C++之Linux多线程服务端编程读书笔记
Author: Once Day Date: 2023年1月31日/2024年8月23日
一位热衷于Linux学习和开发的菜鸟,试图谱写一场冒险之旅,也许终点只是一场白日梦…
漫漫长路,有人对你微笑过嘛…
全系列文章可参考专栏: Linux实践记录_Once-Day的博客-CSDN博客
参考文章:
《Linux多线程服务端编程:使用muduo C++网络库》
文章目录
C++之Linux多线程服务端编程读书笔记1. 线程安全的对象1.1 对象的创建1.2 对象销毁1.3 指针类错误1.4 智能指针1.5 并发编程 2. 线程同步精要2.1 线程同步原则2.2 互斥器原则2.3 条件变量2.4 读写锁和信号量2.5 线程库和锁封装2.6 Singleton与线程安全 3. 多线程服务器常用编程模型3.1 单线程单循环3.2 进程间通信3.3 多线程服务器3.4 多线程程序适用场景3.5 多线程信号处理 4. 多线程日志4.1 基本信息4.2 功能需求4.3 性能需求 5. 工程经验5.1 分布式系统可靠性5.2 C++编译经验5.3 C++编程5.4 C++内存管理
1. 线程安全的对象
线程安全的class应满足下面三个条件:
多个线程同时访问时,其表现出正确的行为。无论操作系统如何调度这些线程,无论这些线程的执行顺序如何交织(interleaving)。调用端代码无需额外的同步或其他协调工作。1.1 对象的创建
对象构造做到线程安全的唯一要求,是在构造期间不要泄露this指针。
原因是:在构造函数执行期间未完成对象初始化,this指针泄露可能导致其他地方处代码调用,从而操作未完成初始化的对象。
应采用二段式构造方法,即:构造函数+initialize()。在initialize()函数中可以返回标志值来判断是否初始化正常。
1.2 对象销毁
在单线程里,对象析构,注意空悬指针和野指针即可。
对于多线程,析构函数会把互斥量、自旋量等用于保护临界区的成员给销毁调用,从而导致同步/互斥手段失效。
作为class数据成员的MutexLock只能用于同步本class的其他数据成员的读和写,不能保护安全地析构。
此外,也必须保证按照相同的顺序加锁互斥量,否则可能导致死锁产生。例如,可以按照互斥量地址从小到大进行加锁。
析构过程必须要其他线程都访问不到才是安全的。
原始指针无法解决空悬指针的问题,无法判断一个对象是否被销毁或回收。
通过智能指针引入一个二级指针,便可以一定程度上解决相关问题。
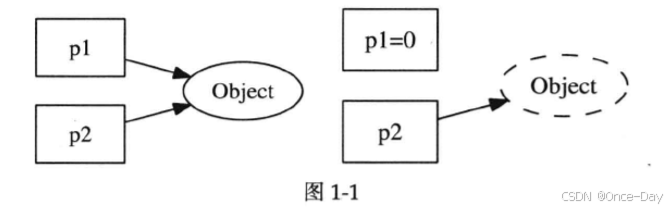
上图是直接引用源地址,当p1释放后,此时p2就变成了空悬指针。
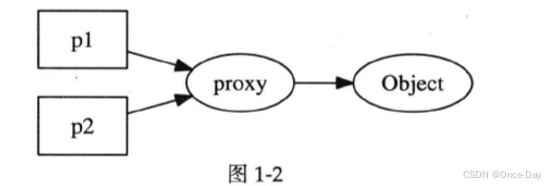
通过引入间接指针,可避免相关问题。但是此时在proxy上也存在竞争条件,proxy不确定自身被引用多少次,因此也就无法确定释放的时机。在此基础上,可以进一步引入引用计数。
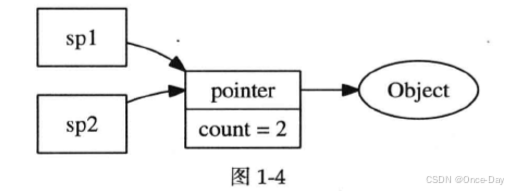
当sp1析构/销毁时,引用计数减一,当引用计数降为0时,就可以安全的销毁proxy和Object了。
上述的这种引用计数型指针可以直接使用shared_ptr和weak_ptr。
相比于shared_ptr,weak_ptr不增加对象的引用次数,为weak引用。
1.3 指针类错误
C++里面的内存问题大致如下:
缓冲区溢出(buffer overrun),使用std::vector<char>和std::string等对象。空悬指针/野指针,使用shared_ptr、weak_ptr。重复释放(double delete),使用scoped_ptr。内存泄露(memory leak),使用scoped_ptr。不配对的new[]/delete,使用std::vector/scoped_array。内存碎片(memory fragmentation)。 解决上面的手段,是广泛使用智能指针,以及std::vector等模板库,不要再像C语言一样手动分配内存。
需要注意,scoped_ptr/shared_ptr/weak_ptr都是值语意,应该是栈对象、对象直接数据成员、标准库容器的元素,而不应该去手动new分配内存使用。
