文章目录
插入排序直接插入排序希尔排序内层循环时间复杂度计算 选择排序直接选择排序优化 堆排序
插入排序
直接插入排序
时间复杂度最差:大的数据都在左边,小的数据在右边,随着有序区间增大,交换次数增多
时间复杂度最优:小的数据在左边,大的数据在右边。
直接插入排序,通过构建有序序列,对于为排序的数据,在已排序的序列,从后向前寻找到适合位置插入。
从第一个元素开始,认为前一个元素已经排序(假设)从为排序的第一个元素开始,将其与已经排序的元素从前向后依次进行比较,找到合适的位置插入。对于下一个为被排序的元素重复以上过程,直到所有元素排序完成时间复杂度:考虑最坏的情况,对逆序的数组排成有序的时间复杂度为O(n^2),最好的情况,对有序的数组进行排序,时间复杂度为O(n)
空间复杂度:O(1)
void InsertSort(int* arr, int n){for (int i = 0; i < n - 1; i++){int end = i;int tmp = arr[end + 1];while (end >= 0 && arr[end] > tmp){arr[end + 1] = arr[end];end--;}arr[end + 1] = tmp;}}现在假设对 8 4 5 3四个数据使用直接插入排序算法进行排序
4 8 5 3接着,保存8之后的数据,这次是5,将其保存后与8进行比大小,8大,8向前移动,而5这与8之后的有序序列比较大小,寻找合适位置插入5 与 4 比大小,5大,5就放在了4之前 4 5 8 3保存8之后的数据,这次是3,将其保存后与8进行比大小,8大,8向前移动,而3这与8之后的有序序列比较大小5比3大,end–继续向后找,4比3大,end继续减1向后找,这次end减到-1也就说明没有数据可以比较,3就是最小的,将3放入end + 1的位置即可。3 4 5 8 希尔排序
希尔排序,是在直接插入算法的基础上进行优化的排序算法,通过增量序列来提高算法性能。首先对数据进行预排序,将小的数据在左边,大的数据在右边,使直接插入排序的时间复杂度最优。
预排序,根据gap的大小进行分组,排序完更新gap直接插入排序(gap == 1)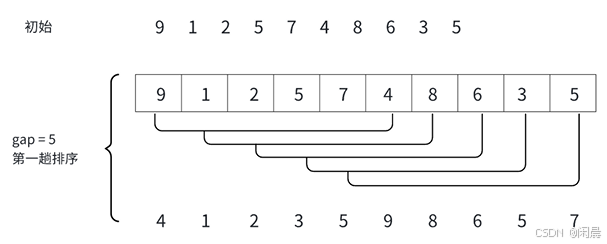
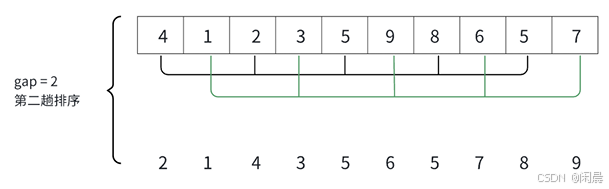
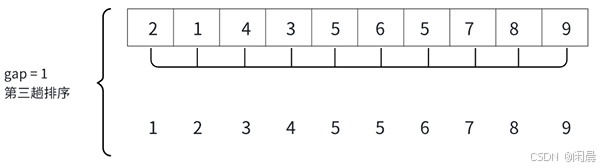
void ShellSort(int* arr, int n){int gap = n;while (gap > 1){gap = gap / 3 + 1;for (int i = 0; i < n - gap; i++){int end = i;int temp = arr[end + gap];while (end >= 0 && arr[end] > temp){arr[end + gap] = arr[end];end -= gap;}arr[end + gap] = temp;}}}希尔排序时间复杂度约为:O(n^1.3) 出自严蔚敏----- 《数据结构(C语言版)》
外层while循环,时间复杂度:gap = n / 3,每次循环一次,n除一次3,循环执行x次,就有
n / 3 x = 1 − > n = 3 x − > x = l o g 3 n n / 3^x = 1-> n = 3^x-> x = log_3^n n/3x=1−>n=3x−>x=log3n
外层循环时间复杂度:
O ( l o g n ) O(log^n) O(logn)
内层循环时间复杂度计算
假设有n个数据,一共有gap组,则每组有n / gap个,在gap组中,插入移动的次数最坏的情况下为:g a p ∗ ( 1 + 2 + … … + ( n / g a p − 1 ) ) gap*(1+2+……+(n/gap - 1)) gap∗(1+2+……+(n/gap−1))
当gap为 n / 3时,移动的总次数为:n / 3 ∗ ( 1 + 2 ) = n n / 3*(1 + 2) = n n/3∗(1+2)=n
时间复杂度为:O(n)
当gap为 n / 9时,移动的总次数为:n / 9 ∗ ( 1 + 2 + 3 + 4 … … + 8 ) = 4 n n / 9 *(1+2+3+4……+8) = 4n n/9∗(1+2+3+4……+8)=4n
