博客主页:【夜泉_ly】
本文专栏:【C语言】
欢迎点赞?收藏⭐关注❤️
C语言-结构体-详解
1.前言2.结构体类型2.1声明2.2变量的创建与初始化2.3访问2.4匿名结构体类型 3.结构体内存对齐3.1对齐规则3.2示例
1.前言
在C语言中,除了整型、浮点型等给定的类型外,还有很多自定义类型,结构体就是其中之一。
结构体十分重要,想要学好数据结构,必须掌握指针、结构体和动态内存管理。
本篇,我将详细介绍C语言中的结构体。
2.结构体类型
结构体作为C语言的一种重要的数据类型,其特点是由一组数据组合而成,且这些数据的类型可以不同。
2.1声明
基本框架:
struct tag{ member-list;}variable-list;其中,tag为该结构体的名字,member-list为成员列表,variable-list为创建变量的列表。
例如:
struct student{char name[20];int age;int tele;}s1,s2;为了存储一个学生的信息,需要存储姓名、年龄、电话等等内容,这些内容的数据类型显然不同,因此,可以用结构体存储:
struct student这里定义了一个结构体类型struct student,代表该结构体类型用于存储学生信息。
在这之后:
{char name[20];int age;int tele;}这里的name、name、tele称为结构体的成员,共同组成成员列表。
最后:
s1,s2;这里使用结构体类型创建了两个变量s1和s2,代表学生一和学生二。
当然,这里也可以不创建变量,但需注意, 分号一定不能丢 !
顺带一提,好像只要顺序正确,都能编译成功:
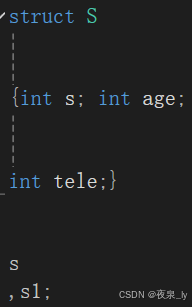
不过这样的代码过于恶心,这里只是尝试一下,平时可不敢这样写?。
2.2变量的创建与初始化
创建:
struct Stu{char name[20];int age;int tele;}s1;struct Stu S2;int main(){struct Stu S3;return 0;}S1、S2为全局变量,S3为局部变量
初始化大致分两种:
按原顺序进行初始化struct Stu s1 = { "张三", 18, 11223344 };struct Stu s2 = { .age = 81, .tele = 44332211, .name = "李四" };2.3访问
直接访问:
使用.
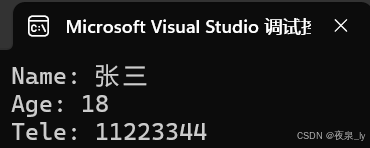
struct Stu s1 = { "张三", 18, 11223344 };printf("Name: %s\nAge: %d\nTele: %d\n", s1.name, s1.age, s1.tele);运行结果如下:
通过指针访问:
常见于数据结构部分,因为这部分的结构体变量大多是在堆上分配的。
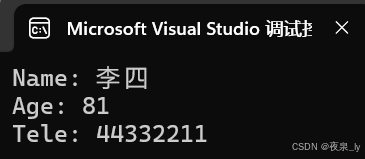
struct Stu *p = malloc(sizeof(struct Stu));if(!p){perror("malloc");return 1;}strcpy(p->name, "李四");p->age = 81;p->tele = 44332211;printf("Name: %s\n", p->name);printf("Age: %d\n", p->age);printf("Tele: %s\n", p->tele);free(p);p = NULL;运行结果如下:
一个小细节:
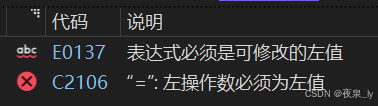
p->name = "李四";//strcpy(p->name, "李四");为什么不能写成这样?
在C语言中,字符串常量(如 “李四”)是不可修改的常量数组。
当试图将一个字符串常量赋值给一个字符数组时,编译器会报错:
因此,需要先创建一个字符数组,然后将字符串strcpy复制到这个数组中。
2.4匿名结构体类型
特点是没有名字,且只能用一次:
struct{char name[20];int age;int tele;}s,*ps;使用时,只能在结构体后创建变量,如s、*ps。
且,即便两个匿名结构体的成员列表相同,它们依然是两个不同的类型。
3.结构体内存对齐
先来看看下面这段代码:
struct S1{ char c1; int n; char c2;};struct S2{ char c1; char c2; int n;};int main(){printf("%zd\n",sizeof(struct S1));printf("%zd\n",sizeof(struct S2));return 0;}运行结果如下:
128如果单纯的将成员列表中各个成员的大小相加,那么S1、S2都应该是6字节。
但是很遗憾,不仅不是6字节,S1、S2的大小甚至都不一样,这是为什么呢?