1.4 智能指针
此外,智能指针自身并不是完成线程安全的,其级别和内建类型、标准库容器、std::string一样,如下:
一个shared_ptr对象实体可被多个线程同时读取。两个shared_ptr对象实体可以被两个线程同时读取,“析构”算写操作。如果要从多个线程读写同一个shared_ptr对象,那么需要加锁。shared_ptr还有如下的特性:
为了避免shared_ptr的拷贝开销,尽量使用常量引用(const reference),只在外层函数获取一次,后续使用栈对象引用传递。
shared_ptr的析构动作在创建时被捕获,因此可以无需虚析构,并且可以定制析构动作。
析构所在的线程位于最后一个引用指针所在,不一定是创建的线程,为了避免拖慢关键线程的运行,可以通过BlockingQueue将对象析构转移到专用线程中。
RAII(资源获取即初始化),new之后的对象立刻交给shared_ptr对象,不直接出现delete。
避免循环引用,owner持有指向child的shared_ptr,child指向owner的weak_ptr。
对于对象池,如果元素e本身需要访问对象池pool,可以通过定制析构函数将对象池指针以弱引用(weak_ptr) + 仿函数(bind)组合,从而在元素e释放时尝试处理对象池中的资源状态。这种方式称为弱回调技术。
1.5 并发编程
Go语言指出,没有垃圾回收的并发编程时困难的(Concurrency is hard without garbage collection)。
采用编发编程,不需要使用多么复杂的方法,关键点在于理解清楚。
多线程最好尽量减少跨线程的对象,使用流水线、生产/消费者、任务队列等有规律的机制,最低程度的共享数据。
对于c++语言,最好的方法就是避免使用指针,多使用新特性,如STL模板、Boost库,智能指针等等。
2. 线程同步精要
2.1 线程同步原则
并发编程有两种基本模型,一种是message passing,另一种是shared memory。
线程同步具有四项原则:
尽量最低限度地共享对象,减少需要同步的场合。如果需要共享,尽可能是immutable对象。使用高级的并发编程构件,如TaskQueue,Producer-Consumer Queue,CountDownLatch等等。底层同步原语(primitives),只用非递归的互斥器和条件变量,慎用读写锁,不要使用信号量。除了使用atomic整数,不要自己编写lock-free代码。 2.2 互斥器原则
互斥器保护了临界区,任何一个时刻最多只有一个线程在此mutex划出的临界区内活动。
用RAII(创建时初始化)封装mutex的创建、销毁、加锁、解锁这四个操作。只使用非递归的mutex(即不可重入的mutex)不手动调用lock()和unlock()函数,交给栈对象的构造和析构完成,即Scoped Locking作用域范围锁。规定加锁的顺序,避免死锁现象产生。不使用跨进程的mutex,进程间通信只用TCP sockets。加锁和解锁都在同一个线程。 非重入的互斥锁可以避免重复上锁,暴露逻辑上的缺陷。
互斥器(mutex)是加锁源语,用来排他性访问共享数据,它不是等待原语。在使用mutex的时候,一般都会期望加锁不要阻塞,总是能立刻拿到锁。然后尽快访问数据,用完之后尽快解锁,如此才能不影响性能和并发性。
2.3 条件变量
条件变量(condition variable)的学名叫管程(monitor)。用于等待某个事件发生。
对于等待端(wait()):
条件变量存在spurious wakeup,即虚假唤醒,所以需要使用while额外检查。
等于signal/broadcast端:
倒计时(CountDownLatch)是一种常用且易用的同步手段,可以如下使用:
主线程发起多个子线程,等待这些子线程各自都完成一定任务之后,主线程才继续执行。通常用于主线程等待多个子线程完成初始化。主线程发起多个子线程,子线程都等待主线程,主线程完成其他的任务后,通知所有子线程一起执行。2.4 读写锁和信号量
读写锁(Readers-Writer lock)区分读和写两种操作。
