【目录】
1. Transformer 是什么
自注意力机制(Self-attention Mechanism)
自然语言处理(Natural Language Processing)
seq2seq模型(Sequence to Sequence Model)
2. Transformer 结构
输入部分
输入(Inputs)
输入嵌入 (Input Embedding)
右移输出 Outputs (Shifted Right)
输出嵌入(Output Embedding)
位置编码(Positional Encoding)
输出部分
Linear(线性层)
Softmax
输出概率(Output Probabilities)
3. 编码器(Encoder)
Encoder擅长什么
双向上下文编码 (Bi-directional Context)
组成模块
多头自注意力机制(Multi-head self-attention Mechanism)
查询、键和值(Query,Key,Value)
前馈神经网络(Feed-Forward Network)
残差连接与层归一化(Add & Norm)
4. 解码器(Decoder)
Decoder擅长什么
单向上下文编码(Unidirectional Context)
组成模块
掩码自注意力机制(Masked self-attention mechanism)
编码-解码注意力(Encoder-Decoder Attention)
前馈神经网络(Feed-Forward Network)
5. 编码器-解码器(Encoder-Decoder)
使用Encoder-Decoder结构的好处
1. Transformer 是什么
Transformer 是一个基于自注意力机制(Self-attention mechanism)的神经网络架构, 是由2017年的论文《Attention is All You Need》中提出的,为自然语言处理(Natural Language Processing)领域带来了新的模型架构。他是一种seq2seq模型(Sequence to Sequence Model)
Transformer可以解决将输入序列转换为输出序列的任务,通过分析大量数据中,学会理解和生成类似人类语言的文本。
自注意力机制(Self-attention Mechanism)