时间复杂度为:O(4n)
当gap为1时,此时插入移动的次数并不需要考虑最坏的情况,通过之前的预排序已经将小的数据在左边,大的数据在右边,将一个乱序的数据排为一个基本有序的,此时直接插入排序的时间复杂度时最优的情况。 时间复杂度为:O(n)
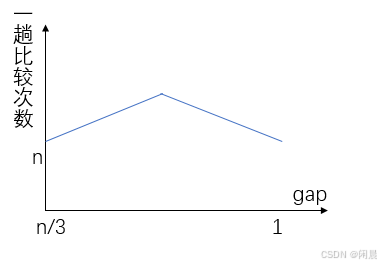
总的说:希尔排序的平均情况性能通常比最坏情况要好,在某些情况下,希尔排序的实际运行时间可能比理论时间复杂度要快。
gap/3 + 1与 gap/2 + 1的区别:当n等于10
gap / 3 + 1 ——>4——>2——>1
gap / 2 + 1 ——>6——>4——>3——>2——>1
可以发现当gap除2时比gap除3时需要进行的预排序次数多2次,gap除3里每组的数据个数比gap除2多1个。假设当n非常大时为10w、100w,那gap除2需要执行的循环次数就远大于gap除3,增加了时间性能的消耗。而gap除3只比gap除2多移动一个数据,它带来的影响是小于增加循环的次数的。
选择排序
每⼀次从待排序的数据元素中选出最小(或最大)的⼀个元素,存放在序列的起始位置,直到全部待 排序的数据元素排完
直接选择排序
通过两个指针向后遍历,begin指针从第一个位置开始,mini指针负责遍历begin之后所有的数据,并记录最小的那个数据,mini遍历完数组后将最小的数据与begin交换,交换完成后begin向前走一步mini向前走一步,如此反复循环。
void SelectSort(int* arr, int n){ for(int i = 0; i < n - 1; i++) { int begin = i; int mini = i; for(int j = begin + 1; j < n; j++) { if(arr[j] < arr[mini]) { mini = j;} } Swap(&arr[mini], &arr[begin]); }}优化
对初代版本的优化,既然向后循环的过程是在不断找第i个数据之后最小的数据,那也可以向后找第i个数据之后最大的数据,让最大的数据和最后一个位置的数据进行交换。
使用begin,end分别记录数组的开始位置和数组末尾,mini负责从前向后找最小的数据然后与begin交换,maxi负责从前向后找最大的数据然后与end交换。
将单向排序的直接选择排序算法,优化为双向的排序算法。begin当为数组的起始位置,end为数组的结束位置,从两头向中间靠拢,当end <= begin时跳出循环结束排序。
void SelectSort(int* arr, int n){int mini, maxi;int begin = 0;int end = n-1;while(begin < end){maxi = mini = begin;for(int j = begin + 1; j <= end; j++){if(arr[j] < arr[mini]){mini = j;}if(arr[j] > arr[maxi]){maxi = j;}}if(maxi == begin)maxi = mini;Swap(&arr[maxi], &arr[end]);Swap(&arr[mini], &arr[begin]);begin++;end--;}}在代码中尤为重要的一点:if(maxi == begin),这串if语句。
若没有这串代码对 5 3 9排序的结果为:

对 9 6 3排序的结果为 :

9 6 3,刚开始进入循环时,begin指向9的位置,end指向3的位置,maxi和mini都处于begin指向的位置。 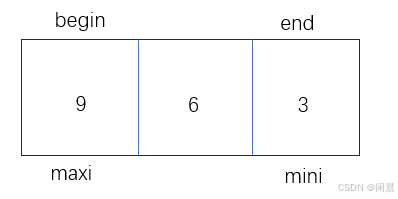
mini开始从前向后找小,3是待排数据里最小的,mini此时指向3,出了内层for循环后开始交换,此时begin指向9。
maxi开始从前向后找大,9为待排数据里最大的,maxi此时指向9,出了内层for循环后开始交换,此时end指向3。
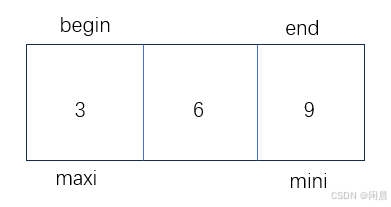
