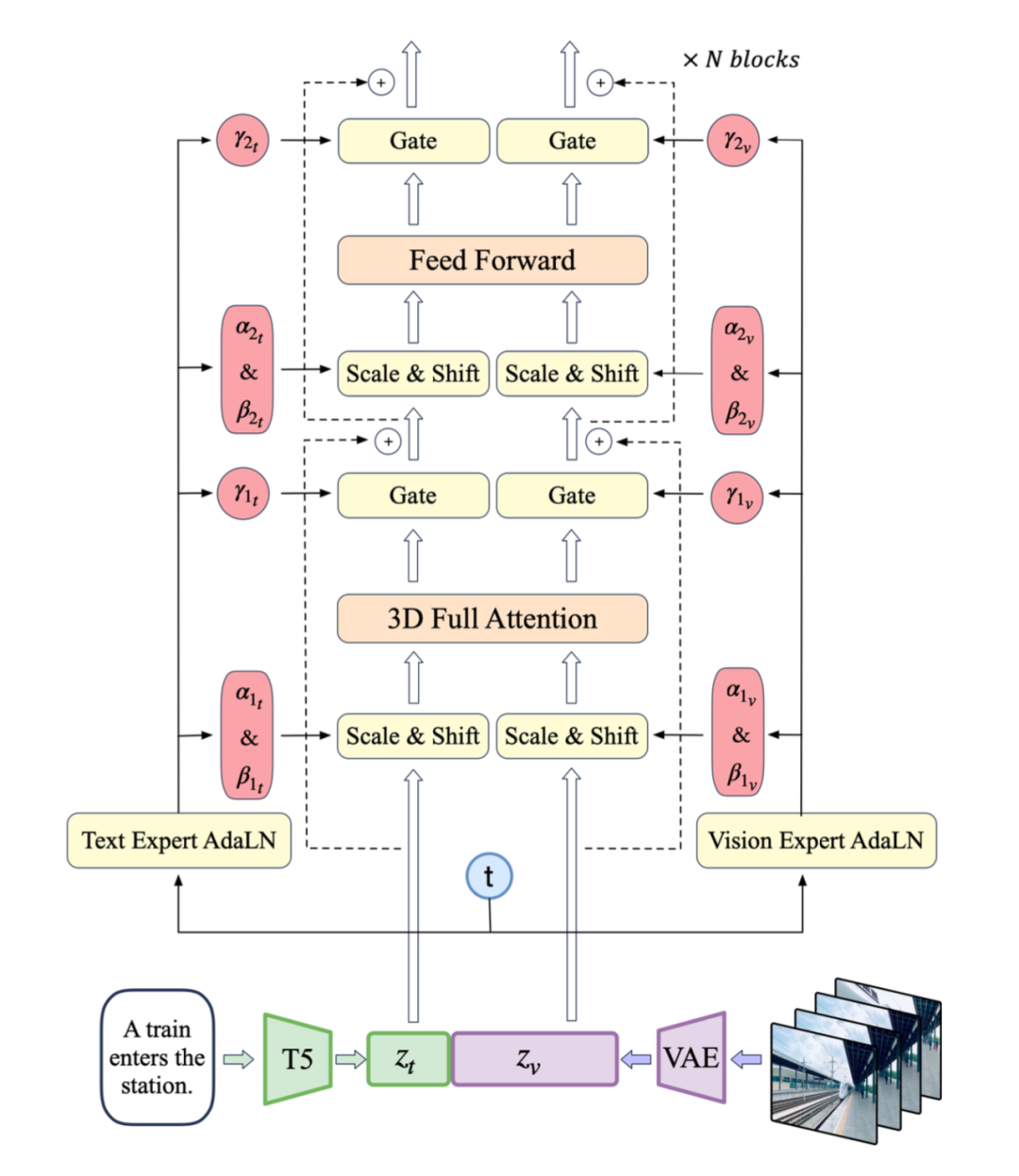
使用VAE的编码器将视频压缩至潜在空间,然后将潜在空间分割成块并展开成序列嵌入z_vision。同时,使用T5将文本输入编码为文本嵌入z_text,然后将z_text和z_vision沿序列维度拼接。拼接后的嵌入被送入专家Transformer块堆栈中处理。最终,反向拼接嵌入恢复原始潜在空间形状,并使用VAE进行解码以重建视频。
数据处理
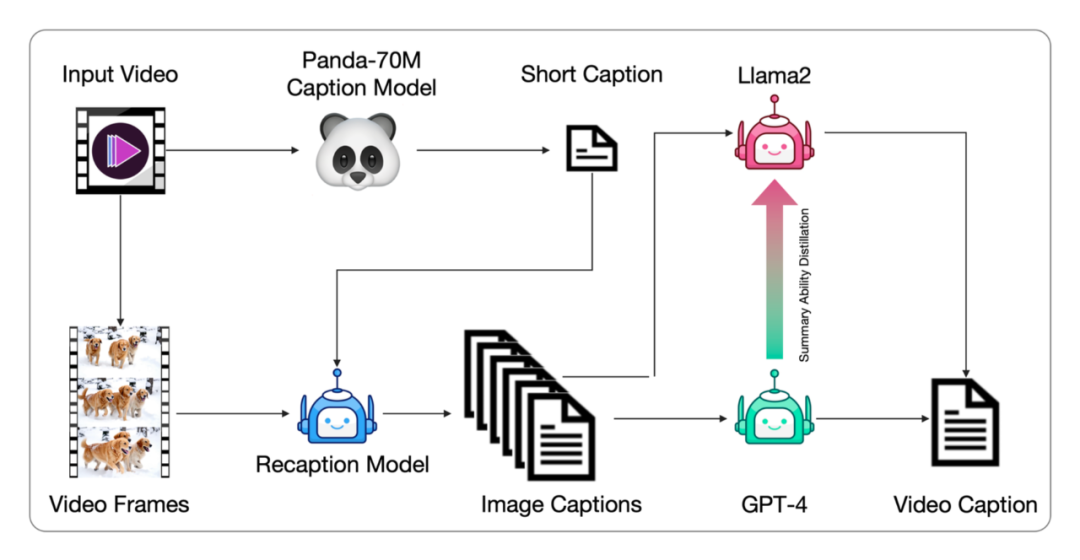
高质量的视频数据对视频生成模型的训练至关重要。智谱AI开发了负面标签来识别和排除低质量视频,如过度编辑、运动不连贯、质量低下、讲座式、文本主导和屏幕噪音视频。通过video-llama训练的过滤器,标注并筛选了20,000个视频数据点,同时计算光流和美学分数,动态调整阈值,确保生成视频的质量。
视频数据通常没有文本描述,需要转换为文本描述以供文本到视频模型训练。智谱AI提出了一种从图像字幕生成视频字幕的管道,并微调端到端的视频字幕模型以获得更密集的字幕。这种方法通过Panda70M模型生成简短字幕,使用CogView3模型生成密集图像字幕,然后使用GPT-4模型总结生成最终的短视频。
03 性能评估
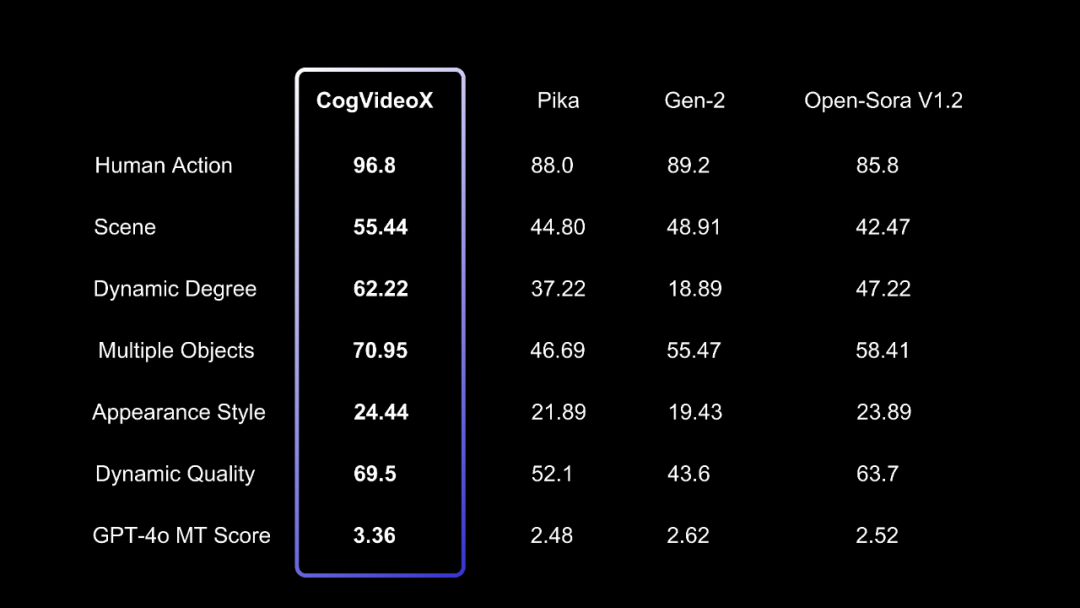
为了评估文本到视频生成的质量,智谱AI使用了VBench中的多个指标,如人类动作、场景、动态程度等。还使用了两个额外的视频评估工具:Devil中的Dynamic Quality和Chrono-Magic中的GPT4o-MT Score,专注于视频的动态特性。
04 生成实例
小编也应用智谱清影生成了几段视频,让我们看看效果吧~
video_gen1722914262885
video_gen1722926244467
05 快速上手
本模型已经支持使用 huggingface 的 diffusers 库进行部署,你可以按照以下步骤进行部署。
安装对应的依赖