又名Scaled Dot-Product Attention,是深度学习的一种机制,Transformer神经网络架构中的核心组成部分。Attention 指的是根据上下文确定哪个单词在理解语义中最重要,而 self 指只用输入序列进行 attention 计算,而不涉及输出序列
自然语言处理(Natural Language Processing)
简称 NLP ,是语言学和机器学习中的一个领域,专注于解析人类的词汇、语言、及其语境。
NLP 是语言学和机器学习交叉领域,专注于理解与人类语言相关的一切。 NLP 任务的目标不仅是单独理解单个单词,而且是能够理解这些单词的上下文。以下是常见 NLP 任务的列表,每个任务都有一些示例:- **对整个句子进行分类**: 获取评论的情绪,检测电子邮件是否为垃圾邮件,确定句子在语法上是否正确或两个句子在逻辑上是否相关- **对句子中的每个词进行分类**: 识别句子的语法成分(名词、动词、形容词)或命名实体(人、地点、组织)- **生成文本内容**: 用自动生成的文本完成提示,用屏蔽词填充文本中的空白- **从文本中提取答案**: 给定问题和上下文,根据上下文中提供的信息提取问题的答案- **从输入文本生成新句子**: 将文本翻译成另一种语言,总结文本(来自 Hugging Face 官方教程)
seq2seq模型(Sequence to Sequence Model)
序列到序列模型,深度学习和NLP中的重要概念,是一种根据给定的序列然后根据特定的方式生成另一个序列的方法,也可以称为Encoder-Decoder模型(编码-解码模型),是RNN(Recurrent Neural Network)n-to-m 的一个变种
RNN(Recurrent Neural Network):循环神经网路,一个序列当前的输出与前面的输出有关系。n-to-m指输入序列(n个元素)到输出序列(m个元素)可以不一样长
2. Transformer 结构
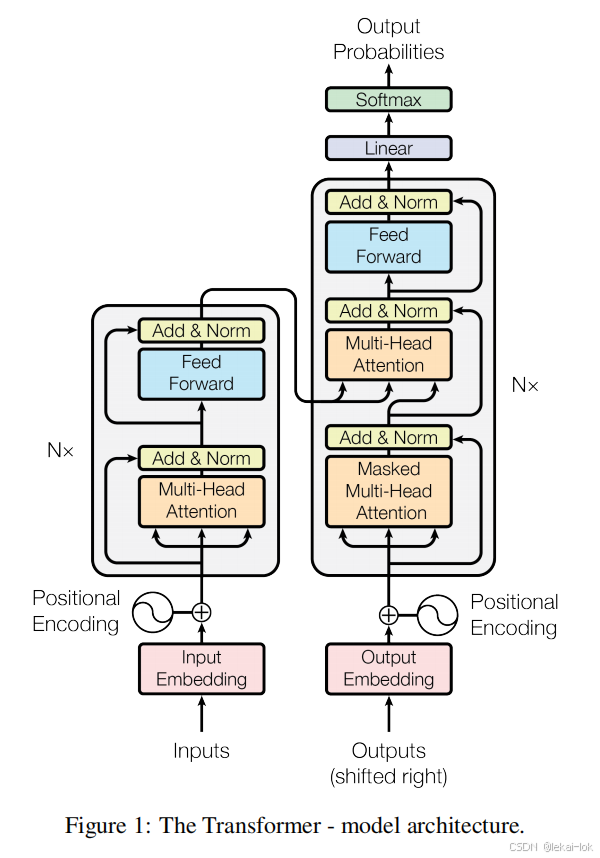 论文 "Attention is All You Need" 中的transformer结构
论文 "Attention is All You Need" 中的transformer结构 Transformer 是由 一个Encoder(编码器) 和 Decoder (解码器)组成的,输入数据首先进入编码器,在其中被转换为每个输入词语的数值表示,称为Feature Vector(特征向量)