根据代码,Swap(&arr[maxi], &arr[end]);,maxi与end交换,9 和 3进行交换,此时数组的顺序为 3 6 9
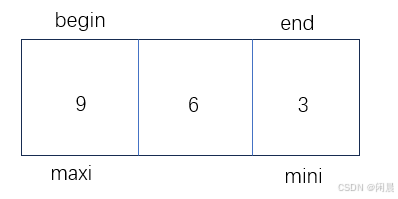
到下一步,Swap(&arr[mini], &arr[begin]);,mini与begin交换,数组发生改变,此时mini指向的值为9,begin指向的值为3,发生交换结果为:9 6 3
这里多进行了一次重复交换,发生重复交换的源头是,begin == maxi 以及 end == mini,两者劈叉了~ ,各自找了个小3~

解决的办法,通过if语句maxi的位置放在end下面,或者mini的位置放在begin下面。
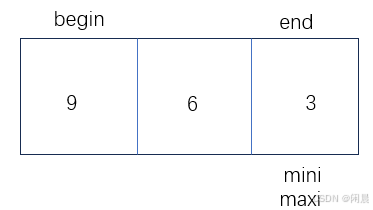
此时进行第一次交换 Swap(&arr[maxi], &arr[end]);,maxi与end交换,数组的顺序为 9 6 3,进行第二次交换,Swap(&arr[mini], &arr[begin]);,mini与begin交换,数组顺序为 3 6 9。
堆排序
堆排序是借助数据结构堆,来实现的排序算法,借助堆的自上向下调整算法,实现建堆,排序堆。堆详解,
自上向下算法是向下找孩子节点更具传递过来的参数 parent 向下个找孩子。
与自下向上调整算法相比,它会进行更多的判断,因为向下找的孩子有两个。而我们默认的孩子起始是左孩子节点。
在对孩子节点与父亲节点比较大小交换之前还需要比较左孩子节点和右孩子节点,arr[child] > arr[child + 1],若左孩子节点大于有孩子,那child就需要加1,但还有个前提,万一child加1后刚好不满足 child < n的条件从而在后续的交换里导致数组越界访问,所以在if语句里还需要加上一条判断 child + 1 < n。
执行孩子节点与父亲节点交换的if语句里,在交换完两个节点后需要更新新的父亲节点,和孩子节点来是否存在比父亲节点还小的值。最后若孩子节点大于父亲节点,那就说明不需要交换,使用break跳出循环即可。
左孩子:孩子 = 父亲 * 2 + 1,child < n
右孩子:孩子 = 父亲 * 2 + 2,child < n
需要注意的:对数据排升序,建大堆,排降序,建小堆。
通过建立大堆,出堆顶数据时,会将堆顶数据与堆尾数据进行交换,然后进行向下调整,即大的数据向下浮,小的数据向上浮,堆顶数据出完后,现在数组就是一个降序序列。
建小堆同理,出堆顶数据时,会将堆顶数据与堆尾数据进行交换,然后向下调整,使得小的数据向下浮,大的数据向上浮,出完堆顶数据最终会得到一个,升序序列
使用自下向上调整建堆时间复杂度最有优O(n),自上向下建堆时间复杂度O(nlogn)。
void AdjustDown(int* arr, int parent, int n){int child = parent * 2 + 1;while (child < n){if (child + 1 < n && (arr[child] < arr[child + 1])){child++;}if (arr[child] > arr[parent]){Swap(&arr[child], &arr[parent]);parent = child;child = parent * 2 + 1;}elsebreak;}}void HeapSort(int* arr, int n){for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(arr, i, n);//建大堆,排升序}int end = n - 1;while (end > 0){//模拟出堆顶Swap(&arr[0], &arr[end]);end--;AdjustDown(arr, 0, end);}}elsebreak;}}void HeapSort(int* arr, int n){for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(arr, i, n);//建大堆,排升序}int end = n - 1;while (end > 0){//模拟出堆顶Swap(&arr[0], &arr[end]);end--;AdjustDown(arr, 0, end);}}