结构体的大小不是结构体元素单纯相加就行的,因为主流的计算机使用的都是32bit字长的CPU,对这类型的CPU取4个字节的数要比取一个字节要高效,也更方便。所以在结构体中每个成员的首地址都是4的整数倍的话,取数据元素时就会相对更高效,这就是内存对齐的由来。
3.1对齐规则
第一个成员对齐到偏移量为0的位置。之后的成员对齐,对齐到对齐数的整数倍处。总大小需是最大对齐数的整数倍。对齐数:
常见类型的对齐数,按默认对齐数和自身长度,较小的那个进行数组的对齐数,按默认对齐数和自身成员长度,较小的那个进行结构体的对齐数,按默认对齐数和自身成员最大长度,较小的那个进行默认对齐数:
每个特定平台上的编译器都有自己的默认对齐数,如VS上的是8。
也可以通过预编译指令修改默认对齐数:
#pragma pack(n)注:这里的n最好取2的倍数
3.2示例
下面我将给出多个结构体,并解释它们的大小是如何得到的。
struct S1{char c1;char c2;int n;}先将c1存入偏移量为0的位置,占一字节:
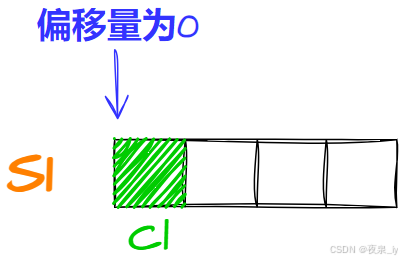
再存c2,计算得对齐数为1,因此存入偏移量为1的位置,占一字节:
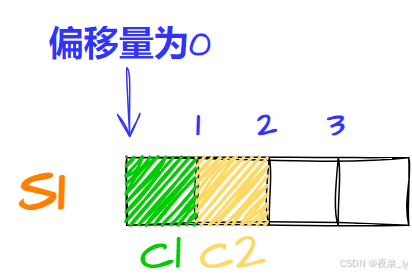
再存n,计算得对齐数为4,因此存入偏移量为4的位置,占四字节:
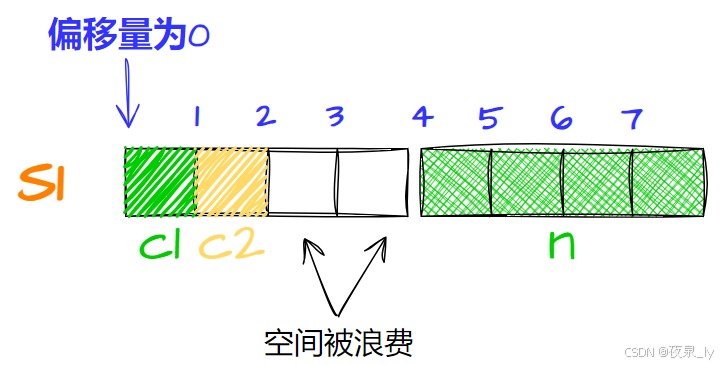
最后,最大对齐数为4,因此大小为8。
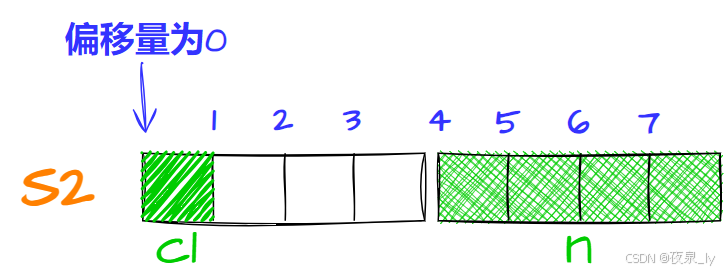
struct S2{ char c1; int n; char c2;};先将c1存入偏移量为0的位置,占一字节:
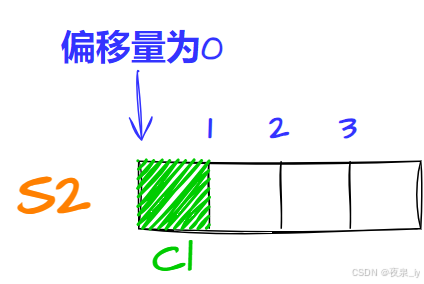
再存n,计算得对齐数为4,因此存入偏移量为4的位置,占四字节:
再存c2,计算得对齐数为1,因此存入偏移量为8的位置,占一字节:
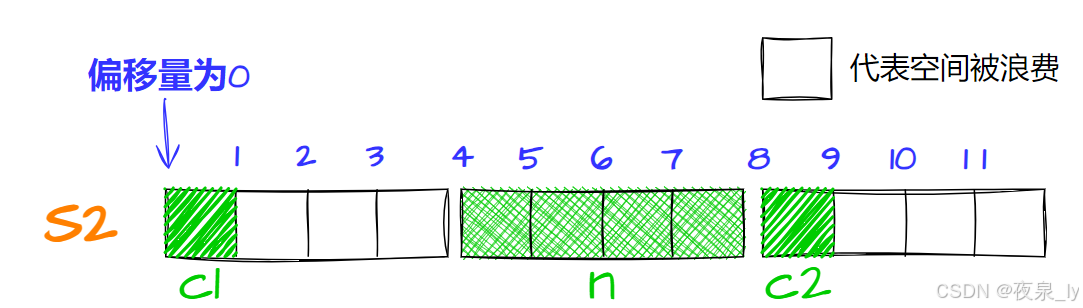
最后,最大对齐数为4,因此大小为12。
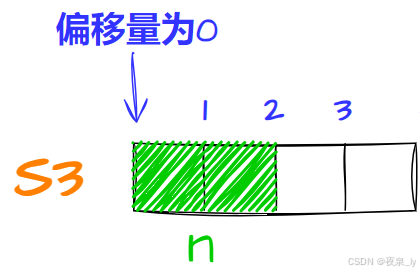
struct S3{ short n; char c; int i;};先将n存入偏移量为0的位置,占两字节:
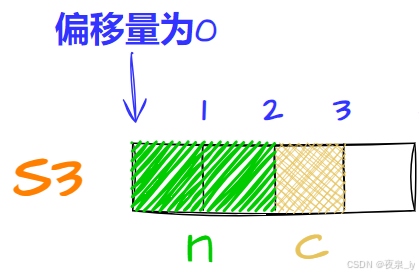
再存c,计算得对齐数为1,因此存入偏移量为2的位置,占一字节:
再存i,计算得对齐数为4,因此存入偏移量为4的位置,占四字节:
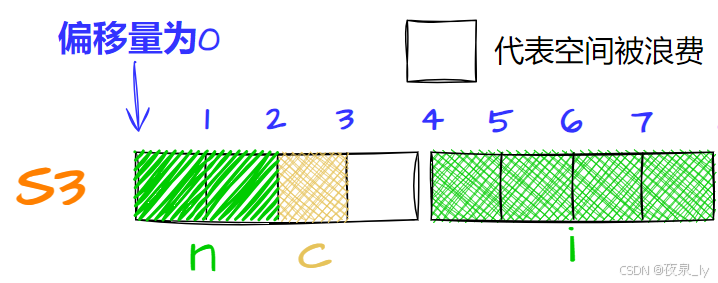
最后,最大对齐数为4,因此大小为8。
struct S4{ char c; struct S3 s3; double d;};先将c存入偏移量为0的位置,占一字节:
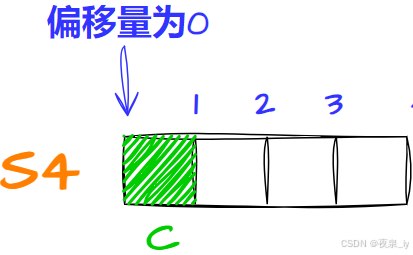
再存S3,计算得对齐数为4,因此存入偏移量为4的位置,占八字节:
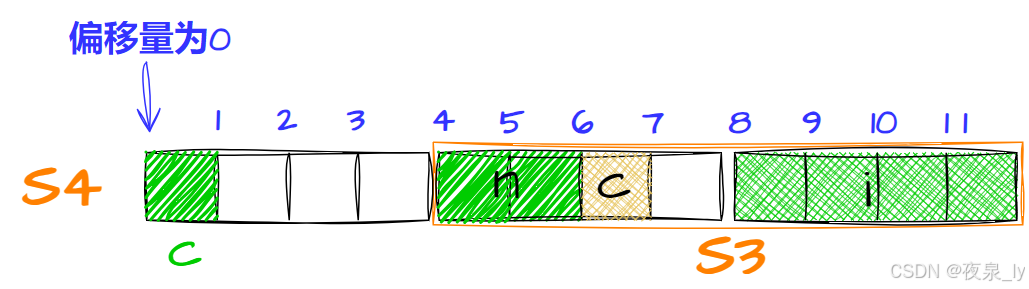
再存d,计算得对齐数为8,因此存入偏移量为16的位置,占八字节:

最后,最大对齐数为8,因此大小为24。
希望本篇文章对你有所帮助!并激发你进一步探索C语言的兴趣!
本人仅是个C语言初学者,如果你有任何疑问或建议,欢迎随时留言讨论!让我们一起学习,共同进步!