通过自注意力机制,它能够同时考虑上下文(左右两侧),从而实现语言理解。
简单结构如下:Input(输入),六层Encoder和六层Decoder,Output(输出)
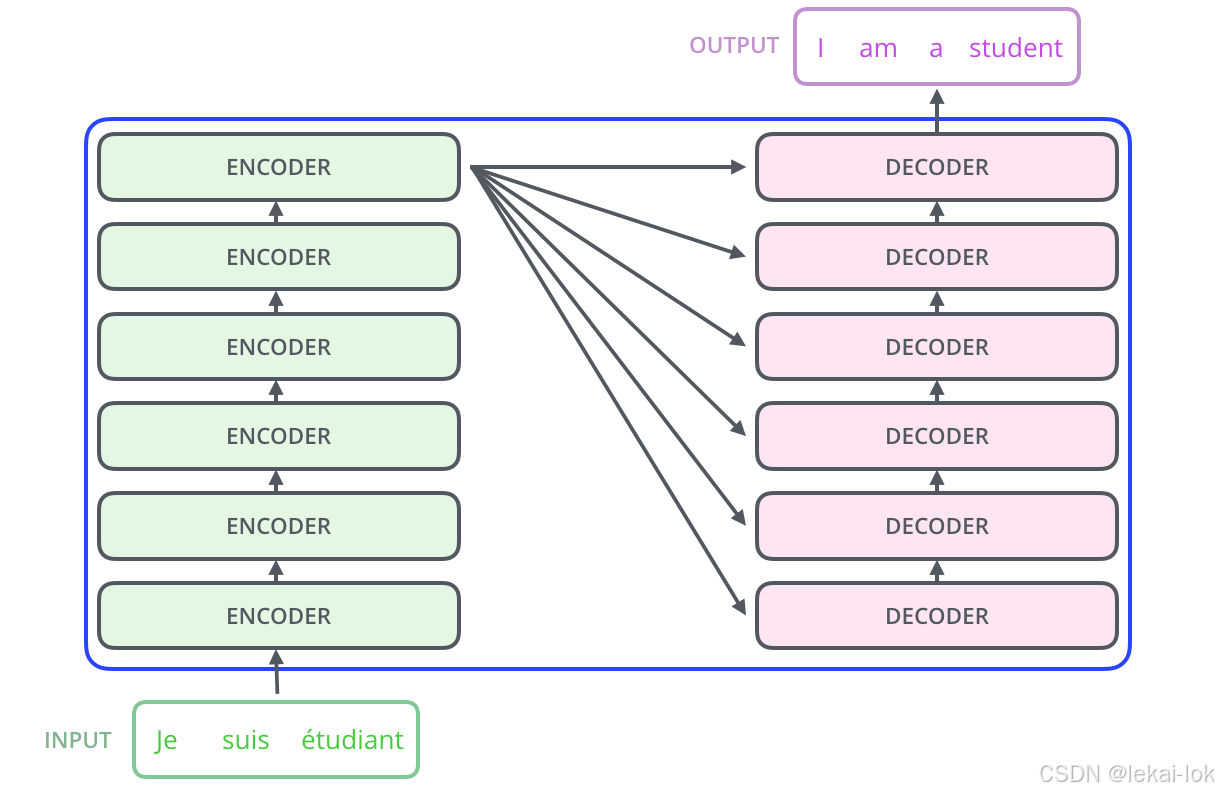 图片来自 The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time.
图片来自 The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time.
输入部分
输入(Inputs)
输入表示为一系列的单词或令牌(token)。这些token是文本的基本单位,可以是单词、标点符号或其他任何文本元素(如开始符、结束符)
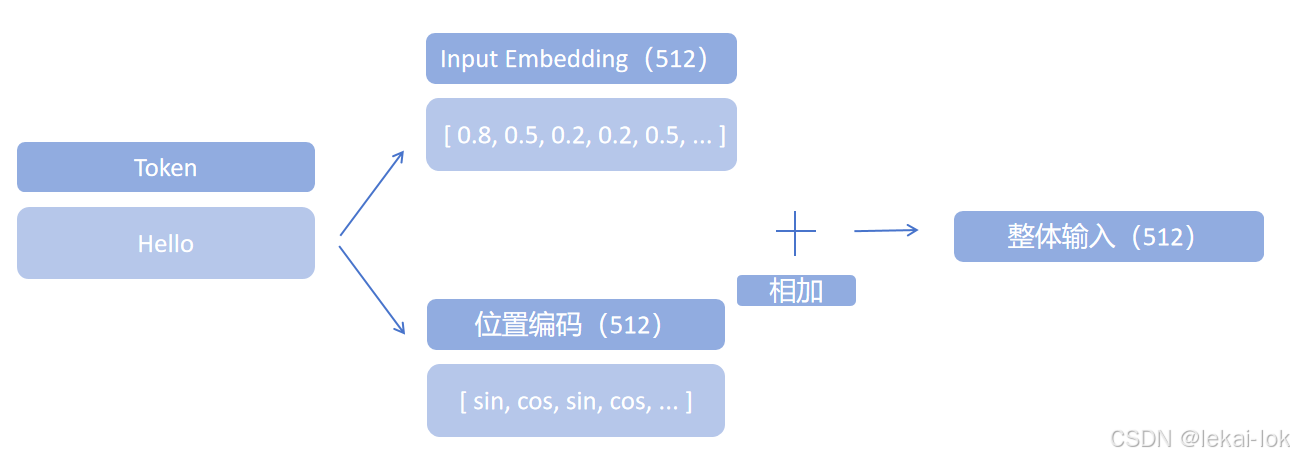
输入嵌入 (Input Embedding)
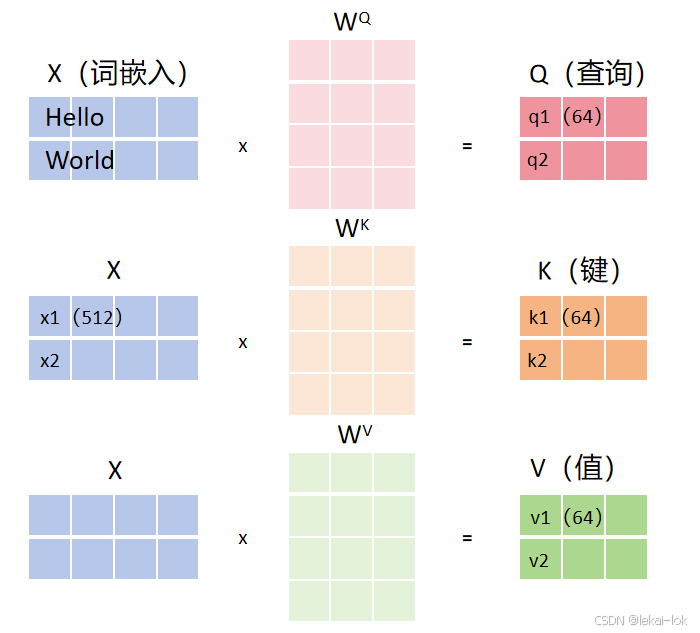
将输入文本中的每个token转换为一个连续的、固定维度的向量序列,这个向量可以捕捉词语的语义和句法信息,并映射为一组数值(如:Hello -> [ 0.8, 0.5, 0.2, 0.2, 0.5, ... ]),叫做词嵌入
每个Encoder都会得到一个固定长度为d_model = 512的特征向量列表。最底层的Encoder获得词嵌入,而其他层的Encoder则接收地下一层的Encoder的输出。
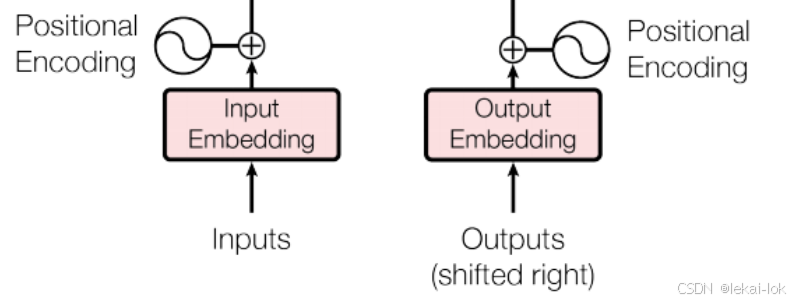
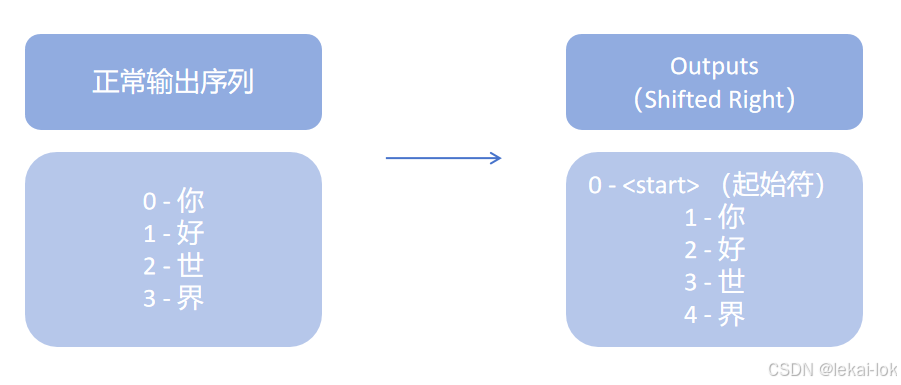
右移输出 Outputs (Shifted Right)
输出指模型预测现有的输出句子,每个时间步模型会预测下一个词,并将其添加到输出序列的末尾
Shifted Right就是将Decoder的初始输出序列向右移动一个位置,增加一个起始符,导致序列整体向右移一位,这样做可以让模型从起始符开始预测第一个词语
输出嵌入(Output Embedding)
输出嵌入与输入嵌入类似,它将输出序列中的每个token转换为一个连续的、固定维度的向量序列。这些向量可以捕捉词语的语义和句法信息,并映射为一组数值。
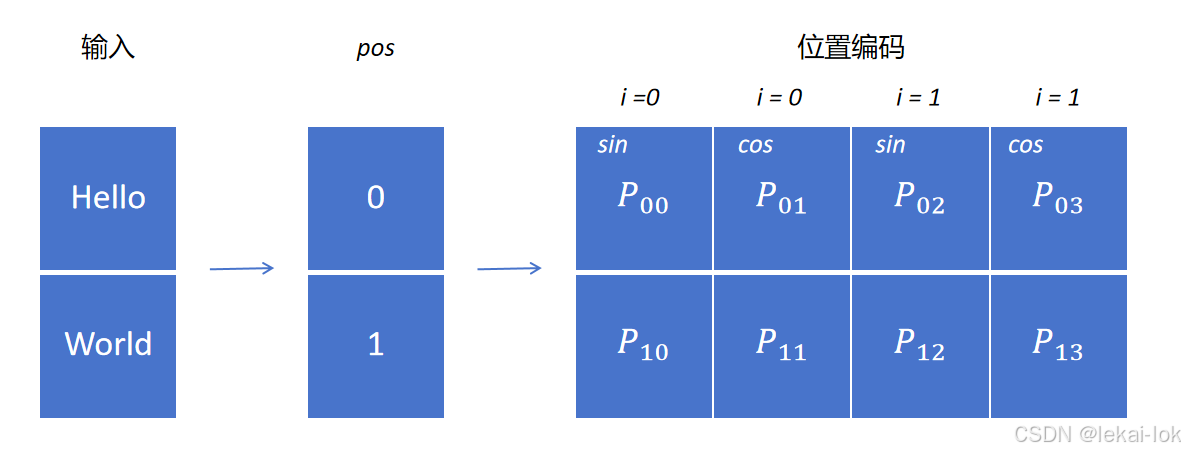