pip install --upgrade opencv-python transformers accpip install git+https://github.com/huggingface/diffusers.git@878f609aa5ce4a78fea0f048726889debde1d7e8#egg=diffusers # Still in PR
2.运行代码
import torchfrom diffusers import CogVideoXPipelinefrom diffusers.utils import export_to_videoprompt = "A panda, dressed in a small, red jacket and a tiny hat, sits on a wooden stool in a serene bamboo forest. The panda's fluffy paws strum a miniature acoustic guitar, producing soft, melodic tunes. Nearby, a few other pandas gather, watching curiously and some clapping in rhythm. Sunlight filters through the tall bamboo, casting a gentle glow on the scene. The panda's face is expressive, showing concentration and joy as it plays. The background includes a small, flowing stream and vibrant green foliage, enhancing the peaceful and magical atmosphere of this unique musical performance."pipe = CogVideoXPipeline.from_pretrained("THUDM/CogVideoX-2b",torch_dtype=torch.float16).to("cuda")prompt_embeds, _ = pipe.encode_prompt(prompt=prompt,do_classifier_free_guidance=True,num_videos_per_prompt=1,max_sequence_length=226,device="cuda",dtype=torch.float16,)video = pipe(num_inference_steps=50,guidance_scale=6,prompt_embeds=prompt_embeds,).frames[0]export_to_video(video, "output.mp4", fps=8)
使用单卡A100按照上述配置生成一次视频大约需要90秒。
如果您生成的模型在 MAC 默认播放器上表现为 "全绿" 无法正常观看,属于正常现象 (OpenCV保存视频问题),仅需更换一个播放器观看。
06 模型下载
传神社区:https://opencsg.com/models/THUDM/CogVideoX-2b
huggingface:https://huggingface.co/THUDM/CogVideoX-2b
github:https://github.com/THUDM/CogVideo
欢迎加入传神社区
•贡献代码,与我们一同共建更好的OpenCSG
•Github主页
欢迎?:https://github.com/OpenCSGs
•Huggingface主页
欢迎下载:https://huggingface.co/opencsg
•加入我们的用户交流群,分享经验

添加图片注释,不超过 140 字(可选)
扫描上方二维码添加传神小助手
“ 关于OpenCSG
开放传神(OpenCSG)成立于2023年,是一家致力于大模型生态社区建设,汇集人工智能行业上下游企业链共同为大模型在垂直行业的应用提供解决方案和工具平台的公司。
关注OpenCSG

加入传神社区
