文章目录
- 前言
- Connection管理的权衡问题
- RBF的Connection管理
- 细粒度的Connection Pool划分
- Connection的创建
- Connection的清理
- 参考资料
前言
为了解决HDFS Federation下多集群的维护管理,Hadoop社区实现了Router-Based Federation(HDFS-10467)功能。此功能的强大之处在于它在client和集群NN服务之间新加了一层Router的服务。有了这个Router这个服务后,所有客户端的请求将会由这个Router负责转发给下游的NN节点。这样的话,客户端用户就不需要知道下游有哪些NN节点以及各个NN Namespace里分布着什么样的数据了。这些事情Router都会透明地帮client做完。既然Router在这里主要做了请求转发这件事,那么势必它会存在与下游NN建立新的连接然后进行请求转发的步骤。那么问题来了,Router是怎么做这块的处理呢?如果是每次来一个客户端请求,Router对应建立一个新的connection去请求NN,那么这意味着Router会做大量的连接重建立操作,这显然是不太高效的做法。高效一点的做法是是Router自己维护一定的connection,然后尽可能能够复用其中的connection去请求NN。但是这无疑会增加Router Connection这块的管理工作,而且这里还要避免connection泄漏的问题。本文笔者来简单聊聊Router Connection管理这块的内容,Router是如何做到即高效又安全的Connection管理的。
Connection管理的权衡问题
说到Connection管理,这里始终会存在一个权衡问题:是尽可能维护更多的Connection呢还是尽可能少的维护Connection呢?更多的Connection意味着更高的复用率,但同时可能会造成inactive的Connection过多导致影响到下游服务本身。
因此这里Connection管理不是一刀切的做法,没有固定说一定要cache住多少当前的open的Connection,而是一种更加变通的灵活的管理做法。简单来说,当在需要建立更多connection的时候,我们尽量去cache住这些connection。但是当我们发现当下很多connection在一段时间内没有被用到的时候,我们就及时地对其进行close清理掉。RBF的Connection管理正是巧妙地运用了此策略。
RBF的Connection管理
细粒度的Connection Pool划分
在RBF模式下,Router一方面要面对不同client发来的RPC请求,另一方面它还需要转发请求到多个namespace的NN节点。为了做到不同namespace,不同用户间Connection的隔离,Router在这里按照user/namespace/protocol级别进行了Connection的隔离。简单来说,Router按照上述提到的3个维度进行了ConnectionPool的创建,然后每个ConnectionPool自行再进行connection的管理。
Connection的创建
说到connection的管理,它无外乎两大方面的处理,一是connection的创建,二是connection的清理。这里我们先来看看connection的创建。
Router是在每次获取connection的时候如果发现可用connection不够的话,则尝试进行connection的创建的,相关代码如下:
public ConnectionContext getConnection(UserGroupInformation ugi,
String nnAddress, Class<?> protocol) throws IOException {
...
// 1) 根据user+ns+protocol拼出connectionPoolId
ConnectionPoolId connectionId =
new ConnectionPoolId(ugi, nnAddress, protocol);
ConnectionPool pool = null;
readLock.lock();
try {
// 2) 根据connectionPoolId取出对应的ConnectionPool
pool = this.pools.get(connectionId);
} finally {
readLock.unlock();
}
// Create the pool if not created before
if (pool == null) {
...
}
// 3) 取出一个connection
ConnectionContext conn = pool.getConnection();
// Add a new connection to the pool if it wasn't usable
if (conn == null || !conn.isUsable()) {
// 4) 如果connection不可用,则将connection pool加入队列让其进行connection的异步创建
if (!this.creatorQueue.offer(pool)) {
LOG.error("Cannot add more than {} connections at the same time",
this.creatorQueueMaxSize);
}
}
if (conn != null && conn.isClosed()) {
LOG.error("We got a closed connection from {}", pool);
conn = null;
}
return conn;
}
如上代码所示,creatorQueue队列是拿来临时存放那些需要创建connection的connection pool。此queue将被用在下面的创建connection的thread内。
/**
* Thread that creates connections asynchronously.
*/
static class ConnectionCreator extends Thread {
...