位置编码(Positional Encoding)
在输入嵌入中注入序列中词语的位置信息,在处理序列数据时,词语的位置对于理解句子的意义通常是重要的。Transformer 的位置编码使用sin和cos函数生成的位置向量,将每个位置映射到-1到1之间的值
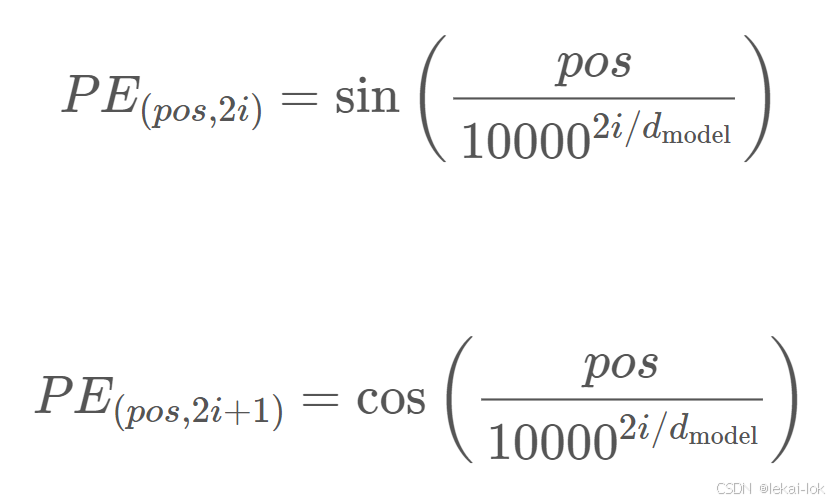
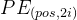 代表偶数token的位置向量,用sin函数
代表偶数token的位置向量,用sin函数
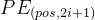 代表基数token的位置向量,用cos函数
代表基数token的位置向量,用cos函数
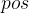 代表token在输入里的位置
代表token在输入里的位置
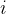 代表位置编码的第几sin/cos组,共有256组,从零开始算最后为255(0, 1, 2, 3, ...,
代表位置编码的第几sin/cos组,共有256组,从零开始算最后为255(0, 1, 2, 3, ..., 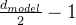 )
)
 代表特征向量的维度(512)
代表特征向量的维度(512)
整体输入:
输出部分
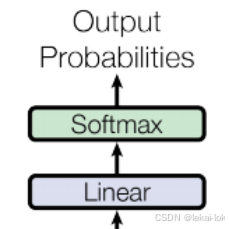
Linear(线性层)
全连接神经网络的一个组成部分,它可以将输入向量投射到另一个维度。在 Transformer 模型中,线性层通常用于将 Encoder 和 Decoder 的输出转换为对数几率向量
Softmax
激活函数,可以将实数向量转换成词汇表的概率分布,这个概率分布代表了模型对于每个词汇预测的概率,让其中所有概率值的总和等于一
输出概率(Output Probabilities)
输出序列中每个词汇预测的概率,用Softmax 激活函数激活Decoder 的输出向量后,可以得到每个词汇的概率分布,其中输出概率最大的词汇被选择作为下一个预测的词
3. 编码器(Encoder)
Encoder负责处理输入序列并生成一系列连续的向量表示。
Encoder擅长什么