读写锁性能不一定比普通mutex更快。读写锁也存在很多误用的情况。读写锁可能发生死锁情况,也可能被堵塞住。信号量比较复杂,典型处理的问题是哲学家就餐问题,但是正常项目开发不会去如此设计,因此可以少用。
信号量可以使用mutex和条件变量来代替。
因此编程的时候可以尽量不使用读写锁和信号量。
2.5 线程库和锁封装
C++支持多线程,因此有标准的线程库实现,以及配套的锁,但是目前并不建议使用,其主要作为Pthread库的封装,且复杂度较高。除非在跨平台程序中,否则无需强迫去使用C++11线程库。
2.6 Singleton与线程安全
单例类最大的问题是线程安全,在多线程执行的环境下,很难确保不会出现并发冲突,特别是在创建和销毁时,chrome禁止全局构造和析构,所以单例类使用函数局部静态变量代替(需要禁止析构函数)。
事实上chrome不建议使用单例类,如果有需求,可以使用pthread的pthread_once_t来实现,或者c++11线程库中call_one。
3. 多线程服务器常用编程模型
3.1 单线程单循环
程序的每个IO线程都有一个event loop,处理读写和定时事件,这是一个非常好的保守性编程方法:
线程数目基本固定,可以在程序启动的时候设置,不会频繁创建与销毁。可以方便地在线程间调配负载。IO事件发生的线程是固定的,同一个TCP连接不必考虑事件并发。对于没有IO而光有计算任务的线程,使用event loop有些浪费,需要额外补充blocking queue实现的任务队列。因此,C++多线程服务端编程模式为:one (event) loop per thread + thread pool:
event loop (也叫 IO loop) 用作IO multiplexing,配合non-blocking IO和定时器。thread pool用来做计算,具体可以是任务队列或者生产者消费者队列。3.2 进程间通信
Linux下进程间通信(IPC)方式很多,如匿名管道(pipe)、具名管道(FIFO)、POSIX消息队列、共享内存、信号(signals)等等。
同步原语(synchronization primitives)有互斥锁(mutex)、条件变量(condition variable)、读写锁(read-writer lock)、文件锁(record locking)、信号量(semaphore)等等。
进程间通信首选Sockets,这样伸缩性比较好,需要跨设备就使用TCP/UDP,本设备上就使用Unix domain。
线程的创建和销毁存在代价,程序尽量一次创建好所需的线程,并且反复使用,不要在运行期间反复创建和销毁线程,最后频率低于1分钟一次。线程也是非常宝库的,程序一般使用数十个线程,但不要同时运行几百上千个用户线程,这对于内核scheduler的负担很大。
3.3 多线程服务器
服务端网络编程处理并发连接的两种方式:
线程廉价时,一台机器上可以创建远高于CPU数目的“线程”,这时一个线程只处理一个TCP连接(甚至半个),通常使用阻塞IO。通常意义上是Python和GO语言提供的协程支持。线程很珍贵时,一台机器上只能创建与CPU数目相当的线程,这时一个线程要处理多个TCP连接上的IO,通常使用非阻塞IO和IO multiplexing,例如libevent、muduo、Netty。一般推荐运行多个单线程的进程,因为多线程程序写起来很麻烦(目前多线程程序开始成为主流,但是单线程仍然有好处)。
单线程程序支持fork,多线程程序fork时容易出现问题。可以限制程序的CPU占用率,这个也可以通过cgroups实现。3.4 多线程程序适用场景
多线程程序的典型场景:提高响应速度,让IO和“计算”相互重叠,降低latency,虽然多线程不能提高绝对性能,但能提高平均响应性能。
有多个CPU可用,单核机器上多线程没有性能优势。线程间存在共享数据,但应该尽可能减少数量。共享的数据是可以修改的,而不是静态常量。提供非匀质的服务,事件的响应有优先级差异,使用专门的线程来处理优先级高的事件,防止优先级反转。latency和throughput同样重要,程序存在一定的计算量。利用异步操作,比如logging,需要往磁盘写log file或者往log server 发送消息,但不应该阻塞critical path。可以伸缩(scale up),一个好的多线程程序应该能够享受CPU数目带来的好处。具有可预测的性能,随着负载增加,性能缓慢下降,超过某个临界点之后会急速下降。多线程能有效地划分责任与功能,让每个线程的逻辑都比较简单,任务单一,便于编码。一个典型的多线程程序如下所示:
任务之间的状态是共享且可变的,如果大量使用共享内存,就是披着多进程外衣的多线程程序。master的主要性能指标不是throughput,而是latency,尽快地响应各种事件,几乎不会出现把IO或CPU跑满的情况。IO通信、logging、数据库、监控等工作都具有单独的线程。3.5 多线程信号处理
多线程程序中,信号会分为两类:
发送给某一线程(SIGSEGV),这种信息指定线程执行。发送给进程中的任一线程(SIGTERM),随机选择线程执行。一般而言,使用signal需要注意一下原则:
不要使用的signal作为IPC的手段,例如使用SIGUSR1来触发服务端的行为,通常可以使用双向监听端口来代替。不过,如果程序堵塞情况下,信号处理还是有较大用处的。不要使用基于signal实现的定时函数,例如alarm/ualarm/setitimer/timer_create/sleep/usleep。大部分异常信息(SIGSEGV/SIGBUS/SIGFPE/SIGABRT等),只使用默认语义,不进行处理。但是SIGPIPE可以忽略,避免IPC断开时程序意外终止。无替代情况下(比如处理SIGCHLD信号),可以把异步信号转换为同步的文件描述符事件,例如采用signalfd将信号转换为文件描述事件,从而根本上避免使用signal handler。4. 多线程日志
4.1 基本信息
在服务端编程中,日志是必须项,生产环境需要做到无时无刻记录任何事情,通常需要包含以下信息:
收到的每条内部消息的ID(包括关键字段,长度,hash等)。收到的每条外部消息的全文。发出的每条消息的全文,每条消息都有全局唯一的ID。关键内部状态的变更。诊断日志不光是给程序员看,也许要给运维人员查看,日志的内容应该避免造成误解,需要尽可能准确。日志框架是一个典型的多生产者-单消费者问题,对于生产者(前端),要做到低延迟、低CPU开销、无阻塞。对于消费者(后端),需要足够大的吞吐量,并占用较少资源。
通常C++日志有以下两种风格:
log_info("Received %d bytes from %s", len, 66);LOG_INFO << "Received " << len << " bytes from " << getClientName();4.2 功能需求
日志通常有以下的功能:
日志消息有多个级别(level),如TRACE、DEBUG、INFO、WARN、ERROR、FATAL。日志消息可能有多个目的地(appender),如文件、socket、SMTP等。日志消息的格式可配置(layout),例如org.apache.log4j.PatternLayout。可以设置运行时过滤器(filter),控制不同组件的日志消息的级别和目的地。日志目的地通常只有一个,本地文件,因为往网络写日志消息是不靠谱的,通常网络功能异常后,也是需要生成大量的日志。
本地文件日志需要进行日志文件的滚动(rolling),一般需要按照文件大小和时间条件来确定。
文件日志内容通常不能时刻刷新,因此通常是定期(3-5s)写入一次磁盘,其次是内存中的日志消息带有cookie(哨兵值/sentry),其值为某个函数的地址,然后通过coredump文件来寻址尚未写入磁盘的消息。
每条日志尽量都只占用一行,并且时间戳精确到微妙,通过VSDO系统调用,gettimeofday几乎没有什么性能损失。
跨洲使用的软件,通常使用GMT时区,多线程程序的线程ID也是需要打印的,此外日志级别、源文件名和行号也是需要打印的。
4.3 性能需求
日志库足够高效,输出的诊断信息才能足够充分,重点在于下面几部分:
每秒写几千上万条日志的时候没有明显的性能损失(实际瓶颈在字符串格式化操作)。能应对一个进程产生大量日志数据的场景,例如1GB/min。不阻塞正常的执行流程。在多线程程序中,不造成争用(contention)。日志库常见优化措施:
时间戳字符串中的日志和时间两部分是缓存的,一秒以内的多条日志只需重新格式化微妙部分。日志消息固定长度部分,直接copy赋值即可,无需重复调用strlen获取其长度,通常用于文件名取basename。线程ID和进程ID可以预先格式化为字符串,在输出消息时只需简单拷贝几个字节。多线程日志框架需要使用非阻塞的日志操作,通过背景日志线程来写入日志。当日志消息堆积时,也就是典型的生成速率超过消费速率,则会造成数据 在内存中堆积,严重引发性能问题或者程序崩溃,这个时候直接丢弃多余的日志buffer即可(限速日志)。5. 工程经验
5.1 分布式系统可靠性
正常的网络设备每年出问题的概率通常超过了1%,因此单机软件通常需要连续运行较长时间。
但是对于7x24小时的运行,需要明确 T M T B F T_{MTBF} TMTBF指标,要避免不切实际的软件可靠性指标。
在64位系统上,通常不需要考虑锁、内存、磁盘写满的情况,这种情况下程序也无法做什么。
硬件和软件条件都无法运行程序长期运行,因此程序设计时候必须确定重启进程的方式和待机,做到随时重启进程,耗时应该尽可能的短。一般而言,exit(3)或者kill(1)这种行为是无法区分的,但是进程都要求可以立即重启,所以程序只使用操作系统能够自动回收的IPC,跨进程的mutex或者semaphore和共享内存需要尽少使用。
可以使用四元组(ip:port:start_time:pid)作为分布式系统中进程的gpid,可以保证唯一性,避免单个条件异常时,弄混不同的进程实例。
进程可以仿照linux procfs内置监控接口,通过http协议暴露内部状态,这样可以避免运维时和黑盒子一样。
5.2 C++编译经验
C++语言需要满足与C兼容、零开销和值语义的约束,与C兼容就必须兼容C语言的编译模型与运行模型,比如可以直接使用C语言的头文件和库。
由于早期计算机设备的性能制约,C语言要求一个大程序必须划分为多个源文件进行编译,并且支持隐式声明。编译设计是单通编译,因此变量和类型必须提前定义,外部变量则等到链接期去实际生成引用。
C++编码规范通常建议使用前向声明来减少编译器依赖,但是需要主要声明和定义需要保持一致,否则容易出现未知的故障。
通常Linux内核版本、glibc版本、c标准库和c++标准库的版本是绑定的,更换也是可以的,不过需要编译大量的相关库,并且由于没有进行完善的测试验证,可能存在未知漏洞。
动态库和静态库使用都存在一定的风险,需要深入了解动态链接机制,对于业务程序,源码编译和分发是更好的选择。
5.3 C++编程
在C++这种需要自己管理内存和对象生命周期的语言里,大规模使用面对对象、继承、多态是自讨苦吃,应该适当使用。
C++ ABI接口主要内容如下,使用库代码时需要注意ABI的兼容性:
函数参数传递的方式,比如x86-64用寄存器来传函数的前4个整数参数。虚函数的调用方式,通常是vptr/vtbl机制,然后使用vtbl[offset]来调用。struct和class的内存布局,通过偏移量来访问数据成员。name mangling(名称处理,c++函数名称会进行修饰)。RTTI和异常处理的实现。C++的内置内联(bool/int/double/char)都是值语义,值语义(value semantics)指的是对象的拷贝与原对象无关。
与此相对的是对象语义,对象语义指的是面对对象下的对象,对象拷贝是禁止的。
值语义通常不用考虑生命周期管理,通常作为栈对象或者其他对象的成员。而对象语义一般需要通过指针和引用访问,必须考虑其释放过程,进而引入十分复杂的生命周期管理。
C++要求能放入标准容器的类型必须具有值语义,但是C++会默认给class提供拷贝和赋值函数,这可能引入隐性bug。当class涉及对象生命周期管理时,就必须实现拷贝和赋值控制,确保对象管理正常。
现代编译器通常对于程序细节优化做得很好,懂点汇编就打败C/C++编译器的时代已经过去了。
5.4 C++内存管理
内存管理基本要求就是不重不漏,不重复delete,也不漏掉delete,并且new/delete需要配对,malloc分配的内存要交给系统默认的free()去释放。
一般情况下不需要重载new运算符,这个仅限大型库的特殊要求。如果有内存统计和检查的需求,通过valgrind等库直接替换,或者重载malloc底层实现即可。
尽量不要为单独的类实现new重载,而且通过显式声明和构造一个函数来完成这个操作。