@Override
public void run() {
while (this.running) {
try {
// 从queue中获取connection pool
ConnectionPool pool = this.queue.take();
try {
int total = pool.getNumConnections();
int active = pool.getNumActiveConnections();
float poolMinActiveRatio = pool.getMinActiveRatio();
// 判断此pool内
// 1) 前活跃的connection数超过最小阈值
// 2) connection总数不超过最大值限制的话
// 则进行新的connection的创建
if (pool.getNumConnections() < pool.getMaxSize() &&
active >= poolMinActiveRatio * total) {
ConnectionContext conn = pool.newConnection();
pool.addConnection(conn);
} else {
LOG.debug("Cannot add more than {} connections to {}",
pool.getMaxSize(), pool);
}
} catch (IOException e) {
LOG.error("Cannot create a new connection", e);
}
} catch (InterruptedException e) {
LOG.error("The connection creator was interrupted");
this.running = false;
} catch (Throwable e) {
LOG.error("Fatal error caught by connection creator ", e);
}
}
}
上述实现较为巧妙的点在于它进行了最小活跃connection阈值的设置来确保说新的connection不至于大概率在后面会变成一个无用的connection。
Connection的清理
Connection管理另一方面的内容是connection的清理。Router在这里采用定期task schedule的方式进行connection的清理的。
this.cleaner.scheduleAtFixedRate(
new CleanupTask(), 0, recyleTimeMs, TimeUnit.MILLISECONDS);
CleanupTask清理task代码逻辑如下:
/**
* Removes stale connections not accessed recently from the pool. This is
* invoked periodically.
*/
private class CleanupTask implements Runnable {
@Override
public void run() {
long currentTime = Time.now();
List<ConnectionPoolId> toRemove = new LinkedList<>();
// Look for stale pools
readLock.lock();
try {
for (Entry<ConnectionPoolId, ConnectionPool> entry : pools.entrySet()) {
// 1)根据最近一次的活跃时间,查找那些过期的不活跃的connection pool
ConnectionPool pool = entry.getValue();
long lastTimeActive = pool.getLastActiveTime();
boolean isStale =
currentTime > (lastTimeActive + poolCleanupPeriodMs);
// 2)如果查找到的情况,则加入pool移除列表
if (lastTimeActive > 0 && isStale) {
// Remove this pool
LOG.debug("Closing and removing stale pool {}", pool);
pool.close();
ConnectionPoolId poolId = entry.getKey();
toRemove.add(poolId);
} else {
// 3)如果当前connection pool还是活跃在使用的话,则继续进行此pool内无用connection的清理
LOG.debug("Cleaning up {}", pool);
cleanup(pool);
}
}
} finally {
readLock.unlock();
}
// Remove stale pools
if (!toRemove.isEmpty()) {
writeLock.lock();
try {
for (ConnectionPoolId poolId : toRemove) {
pools.remove(poolId);
}
} finally {
writeLock.unlock();
}
}
}
}
上面清理的逻辑从stale的connection pool到pool内不活跃的connection两个层面对无用connection进行清理。这样可以避免那些过多无效connection的存在。
最后是Router connection管理简化图:
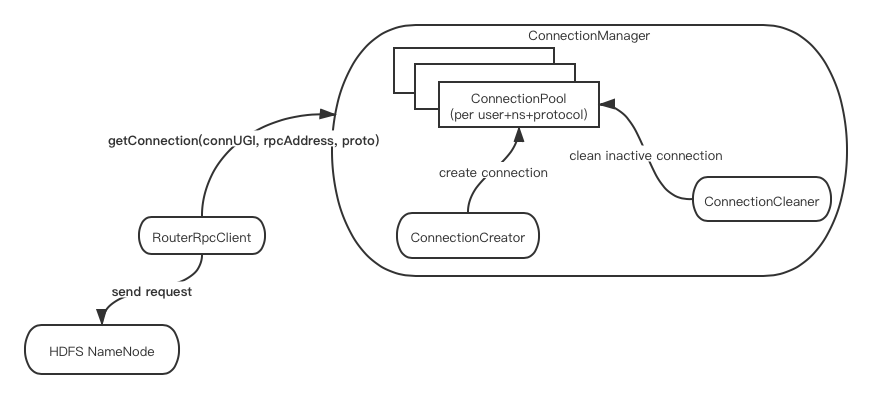
以上就是本文所要阐述的所有内容,上述涉及到的代码均来自于下文参考链接的ConnectionManager类,感兴趣的同学可自行进行阅读学习。
参考资料
[1].https://github.com/apache/hadoop/blob/trunk/hadoop-hdfs-project/hadoop-hdfs-rbf/src/main/java/org/apache/hadoop/hdfs/server/federation/router/ConnectionManager.java