Encoder采用双向上下文编码(Bi-directional Context),这意味着位置编码同时考虑了词汇在句子中左侧和右侧的词语,并通过自注意力机制来实现这一功能
双向上下文编码 (Bi-directional Context)
编码中考虑了词汇在句子中左侧和右侧的词语,从而更好地理解整个句子的上下文
擅长:理解句子,情感分析(Sentiment analysis),推测masked词语
有名的Encoders有BERT、RoBERTa、ALBERT、ERINE(文心一言)等
组成模块
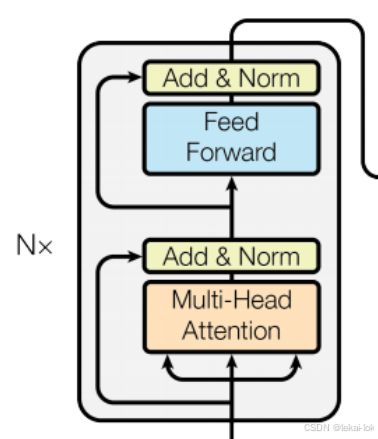
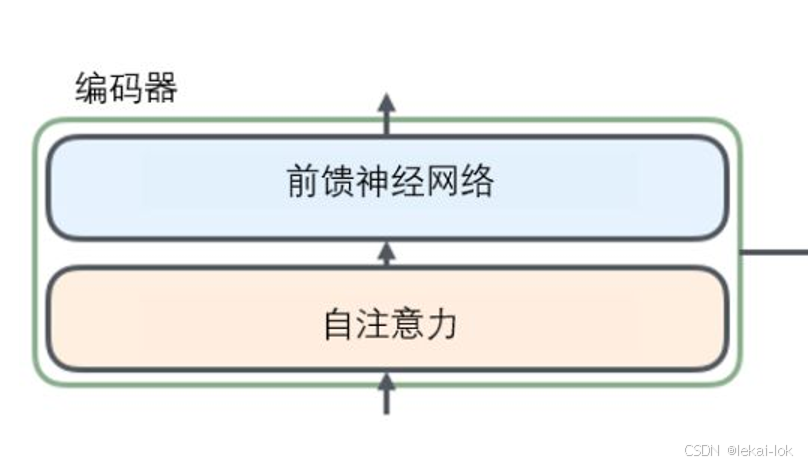
Encoder是由 N=6 个相同的层堆叠而成,每个层包含两个子层。
第一层是一个多头自注意力机制(Multi-head self-attention mechanism)
第二层是一个逐位置的前馈神经网络(Feed-Forward Network)
多头自注意力机制(Multi-head self-attention Mechanism)
自注意力机制的一种扩展,多头的意思就是将输入序列的嵌入向量分割成多个“头”,每个“头”都有自己的权重矩阵,每个头都会分别计算查询、键和值向量之间的相似度,通过并行计算后后通过Softmax函数转换为权重
权重矩阵(Weight Matrix):用于计算注意力权重,权重矩阵代表了每个词语在注意力机制中的重要性。用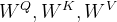 表示查询、键和值(Q, K, V)的权重矩阵
表示查询、键和值(Q, K, V)的权重矩阵
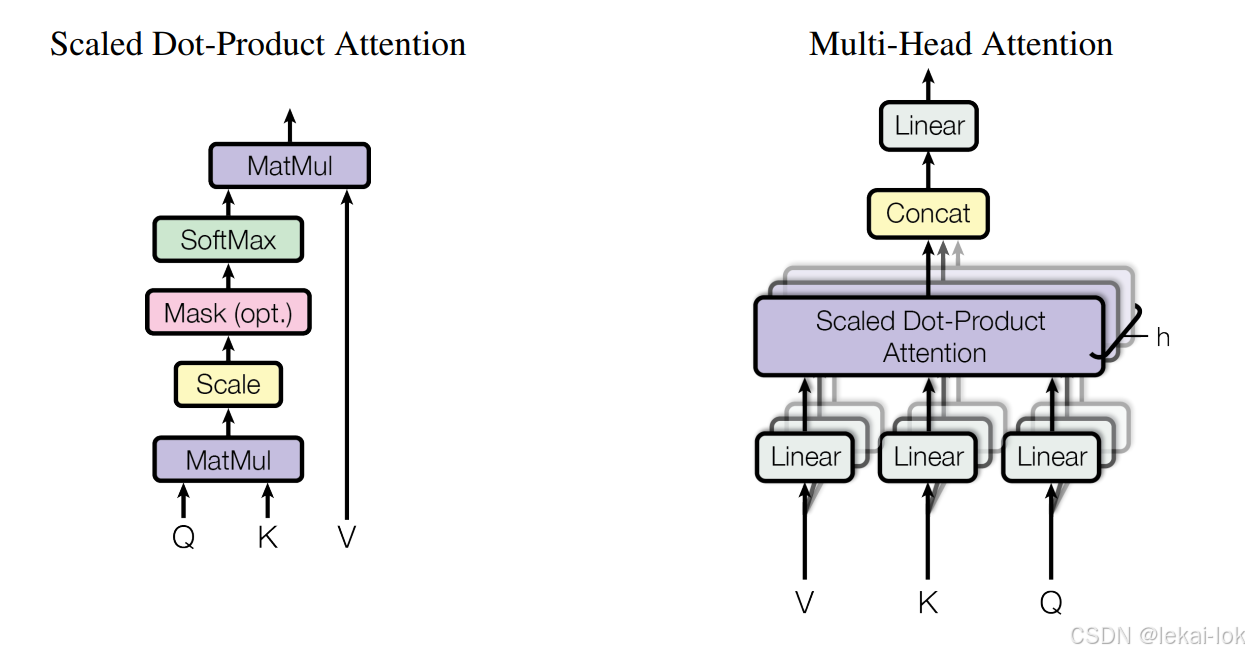 多头自注意力机制结构,来自原论文
多头自注意力机制结构,来自原论文 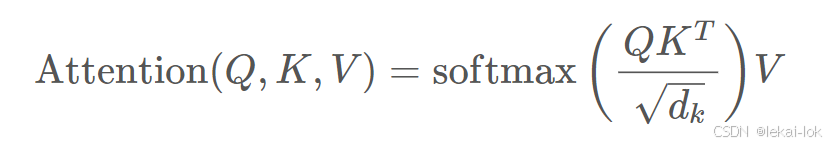
查询、键和值(Query,Key,Value)
自注意力机制计算的第一步是将序列中的每个元素转换成三个向量进行处理——即查询向量、键向量和值向量,通常通过Q, K, V的权重矩阵与原始元素向量(如词嵌入)相乘得到。
Mathmul:模型计算完查询、键和值向量跟上方公式后会对序列中的每一个单词计算注意力分数,通过取得所有输入句子中的token的键向量和现在单词的查询向量的点积来计算的(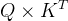 )
)
Scale:计算分数后将分数除以 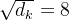 ,
,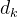 是键向量的维数(在论文中作者设定为64,平方根为8)这么做可以让梯度更稳定,因为论文作者怀疑当
是键向量的维数(在论文中作者设定为64,平方根为8)这么做可以让梯度更稳定,因为论文作者怀疑当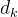 的值较大时,点积的大小会增大,导致softmax梯度极小。
的值较大时,点积的大小会增大,导致softmax梯度极小。
Softmax:接下来进行 softmax 对注意力分数进行归一化,获得注意力权重正值且和为1。
Mathmul:然后每个值向量乘以softmax分数,来强化为理解语义的相关单词,并弱化不相关的单词,最后,计算所有值向量加权的和,得到该位置的自注意力机制输出
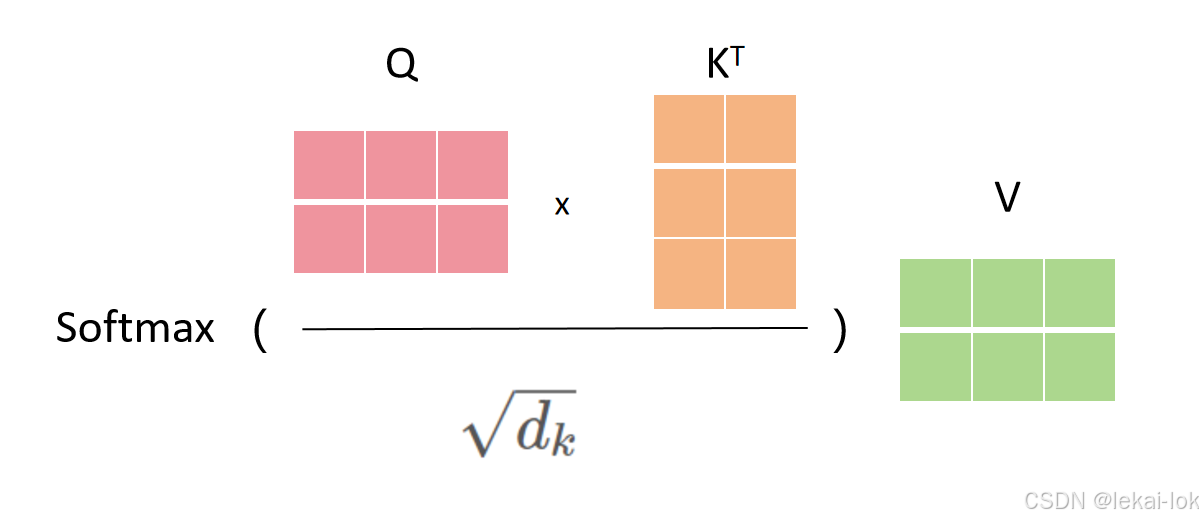
多头机制增加了一步,将词嵌入分成8个不同的头分别用以上计算,然后合到一起(Concat)并通过另一个线性层来整合这些信息,然后传给前馈神经网络
第二层以上的Encoder输入不是词嵌入而是上一个Encoder处理后的输出。
前馈神经网络(Feed-Forward Network)
单向传输信息的神经网络,逐个处理输入tokens的非线性变换网络,它在每个位置上进行转换,然后将处理后的信息传递到下一个层
残差连接与层归一化(Add & Norm)
残差连接通过添加跨层连接,帮助模型更好地训练。层归一化在每个子层之后将输出标准化。
全部Encoder输出后,最后一个Encoder将键矩阵(K)和值矩阵(V)传递给每一个Decoder层,因为Decoder的自注意力机制中需要使用这些矩阵来计算与Encoder输出之间的注意力权重。
4. 解码器(Decoder)
Decoder负责预测词语可能性、生成句子。Decoder的结构使得它能够在生成序列时考虑之前生成的所有词语
Decoder擅长什么
Decoder采用单向上下文编码(Unidirectional Context),这意味着着词语只能观察到左侧的上下文,而右侧的上下文则被隐藏(或只考虑右侧而屏蔽左侧也是可以的),这一功能是通过使用掩码自注意力机制(Masked self-attention mechanism)来实现的
单向上下文编码(Unidirectional Context)
生成序列时只考虑词语左侧的上下文(之前的词语),而另一侧的上下文(而未来的词语)则被隐藏
擅长:因果语言模型(Causal Language Modeling)- 预测句子中的下一个词语,生成序列
有名的Decoders有GPT-2、GPT Neo、ChatGLM(智谱清言)、等
组成模块
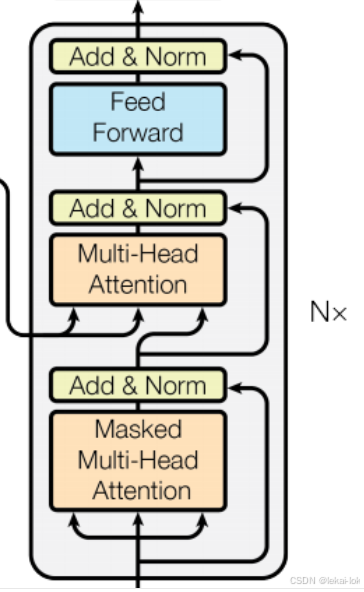
Decoder也是是由 N=6 个相同的层堆叠而成,每个层包含三个子层。
除了和Encoder相同的两个子层,额外加了一个子层,一个对Encoder的输出执行多头注意力机制的子层,注意,这个不是自注意力,而是编码-解码注意力(Encoder-Decoder Attention)
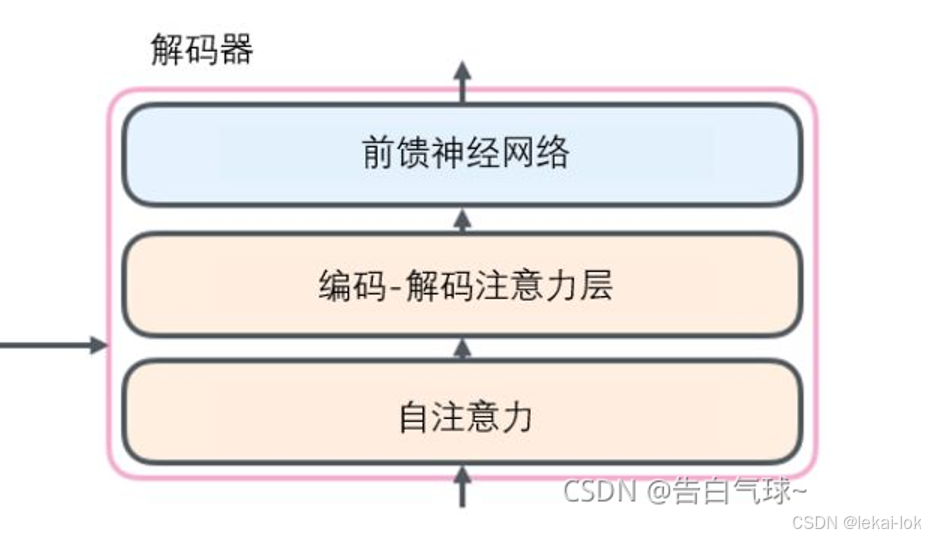
掩码自注意力机制(Masked self-attention mechanism)
自注意力层只被允许看到输出序列中已经生成的位置,防止模型在预测下一个词时能看到未来的信息。这是通过在自注意力计算中的softmax之前,将未来位置打上掩码(设置为 -inf)来实现的。
编码-解码注意力(Encoder-Decoder Attention)
和自注意力相似,只不过查询矩阵(Q)来自下方的Decoder,而键矩阵(K)和值矩阵(V)来自Encoder的最终输出。它的作用是在Decoder层中结合Encoder层的输出信息,这帮助Decoder在生成每个词语时都能够参考整个输入序列的信息
前馈神经网络(Feed-Forward Network)
与Encoder中的前馈神经网络结构相同,处理输入后传递到下一个Decoder层
5. 编码器-解码器(Encoder-Decoder)
Encoder 和 Decoder 可以不共享单词权重。Encoder负责理解输入句子,而 Decoder则负责根据Encoder的理解生成序列。
使用Encoder-Decoder结构的好处
这种结构允许模型在理解输入文本的语义内容后,根据需要生成不同长度的输出文本,以实现高质量的翻译或摘要结果。
擅长:处理序列到序列的任务,如翻译,文本摘要
有名的Encoder-Decoder有Transformer自己、BART、Pegasus等
于是整个Transformer工作流程如下
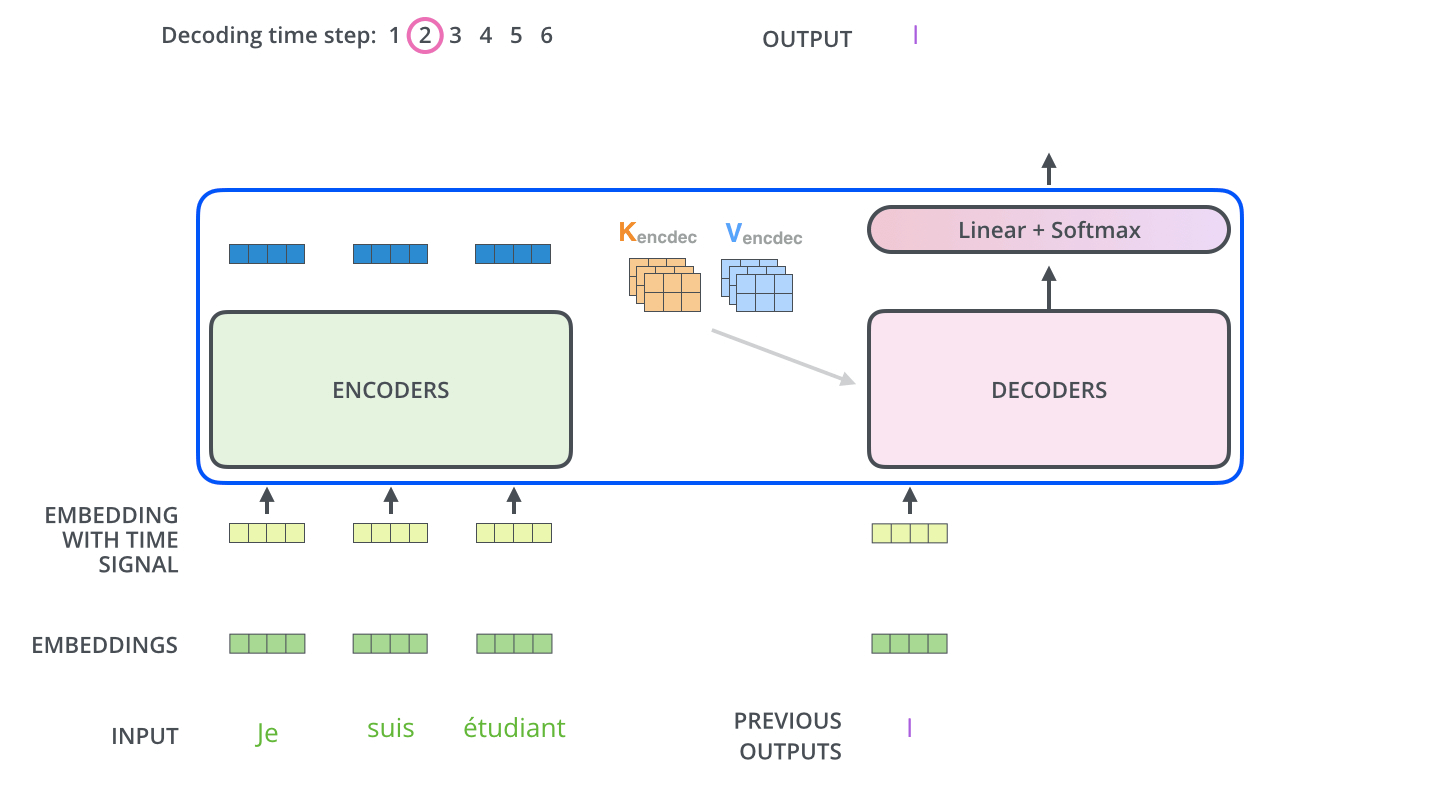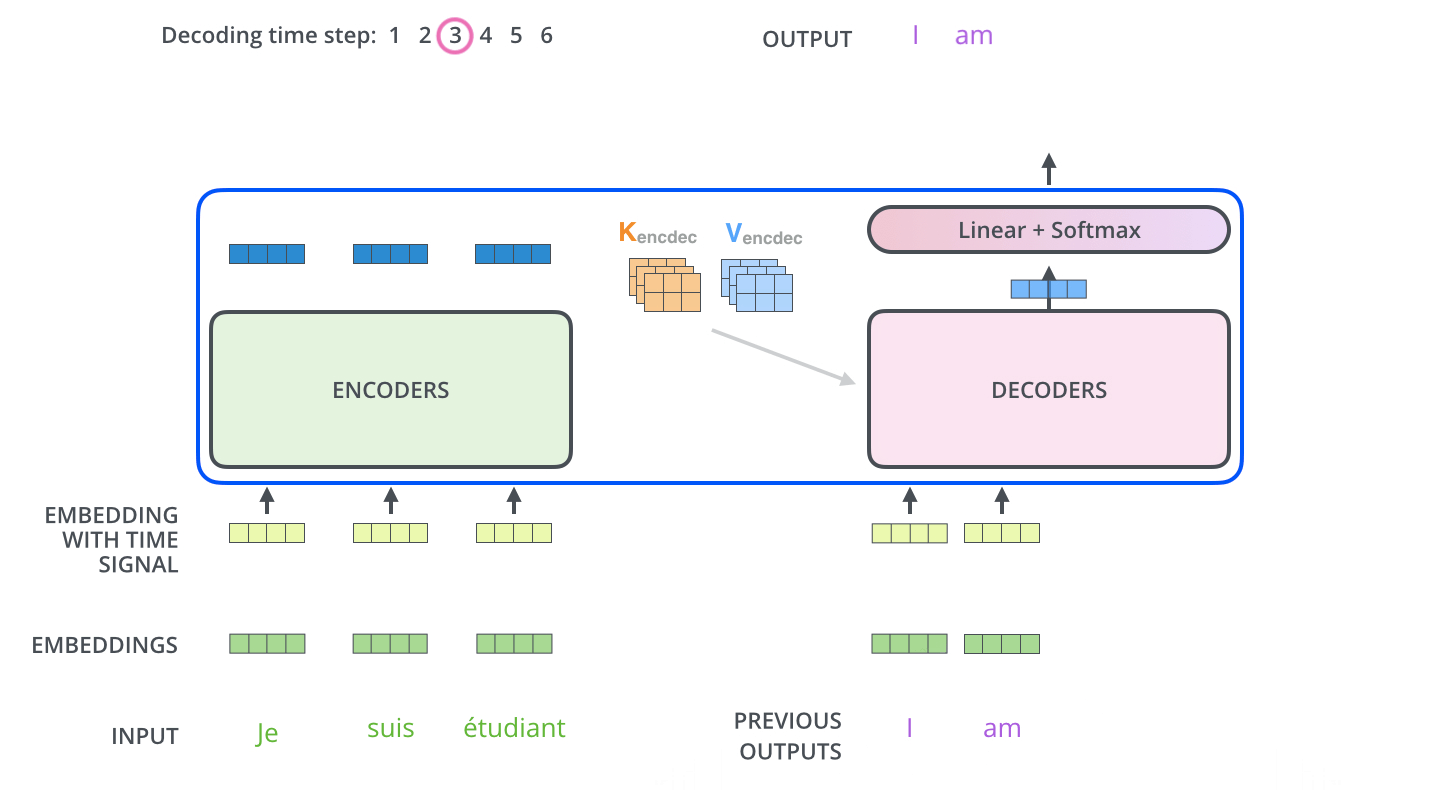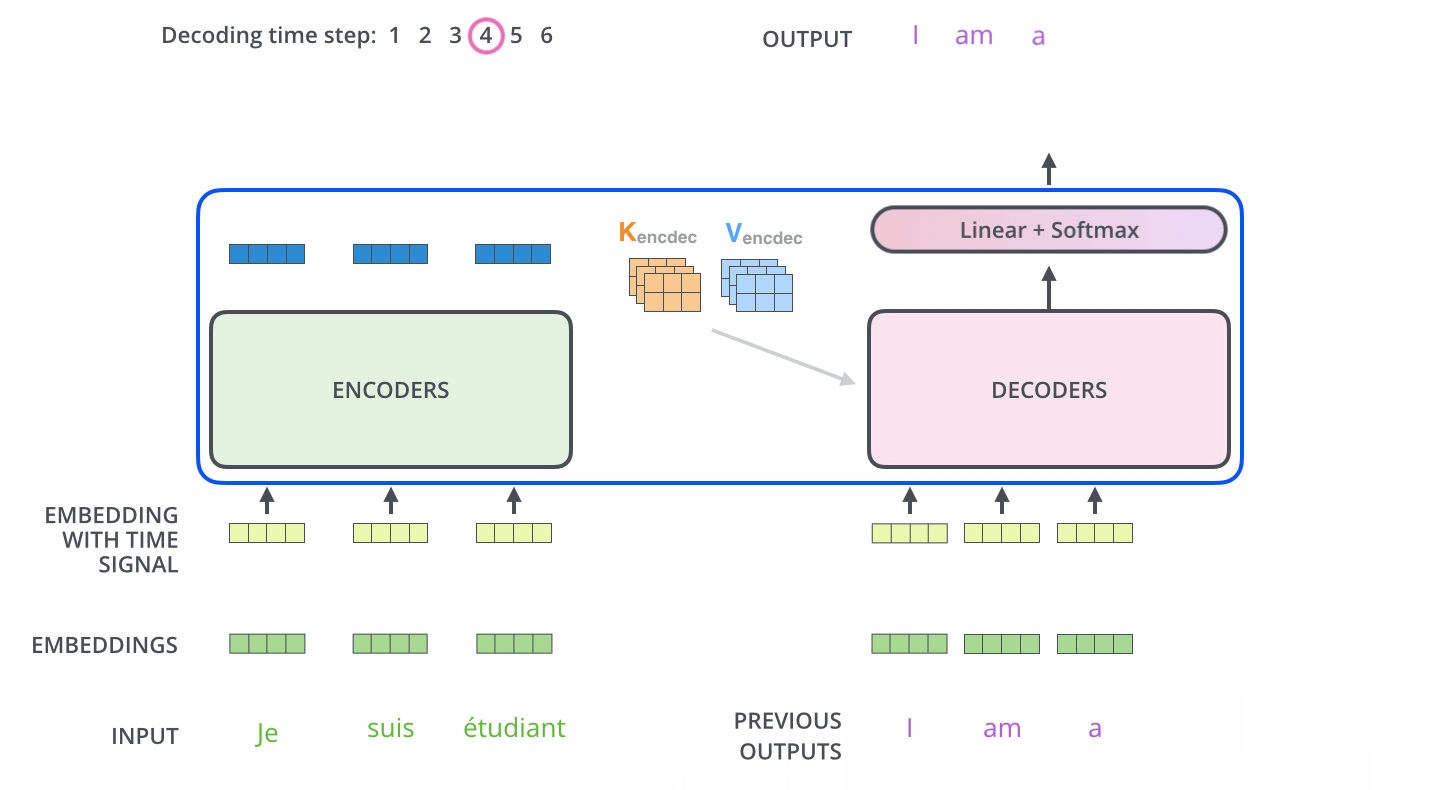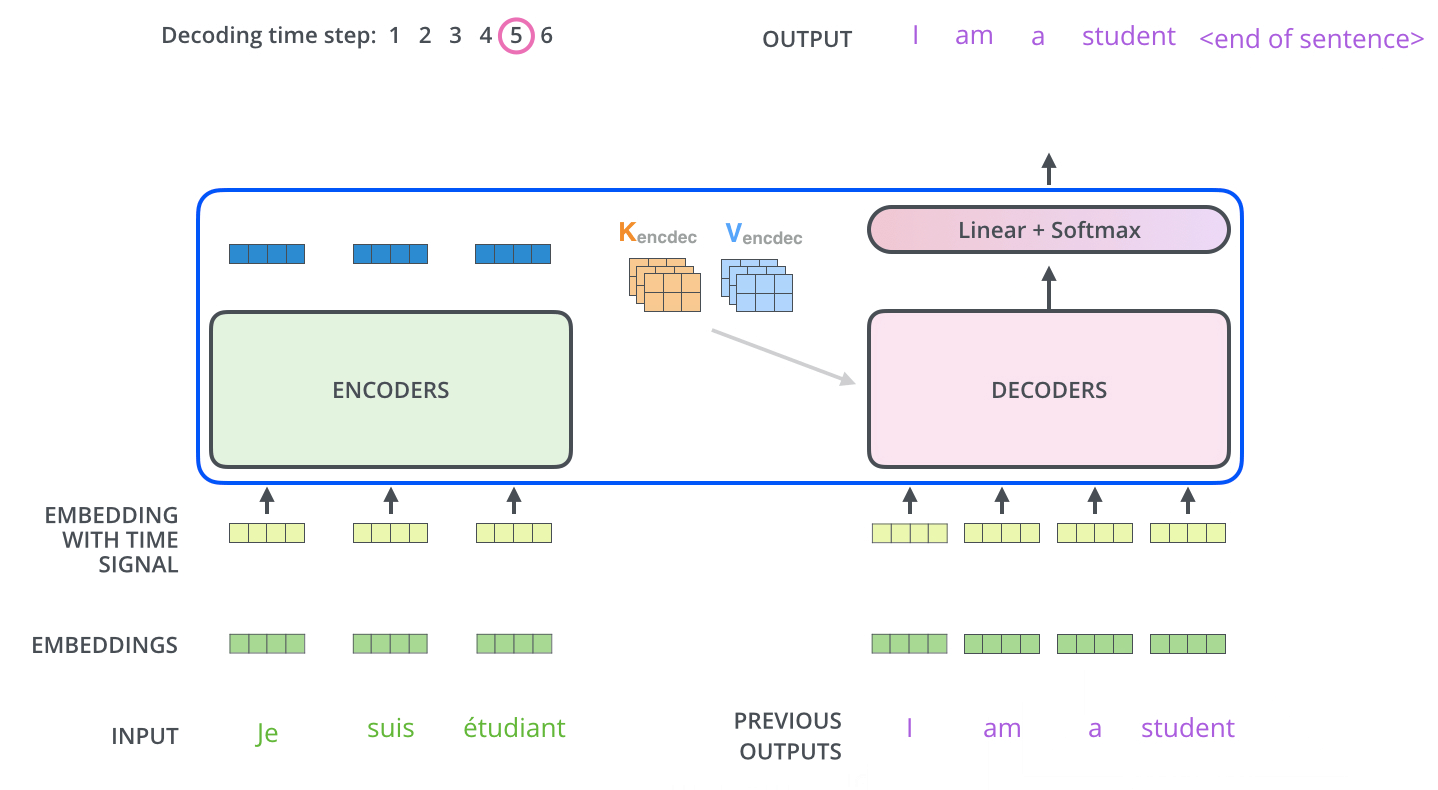 来自 The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time.
来自 The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time.
参考文献:
Attention is All You Need
GitHub - huggingface/course: The Hugging Face course on Transformers
Attention机制与Self-Attention机制的区别_self attention机制有何不同-CSDN博客
哔哩哔哩 | 1.4 The Transformer architecture - Hugging Face自然语言处理教程(官方)
【神经网络】学习笔记十四——Seq2Seq模型-CSDN博客
【超详细】【原理篇&实战篇】一文读懂Transformer-CSDN博客
How Transformers Work: A Detailed Exploration of Transformer Architecture | DataCamp
图解Transformer系列一:Positional Encoding(位置编码)
A Gentle Introduction to Positional Encoding in Transformer Models, Part 1 - MachineLearningMastery.com
这是我见过最全的 Transformer 模型解读了(代码+注释+讲解)-CSDN博客
一文彻底搞懂 Transformer(图解+手撕)-CSDN博客
The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time.
如有错误请指出!